- Azure Active Directory
- Azure Active Directory B2C
- Azure Active Directory Domain Services
- Azure Analysis Services
- Azure App Services
- What is Azure Application Insights?
- Azure Arc
- Azure Automation - Benefits and Special Features
- A Complete Guide On Microsoft Azure Batch
- Azure Cognitive Services
- Azure Data Catalog
- Azure Data Factory - Data Processing Services
- Everything You Need To Know About Azure Data Lake
- Azure DNS - Azure Domain Name System
- Azure ExpressRoute
- Azure Functions - Serverless Compute
- Azure Interview Questions and Answers (2024)
- Azure IoT Edge Overview
- Azure IoT Hub
- What Is Azure Key Vault??
- Azure Load Balancer
- Azure Logic Apps - The Lego Bricks to Serverless Architecture
- Azure Machine Learning
- Microsoft Azure Media Services
- Azure Monitor
- Introduction To Azure SaaS
- Azure Security Center
- Azure Service Bus
- Overview of Azure Service Fabric
- Azure Site Recovery
- Azure SQL Data Warehouse
- Azure Stack - Cloud Services
- Azure Stream Analytics
- Azure Virtual Machine
- Azure’s Public Cloud
- Microsoft Azure Application Gateway
- Microsoft Azure Certification Path
- Microsoft Azure - Exactly What You Are Looking For!
- Microsoft Azure Fabric Interview Questions
- HDInsight Of Azure
- IS Microsoft Azure Help To Grow?
- Microsoft Azure Portal
- Microsoft Azure Traffic Manager
- Microsoft Azure Tutorial
- Overview of Azure Logic Apps
- Top 10 Reasons Why You Should Learn Azure And Get Certified
- Server-Less Architecture In Azure
- What is Microsoft Azure
- Why Azure Machine Learning?
- Azure DevOps Interview Questions
- Azure Active Directory Interview Questions
- Azure DevOps vs Jira
- What is Azure Service Fabric
- What is Azure Databricks?
- Azure Databricks Interview Questions
- Azure Data Factory Interview Questions
- Azure Architect Interview Questions
- Azure Administrator Interview Questions
- Azure Data Studio vs SSMS
- Microsoft Interview Questions
- What is Azure Data Studio - How to Install Azure Data Studio?
- Azure DevOps Projects and Use Cases
- Azure Data Factory (ADF) Integration Runtime
- Azure DevOps Delivery Plans
- Azure DevOps Variables
- Azure DevOps vs GitHub
- Azure DevOps Pipeline
Azure data factory is a cloud-based platform. The platform or rather an eco-system allows you to develop, build, deploy and manage the application on the cloud storage. The cool thing about the platform is that it allows you to do everything on the cloud. That said, your physical device’s storage memory is saved. And all the stuff that you do is stored on the cloud.
Seeing the Azure platform from the future point of view has tremendous scope. When Microsoft has come up with a concept, it is sure that it is futuristic. Hence, learning it right now is an excellent move towards your career.
You must know how practically Azure data factory works before using it. Let us consider a scenario where you are having a lot of data and you are unable to sort it. Azure data factory helps you to analyze your data and also transfer it to the cloud.
To introduce you to the Azure data factory, we can say that the Azure data factory can store data, analyze it in an appropriate way, help you transfer your data via pipelines, and finally, you can publish your data. With the help of some third-party apps like R and spark, you can also visualize your data.
| If you would like to Enrich your career with a Microsoft Azure certified professional, then Enrol: "Azure online training". This course will help you to achieve excellence in this domain. |
The Azure Tutorial is basically designed for developers who have Azure subscriptions. The implementation of Azure is going to be fallen in website, application, and software development. Hence, for the ones who are keen to do such projects, Azure will be more beneficial to them.
Azure Data Factory Tutorial For Beginners
If you want to use Azure data factory, you must have knowledge about Azure data factory tutorials. Let us know what exactly is Azure data factory tutorial is and how it is useful. With the help of the Azure data factory tutorial, you will know how the Azure data factory actually works. You will also be made aware of the importance of the Azure data lake.
Azure data factory tutorial will guide you to copy your data from SQL of Azure to Azure data lake. After that, you can also visualize your data using third-party sources like Power BI.
You will also learn more about Analytics. Analytics can also be operated by using U SQL for processing the data.
Nowadays, we are getting a large number of data from many resources. The result of such increasing data is that it gets very difficult for us to manage, store and analyze the data at the same time. That is why we must use Azure data factory, which helps you to store, analyze and transfer a large amount of data.
There are various steps and terms associated with Azure data factory such as pipelines, Azure data lake, storage. Let us learn about all these terms and get detailed information about them. As discussed earlier, if you are having stored data then azure data factory collects that data, transfers that data through pipelines, and finally you can use that data to publish or visualize using various sources.
Here is a step-by-step illustration.
- Collect the data and connect it: Data in the pipeline can be copied or transferred to the cloud source data stores or the same data can also be moved from on-premises.
- Transforming the data: computer services can help you in transforming or processing the data which is already centralized in the cloud. Computer services are Hadoop, Spark, R, etc.
- Publishing the data: Data that is already structured, analyzed, and well-refined is now collected into the Azure data factory warehouse. It is monitored and published in the Azure data warehouse.
- Monitoring your data: PowerShell, Azure monitor is available on the Azure portal which helps you in pipeline monitoring. Azure data factory works on data-driven workflow with structure so that it can easily move and transfer the data. Azure data factory does not work with a single process. It has various small components which work independently, and when combined, it performs successful operations.
- Pipeline: A unit of work that is performed by logical grouping activities is called a pipeline. Pipelines can be single or multiple. Various tasks are performed by pipeline at a time, such as transforming, analyzing, and storing
- Activity: processing steps of the pipelines are represented by the help of Activity. For example - copy activity is widely used to move data from one source to another source.
- Datasets: data sources that are present in the data stores are represented by the data set structures. We can also classify that data in our activities.
- Linked Services: It can be defined as a bridge that is used to connect the Azure data factory to external resources. Computer resources and data stores are types of the linked services.
- Triggers: Triggers, as the name suggests, triggers something. When pipeline execution is needed to be disabled then the unit of processing determines it with trigger this unit is known as a trigger. Another feature of the trigger is that we can schedule this process pre-handed so that at a particular point we can trigger and disable the process.
- Control flow: It is an extension of activities that are carried out by pipeline. We can also say it is like a thread or chain which arranges activities in a sequence.


Components of SQL Data Warehouse
- Data Warehouse Units: Data Warehouse Units (DWUs) are the measure of data or resources that are received by SQL. This memory is allocated to the data warehouse.
- Scan/Aggregation: Scan/Aggregation scans the query generated. This work is I/O and CPU-based.
- Load: Load is the measure of how much data could be actually talked up by the data warehouse.
- Create Table As Select (CTAS): CTAS enables users to make a copy of the table. It reads, operates, distributes, and writes the table.
Structure of Azure data factory
Let us get into more depth about the Azure data factory structure. Let us consider you are having some data, it can be in the form of mobile data or any other kind. Now, this data can be transferred to your output cloud using a pipeline. Pipeline is SQL or hype which carries various operations on data and transfers it to the output cloud. We will learn more about pipelines in a few more upcoming points. Output data is the structure form of your data as it is already transformed and analyzed in the pipeline. Finally, this data is stored in the lake data.
- Organization: Azure DevOps Organization works very similarly to any physical organization out there. It is a group or division of alike projects combined together.
- Projects: Projects in DevOps are agile and continuous testing, integration, and the deployment of the same project is ongoing.
Creating Azure Data-Factory using the Azure portal
Step 1: Find - "create a resource' and search for "Data Factory". Click the create icon.
Step 2: Give your data factory a name. Select your resource group. Give it a path to and choose the version you would like.
Step 3: Click on create.
Thus your data factory is ready to be filled with more data.
Azure SQL Stretch Database & SQL Data Warehouse
SQL Stretch Database:
SQL database acts as an interface between the user's raw data and Azure's data lake. SQL database is processed and transformed to the cloud. The data is processed to be classified further. Hot data is the one that is accessed frequently by the users. And cold data is one that is not accessed quite frequently.
To recover or fetch the data, whenever needed, we simply need to type a query. And the data, wherever it may have been categorized, is searched out.
Advantages of SQL Stretch Database
The on-premise storages are expensive and they take some extra effort to fit in the database queries. SQL is comparatively easier and cheaper than most of the other storage platforms. SQL extracts the data on the cloud. Hence it is faster, and its maintenance is minimal too.
While transforming the data, SQL keeps it extremely safe and secure. Its encryption is protecting the privacy of data even while the transformation of data is in process. Advanced security of the SQL keeps the stretch database absolutely secure and safe.
SQL database warehouse is a fully cloud-based platform and hence extracts the data with ease. It uses parallel architecture to fetch out whichever type of data is searched for. In the parallel architecture, the data is inquired with the control mode and passed on to the computer mode. Both the modes and processes in between are made to work parallelly.
Azure DevOps
Azure DevOps helps in coordinating with the support team to make the Azure application development and changes. That said, Azure DevOps allows you to modify the minor changes in codes and infrastructure without having developers interfere.
Services of Azure DevOps
Not only does the Azure DevOps allow you to modify minor changes, but it also helps the user deploy and build the applications. Its services are scattered wide. Right from building to developing to deploying, all the functionalities are performed in sync on the single cloud platform.
Azure Repository:
Azure Repository is very analogous to the git repository. All the codes are stored in the Azure repository to build up an application. The tool is used by developers to code and build. Specific developers are granted access to a particular git part of the code.
Azure pipeline:
Azure pipeline works as a pipeline to the destination path. Wherever the code is required to combine or to function at a particular time, this pipeline inserts the code there.
Boards:
Board is something where you can create activities, track activities, and distribute the task of development to the team.
Test Plan:
A test plan is browser-based testing done with automation instead of having manual testing be done.
Artifacts:
Azure data factory, requires the NuGet package, npm, Maven package, and many other such packages. Artifacts are compatible with all the packages and hence is very useful.
Collaboration tools:
These are the tools for team collaboration. The team is free to have their own customized dashboard and the widgets they require on their board.
| Also Read: Overview of Azure Arc |
Azure DevOps Portal
Azure DevOps Portal is where you will be performing all the development tasks. To create an Azure Portal, you need to register to Azure services first.
Step 1: Visit https://Azure.microsoft.com/en-in/services/devops/ and click on Start Free if you are not yet registered to Azure services.

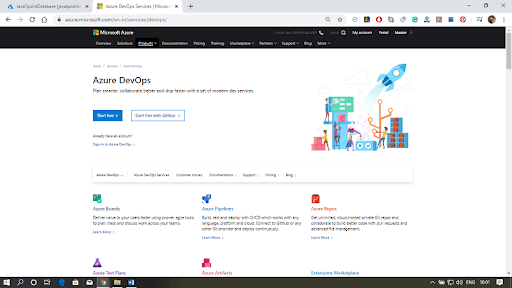
Step 2: Once you have started, it will ask you to fill up the details.
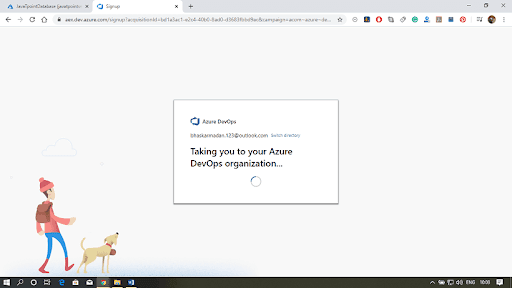
Step 3: Now you are in Azure DevOps Portal and you got to create a new project and organization for yourself.
Step 4: Create New Organization.
Step 5: Give your organization a name and select the path location for your organization.
Step 6: Organization is created now and you will be asked to create your new project
Step 7: Give your project a name. And select the version on which you will be working, from advanced settings.
Step 8: Once you click on create a project, your project will be created successfully.
You can invite your teammates to the project.
Publish ARM Deployment project into DevOps
Step 1: Open Visual Studio and search for a new project tab.
Step 2: In the project, you will find Azure Resource Group.
Step 3: Configure the new project with it and click next.
Step 4: Click on Web Application from the Azure Template in Visual Studio.
Step 5: You will find the website.json file on the left-hand side of the file explorer.
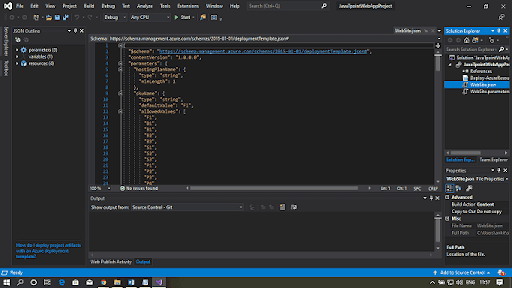
Step 6: Publish this code by clicking on Add code.
Step 7: You will get a new git repository.
Step 8: Click Team Explorer and then right-click to select sync.
Step 9: Click on the Publish Git Repo button. And your project in the Azure DevOps organization is published.
Step 10: Select the project and repository path where you want to publish this code and then click on publish repository.
Azure Factory Data lake file system.
Microsoft Azure Data Lake: Working of data can be understood in three basic steps. The first step is to get you output data which can be in mobile data form or any other type then it is transferred to the Azure factory data and you can visualize your data in the third step using any third-party apps like R, apache, Spark, etc.
There are another two vital components which you should be aware of. The first concept is storage, storage of data can be in Gigabytes, terabytes, etc. This data is wide and large information. You can analyze this data as structured or unstructured data. Structured data has specific information in it and unstructured data is a lobby type of data.
The second concept is analysis, now the analysis is also divided into two types. First type of
The analysis is a monitor type where you can generate your data. For example data of buildings, location, construction cost, area of the building, the life of the building, amount of live load, and dead load it carries. All this data of building is available to you in a structured manner.
Another type of analysis is the use of the Azure data factory in a card. If you have a debit card you can know its transactions, location of the card, its expiration date, and much more. These are the two main concepts you must know about the Azure data factory.
Bottom Line
Thus was the glimpse into Microsoft Azure. The tutorial was for beginners who have not accessed the Azure data factory platform yet. Looking forward to the Azure data factory from a career point of view, it is the best skill to learn today that will help you earn tomorrow. Basically, all the social media data is processed and optimized using a data factory.
Azure, being a cloud-based platform, the load on Azure is light. The data could be accessed whenever the user wishes to. There are various career opportunities in the forte of the Azure data factory.

.svg&w=750&q=75)
Stay updated with our newsletter, packed with Tutorials, Interview Questions, How-to's, Tips & Tricks, Latest Trends & Updates, and more ➤ Straight to your inbox!
| Name | Dates | |
|---|---|---|
| Azure Training | Apr 27 to May 12 | View Details |
| Azure Training | Apr 30 to May 15 | View Details |
| Azure Training | May 04 to May 19 | View Details |
| Azure Training | May 07 to May 22 | View Details |


Anjaneyulu Naini is working as a Content contributor for Mindmajix. He has a great understanding of today’s technology and statistical analysis environment, which includes key aspects such as analysis of variance and software,. He is well aware of various technologies such as Python, Artificial Intelligence, Oracle, Business Intelligence, Altrex, etc. Connect with him on LinkedIn and Twitter.














Copyright © 2013 - 2024 MindMajix Technologies