- BitBucket Tutorial
- Git Rebase Tutorial
- Branches, Part II – Git
- Centralized Workflow In Git
- Git – Distributed Workflows
- Git Interview Questions And Answers
- Git – Plumbing Commands
- Git – Rewriting History
- Git – Tips & Tricks
- Git Tutorial
- Git – Working With Remotes
- GitHub Interview Questions
- GitLab Tutorial
- Installation of Git
- Patch Workflows – Git
- Git Basic Concepts
- GitHub CI/CD Tutorial
- Git vs SVN
In this article, we will discuss an open source distributed version control system which is quite popular in the current market, i.e. Git. Using this tool, individuals will be able to share and manage code in a better way.
Git -Table of Contents
- What is Git?
- Distributed Version Control System
- Advantages of Git
- Basic workflow of Git
- Branching Strategy for Git
- Why branching is important
- Undo local changes
- Unstaged local changes
- Quickly save local changes
- Staged local changes
- Committed Local changes
- Redoing the Undo
- Undo remote changes without changing history
- Undo remote changes with modifying history
- Where does modifying history is generally acceptable?
- How modifying history is done?
- Deleting Sensitive information from commits
What is Git?
Git is a open source distributed version control system which has capabilities to handle a small level project as well as a high level project with utmost speed and efficiency. The code repositories are handled with the use of Git tool. This tool is developed by Linus Torvalds, the same individual who has developed Linux operating system.
Git is easy to learn and has developer friendly features like local branching, staging areas and can accommodate multiple workflows.
Before getting into the details, let us understand what a distributed version control system is first:
Distributed Version Control System:
The next generation of version control systems is nothing but a distributed version control system which is capable of accessing the code from anywhere, i.e., irrespective of the geographical location. All you need is a computer with the development setup with an active internet connection.
GIt is nothing but a distributed version control system. Initially, the software development market had access to multiple version control systems but always lacked the flexibility and usability. During the course of time, distributed version control system has evolved and started helping out the developers to manage their code.
The master code copy is available in the central server and at the same time, a local repository is also available in the developer computer. So, if the developer has worked on any latest code changes, they can push the code changes to the central server, this will provide flexibility for the developer to access the code from any other machine.
[Related Page: Git Rebase]
Git is a source code tracker, i.e, it tracks and stores the code. Apart from storing the code, the tool provides other functionalities as well.
Git enables the developers to store code. As and when the new code is pushed into the repository, the developers will be able to differentiate the changes that they have carried out.
In the below section, we will understand the advantages of Git and further discuss the various operations/functions that the developers will be able to do.


Advantages of Git
In this section, we will discuss the advantages of Git.
- Open source free tool: The tool is available for free of cost.
- Fast and reliable: Most of the operations can be done locally and there is no need for constant interaction with the central server.
- Backup: All the code is backed up into the remote system, and at the same time, a master copy is available in the central server all the time, so there is no need to worry if the system crashes.
- Security: It uses a cryptographic function called (SHA1), i.e., secure hash function.
- Powerful hardware is not necessary: Most of the operations happen at the local system. If the developer wants to push or pull the code, only then the interaction is needed with the central server system.
[Related Page: Git – Rewriting History]
Basic workflow of Git
The below section discusses the basic workflow of Git. The steps in this process are depicted in the diagram below.
Step1 : From the working directory, modify a file.
Step 2: By using Git Add operation, add the files to staging area
Step 3: By using Git commit operation, commit the files to the staging area. The changes are now will be permanently saved to the GIt repository.
For example:
You have modified two files,
“sort.n”and “search.g”. These two files can be committed one by one.
First add “sort.n” file to the staging area and commit the file.
Now, commit the second file by following the same process as above. Add "Search.g" file to the staging area and commit the file.
Using below commands, the users will be able to add the files to the staging area, and then commit the file.
# First commit [bash]$ git add sort.n # adds file to the staging area [bash]$ git commit –m “Added sort operation” # Second commit [bash]$ git add search.g # adds file to the staging area [bash]$ git commit –m “Added search operation”
Before going further into the specifications, it is good to understand Git basic concepts. Let’s have alook at them.
Blobs:
- Stands for Binary Large Object.
- Each and every version of a file represents a blob.
- A blob actually holds the file but id doesn’t have any metadata. Also, it is a binary file.
Trees:
- A tree is an object, and it represents a directory. The tree holds blobs and other available subdirectories.
Commits:
- It determines the current state of the repository.
Branches:
- Usually, they are used for a different line of development.
- By default, Git has a Master branch which has the latest code. If the developers are working on a new feature, then they can create a new branch and push their code to the master. Doing this will not affect the master code repository and at the same time, it doesn’t affect the un-reviewed developer code.
Tags:
- Tags are used to define a meaningful name for a particular version.
- They are used while giving out product releases.
Clone:
- As the name implies, this command is used to get an additional copy of the current code repository.
Pull:
- A pull operation gets all the changes from the remote instance to the local instance.
Push:
- A push operation gets all the changes from the local instance to the remote instance.
Head:
- Head is nothing but a pointer, and it always commits to the latest commit in the branch. So, whenever there is a new commit, the head is directly pointed towards the latest commit.
- Head of the branches is stored in .git/refs/heads/directory.
[Related Page: Centralized Workflow In Git]
Branching Strategy for Git
In this section of the article, we will understand about Branching strategy and what is the standard process that everyone should follow.
A branching strategy is nothing but a process where it helps the developers to find out a perfect balance between flexibility and collaboration. Based on these factors, one can share the code in a regular manner.


In the above figure, the user gets to see three different branches. The first branch is the Master branch where all the code is available. This branch shouldn’t be affected at any point of the time. So if the developers has to go through a new feature development they have to consider a new branch from the master and carry on with the development. The same process should be taken into consideration.
Why branching is important
With the help of branching, you can manage your developer team perfectly. By following the branching strategy, team members will be able to share and review the code via Git branches. This process helps to maintain optimum collaboration and at the same time spend less amount of time on version control.
The process of building a successful branching strategy:
- Always use feature branches for all new features and bug fixes
- Using pull requests, merge all of your feature branches into the master branch
- Make sure the master branch is always up to date
Using the above process will be an added advantage because the developer will have an option to review the history easily.
Also, using a consistent branch naming convention is really important. This will help the team to understand and also identify the piece of work that a particular branch has.
[Related Page: Git Tips & Tricks]
Few suggestions for having ideal branch naming conventions are:
- feature/feature-name
Feature is a new functionality that will enhance the application/project.
- feature/feature-area/feature-name
- bugfix/description
Bugfix is nothing but a known issue that is identified within the application/project
- hotfix/description
Hofix is nothing but a quick fix to the code base.
Undo local changes:
The process of undoing local changes or the question of how to handle undo local changes depends based on various stages. The process is handled differently based on the situation.
Unstaged local changes ( this is before committing the code).
When a change is made within the file and it is not added to the staged tree, Git itself proposes a solution to undo the changes for that particular file.
[Related Page: Git Basic Concepts]
For example:
A file is opened via file editor to modify the content.
vimIf the file is not added to the staging, use git add. The file will be available under unstaged files.To confirm whether the file exists,
Please use $ git status command. This will show the status of the master branch. Also, the below commands are used to add the file to staging and commit. Further, a checkout command is used to complete the process.
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes not staged for commit:
(use "git add ..." to update what will be committed)
(use "git checkout -- ..." to discard changes in working directory)
modified:
no changes added to commit (use "git add" and/or "git commit -a")So to handle the situation, there are three options available.
Frequently asked Git Interview Questions
Option 1:
- Ignore all the changes that are done to the file
- Save the modifications for later re-use.
To do this, use the below command.
git stashOption 2:
- Ignore all the changes that are done to the file permanently.
To do this, use the below command.
git checkout -- Option 3:
- Ignore all the changes for all the available files permanently.
To do this, use the below command.
git reset --hardQuickly save local changes:
This section of the article is really useful and most of the developers use this quite often. For example, If you are working on a feature implementation on a new feature branch, and all of a sudden you had to take care of a bug fix, so saving the current work and attending the bug fix can be easily handled with the use of Git.
[Related Page: Installation of Git]
This can be done by using the following command.
-
git stash
Using this command will save all the work that you were doing and lets you move to another branch. Also, they are other commands available, which are:
-
git stash list
The developer can add a temporary commit message. This will help to identify the changes
-
git stash list
Using this command, a list of stashed commits will be displayed.
-
git stash pop
Previous stashed changes will be redone and will be removed from the list.
-
git stash apply
Previous stashed changes will be redone and it will be available in stashed list.
Staged local changes ( i.e. before you commit your changes)
In this section, we will discuss the process where you can save your changes locally in the local machine.
For example, you have modified some files and moved it into the staging stage. Later, you wanted to move these files out of staging stage but want to retain the files for later use. So, this can be done by using the below command.
-
git reset-hard
Or use below command.
-
git stash
So to perform the above steps, check on the following:
vim
git add The file will be added to the staging, this can be confirmed by using git status command.
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes to be committed:
(use "git reset HEAD ..." to unstage)
new file:
To undo the steps, we have 4 options :
Option 1:
- From the current commit, unstage the file (HEAD)
This can be done by using the below command.
git reset HEAD Option 2:
- Retain the changes by reverting the stage operations.
This can be done by using the below command.
git resetOption 3:
- Discard all the local changes
- Save the changes for later usage.
This can be done by using the below command.
git stashOption 4:
- Permanently discard everything.
This can be done by using the below command.
git reset --hardCommitted Local changes:
With version control systems, if you push any latest code to the central repository, your changes will be recorded. If you have not pushed any code to the central repository, then you will have different workarounds to work with.
Without modifying history:
Within the development process, let us say that you have committed several times and some of the changes do not match with the current solution, then you can simply revert the changes from the commit by using the following command.
git revert commit-id
Using this command will swap all the additions and deletions in that particular commit. Doing this will not affect your history.
To explain this in detail, let us consider an example:
Let’s say that you have these commits, A, B, C, D, E
The order of commits is A-B-C-D-E, out of which B is the commit that you want to undo the changes.To do this, you have a lot of different options, one of the best options is to pass through the commit range by using the below command.
git bisectUsing this command, the last known good commit is A and let us assume that last known bad commit is E.
git bisect A..E
Using the bisect command, we will get to know the middle commit-id where you can test.
For our discussions, let us stop with Commit B and consider that this command has introduced a bug.
So, to remove this bug or error from the Commit B, we have 3 options.
Option 1:
- Undo the changes introduced by Commit B ( Swaps all the additions and deletions).
- This can be done by using the below command.
git revert commit-B-id
Option 2:
- Pick a single file or a directory
- undo the changes from Commit B, but make sure to retain the changes in the staged state.
This can be done by using the below command.
git checkout commit-B-id
Option 3:
Pick a single file or a directory, undo the changes from Commit B, but make sure to retain the changes in the unstaged state.This can be done by using the below command.
git reset commit-B-id
With history modification:
For history modifications, we have one command,
git rebase
Also with the command, you can use the interactive mode. Using this mode will help you to use:
- Reword the commit message.
- Edit the commit content
- Squash- multiple commits can get into one single message.
- Drop commits, this will simply delete the message.
[Related Article: Git – Rewriting History]
Redoing the Undo:
In this section, we will discuss the process where you can revert the changes that you have undone.
Sometimes, by mistake, we undo few modifications in a file and later realize that the undone modifications are important.
So, to recall all the detached local commits, you can use the below command. Using this command, you will be able to view the history repository and also track all the older commits. The log will be displayed with the commit-ids as well.
Git reflog
$ git reflog show # Example output:
b673187 HEAD@{4}: merge 6e43d5987921bde189640cc1e37661f7f75c9c0b: Merge made by the 'recursive' strategy.
eb37e74 HEAD@{5}: rebase -i (finish): returning to refs/heads/master
eb37e74 HEAD@{6}: rebase -i (pick): Commit C
97436c6 HEAD@{7}: rebase -i (start): checkout 97436c6eec6396c63856c19b6a96372705b08b1b
...
88f1867 HEAD@{12}: commit: Commit D
97436c6 HEAD@{13}: checkout: moving from 97436c6eec6396c63856c19b6a96372705b08b1b to test
97436c6 HEAD@{14}: checkout: moving from master to 97436c6
05cc326 HEAD@{15}: commit: Commit C
6e43d59 HEAD@{16}: commit: Commit BThe above highlighted content is nothing a repository history that we get after using the command.
Undo remote changes without changing history:
In this section, we will discuss the process to undo the remote changes without actually changing the history.
- This is the standard method of undoing the changes on any remote system or repository/ public branch.
- While following this process, branching is one of the best solutions to accomplish the task without modifying the history.
Also, branching will help you to start a new branch where you can merge all code fixes and new feature implementations to the master branch. This will enable you to see the timeline of all the development efforts went in.
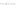
In the above screenshot, the history of commit structure is displayed. Intially, the user has commited in this order: Commit A, Commit B, Commit C.
- At this point of time, if the developer wants to revert any commits, they can do so by using below commit id.
- In this case, the user has reverted Commit id B after Commit C.
So, if the user checks the commit history, the commit structure will be in this order :
Commit A, Commit B, Commit C, - Commit B, Commit D.
The same is depicted in the above screenshot. To revert any changes that are introduced within the commit cycles, it is advised to revert the changes with the particular commit id. This can be done by using below command.
git revert commit-id
Or else, creating a new branch will also solve the problem
git checkout commit-id
git checkout -b new-path-of-feature
Undo remote changes with modifying history:
- This process is useful only to hide important keys like secret keys, passwords, SSH keys, etc.
- It shouldn't be used to hide any known mistakes, if used, then it will be hard to debug other bugs.
- One point to be noted, even though the history is modified, commits can be accessed individually through commit id.
Where does modifying history is generally acceptable?
The modified history actually breaks the development chain of other developers. The change in history actually creates commit ids mismatch. This is one of the primary reasons why history modification is not preferred on any public branch.
So, if you or your team is contributing to a big open source repository, then they are typically squash commits into a single one. This will make history viewing easy. Further, a point to be noted on the comments is, if you are squashing the commits then the comments that are associated with the commits will be removed.
Never ever modify a commit history of the master or any shared branch. This is not at all acceptable.
How modifying history is done?
In this section of the article, we will discuss about the process of modifying the history.
First of all,
- Identify the commits where you want to modify ( In this case, commits range is taken into consideration).
- Use the command
git rebase -i commit-id - Using this command will show all the history of the commits from the current version to the chosen commit id.
- Allowing modification via deletion, squashing of the commits.
Below command shows the different options that the developer can avail while using Rebase commands.
$ git rebase -i commit1-id..commit3-id
pick
pick
pick
# Rebase commit1-id..commit3-id onto (3 command(s))
#
# Commands:
# p, pick = use commit
# r, reword = use commit, but edit the commit message
# e, edit = use commit, but stop for amending
# s, squash = use commit, but meld into previous commit
# f, fixup = like "squash", but discard this commit's log message
# x, exec = run command (the rest of the line) using shell
# d, drop = remove commit
#
# These lines can be re-ordered; they are executed from top to bottom.
#
# If you remove a line here THAT COMMIT WILL BE LOST.
#
# However, if you remove everything, the rebase will be aborted.
#
# Note that empty commits are commented outDeleting Sensitive information from commits
In this section of the article, we will discuss about the commands that can be used to delete sensitive information from the commits.
Using the Git tool, the sensitive data can be deleted from the previous commits. To do this,
- use the below command.
git filter-branch
- Using this command will help you to rewrite the history by using specific filters.
- Also, this command uses rebase to modify history.
git filter-branch --tree-filter 'rm filename' HEAD
If the same process is implemented in big repositories, then it will be slow and to speed up the process, we have some tools available. A specific tool that one can use straight away is BEG Repo-cleaner. There are few limitations but it will serve the purpose.
Conclusion:
Using a distributed version control system is definitely beneficial and it is a boon for the developer teams. Using Git has definitely reduced the amount of time in managing the repos and also increased the productivity. Further, in this article, we have also looked into different options of undoing the work that has been committed to the local systems.
Git also provides an option to rewrite the history. This option should be not utilized frequently and should be used only when it is really needed.
We hope you have enjoyed reading this article and if you are looking for any specific training, then please get in touch with us and we will be able to help you.

.svg&w=750&q=75)
Stay updated with our newsletter, packed with Tutorials, Interview Questions, How-to's, Tips & Tricks, Latest Trends & Updates, and more ➤ Straight to your inbox!
| Name | Dates | |
|---|---|---|
| Git Training | Apr 27 to May 12 | View Details |
| Git Training | Apr 30 to May 15 | View Details |
| Git Training | May 04 to May 19 | View Details |
| Git Training | May 07 to May 22 | View Details |


Priyanka Vatsa is a Senior Content writer with more than five years’ worth of experience in writing for Mindmajix on various IT platforms such as Palo Alto Networks, Microsoft Dynamics 365, Siebel, CCNA, Git, and Nodejs. She was involved in projects on these technologies in the past, and now, she regularly produces content on them. Reach out to her via LinkedIn and Twitter.




Copyright © 2013 - 2024 MindMajix Technologies