- About QlikView Scripting & Qlikview Hidden Scripts
- QlikView Circular Reference
- OLE DB/ ODBC Connection to Qlikview Data Sources
- Best Practices for Data modelling in QlikView
- Definition And Advantages of QVDs in QlikView
- How to Fix Circular References & Remove Synthetic Tables
- Concatenating Two Tables in QlikView
- Creating Data Islands in QlikView using Data Source
- Optimize QlikView Application User Interface
- Learn SET Analysis Syntaxes, Examples in QlikView
- QlikView Table Viewer - Previews Records
- Process of Incremental Load in QVD QlikView
- QlikView Architecture
- Binary Load in QlikView
- QlikView Bubble Chart
- Intervalmatch Function in Qlikview
- QlikView Interview Questions
- Qlikview Management API
- Qlikview Mapping
- QlikView Metadata
- QlikView Qualify
- QlikView Tutorial
- QlikView vs Qlik Sense
- Color Alerts and Calculated Colors In QlikView Scripting - QlikView
- How Debugging works in QlikView Script Debugger
- Rename Field and Qualify in Qlikview
- Script Editor Features and Commands in QlikView
- Script Expressions & Quotation marks in Qlikview
- Qlikview Scripting Features and Functions
- Star schema and Snowflake schema in QlikView
- Synthetic keys in QlikView
- Table Viewer in QlikView
DATA TRANSFORMATIONS IN FLAT FILES
Data Transformation is the process of modifying the existing data to a new data format. It can also involve filtering out or adding some specific values to the existing data set. QlikView can carry out data transformation after reading it to its memory and using many built in functions.
Original data have been rarely in a state such that it can be used directly in QlikView without any modification. QlikView is powerful enough to allow modification of data when the data sources are flat files such as Excel or text files.
If you would like to become a Qlik Sense Certified professional, then visit Mindmajix - A Global online training platform:" Qlik Sense Certification Training Course ". This course will help you to achieve excellence in this domain.
Flat files are common data sources for QlikView documents. Since we can’t always control how the data is formatted and arranged in the flat files, we have plenty of options when it comes to transforming this data into something we can use in our QlikView application. Most of these transformations are executed in the File Wizard: Transform dialog (also referred to as the Transformation Wizard).
This chapter describes the modification of data through the various QlikView transformation functions that can be used with flat files such as Excel, CSV, TXT, XML, or HTML.
WHY DATA TRANSFORMATION?
Flat files are usually not perfectly formatted for use in QlikView; they may contain junk rows, columns, or fields; have blank fields; have repeating columns requiring unwrapping; require rows and columns to be rotated or transposed; or have table types considered to be of cross table or generic types. Fortunately, when connecting to a flat data file, the Transformation Wizard allows you to manipulate the data before loading it into your QlikView document.
This will allow you, as a developer, to finely process the source data and turn it into a clean design, while at the same time keeping an efficient script.
USING THE TRANSFORMATION WIZARD
The Transformation Wizard can be accessed from the Script Editor, when you are connected to a flat file such as a table file. Once you have selected the file, click on the Enable Transformation Step button to start the Transformation Wizard.
REMOVING GARBAGE FROM DATA FILES
Let’s start using the Transformation Wizard by opening an .xls file and removing some of the garbage (unnecessary) rows and columns from the data. Download the Hospital_General_Information_Chap3 .xls spreadsheet (this data is adapted from multiple healthcare and hospital spread sheets publicly available at https:// www.data.gov ):
-
From the Script Editor, navigate to and click on the Data | Table Files button and in the Open Local Files window, navigate to the location of your copy of the Hospital_General_Information_Chap3.xls Excel file. The following screenshot illustrates the data fields of this .xls file:


Related Page: Learn SET Analysis Syntaxes, Examples In QlikView
-
In the File Wizard: Type dialog, leave the default Excel (xls) file type radio button enabled. The tables and header size drop-down fields should remain the same, but choose Embedded Labels in the Labels dropdown.

- Click on the Next button, and then on the Enable Transformation Step button to open the Transformation Wizard. The tab in the wizard is open to Garbage, allowing us to remove junk data. Select the first column header (as we don’t need a revision data column). The column is highlighted. Remove the column by clicking on the Delete Marked button. The first column is removed.
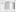
Related Page: Learn SET Analysis Syntaxes, Examples In QlikView
-
If you are not re-using this flat-file again, you could delete the row with the Note: OROVILLE HOSPITAL.. the text in it, by selecting that row header (row 17 in the Transformation Editor window of the previous illustration), and clicking on the Delete Marked button. But a better way to delete this row is to set up a conditional rule, so if the note entry changes often, it will always be deleted upon reload. If you wish to delete all the possible rows marked Note, use the Conditional Delete function as follows:

-
Click on the Conditional Delete button, then enable Compare with value, then select Column 1, contains (or starts with), and enter the word NOTE in capital letters. Select the Case Sensitive checkbox, and click on the Add button. The condition code appears in the textbox. Note that you can add other conditions after clicking on Add, or select a range of rows or other columns or conditions in this dialog as well. Click on OK to make your changes immediately appear in the Transformation Wizard.


USING THE FILL FUNCTION
The Fill function in QlikView is used to fill values from existing fields into a new field.
It allows you to fill in field data from data cells adjoining the target field. In this example, note row 18 (Oroville Hospital – Clinic) has a value TBD for the provider ID column. Assume that we know from the business requirements that all fields marked TBD are for hospitals that are child facilities of the main hospital facilities. Let’s remove any fields marked TBD and replace the value with the value of the field directly above it (in this case, the provider ID of the parent facility).
-
Select the Fill tab in the Transformation Wizard, and click on the Fill button. In the Fill Cells dialog, leave Target Column with the value 1, and click on the Above file type radio button. Click on the Cell Condition button, select is contained in the Cell Value list box, and enter the text TBD in the textbox. Select Case Sensitive so we don’t inadvertently delete any fields that may contain that string in a hospital name. Click on OK in the Cell Condition dialog and then on OK in the Fill Cells dialog as shown in the following screenshot:
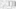
-
Note that both the Oroville Hospital – Clinic and Oroville Hospital – Main rows now have the same provider ID number 050029.
-
Continue filling data fields in the same manner in the blank City and State fields in columns 3 and 4, respectively. Those columns will need to pull in the data from the cell directly below the target field.
UNWRAPPING DATA FROM REPEATING COLUMNS
The Excel file we are using for this example has repeating columns (1 to 4 and 5 to 8). We want to transform this data by moving all the columns from 5 to 8 and appending them to their corresponding columns from 1 to 4. We will accomplish this by using the Unwrap feature of the Transformation Wizard:
-
From the Unwrap tab, move the cursor to the row area between columns 4 and 5 (the end of the first set of rows, ending with column 4, and the beginning of the repeating set of rows starting at column 5). The cursor changes into a vertical line, and a dashed vertical line appears.
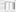
-
Click on the vertical column separator, and the line turns blue. Click on Unwrap, and columns 5 to 8 are appended to columns 1 to 4 at the last column.
-
Clean up the data by removing the second set of column headers, which is now located halfway down the table. Accomplish this by selecting the Garbage tab and clicking on the Conditional Delete button.
-
Click on the Compare with value radio button, then select Column 1, contains, and enter the text Provider. Click on Add, and the condition code is entered in the textbox.
-
Now, set another condition to work within the text condition that you have just set. Select the Range radio button and set the From row as 2 rows from the top (skipping the first row) and the To row as 1 from the bottom. Click on the Select button and leave the default selection scheme as select 1 row at a time, skip no rows.
-
Click on OK and then on Add to add the query code. Click on OK to run these two conditions. The additional column headers are removed, but the first column headers remain untouched.
-
Clean up any blank rows remaining, by using the Garbage tab’s conditional deletion functionality, by deleting empty rows.
-
Once finished cleaning up, click on Next and then on Finish in the Transformation Wizard. Your custom transformation script is inserted into the script pane in the Script Editor. Note that you can always edit the resulting code at any time rather than starting over with the transformation.
Frequently Asked QlikView Interview Questions & Answers
COLUMN MANIPULATION
Column Manipulation is a type of Data Transformation, in which a new column is populated with values from an existing column which meets certain criteria. The criteria can be an expression which is created as part of the Data Transformation step.
Now that we’ve unwrapped the columns, we can further manipulate columns if we want to. Select the Column tab in the Transformation Wizard. In this tab, you can move or copy data from one column to an existing column or a new column. In this example, we will copy the provider ID column (column 1) to a new column we will create using this wizard (column 5). Duplication of columns within QlikView may be useful in building expressions later when designing sheet objects. This may also be done in the script itself by loading the same column twice and renaming the second column with an alias.
-
From the Columns tab, click on the New button. Then Specify cells for new column dialog is displayed:
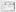
-
In this case, set the Source Column value to 1, and leave Target Column at 0. Setting Target Column to zero automatically creates a new column after any used columns (column 5 is created in this example). Click on the button Cells from these rows to open the Specify Row Condition dialog.
-
Select the All Rows radio button. You could also set this option to move all rows that contain a zero, as all provider IDs start with a zero. Click on Add to create the condition query, and then click on OK. Advanced options are available here as well if you want to delete the source column, or fill in null values with previous field values (in the same column) when moving data. We are not interested in either of those options, so click on OK in the Specify cells for new column dialog.
-
Column 1 (Provider Name) is now copied to the new column 5— even the column header (since we moved all rows as the condition to move). There is now an issue with that, two columns are named identically, so in the next step, we will change the column label for the newly added row.
-
From the Column tab in Transformation Wizard, highlight column 5 (the duplicate Provider Name). Click on the Label button and enter a new name in the textbox, such as Provider Name 2. Click on OK, and the new column name appears in the table pane.
Related Page: Color Alerts And Calculated Colors In QlikView Scripting - QlikView
TRANSFORMATION SCRIPT RESULTS
When you click on Finish in the Transformation Wizard, the script code that is generated appears in the Script Editor.
Note that it’s easier to let the Transformation Wizard generate this code, and if anything needs to be tweaked a bit, such as changing a row position or column label name, it can be done in the script itself.
ROTATING TABLES
The Rotating table in QlikView is similar to the column and the row transpose feature in Microsoft Excel but with some additional options. We can transpose columns in multiple directions and they give different result.
It can be useful in data modeling to rotate a table in any direction or transpose (swap) rows and columns. Let’s try it using the rotate function of the Transformation Wizard. This is very similar to the crosstable function of the Transformation Wizard, but doesn’t allow for aggregation of column data. From the Script Editor, click on the Table Files button and, in the Open Local Files window, navigate to your copy of the file US_Oil_Imports_Chap3. xls Excel file (this file is adapted from the publicly available file at https:// www.data.gov ), and click on Next. The following screenshot illustrates the data fields of this .xls file:

1. In the File Wizard: Type dialog box, choose the Selected_Imports $ tab in the Tables drop-down list (this will select the correct tab in the Excel file), then sets the Header Size value to 1 line (this will remove the table title in row 1). Then, choose Embedded Labels in the Labels drop-down list.
2. Click on Next, and then click on the Enable Transformation Step button. Select the Rotate tab, then click on the Left button to see the table rotate counter clockwise. Click on the Right and the table moves back to the original orientation. In this fashion, you can rotate the table to whichever orientation you think makes sense for your needs. Click on Undo to return the table to the original orientation.
3. With the table in original orientation, click on the Transpose button. The table rows and columns swap positions. This orientation may be useful and is close to the crosstable function discussed in the next section. Click on Next twice and then on Finish to insert your transposition code into the script if desired. The transposed table can also be viewed in the wizard Results table window, just before clicking on Finish. Note that the month dates have now swapped places with the Region and Source key codes. This can be used in limited situations, but crosstable functionality (see the next section) may be more useful, however.
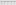
Related Page: How To Optimize QlikView Application User Interface - QlikView
WORKING WITH CROSS TABLES
Cross tables are a common table type that creates problems in aggregation and analysis when trying to use them in the QlikView data model. The US_Oil_Imports_Chap3.xls spreadsheet worked within the preceding rotation exercise as a cross table, because the dates are stored as dimensions and you can’t properly aggregate all month data in the present format. We can convert this table into a normal table with the crosstable function of the Transformation Wizard as follows:
1. In the Script Editor, click on the Table Files button and navigate to the US_Oil_Imports_Chap3. xls Excel file. Click on Next, and then choose the Selected_Imports $ tab in the Tables drop-down list (this will select the correct tab in the Excel file). Then set the Header Size to 1 line (this will remove the table title in row 1). Then, choose Embedded Labels in the Labels drop-down list, and then click on OK.
2. Click on Next twice, and then click on the Crosstable button. In the Crosstable dialog box, select 2 for the Qualifier Fields (since we have 2 rows describing the region dimensions). In the Attribute field, enter the Date (note the color coding of the rows and column areas), and in the Data field, enter Barrels. Click on OK.
3. The Results tab in the Transformation Wizard allows you to view the results of the crosstable function. Note that the dates are now rolled up in one dimension.
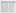
4. Click on Finish, and the code is inserted into the script pane of Script Editor. Note in the code the prefix line of the Load statement, named CrossTable.
Imports:
CrossTable( Date, Barels, 2)
Load * From
C: QlikView_ScriptingUS_Oil_Imports_chap3.xls
(biff, embedded labels, header is 1 lines, table is [Selected_Imports$]);WORKING WITH GENERIC TABLES
Generic tables are very common tables; also called standard tables. These tables have less organization and have many different dimensions and measure units. Each dimension or unit may have its own field. In this example, we will review a scripting solution to create separate tables of each dimension, and then combine the tables into one fact table:
open Generic_Table_Loading_Chap3.qvw. This QlikView application is a prototype tool for tracking software defects (noting software defect groups, priorities, and stages of development). Open the Script Editor and note the inline table load that builds a generic table.
Defect Table:
LOAD * INLINE [
Defect, Group, Priority, Stage
1, Reports, High, Queued
2, Data, Low, Reported
3, Data, High, Closed
4, Object, Medium, Rejected
5, Security, High, Reported
6, System, Medium, Rejected
7, Security, High, Closed
8, Object, Low, Queued
9, Data, Medium, Closed
10, Requirements, Medium, Verified
];
-
Next, note the GENERIC identifier before the LOAD statement that follows the above inline table creation for a resident load of the already loaded DefectTable.
Workflow:
GENERIC LOAD Defect, ‘WorkStep_’ & Stage, ‘x’ RESIDENT DefectTable;-
The effect of generic loading is that many new QlikView tables are created to handle each new dimension (see the following illustration from the Table Viewer):
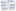
This result may be fine in many circumstances, but one very useful tip is to clean up these tables and concatenate them into one larger fact table. To do this, place this code in the script after the generic load (modify it for your own example):
FOR t = 0 to NoOfTables()
TableList:
LOAD TableName( $( t)) as Tablename
AUTOGENERATE 1
WHERE WildMatch( TableName( $( t)),
‘Workflow.*’);
NEXT t
FOR t=1 to FieldValueCount (‘Tablename’)
LET vTable = FieldValue (‘Tablename’, $ (t));
LEFT JOIN (DefectTable) LOAD * RESIDENT $ (vTable);
DROP TABLE $ (vTable);
NEXT t
DROP TABLE TableList;-
After reloading, access Table Viewer once again, to see the following lone concatenated fact table:

WORKING WITH HIERARCHIES
In Relational database, you must have come across dimensions which has a different level of granularity. When one field/level is correlated or divided into its several other subfields/sublevel for detailed analysis of data, then together all these fields constitute a hierarchy.
Hierarchies are an important part of all business intelligence solutions, used to describe dimensions that naturally contain different levels of granularity. Some are simple and intuitive whereas others are complex and demand a lot of thinking to be modeled correctly. QlikView has its own way of dealing with hierarchies using the hierarchy keyword.
Related Page: How Debugging Works In QlikView Script Debugger
The hierarchy function of QlikView is powerful for creating parent-child relationships between two or more values. A quick example of a hierarchy may be: the Solar System is the parent of the child Sun and Planet, and Planet is the parent of the child Earth. With the hierarchy functions set, QlikView can easily use this data to create tree-view tables.
Let’s consider another example, using a hospital surgery department structure:
-
In QlikView, create a new QlikView document, and click on the Table Files button in Script Editor. Navigate to the QlikView_Scripting folder and open the file Hierachy_Chap3. xls as seen in the following screenshot. This file is a typical adjacent-nodes table that is used in setting up a parent-child relationship in a data model.

-
In the File Wizard: Type dialog, select Sheet1 $ in the Tables drop-down list, None in the Header Size field, and Embedded Labels in the Labels field. Click on Next twice and then on the Hierarchy button to display the Hierarchy Parameters dialog.
-
Set up the parameters in this dialog as shown in the following screenshot. The first three parameters are required, but the rest of them are not (but you will need them to add the tree-view listbox). Note that the Parent Name, Path Name, and Depth Name fields can be named as you like. The Path Delimiter value can of any character ( be sure to add single quotes as seen). To make the path easier to read, add leading and trailing spaces before the character (in this case an asterisk):

-
Click on OK and then on Finish. Your new HIERARCHY load statement appears. Click on Save and then on Reload. In the QlikView sheet, create a new table box with all the child and parent fields in it, and examine the layout.
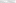
-
Now, set up a tree view listbox on the sheet by selecting Layout | New Sheet Object | List Box from the menu bar, and set up the parameters as in the following illustration. Make note of the with Separator field: it must match exactly what was set up in the HIERARCHY Load statement (in this case, a leading space, asterisk, and a trailing space, but this time with no single quotes):

-
The final result of the tree view listbox for your hierarchy is displayed on the sheet. If it does not work properly, check your Path Delimiter and TreeView Separator values to ensure that they match.
Explore QlikView Sample Resumes! Download & Edit, Get Noticed by Top Employers!Download Now!

.svg&w=750&q=75)
Stay updated with our newsletter, packed with Tutorials, Interview Questions, How-to's, Tips & Tricks, Latest Trends & Updates, and more ➤ Straight to your inbox!
| Name | Dates | |
|---|---|---|
| QlikView Training | Apr 23 to May 08 | View Details |
| QlikView Training | Apr 27 to May 12 | View Details |
| QlikView Training | Apr 30 to May 15 | View Details |
| QlikView Training | May 04 to May 19 | View Details |


Vinod Kasipuri is a seasoned expert in data analytics, holding a master's degree in the field. With a passion for sharing knowledge, he leverages his extensive expertise to craft enlightening articles. Vinod's insightful writings empower readers to delve into the world of data analytics, demystifying complex concepts and offering valuable insights. Through his articles, he invites users to embark on a journey of discovery, equipping them with the skills and knowledge to excel in the realm of data analysis. Reach Vinod at LinkedIn.















Copyright © 2013 - 2024 MindMajix Technologies