
- Cassandra vs MongoDB
- MongoDB Aggregate
- MongoDB Commands
- MongoDB Create Collection
- MongoDB Create Database
- MongoDB Create Index
- MongoDB Docker Container Creation
- MongoDB Find Queries
- Top 7 MongoDB GUI Tools In 2024
- Installation of MongoDB on Windows
- MongoDB Interview Questions and Answers
- MongoDB Port - How to Change MongoDB Default Port
- MongoDB Query With Examples
- MongoDB Show Collections
- Sorting data with MongoDB
- MongoDB Update Document
- MongoDB vs CouchDB
- MongoDB vs DynamoDB
- MongoDB vs Elasticsearch
- MongoDB Vs MySQL - Which Is A Better Database?
- MongoDB vs PostgreSQL
- What is MongoDB?
- MongoDB Projects and Use Cases
- How to Install MongoDB on Windows?
- MongoDB Connection in Java
Regular relational databases stress rigid, flat schemas for a tabular storage format. MongoDB has reduced the strain schemas by building scalable, performance-oriented, and high-availability storage structures. Know more about MongoDB and its architecture.
MongoDB Tutorial - Table of Contents
- Data Modeling in MongoDB
- MongoDB Document Structure
- Types of Data Modeling
- Importance
- Schema Validation
- Create a database
- Drop the database
- Data Types
- Deployment of Database
| If you want to enrich your career and become a professional in MongoDB, then visit MindMajix - a global online training platform: "MongoDB Certification Training" This course will help you to achieve excellence in this domain. |
What is Data Modeling in MongoDB?
Data Modeling is a process of balancing the requirements of an application and we need to make sure the performance of data modeling is highly effective. MongoDB deals with documents, fields, and collections.
Flexible Schema: The major part of any relational database is a schema. JSON is used as a lightweight encoded string to store data in VoltDB. The following is an example to create a table:
CREATE TABLE employee_session_table (
username VARCHAR(100) UNIQUE NOT NULL,
password VARCHAR(50) NOT NULL,
employee_session_id VARCHAR(100) ASSUME UNIQUE NOT NULL,
last_logout_time TIMESTAMP,
session_info VARCHAR(2048)
);
PARTITION TABLE employee_session_table ON COLUMN username and password;
MongoDB Document Structure
There are two ways to establish the relationships between the data in MongoDB:
- Referenced Documents
- Embedded Documents
1. Referenced Documents
The relationship between one data to the other is stored in the Reference documents. The reference to the data of one collection is used to collect the data between the other collections. The normalized data models resolve these references to access the related data. Reference relationships should be used to establish connections. The relationship between documents may be many to many or one to many.
2. Embedded Documents
Embedded documents are denormalized data models that are used to create relationships between data by storing related data to store, retrieve and manipulate data in a single operation in one document structure. Embedded documents should be used when a relationship exists between entities.

[ Learn How to Install MongoDB? ]
Types of Data Modeling
There are mainly three different types of data models:
- Conceptual: This model defines what the system contains and is created by clients and data architects. The aim of using this model is to organize business concepts and define the scope and rules.
- Logical: This model defines how the system should be implemented without DBMS and is created by business analysts and data architects. The aim is to develop data structures and technical map rules.
- Physical: This model defines how the system will be implemented using a particular DBMS system and is created by Database administrators and developers.
1. Conceptual Data Model
The purpose of this model is to establish the entities along with their attributes and relationships. At this level, the actual Database structure is not defined. The following are the three basic elements of a Data Model:
- Relationship: Dependency or association.
- Attribute: Characteristics of an entity.
- Entity: A real-world thing.
For example:
- Product and Customer are 2 entities.
- Product name and product price are attributes of the product entity
- customer name and Customer number are attributes of the Customer entity
- A sales relationship exists between the product and the customer.
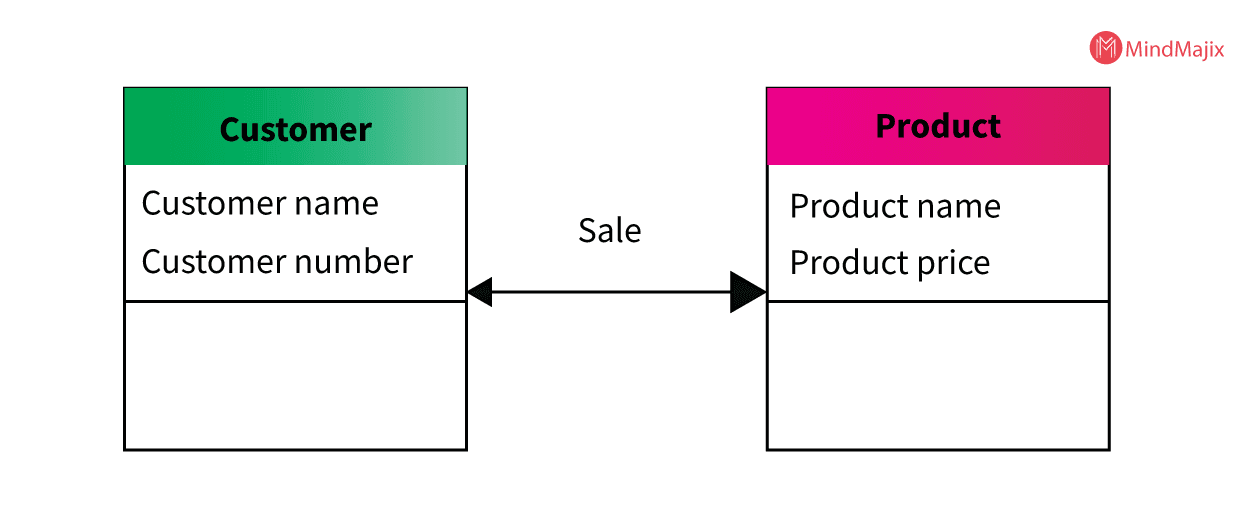
Characteristics of a conceptual data model:
- This type of Data model is designed to offer business concepts to an organization-wide coverage and is developed for the business audience.
- This model is developed independently irrespective of hardware specifications like location, data storage capacity, and software specifications like technology and DBMS vendors.
- The primary focus of this model is to represent data from the user perspective (Real-time)
- This model is also known as the Domain model and it creates a common language for all consumers.
2. Logical Data Model
The purpose of this model is to add additional information to the elements of the conceptual model. This model sets the relationships between the entities and defines the structure of the data elements.
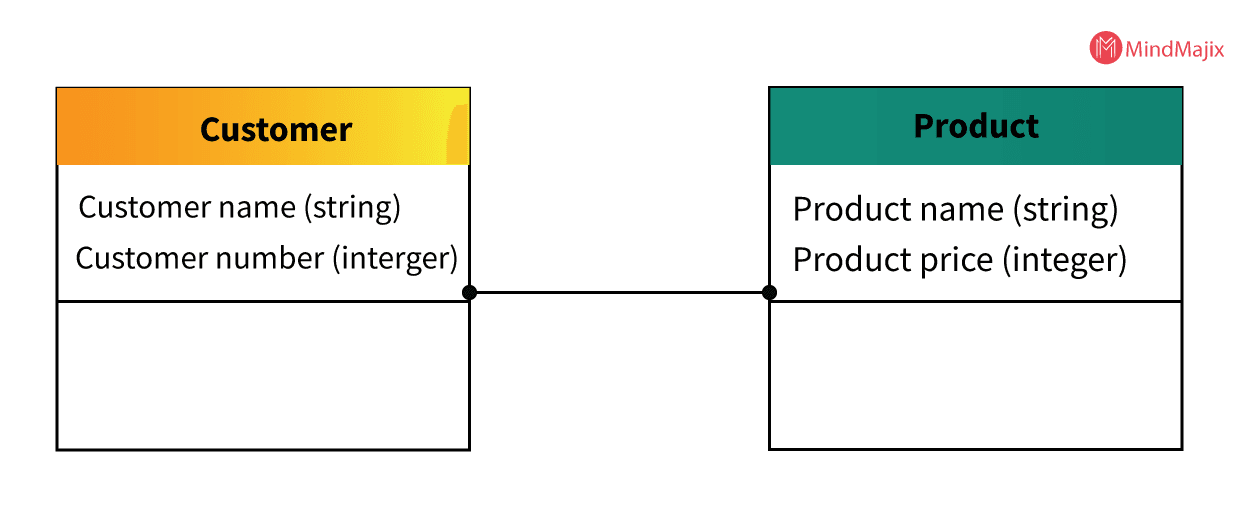
The major advantage of the Logical data model is the modeling structure will always remain generic and provide a foundation to form the base for the Physical model. At this level, we will not define any primary or secondary key but, we have to verify and adjust the connector details of relationships.
Characteristics of a Logical data model:
- This model describes the data required for a single project as integrating the other logical data models is not possible.
- Designed independently from the DBMS and developed by architects.
- Data attributes possess data types with exact length and precision.
- Typically 3NF Normalization is used in this model.
[ Check out How to Sort Data with MongoDB? ]
3. Physical Data Model
The main purpose of this model is to implement a database-specific data model that provides an abstraction of the database to generate a schema. Physical Data Model offers a richness to the meta-data.
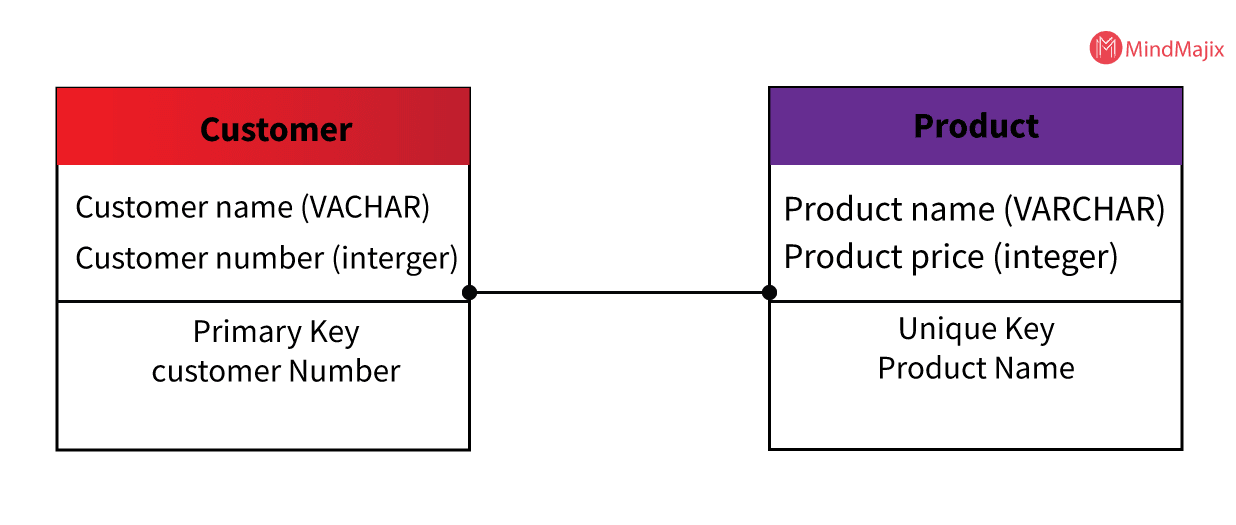
Characteristics of Physical Data Model
- This model helps in visualizing a database structure.
- It helps in modeling the database indexes, constraints, columns keys, triggers, and other features of RDBMS.
MongoDB allows several ways to use tree data structures to model large nested or hierarchical data entities and relationships.

What is the Importance of Data Modeling in MongoDB?
MongoDB has a unique architecture to achieve scalability with ease. The main components of this architecture are its NoSQL database (schema-less) collections and documents. While implementing MongoDB in any application, it is essential to use Data Modelling.
Types of Model Relationships Between Documents
There are mainly three kinds of relationships present in data modeling, and they are as follows
- One-to-One Relationships (Embedded Documents)
- One-to-Many Relationships (Embedded Documents)
- One-to-Many Relationships (Document References).
1. One-to-One Relationships (Embedded Documents): Describe one-to-one relationships between connected data present data in an Embedded Document.
2. One-to-Many Relationships (Embedded Documents): Represents a data model to resemble embedded documents that define one-to-many relationships between connected data.
3. One-to-Many Relationships (Document References): Represents a data model that refers to one-to-many relationships between connected data.
What is Schema Validation?
Schema Validation is an enterprise gateway to check the XML messages conform to the structure and format the message as expected by the Web Service by validating XML Schemas. An XMLSchema briefly defines the attributes and elements that contain instances of an XML document.
MongoDB offers the capability to perform schema validation during insertions and updates.
Specify Validation Rules
Specific validation rules are on a per-collection basis to create a new collection. The following command is used with the validation option.
1. Query: db.createCollection()
collMod command is used along with the validator option to add document validation to an existing collection.
MongoDB also provides the following related options:
2. Validation level: Determines how strictly the MongoDB applies validation rules to existing documents during an update.
3. Validation action: Determines whether MongoDB rejects documentations that violate the validation rules or not.
4. JSON Schema: MongoDB supports JSON Schema validation which uses $jsonSchema operator in your validator expression for performing schema validation.
Example: Shows validation rules using JSON schema:
copy
copied
db.createCollection("students", {
validator: {
$jsonSchema: {
bsonType: "object",
required: [ "name", "year", "major", "address" ],
properties: {
name: {
bsonType: "string",
description: "must be a string and is required"
},
year: {
bsonType: "int",
minimum: 2017,
maximum: 3017,
description: "must be an integer in [ 2017, 3017 ] and is required"
},
major: {
enum: [ "Math", "English", "Computer Science", "History", null ],
description: "can only be one of the enum values and is required"
},
gpa: {
bsonType: [ "double" ],
description: "must be a double if the field exists"
},
address: {
bsonType: "object",
required: [ "city" ],
properties: {
street: {
bsonType: "string",
description: "must be a string if the field exists"
},
city: {
bsonType: "string",
"description": "must be a string and is required"
}
}
}
}
}
}
})For more information, see $jsonSchema.
Query Expressions
In addition to JSON Schema validation, MongoDB supports validation with other query operators.
Example: Shows validatory rules using query expression:
copy
copied
db.createCollection( "contacts",
{ validator: { $or:
[
{ phone: { $type: "string" } },
{ email: { $regex: /@mongodb.com$/ } },
{ status: { $in: [ "Unknown", "Incomplete" ] } }
]
}
} )For further information look for query operators.
[ Related Article: Find Queries in MongoDB ]
Bypass Document Validation
The bypass document validation option is used to bypass document validation. Learn more about the list of commands that support the bypass document validation.
To enable access control for deployments, an authenticated user should have to bypass document validation action. The built-in roles restore and dbAdmin offer these actions.
How to Create a Database in MongoDB?
The creation of a database in MongoDB is very simple. The “Use” command is required to create a database. The following example shows how a database is created. Learn how to create or insert collections.
Syntax:
use [database name]Example: use students
Sample code to insert collections:
db.student.insert
(
{
"studentid" : 1,
"studentName" : "Mani"
}
)[ Learn More About How to Create a Database in MongoDB? ]
How to Drop the Database in MongoDB?
To drop the collections from a database, you need to use the drop() method to delete the database permanently. The following is the program to delete a collection:
Query:
db.dropDatabase()Example:
>show dbs
local 0.78125GB
mydb 0.23012GB
test 0.23012GB
>Dropping a Collection
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
import org.bson.Document;
import com.mongodb.MongoClient;
import com.mongodb.MongoCredential;
public class DropingCollectionSample{
public static void main( String args[] ) {
// declaring Mongo client
MongoDBClient mongo = new MongoDBClient( "localhost" , 22667 );
// Creating MongoDB credentials
MongoDBCredential credential;
credential = MongoDBCredential.createCredential("ExampleUser", "myDb1",
"password".toCharArray());
System.out.println("Establishing the connection successfully completed");
// Accessing collections of the database
MongoDBDatabase database = mongo.getDatabase("myDb");
// printing collections
System.out.println("The collections created successfully");
// Retrieving a collections from the database
MongoDBCollection<Document> collection = database.getCollection("sampleCollection");
// Dropping the Collections
collection.drop();
System.out.println(" the collection have dropped successfully");
}
}On compiling, the above program gives you the following result
Establishing the connection successfully completed
The collections created successfully
the collection has dropped successfully[ Related Article: How to Create MongoDB Collection? ]
Basic Database Operations in MongoDB
To perform a few actions we need the following operations:
Database Commands
There are numerous command-line options available in MongoDB. The following are a few database commands.
Helpers: db.help() -- shows help related information on the database.
Administrative Command Helpers: db.cloneDatabase() -- helps you to clone the current database. Read now to know more about Database commands.
Data Types
MongoDB supports several data types. Some of the most commonly used data types are as follows:
- String: Used to store a chain of characters and must be UTF-8 valid.
- Boolean: Used to store boolean values such as true or false.
- Array: Stores multiple values into a single key.
- Min and Max keys: Used to compare values against higher and lower BJON elements.
- Timestamp: Used for recording data whenever the document is modified.
- Objects: This data type used to store embedded documents
- Regular expressions: Data type is used to store regular expressions.
1. Query Documents
Query method is used to read the documents from the collections. The following query will help you fetch data from the collections. Read an article on query collections.
Query:
db.collection.find(<query filter>, <projection>)Example:
db.users.insertMany(
[
{
_id: 001,
name: "mai",
age: 21,
type: 2,
status: "A",
favorites: { games: "PUBG", food: "Burger" },
finished: [ 12, 13 ],
badges: [ "green", "blue" ],
points: [
{ points: 75, bonus: 10 },
{ points: 65, bonus: 20 }
]
},
)2. Update Document
The update method is used to update a particular field within a document or completely modify the document. By default update command updates only a single document where the syntactical update command will update multiple. Learn more about the update query. The following query will help you update the parameters.
Query:
db. collection.update( query, update, options)Example:
db.collection.update(
,
,
{
upsert: ,
multi: ,
writeConcern: ,
collation:
}
)[ Learn More About MongoDB Update Document ]
3. Delete Documents
The remove() method is used to delete a document from the collections. remove() accept the following methods.
- justone - only one document is removed when setting the value as 1 or true.
- deletion criteria − According to the option the documents will be removed.
Query:
db.COLLECTION_NAME.remove(DELLETION_CRITTERIA)Example:
{ "_id" : ObjectId(59854746781331adf45ec5), "title":"Overview"}
{ "_id" : ObjectId(59576445761331adf45ec6), "title":"NoSQL"}
{ "_id" : ObjectId(59547346781331adf45ec7), "title":"MongoDB"}
db.mycol.remove({'title':'MongoDB Overview'})
>db.mycol.find()
{ "_id" : ObjectId(59854746781331adf45ec6), "title":"NoSQL"}
{ "_id" : ObjectId(59576445761331adf45ec7), "title":"MongoDB"}4. Limiting Records
This method is used to limit the records in MongoDB and only one type of number argument. The following query will help in limiting the records.
Query:
db.COLLECTION_NAME.find().limit(NUMBER)Example:
{ "_id" : ObjectId(59467344351331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(59835645781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(59467344351331adf45ec7), "title":"MongoDB"}
db.mycol.find({},{"title":1,_id:0}).limit(2)
{"title":"Overview"}
{"title":"NoSQL"}5. Aggregation
It is the simplest form of operation on documents to compute the result. Aggregation is a function that enables to manipulate data returned queries.
Query:
db.AggregationCollection.aggregate([ {}, {}]) Example:
use ExampleAggregationDB
db.createCollection(“AggregationExample”)
db.AggregationCollection.insertMany([
{ _id: ObjectId('01246564512'), title: 'DragonStone', description: 'GOT Season 7 Episode 1', directed_by: 'Matt Shakman', tags: ['drogon', 'danerys'], likes: 100 },
{ _id: ObjectId('012564567913'), title: 'Stormborn', description: 'GOT Season 7 Episode 2', directed_by: 'Matt Shakman', tags: ['jon', 'sansa'], likes: 10 },
])6. Replication
Replication is the process of synchronizing data across several servers and protects from data loss. A replica is a set of MongoDB instances that host a similar database.
Query:
rs.add(HOST_NAME:PORT)Example:
rs.add("mongod1.net:20717")7. Sharding
It is the process of storing data across multiple machines as a single machine might not be sufficient to store data. The following are the three main components of Sharding.
- Shards − These are used to store data and provide high availability with data consistency.
- Config Servers − Config servers store the cluster's metadata. Sharded clusters have exactly 3 config servers.
- Query Routers − Query routers are basically mongo instances that interface with client applications and direct operations to the appropriate shard.
8. Create Backup for Database
You need to use a command-line interface called mongodump to create a backup. The following command is used to create a backup of a database ~/backups/first_backup.
Query:
$ mongodump -d myDatabase -o ~/backups/first_backupOutput: The backfile of myDatabase appears:
2019-01-24T18:11:58.590-0500 writing myDatabase.myCollection to /home/me/backups/first_backup/myDatabase/myCollection.bson
2019-01-24T18:11:58.591-0500 writing myDatabase.myCollection metadata to /home/me/backups/first_backup/myDatabase/myCollection.metadata.json
2019-01-24T18:11:58.592-0500 done dumping myDatabase.myCollection (3 documents)
2019-01-24T18:11:58.592-0500 writing myDatabase.system.indexes to /home/me/backups/first_backup/myDatabase/system.indexes.bson| Learn Top MongDB Interview Questions and Answers that help you grab high-paying jobs |
Deployment of Database
To monitor your deployment, MongoDB offers the following commands:
- mongostat
- mongotop.
1. Mongostat: This command is used to check the running status of MongoDB instances.
The following command is used to install MongoDB:
- Query: set upmongodbbin>mongostat.
2. Mongotop: This command is used to track the reports to read and write the activity of MongoDB instances on a collection basis.
- Query: set upmongodbbin>mongotop.
- Example: set upmongodbbin>mongotop 30.
This command returns the top 30 rows of less frequent information.
Conclusion
MongoDB is one of the most popular NoSQL databases and its popularity has been increasing exponentially over the years. Many developers have started using it in various applications. Many organizations have been adopting MongoDB as an architectural component to build a solid foundation of data Modelling to find their solutions.
The first step in utilizing any database (be it both rational or NoSQL) is Data Modelling. It represents the process of creating a database design repeatedly to meet the application requirements.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| MongoDB Training | Jul 05 to Jul 20 | View Details |
| MongoDB Training | Jul 08 to Jul 23 | View Details |
| MongoDB Training | Jul 12 to Jul 27 | View Details |
| MongoDB Training | Jul 15 to Jul 30 | View Details |

Vaishnavi Putcha was born and brought up in Hyderabad. She works for Mindmajix e-learning website and is passionate about writing blogs and articles on new technologies such as Artificial intelligence, cryptography, Data science, and innovations in software and, so, took up a profession as a Content contributor at Mindmajix. She holds a Master's degree in Computer Science from VITS. Follow her on LinkedIn.


