- Home
- Blog
- Apache Storm
- Apache Storm Tutorial

This tutorial gives you an overview and talks about the fundamentals of Apache Storm.
The storm is a distributed, reliable, fault-tolerant system for processing streams of data. The work is delegated to different types of components that are each responsible for a simple specific processing task. The input stream of a Storm cluster is handled by a component called a spout. The spout passes the data to a component called a bolt, which transforms it in some way. A bolt either persists the data in some sort of storage, or passes it to some other bolt. You can imagine a Storm cluster as a chain of bolt components that each make some kind of transformation on the data exposed by the spout.
To illustrate this concept, here’s a simple example. Last night I was watching the news when the announcers started talking about politicians and their positions on various topics. They kept repeating different names, and I wondered if each name was mentioned an equal number of times, or if there was a bias in the number of mentions.
Imagine the subtitles of what the announcers were saying as your input stream of data. You could have a spout that reads this input from a file (or a socket, via HTTP, or some other method). As lines of text arrive, the spout hands them to a bolt that separates lines of text into words. This stream of words is passed to another bolt that compares each word to a predefined list of politician’s names. With each match, the second bolt increases a counter for that name in a database. Whenever you want to see the results, you just query that database, which is updated in real-time as data arrives. The arrangement of all the components (spouts and bolts) and their connections is called a topology.
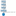
Figure:- A simple topology
Now imagine easily defining the level of parallelism for each bolt and spout across the whole cluster so you can scale your topology indefinitely. Amazing, right? Although this is a simple example, you can see how powerful Storm can be.
| Enthusiastic about exploring the skill set of Apache Storm? Then, have a look at the Apache Storm Training together with additional knowledge. |
Apache Storm Tutorial for Beginners
1)Storm was open-sourced by Twitter in September of 2011 and has since been adopted by numerous companies around the world. Storm provides a small set of simple, easy-to-understand primitives. These primitives can be used to solve a stunning number of real-time computation problems, from stream processing to continuous computation to distributed RPC
2) To understand the parallelism of storm topology, Storm distinguishes between the following three main entities that are used to actually run a topology in a Storm cluster: Worker processes, Executors (threads), Tasks
3) A worker process executes a subset of a topology. A worker process belongs to a specific topology and may run one or more executors for one or more components (spouts or bolts) of this topology. A running topology consists of many such processes running on many machines within a Storm cluster.
4) An executor is a thread that is spawned by a worker process. It may run one or more tasks for the same component (spout or bolt).
5) A task performs the actual data processing — each spout or bolt that you implement in your code executes as many tasks across the cluster. The number of tasks for a component is always the same throughout the lifetime of a topology, but the number of executors (threads) for a component can change over time. This means that the following condition holds true: #threads ≤ #tasks. By default, the number of tasks is set to be the same as the number of executors, i.e. Storm will run one task per thread.
6) The core data model in Trident is the “Stream”, processed as a series of batches. A stream is partitioned among the nodes in the cluster, and operations applied to a stream are applied in parallel across each partition.
7) There are five kinds of operations in Trident:
- Operations that apply locally to each partition and cause no network transfer
- Repartitioning operations that repartition a stream but otherwise don’t change the contents (involves network transfer)
- Aggregation operations that do network transfer as part of the operation
- Operations on grouped streams
- Merges and joins

8) By default, Storm can serialize primitive types, strings, byte arrays, ArrayList, HashMap, HashSet, and the Closure collection types. If you want to use another type in your tuples, you’ll need to register a custom serializer. Well much more in-depth about custom serialization, java serialization is explained during Storm training sessions
What are some typical use cases for Storm?
- Processing streams
- As demonstrated in the preceding example, unlike other stream processing systems, with Storm there’s no need for intermediate queues.
- Continuous computation
- Send data to clients continuously so they can update and show results in real-time, such as site metrics.
- Distributed remote procedure call
- Easily parallelize CPU-intensive operations.
The Components Of Storm
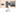
Figure:- Apache Storm Technical Architecture
In a Storm cluster, nodes are organized into a master node that runs continuously.
There are two kinds of nodes in a Storm cluster: master node and worker nodes. The master node runs a daemon called Nimbus, which is responsible for distributing code around the cluster, assigning tasks to each worker node, and monitoring for failures. Worker nodes run a daemon called Supervisor, which executes a portion of a topology. A topology in Storm runs across many worker nodes on different machines.
Since Storm keeps all cluster states either in Zookeeper or on the local disk, the daemons are stateless and can fail or restart without affecting the health of the system

Figure:- A Storm cluster’s architecture
A Storm cluster follows a master-slave model where the master and slave processes are coordinated through ZooKeeper. The following are the components of a Storm cluster.
Nimbus
The Nimbus node is the master in a Storm cluster. It is responsible for distributing the application code across various worker nodes, assigning tasks to different machines, monitoring tasks for any failures, and restarting them as and when required.
| Related Article: Apache Storm Interview Questions and Answers |
Nimbus is stateless and stores all of its data in ZooKeeper. There is a single Nimbus node in a Storm cluster. It is designed to be fail-fast, so when Nimbus dies, it can be restarted without having any effects on the already running tasks on the worker nodes. This is unlike Hadoop, where if the JobTracker dies, all the running jobs are left in an inconsistent state and need to be executed again.
Supervisor nodes
Supervisor nodes are the worker nodes in a Storm cluster. Each supervisor node runs a supervisor daemon that is responsible for creating, starting, and stopping worker processes to execute the tasks assigned to that node. Like Nimbus, a supervisor daemon is also fail-fast and stores all of its states in ZooKeeper so that it can be restarted without any state loss. A single supervisor daemon normally handles multiple worker processes running on that machine.
The ZooKeeper cluster
In any distributed application, various processes need to coordinate with each other and share some configuration information. ZooKeeper is an application that provides all these services in a reliable manner. Being a distributed application, Storm also uses a ZooKeeper cluster to coordinate various processes. All of the states associated with the cluster and the various tasks submitted to the Storm are stored in ZooKeeper. Nimbus and supervisor nodes do not communicate directly with each other but through ZooKeeper. As all data is stored in ZooKeeper, both Nimbus and the supervisor daemons can be killed abruptly without adversely affecting the cluster.
And here are the important high-level components that we have in each Supervisor node.
1. Topology – Topology, in simple terms, is a graph of computation. Each node in a topology contains processing logic, and links between nodes indicate how data should be passed around between nodes. A Topology typically runs distributively on multiple workers processes on multiple worker nodes.
2. Spout – A Topology starts with a spout, source of streams. A stream is made of an unbounded sequence of tuples. A spout may read tuples off a messaging framework and emit them as a stream of messages or it may connect to Twitter API and emit a stream of tweets.
In the above technical architecture diagram, a topology is shown with two spouts (source of streams).
3. Bolt – A-Bolt represents a node in a topology. It defines the smallest processing logic within a topology. The output of a bolt can be fed into another bolt as input in a topology.
In the above technical architecture diagram, a topology is shown with five bolts to process the data coming from two spouts.
Underneath, Storm makes use of zeromq (0mq, ZEROMQ), an advanced, embeddable networking library that provides wonderful features that make Storm possible. Let’s list some characteristics of zeromq:
- Socket library that acts as a concurrency framework
- Faster than TCP, for clustered products and supercomputing
- Carries messages across inproc, IPC, TCP, and multicast
- Asynch I/O for scalable multicore message-passing apps
- Connect N-to-N via fanout, pubsub, pipeline, request-reply
- Storm uses only push/pull sockets.
Features of Storm
The following are some of the features of Storm that make it a perfect solution to process streams of data in real-time:
a) Fast: Storm has been reported to process up to 1 million tuples per second per node.
b) Horizontally scalable: Being fast is a necessary feature to build a high volume/velocity data processing platform, but a single node will have an upper limit on the number of events that it can process per second. A node represents a single machine in your setup that executes Storm applications. Storm, being a distributed platform, allows you to add more nodes to your Storm cluster and increase the processing capacity of your application. Also, it is linearly scalable, which means that you can double the processing capacity by doubling the nodes.
c) Fault-tolerant: Units of work are executed by worker processes in a Storm cluster. When a worker dies, Storm will restart that worker, and if the node on which the worker is running dies, Storm will restart that work on some other node in the cluster. The descriptions of the worker process are mentioned in theConfiguring the parallelism of a topology section of, Setting Up a Storm Cluster.
d) Guaranteed data processing: Storm provides strong guarantees that each message passed on to it to process will be processed at least once. In the event of failures, Storm will replay the lost tuples. Also, it can be configured so that each message will be processed only once.
e) Easy to operate: Storm is simple to deploy and manage. Once the cluster is deployed, it requires little maintenance.
f) Programming language agnostic: Even though the Storm platform runs on Java Virtual Machine, the applications that run over it can be written in any programming language that can read and write to standard input and output streams.
The Properties of Storm
Within all these design concepts and decisions, there are some really nice properties that make Storm unique.
Simple to the program: If you’ve ever tried doing real-time processing from scratch, you’ll understand how painful it can become. With Storm, complexity is dramatically reduced.
Support for multiple programming languages: It’s easier to develop in a JVM-based language, but Storm supports any language as long as you use or implement a small intermediary library.
Fault-tolerant: The Storm cluster takes care of workers going down, reassigning tasks when necessary.
Scalable: All you need to do in order to scale is add more machines to the cluster. The storm will reassign tasks to new machines as they become available.
Reliable: All messages are guaranteed to be processed at least once. If there are errors, messages might be processed more than once, but you’ll never lose any message.
Fast: Speed was one of the key factors driving Storm’s design.
Transactional: You can get exactly-once messaging semantics for pretty much any computation.
| Explore Apache Storm Sample Resumes! Download & Edit, Get Noticed by Top Employers! |
The Storm data model
The basic unit of data that can be processed by a Storm application is called a tuple. Each tuple consists of a predefined list of fields. The value of each field can be a byte, char, integer, long, float, double, Boolean, or byte array. The storm also provides an API to define your own data types, which can be serialized as fields in a tuple.
A tuple is dynamically typed, that is, you just need to define the names of the fields in a tuple and not their data type. The choice of dynamic typing helps to simplify the API and makes it easy to use. Also, since a processing unit in Storm can process multiple types of tuples, it’s not practical to declare field types.
Each of the fields in a tuple can be accessed by its name getValueByField(String) or its positional index getValue(int) in the tuple. Tuples also provide convenient methods such asgetIntegerByField(String)that save you from typecasting the objects. For example, if you have aFraction(numerator, denominator) tuple, representing fractional numbers, then you can get the value of the numerator by either using getIntegerByField(“numerator”) or getInteger(0).
We have compiled few more articles for you to refer to. These and many more topics are explained in-depth during Storm training.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Apache Storm Training | Jul 18 to Aug 02 | View Details |
| Apache Storm Training | Jul 21 to Aug 05 | View Details |
| Apache Storm Training | Jul 25 to Aug 09 | View Details |
| Apache Storm Training | Jul 28 to Aug 12 | View Details |

Although from a small-town, Himanshika dreams big to accomplish varying goals. Working in the content writing industry for more than 5 years now, she has acquired enough experience while catering to several niches and domains. Currently working on her technical writing skills with Mindmajix, Himanshika is looking forward to explore the diversity of the IT industry. You can reach out to her on LinkedIn.














