- Home
- Blog
- Technology Comparisons
- Hive Vs Impala

Are you a developer or a data scientist, and searching for the latest technology to collect data? Well, If so, Hive and Impala might be something that you should consider. Hive is a data warehouse software project, which can help you in collecting data. Similarly, Impala is a parallel processing query search engine which is used to handle huge data.
If you want to know more about them, then have a look below:-
What are Hive and Impala?
Hive, a data warehouse system is used for analysing structured data. It’s was developed by Facebook and has a build-up on the top of Hadoop. Using this data warehouse system, one can read, write, manage the large datasets which reside amidst the distributed storage.
Hive as related to its usage runs SQL like the queries. These queries are called as HQL or the Hive Query Language which further gets internally a conversion to MapReduce jobs. One can easily skip through the traditional approach of writing MapReduce programs which can be complex at times, just by the right usage of Hive. Data Definition Language, Data Manipulation Language, User Defined language, are all supported by Hive.
On the other hand, when we look for Impala, it’s a software tool which is known as a query engine. Its software tool has been licensed by Apache and it runs on the platform of open-source Apache Hadoop big data analytics.
One can use Impala for analysing and processing of the stored data within the database of Hadoop. Impala is also called as Massive Parallel processing (MPP), SQL which uses Apache Hadoop to run. It supports databases like HDFS Apache, HBase storage and Amazon S3.
Talking about its performance, it is comparatively better than the other SQL engines. Although the latency of this software tool is low and neither is it based upon the principle of MapReduce.
As on today, Hadoop uses both Impala and Apache Hive as its key parts for storing, analysing and processing of the data.
Checkout Hadoop Interview Questions
Advantages of using Impala:
- The data in HDFS can be made accessible by using impala. Moreover, the speed of accessibility is as fast as nothing else with the old SQL knowledge.
- Data is processed where it is located, i.e. on Hadoop cluster; therefore, with Impala there rises no need for data movement and data transformation for storing data on Hadoop,
- You do not need the knowledge of Java for accessing the data in HDFS, Amazon s3, and HBase. However, a basic knowledge of SQL queries can do the work.
- Impala uses the Parquet format of a file. It is columnar storage and is very efficient for the queries of large-scale data warehouse scenarios. It is not possible in other SQL query engines..
- Data must pass through the extract-transform-load (ETL) cycle if the programmers want to embed the queries into the business tools. But, Impala shortens this procedure and makes the task more efficient. Thus, loading & reorganizing of data can be totally eradicated by the new methods like exploratory data analysis & data discovery. In this way, the speed of the process can be increased.
Advantages of Hive:
- Hive offers an enormous variety of benefits. The most important is in the field of data querying, analysis, and summarization. It is mostly designed for developers so that they can have better productivity. The cost of latency with Hive increases, but when the subject of concern becomes efficient, the resulting graph gives a fall.
- There is a huge variety of user-defined functions, which Hive provides so that they can be linked with different Hadoop packages like Apache Mahout, RHipe, etc. It is a boon for developers as it can help them in solving complex analytical problems; moreover, it also helps them in processing the multiple data formats.
- There are numerous processes that hive includes to provide beneficial and important information like cleansing, modeling and transforming for various business aspects. This information can help organizations in elevating their profits. Hive is very popular in the market and is getting adapted by most of the technicians so fast as it is very user-friendly. Therefore, it makes the tedious job of developers easy and helps them in completing critical tasks.
- It lets its users, i.e. the developer, to access the stored data while improving the response time. Hive’s response time is found to be the least as compared to all the other technology which works on huge data sets.

Differences in Overall Features:
- Impala is different from Hive; more precisely, it is a little bit better than Hive. It supports parallel processing, unlike Hive. For huge and immense processes, a system sometimes splits a task into several segments, and thereafter, assigns them to a different processor.
- However, with Hive scalability, security and flexibility of a system or code increase as it makes the use of map-reduce support. Moreover, this is the only reason that Hive supports complex programs, whereas Impala can’t.
- The very basic difference between them is their root technology. Hive is built with Java, whereas Impala is built on C++.
- Impala supports Kerberos Authentication, a security support system of Hadoop, unlike Hive.
Finally, who could use them?
- Data engineers mostly prefer the Hive as it makes their work easier, and hence provides them support. However, when the subject of concern and discussion come towards Impala, Data Analyst/Data Scientists shows more interest as compared to other engineers and researchers.
How they process data:
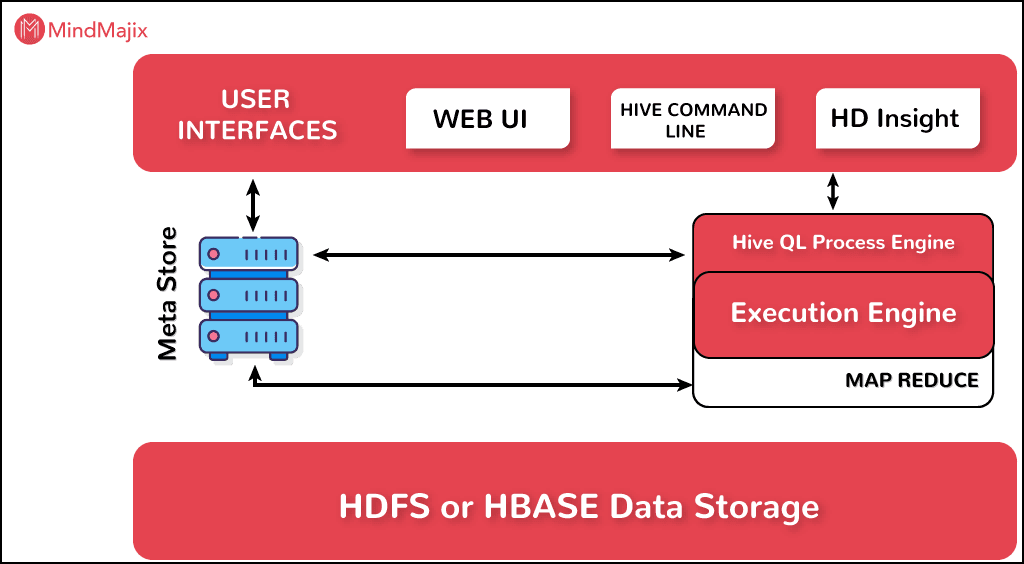
How Hive process data:
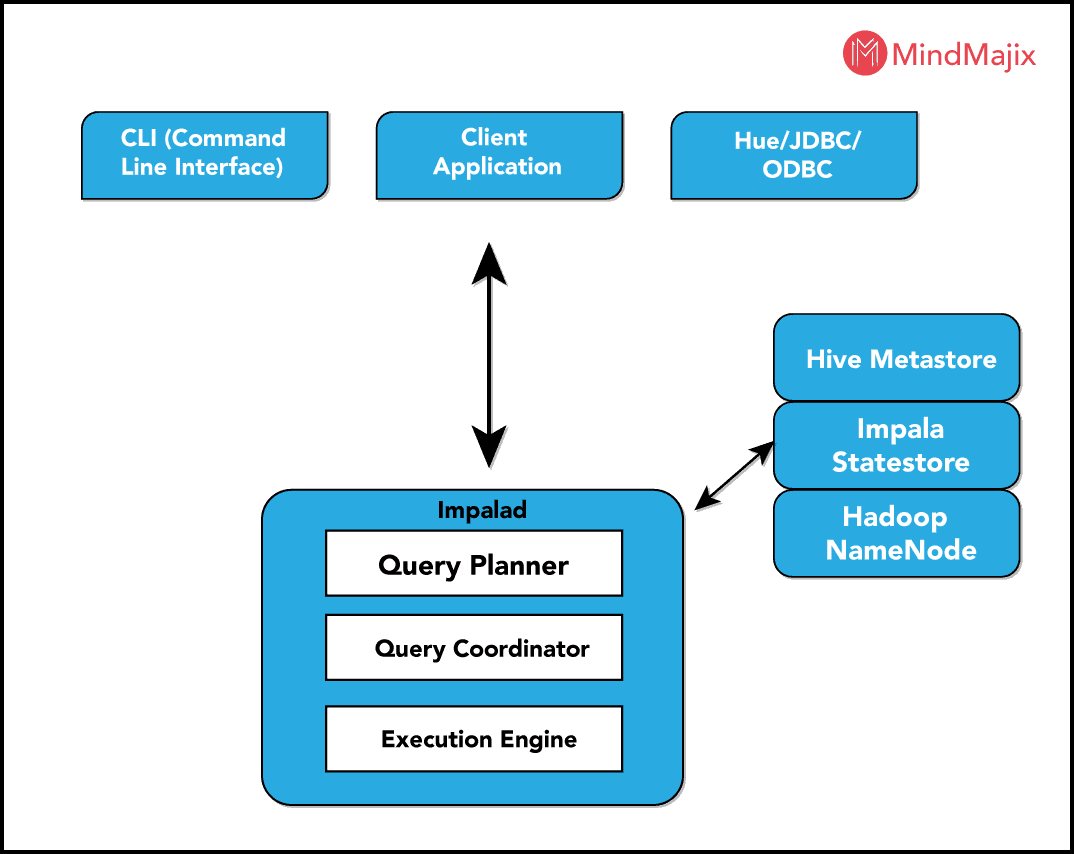
How Impala process data:
The person using Hive can limit the accessibility of the query resources. For example, who can use the query resource, and how much they can make the use of the Hive; moreover, even the speed of Hive response can be managed. Therefore, this is how it could manage the data, and reduce the workload. Through this parallel query execution can be improved and therefore, query performance can be improved.
However, when it comes to the Impala, it splits the task into different segments, these segments are assigned to the different microprocessors and therefore, the execution of tasks is done faster.
Guide for users to initiate Hive and Impala start:
User can start Impala with the command line by using the following code:-
$ sudo service impala-state-store start
$ sudo service impala-catalog start
$ sudo service impala-server startHere the first line starts the state store service, which is followed by the line that starts the catalog service, and finally, the last line starts the Impala daemon services.
Moreover, to start the Hive, users must download the required software on their PCs.
Thereafter, write the following code in your command line.
$ tar -xzvf hive-x.y.z.tar.gzThe above-mentioned code would let you download the most recent release of the Hive version, and the following code would let you set the environment variable HIVE_HOME
$ cd hive-x.y.z
$ export HIVE_HOME={{pwd}}However, for starting Hive on Cloudera, one needs to get the setup of cloudera CDH3. Setting up any software is quite easy. You can simply visit any youtube link to understand how to set it up. Now as you have downloaded it, you would find a button mentioning play Virtual Machine. After clicking on it, you would be redirected to a login page. Login with the user id, Cloudera, and use the login id, i.e. Cloudera as the password. Now open the command line on your pc or laptop. And run the following code:-
Sudo su
If it asks for password, type:- cloudera
Now run the following code:-
root@cloudera-vm:/home/cloudera# > cd /usr/lib/hive/conf/
root@cloudera-vm:/home/cloudera# > sudo gedit hive-site.xmNow enter into the Hive shell by the command, sudo hive.
Now you can start to run your hive queries.
Architectures:
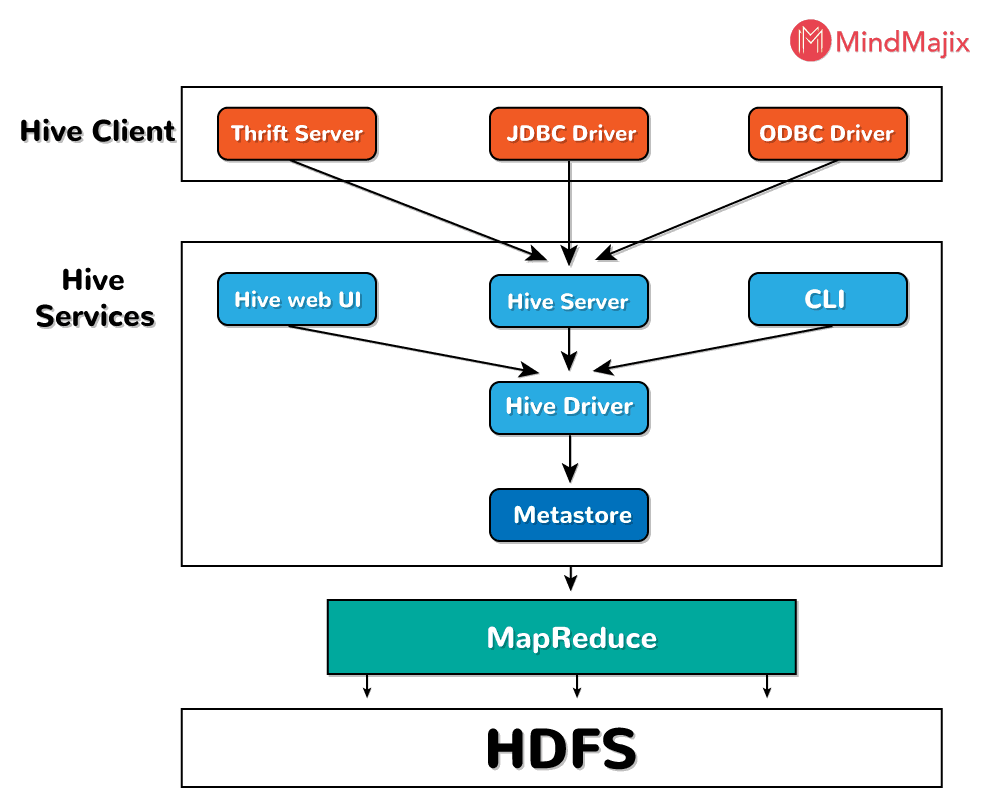
Hive comprises several components, one of them is the user interface. Hive is such software with which one can link the interactional channel between HDFS and user. Hive supports Hive Web UI, which is a user interface and is very efficient.
Now, there is a meta store, when there arises a task, the drivers check the query and syntax with the query compiler. The main function of the query compiler is to parse the query. Thereafter the compiler presents a request to metastore for metadata, which when approved the metadata is sent.
Then there is this HiveQL process Engine which is more or less similar to the SQL. In other words, it is a replacement of the MapReduce program.
The architecture of Impala is very simple, unlike Hive. Impala comprises of three following main components:-
- Impala daemon
- Impala state store
- Impala metadata or metastore.
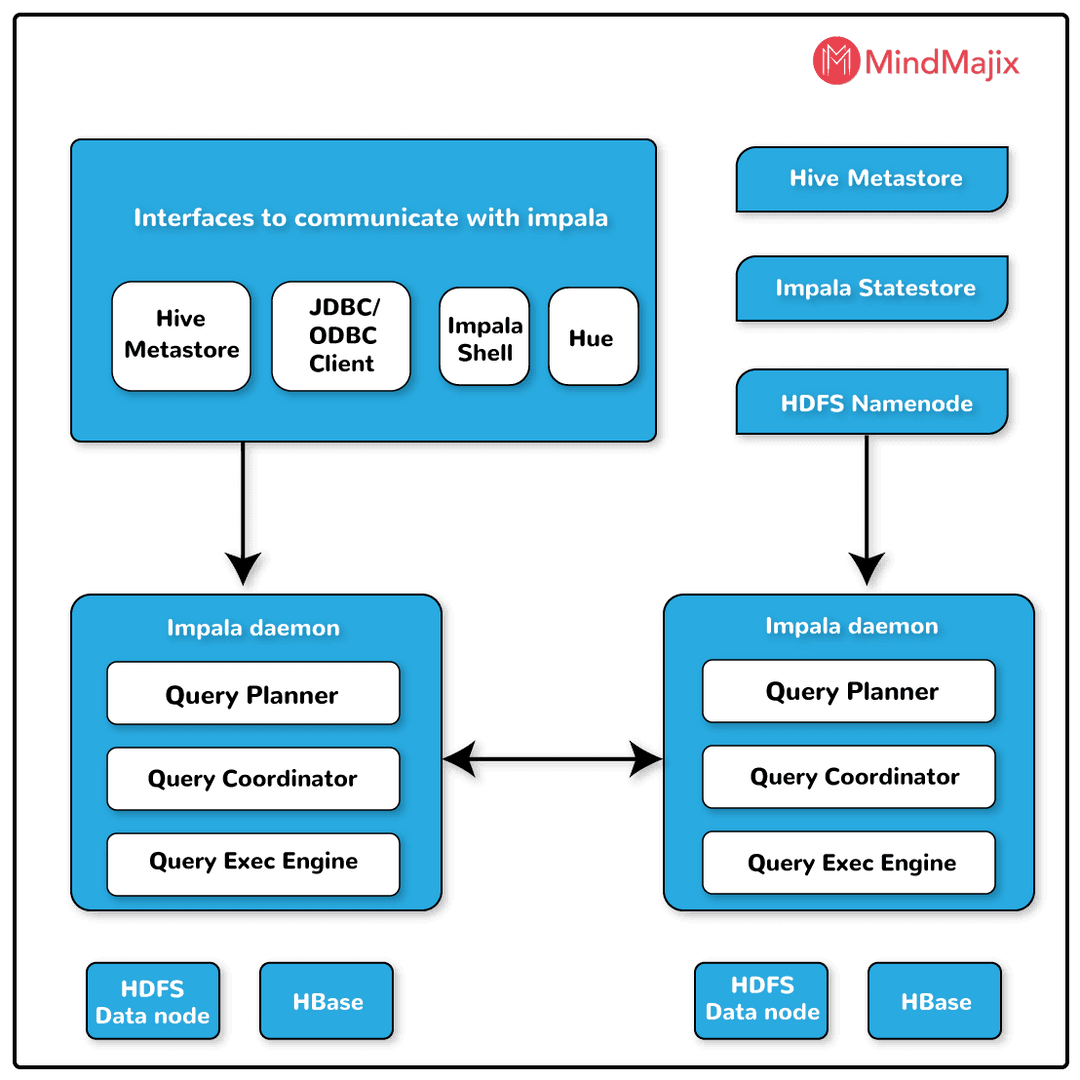
The first part, takes the queries from the hue browser, impala-shell etc. thereafter it processes the tasks and the queries which were sent to them. Therefore, it can be considered that this is the part where the operation heads start. Now the operation continues to the second part, i.e. the Impala state store. It is responsible for regulating the health of Impalads.
Furthermore, the operation continues to the final part, i.e. the Impala metadata or meta store. It uses the traditional way of storing the data, i.e. table definitions, by using MySQL and PostgreSQL. The primary details like columns
Conclusion:
So, now we can wrap up the whole article on one point that Impala is more efficient when it comes to handling and processing data. This is the era of data; from the marketing companies to IT companies all are trying to compete to have a better organization of data. Moreover, the one who gets it done becomes the king of the market.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Hadoop Training | Aug 01 to Aug 16 | View Details |
| Hadoop Training | Aug 04 to Aug 19 | View Details |
| Hadoop Training | Aug 08 to Aug 23 | View Details |
| Hadoop Training | Aug 11 to Aug 26 | View Details |

Ravindra Savaram is a Technical Lead at Mindmajix.com. His passion lies in writing articles on the most popular IT platforms including Machine learning, DevOps, Data Science, Artificial Intelligence, RPA, Deep Learning, and so on. You can stay up to date on all these technologies by following him on LinkedIn and Twitter.














