- Home
- Blog
- Apche Cassandra
- Apache Cassandra Architecture Overview

- Apache Hive - Internal and External Tables
- Cassandra Interview Questions
- Cassandra Tutorial
- Apache Cassandra - Data Model Best Practices
- Apache Cassandra Data Security Management
- How to Backup and Restore in Cassandra Using Multi-Data Center
- Migrating Data From RDBMS to Other Database With Cassandra
- Apache Cassandra NoSQL Performance Management / Benchmarks
- What is NoSQL? - NoSQL Databases
- NoSQL Interview Questions and Answers
The design goal of Cassandra is to handle big data workloads across multiple nodes without any single point of failure. Cassandra has peer-to-peer distributed system across its nodes, and data is distributed among all the nodes in a cluster.
- All the nodes in a cluster play the same role. Each node is independent and at the same time interconnected to other nodes.
- Each node in a cluster can accept read and write requests, regardless of where the data is actually located in the cluster.
- When a node goes down, read/write requests can be served from other nodes in the network.
Introduction to Apache Cassandra Architecture
The architecture of Cassandra greatly contributes to its being a database that scales and performs with continuous availability. Rather than using a legacy of RDBMS master-slave or a manual and difficult-to-maintain sharded design, Cassandra has a masterless “ring” distributed architecture that is elegant, and easy to set up and maintain.
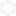
Cassandra sports a masterless “ring” architecture.
In Cassandra, all nodes are the same; there is no concept of a master node, with all nodes communicating with each other via a gossip protocol.
Cassandra’s built-for-scale architecture means that it is capable of handling large amounts of data and thousands of concurrent users/operations per second, across multiple data centers, as easily as it can manage much smaller amounts of data and user traffic. To add more capacity, you simply add new nodes in an online fashion to an existing cluster.
Cassandra’s architecture also means that, unlike other master-slave or sharded systems, it has no single point of failure and therefore offers true continuous availability and uptime.

Architecture layers
| Core Layer | Middle Layer | Top Layer |
| Messaging service | Commit log | Tombstones |
| Gossip Failure detection | Memtable | Hinted handoff |
| Cluster state | SSTable | Read repair |
| Partitioner | Indexes | Bootstrap |
| Replication | Compaction | Monitoring |
| Admin tools |
Key structures
** Node
Where you store your data. It is the basic infrastructure component of Cassandra.
** Data center
A collection of related nodes. A data center can be a physical data center or virtual data center. Different workloads should use separate data centers, either physical or virtual. Replication is set by data center. Using separate data centers prevents Cassandra transactions from being impacted by other workloads and keeps requests close to each other for lower latency. Depending on the replication factor, data can be written to multiple data centers. However, data centers should never span physical locations.
** Cluster
A cluster contains one or more data centers. It can span physical locations.
** Commit log
All data is written first to the commit log for durability. After all its data has been flushed to SSTables, it can be archived, deleted, or recycled.
** Table
A collection of ordered columns fetched by row. A row consists of columns and have a primary key. The first part of the key is a column name.
** SSTable
A sorted string table (SSTable) is an immutable data file to which Cassandra writes memtables periodically. SSTables are append only and stored on disk sequentially and maintained for each Cassandra table.
Writing and Reading Data
One of Cassandra’s hallmarks is its fast I/O operation capability for both writing and reading data.
Data is written to Cassandra in a way that provides both full data durability and high performance. From a high level perspective, data written to a Cassandra node is first recorded in a commit log and then written to a memory-based structure called a memtable. When a memtable’s size exceeds a configurable threshold, the data is flushed to disk and written to an SStable (sorted strings table), which is immutable.
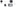
The Cassandra write path.
Because of the way Cassandra writes data, many SStables can exist for a single Cassandra table/column family. A process called compaction for a node occurs on a periodic basis that coalesces multiple SStables into one for faster read access.
Reading data from Cassandra involves a number of processes that can include various memory caches and other mechanisms designed to produce fast read response times.
Frequently asked Cassandra Interview Questions & Answers
For a read request, Cassandra consults a bloom filter that checks the probability of a table having the needed data. If the probability is good, Cassandra checks a memory cache that contains row keys and either finds the needed key in the cache and fetches the compressed data on disk, or locates the needed key and data on disk and then returns the required result set.
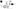
The Cassandra read path.
Data Distribution and Replication
In Cassandra, data distribution and replication go together. Data is organized by table and identified by a primary key, which determines which node the data is stored on. Replicas are copies of rows. When data is first written, it is also referred to as a replica.
Factors influencing replication include:
- Virtual nodes: assigns data ownership to physical machines.
- Partitioner: partitions the data across the cluster.
- Replication strategy: determines the replicas for each row of data.
- Snitch: defines the topology information that the replication strategy uses to place replicas.
Automatic Data Distribution
| Automatic Data Distribution | Cassandra provides automatic data distribution across all nodes that participate in a ring or database cluster. There is nothing programmatic that a developer or administrator needs to do or code to distribute data across a cluster because data is transparently partitioned across all nodes in a cluster. |
Replication Basics
Cassandra also replicates data according to the chosen replication strategy. The replication strategy determines placement of the replicated data. There are two main replication strategies used by Cassandra, Simple Strategy and the Network Topology Strategy. The first replica for the data is determined by the partitioner. The placement of the subsequent replicas is determined by the replication strategy. The simple strategy places the subsequent replicas on the next node in a clockwise manner. The network topology strategy works well when Cassandra is deployed across data centres. The network topology strategy is data centre aware and makes sure that replicas are not stored on the same rack. Cassandra uses snitches to discover the overall network topology. This information is used to efficiently route inter-node requests within the bounds of the replica placement strategy.
The replication option is to specify the Replica Placement strategy and the number of replicas wanted. The following table lists all the replica placement strategies.
| Strategy name | Description |
| Simple Strategy | Specifies a simple replication factor for the cluster. |
| Network Topology Strategy | Using this option, you can set the replication factor for each data-center independently. |
| Old Network Topology Strategy | This is a legacy replication strategy. |
Using this option, you can instruct Cassandra whether to use commitlog for updates on the current KeySpace. This option is not mandatory and by default, it is set to true.
Multi-Data Center and Cloud Support
A very popular aspect of Cassandra’s replication is its support for multiple data centers and cloud availability zones. Many users deploy Cassandra in a multi-data center and cloud availability zone manner to ensure constant uptime for their applications and to supply fast read/write data access in localized regions.
You can easily set up replication so that data is replicated across many data centers with users being able to read and write to any data center they choose and the data being automatically synchronized across all centers.
You can also choose how many copies of your data exist in each data center (e.g. 2 copies in data center 1; 3 copies in data center 2, etc.) Hybrid deployments of part onpremise data centers and part cloud are also supported.
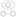
Cassandra supports multi-data center and cloud deployments.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Cassandra Training | Aug 01 to Aug 16 | View Details |
| Cassandra Training | Aug 04 to Aug 19 | View Details |
| Cassandra Training | Aug 08 to Aug 23 | View Details |
| Cassandra Training | Aug 11 to Aug 26 | View Details |

Ravindra Savaram is a Technical Lead at Mindmajix.com. His passion lies in writing articles on the most popular IT platforms including Machine learning, DevOps, Data Science, Artificial Intelligence, RPA, Deep Learning, and so on. You can stay up to date on all these technologies by following him on LinkedIn and Twitter.


