- Home
- Blog
- Apche Cassandra
- What is NoSQL? - NoSQL Databases

- Apache Hive - Internal and External Tables
- Cassandra Interview Questions
- Cassandra Tutorial
- Apache Cassandra Architecture Overview
- Apache Cassandra - Data Model Best Practices
- Apache Cassandra Data Security Management
- How to Backup and Restore in Cassandra Using Multi-Data Center
- Migrating Data From RDBMS to Other Database With Cassandra
- Apache Cassandra NoSQL Performance Management / Benchmarks
- NoSQL Interview Questions and Answers
Whether it is about advanced customer support leveraging AI and ML-like technologies to provide a great user experience, personalization, etc., or complex scientific computations getting used for space science - they all are data-oriented.
This data can be a graph, image, video, or anything required or generated by an application. Now, to handle this massive information getting generated in an unstructured format, you need to have an understanding of a database language that can deal with them all.
NoSQL- due to its ease of access and fast processing, is getting popular day by day among developers. In this NoSQL tutorial, we are going to all about What is NoSQL?. Let’s explore this database language a little deeper:
| Table of Content - What is NoSQL? - NoSQL Databases |
|
➤ Difference between SQL and NoSQL ➤ Ways to deploy NoSQL databases ➤ How will learning NoSQL Course help you enhance your career? |
What is NoSQL (Not Only SQL database)?
NoSQL stands for non-relational database which is currently being used for storing and retrieving data. NoSQL is used for managing large unstructured data sets where the information is not kept in a relational form or non-tabular form. Rather, the data is stored in the form of documents, graphs,s or collections of key-value pairs. The traditional database languages were unable to deliver effective outcomes in the case of:
- Variable data i.e., regularly altering formation such as in unstructured, structured, or semi-structured data.
- Modern applications deal with a huge number of people from multiple geographical locations which needs to run all the time serving data integrity in an effective way.
- Distributed applications hosted over the cloud throw a massive amount of data that needs to be analyzed and accessed from the time to time. Since these data sets are available over various virtual servers, NoSQL is needed to access them especially when they are unstructured.
NoSQL is developed to resolve the major associated issues such as scalability, performance, data integrity, and modeling which are getting common in a relational database. Before going further, let's understand what is structured and unstructured data.
| Enthusiastic about exploring your skill set of Cassandra? Then, have a look at the Cassandra Online Course together with additional knowledge. |
What is structured data?
Data that is available in the form of a table comprising rows and columns are known as structured data. It can be easily accessed, analyzed, and visualized through charts or statistics.
What is unstructured data?
Data that is available in a raw form such as images, videos, pdfs, docs, e-mails, etc., fall under the non-structured data. Now, extracting structured information from unstructured data is a time-consuming task.
Around 2.2 billion gigabytes of data are being produced every day. Since data is emerging at an unstoppable pace, NoSQL databases are the only way to deal with a huge amount of data.
| Related Article: Migrating Data From RDBMS to Other Databases With Cassandra |
Difference between SQL and NoSQL
SQL and NoSQL- both databases are very famous across the industries. Let's understand the key differences among them:
| Sno. | SQL | NoSQL |
| 1 | SQL databases contain a predefined schema. | NoSQL databases contain dynamic schema. |
| 2 | In SQL databases, data is stored in the form of tables. | NoSQL databases have data in the form of key-value pair collection, graphs, wide columns, or documents. |
| 3 | SQL databases are scaled vertically. | NoSQL databases are scaled horizontally. |
| 4 | SQL databases are not good for storing data hierarchically. | NoSQL databases are best for keeping data hierarchically. |
| 5 | SQL database leverages strong query language for manipulating data. | NoSQL database leverages documents collection for manipulating data |
| 6 | SQL database examples are: Oracle, MSSQL, MySQL,PostgreSQL etc. | NoSQL database examples are Redis, Neo4j, BigTable,HBase, MongoDB etc. |
| 7 | SQL databases are perfectly handled through complex queries. | NoSQL databases are not perfect with complex queries. |
- SQL databases contain data in tabular form while NoSQL database is document-oriented, or they can be in the form of key-value, wide columns, or graph. So an SQL database can consist of n number of rows or columns while NoSQL can have a key-value collection, a graph of documents, or wide columns. They do not contain any standard schema definitions as in the case of SQL.
- An SQL database is based on a schema that is predefined. But, a NoSQL database contains a dynamic schema to deal with unstructured information.
- An SQL database can be scaled up or down vertically. But, a NoSQL database is scalable in a horizontal direction. To scale an SQL database, you need to improve the hardware horsepower. In the case of a NoSQL database, you need to scale up or down the server resources to handle the overall load. You can also use load balancers for virtual servers. The best part is - cloud vendors offer auto-scaling group features and load balancers to automatically handle the server load.

- The SQL databases are manipulated through the strong structured query language. In the case of NoSQL, we used to collect documents and deal with them through unstructured data query language (SQL).
- SQL databases are the best choice for complex queries while NoSQL is not very good at this. While dealing with high-level data, NoSQL queries are not as strong as SQL queries. NoSQL doesn't provide any standard interface to deal with such queries. For handling complex transactional websites or applications, SQL databases are preferred due to their data integrity, and atomicity-like nature. But, NoSQL is still not fit for such high load or sensitive transactional applications.
- Now, when we discuss the different varieties of data, SQL databases are not good at dealing with all of them. At the same time, NoSQL databases are the first choice of developers since it supports hierarchical data storage. It leverages the key-value pairs to keep data just like JSON (Javascript Object Notation) data. Organizations dealing with massive data sets (such as in big data) prefer the NoSQL databases like HBase.
- In terms of scalability, SQL databases are highly scalable which can be managed by adding RAMs, SSDs (Solid State Device), or extra central processing units (CPUs), etc., over the same server. But, in the case of NoSQL which is scaled horizontally, you may add some more servers to handle the high workload.
- Let’s discuss the SQL database properties - they are based on the ACID concept, which is atomicity, consistency, isolation, and durability. But, NoSQL is based on the Brewers CAP theorem which states consistency, availability, and partition tolerance.
- The examples of SQL databases are:
- Oracle,
- MS SQL,
- MySQL etc.
- The examples for NoSQL databases are:
- Redis,
- Neo4j,
- CouchDB,
- Postgres,
- Hbase,
- MongoDB, and
- BigTable etc.
| Related Article: Cassandra Tutorials |
History of NoSQL
| Year | Journey |
| 1998 | NoSQL was firstly used by Carlo Strozzi to manage lightweight and open-source databases. |
| 2000 | Neo4j Graph database was introduced |
| 2004 | BigTable was introduced by Google |
| 2005 | CouchDB was introduced |
| 2007 | Amazon Dynamo research paper was published |
| 2008 | Facebook launched its open-source project, Cassandra |
| 2009 | NoSQL term was again introduced to the public |
As we can see above, the word NoSQL was initially used by Carlo to manage his open-source relational database. This NoSQL concept was somehow different than the one introduced in the year 2009. Carlo states that the NoSQL is departing from the relational model to others so it is pronounced as the NoREL called 'no relational'.
In the year 2009, NoSQL was again launched by Johan Oskarsson who was an IT developer at Last.fm. He introduced this database in an event held for discussing open source and distributed non-relational databases.
[Related Article: EY Interview Questions]
Importance of NoSQL
NoSQL database keeps the information in JSON format. It avails the unique data storage and managing concepts which are very different than the one for RDMS tabular forms. The NoSQL databases are the best fit for dealing with modern cloud computing platforms giving rise to decentralized application development. NoSQL fulfills all their demands. These benefits given below will explain the importance of NoSQL databases in this digital world:
- Availability: You may encounter varieties of relational databases for dealing with data transactions, but the NoSQL databases are perfect in it. Their continuous availability makes them manage various kinds of data transactions even in complex scenarios.
- Latency-Rate: Another good thing about the NoSQL database is - it has a low latency rate. The data can be accessed in very little time through easy steps. They are fast enough to manage modern application-oriented operations.
- Easy to Scale: NoSQL provides the easiest ways to scale database resources as per current or upcoming needs. They can be partitioned among various servers to fulfill increased storage demands. And the best part is - the required hardware is not as expensive as in the case of SQL database scaling.
- Can Manage Changes: Schema-less NoSQL can easily manage changes from time to time. It leverages the universal index available for values, and structures from the data, so it becomes easy for it to manage changes very quickly.
Support for Multiple Data Structures: Apart from the application, the NoSQL databases themselves can deal with the necessary data such as binary figures, graphs, strings, lists, interrelated data, etc.

NoSQL vs RDBMS
Currently, NoSQL and RDBMS are widely used among organizations for handling their databases. RDBMS which is most effective in the case of structured databases is not capable of solving challenges faced while dealing with unstructured datasets. And, here comes the role of NoSQL. Let’s explore how these databases differ in their mechanism. NoSQL is much better than the RDBMS in various ways such as:
- NoSQL can manage volatile and unstructured information.
- The queries are performed faster due to the in-memory cache.
- It doesn't rely on a schema.
- The hosting machines are cheaper than in the case of RDBMS.
- The read and write operations are performed faster here.
- Leverage analytics to support big data efficiently.
- Big data up to tera or petabytes can be easily handled.
- Scalability is performed horizontally.
- Reduces developers’ efforts.
RDBMS faces many troubles while dealing with a large number of datasets such as petabytes or terabytes. Even though it leverages the RAID (Redundant Array of Independent Disks) or shredding of data, it doesn't provide the desired outcomes while handling massive information. To do so, you need to spend a significant amount on the hardware. Below here are key differences.
| Sno. | RDBMS | NoSQL |
| 1 | Based on tables | Based on key-value pairs, documents, graph |
| 2 | Handles information in low velocity. | Handles incoming information with high velocity. |
| 3 | Failover can cause a single point of failure. | No single point of failure |
| 4 | It has centralized deployments | It has decentralized deployments |
| 5 | Scaled vertically | Scaled horizontally |
| 6 | Provides read scalability | Provides both read and write scalability. |
| 7 | Transactions are stored in a single location | Transactions are written in various locations. |
| 8 | It manages only structured data. | It manages semistructured, structured, and unstructured data. |
| 9 | Emphasizes ACID properties | Emphasizes on CAP theorem |
Still, the RDMS is effective in various scenarios due to the following reasons:
- ACID based Transactions
- Atomicity, Consistency, Isolation, Durability
- ‘join’ and ‘group’ through clauses help in the execution of complex database queries.
- Queries are managed in real-time. Scenarios like handling data with a size of less than 10-10 terabytes.
Features of NoSQL
NoSQL is highly adopted among developers due to the following features:
Multi-Model:
When it comes to data handling, relational databases are just limited to rows and columns for analyzing or accessing it. While, in the case of the NoSQL database, the multiple data models lead to a much more flexible environment in handling information. Thus, they can easily handle all kinds of data including structured, semi-structured, or unstructured.
Each application demands a different way to handle its information. NoSQL has become the first choice of developers while handling agile application development. Developers can leverage graphs, key-value, wide columns,s, or documents. Rather than using any other database, one can use the same data under multiple model types. Thus, one can enjoy multiple data models through a single database.
Non-relational:
NoSQL database is different than the relational model. It doesn't use tables (including columns or rows) containing a fixed number of records. It uses self-aggregates or binary large objects. NoSQL doesn't leverage data normalization or object-relational mapping like in the case of a relational model. It doesn't require any complex mechanism such as joins, ACID, query planners, etc.
Schema-free:
NoSQL databases don't require any schema, schema definitions, or any other associated terms. Rather, it offers a heterogeneous structure of data under the existing domain. One can use it to handle any kind of data emerging from their complex applications.
Simple API:
NoSQL provides a simple and easy interface to store information. The queries are also simple. You can leverage APIs (Application Programming Interfaces) to handle low-level data and use selection methods. It uses text-enabled protocols through HTTP REST APIs which deal with JSON data. Web applications handling a large amount of data can use various internet active services through APIs.
Distributed:
You can run multiple NoSQL databases over the distributed platform with incredible features like auto-scaling, recovery, fail-over, etc. Here, the ACID feature is diminished to achieve better throughput and scalability. It allows multi-master replication and HDFS replication over the distributed nodes for processing. In NoSQL, the shared-nothing architecture ensures reduced coordination achieving maximized distribution.
Zero Downtime:
The best feature of the NoSQL databases is, that they have zero downtime. Its masterless architecture contains various clones of data. These cloned data are managed across multiple nodes. Suppose a node went down, then you can access this data from any other node leading to zero downtime.
| Related Article: Interview Questions on Cassandra |
Types of NoSQL databases
A NoSQL database can be of four types:
- key-value store: It contains a hash table that stores keys and their values such as Amazon Simple Storage Service (S3), (Dynamo).
- Document-based store: It keeps the documents that are made up of tagged elements.
- Column-based Store: All the storage blocks consist of information just from a single column, such as in Cassandra or HBase.
- Graph-based store: It is a network database that leverages the nodes and their edges for keeping or showing data such as in Neo4J.
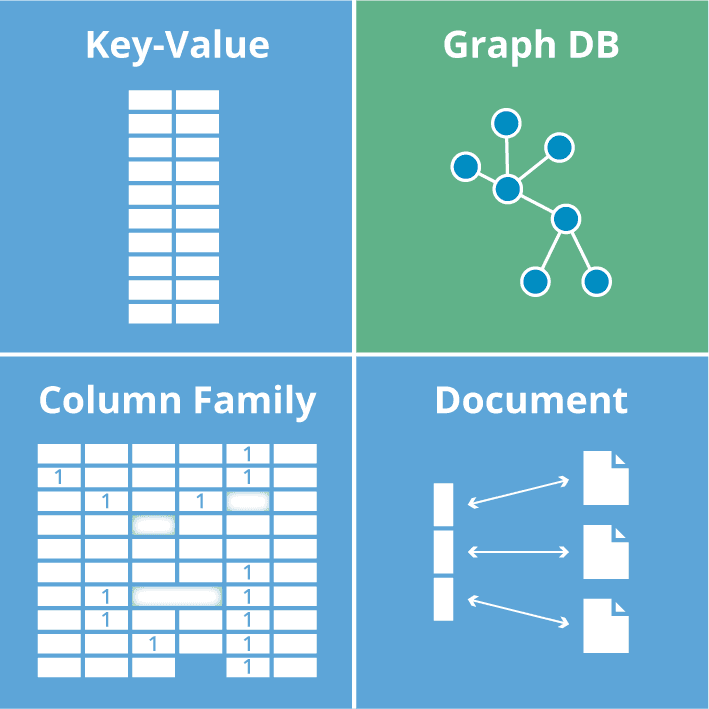
Let's understand all these four types briefly:
Key-Value Store NoSQL Database:
The storages without schema containing key and value databases are the demand of modern applications. Here, a value can be JSON, a basic large object (BLOB) or string, etc. And, the key will be auto-generated or it can be synthetic as well.
A key-value database uses a hash table. This table consists of unique keys and pointers to a specific item. A logical combination of keys is stored in a bucket. It doesn't gather information physically. A bucket can also have identical keys. Here, the cache performs mapping to achieve enhanced performance. While reading a value, it requires both - the key and the bucket. The main key is a hash which is the combination of bucket and key.
The key-value database can be implemented easily making no complexity in it. While going through the CAP theorem, you will get to understand that the key-value databases are perfect in terms of Availability and Partition. They only lack inconsistency.
E.g., let's understand it with the help of the table below. Here, the key represents the name of the country where the office, say, xx is located and the value represents the respective locations where these offices are located in those countries.
| Key | Value |
| "Australia" | {"a-22, mora fitsy building, Sydney-020202"} |
| "USA" | {"e-203, green street, LA 1101003"} |
| "India" | {"r-22, sector 7, Saket, New Delhi-1000001"} |
The key can be auto-generated. The value will be a string, JSON, BLOB, etc.
Here, In this key-value database, one can read or write through keys such as:
- put(key, value): adds value with the given key.
- get(key): it will provide the value associated with this key.
- Delete(key): it deletes the provided entry given for that key from the database.
- Multi-get(k1, k2, .., kN): it provides a list of keys with their associated values.
Apart from these advantages, key-value pairs have some drawbacks too. The first one is that they don’t have the ability to deliver any traditional database operational services. It can be atomicity, consistency, or multiple transaction execution. All these capabilities must be introduced by the application itself. Also, with an increase in the data quantity, the maintenance of the unique keys becomes complex.
Examples of NoSQL key-value databases: Amazon DynamoDB, Riak.
Document Store NoSQL Database:
Any data which is the combination of key-value pairs is compressed as a document store. It is similar to the key-value database, the only difference is that, here, the stored values which are termed as documents are kept in a structured format and encoded. The encodings used in the document stores can be XML, BSON (JSON binary encoding) or JSON (JavaScript Object Notation).
In the example below, the data values are stored as a document. They refer to the names of a particular shop. Here, you will notice that all the stored three values represent the address of the shop but all the representation models are different.
{shopname:"LooksnLooks",
{Add: "a-2, City:"Jamnagar", State:"Gujarat", Pin:"201010"}
}
{shopname:"LooksnLooks USA",
{add:"h-54, rogers street",, block:"5C", City:"Georgia", Pincode:"292020"}
}
{shopname:"LooksnLooks Peru",
{Lat:"48.2403248", Long:"81.2345353"}
}The main difference between the key-value database model and the document store is that the metadata of the embedded attribute are available with the kept content. Thus, one can make data queries on the basis of the available contents. e.g., in the above-discussed example, you can look for all the documents where the city is Georgia. Thus, it will provide all the documents associated with the LooksnLooks office which are present in the searched city.
Examples of document stores: Apache CouchDB and MongoDB.
CouchDB uses JSON for keeping information. It has JavaScript language for querying through MapReduce and leverages HTTP as an API. All the data and their relationships are not kept in a table but are stored as a combination of documents that are independent of each other.
Column Store NoSQL Database:
A column-oriented database keeps the information in cells. These cells are grouped into data columns instead of rows. All the columns are further gathered into column families. These virtually defined columns are created during runtime. We use these columns to read or write data instead of the rows.
Generally, relational databases keep information in rows. Rather, the main benefit of keeping data in columns is- better and very fast access to these data and data aggregation. A relational database keeping the information in rows performs continuous entry over the disk. Different rows are kept over a different locations of the disk memory. Instead, a column-oriented database keeps cells associated with a column through continuous entry over a disk. Thus, performing a search or other operations becomes faster.
Eg., making a query for the title from thousands of blogs is a complex task. In a relational database, the pointer has to go through each place to get a title. But, in the column-oriented database, accessing just one disk provides the desired outcome.
Data Model
To understand how data is stored in the document-oriented NoSQL model, you need to understand all the terms used in its data model. A data model represents the relationship among all the different data elements.
Let’s discuss all the elements of a data model:
- key says the permanent name of a record. It has various columns for scaling.
- Column: An ordered list of data. It is also known as a tuple. It has a name and a defined value. e.g., HBase and Cassandra, BigTable by Google.
- ColumnFamily: a single structure, it groups the columns and SuperColumns easily.
- Keyspace: It specifies the outermost level of an enterprise. Generally, it is the name of an application such as 'LooksnLooks' (name of the database).
| Related Article: Difference between MongoDB and Cassandra |
Google's BigTable is a high-performance base storage system. It compresses the data. Its attributes are:
- Map: it has a key and the value
- Sparse: a few empty cells
- Persistent: data storage over the disk.
- Multidimensional: having more than one dimension.
- Distributed: partitioning data over multiple hosts
- Sorted: it sorts the map which in most cases is not sorted.
Here is a two-dimensional table. It consists of rows and columns starting a relational database.
| City | Pincode | Population | Works |
| Delhi | 110001 | 300 | 23 |
| LA | 102409 | 400 | 25 |
| Sydney | 930594 | 350 | 30 |
| Beijing | 475505 | 650 | 41 |
This RDBMS table can be shown through BigTable as:
{
LooksnLooksDelhi: {
city: Delhi
pincode: 110001
},
details: {
population: 300
works: 23
}
}
{
LooksnLooksLA: {
address: {
city: LA
pincode: 102409
},
details: {
population: 400
works: 25
}
},
{
LooksnLooksSydney: {
address: {
city: Sydney
pincode: 930594
},
details: {
population: 350
works: 30
}
}
{
LooksnLooksBeijing : {
address: {
city: Beijing
pincode: 475505
},
details: {
population: 650
works: 41
}
}The outermost keys LoooksnLooksDelhi, LooksnLooksLA, LooksnLooksSydney, and LooksnLooksBeijing all are analogs to rows. Here, ‘address’ and ‘details’ are representing the column families.
The column-family ‘address’ contains the columns ‘city’ and ‘Pincode.
The column-family details’ contains the columns ‘population’ and ‘works’.
Here, we can reference the Columns through ColumnFamily.
Graph-Based NoSQL Database:
A graph-based database represents graphical data rather than rows or columns. They are perfect for addressing scalability issues. A graph structure comprises nodes, edges, and their properties for availing index-free adjacency. You can very easily transform data from one to another model through it.
Nodes are organized through their relationship with one another. This relationship is visualized through edges. Node and edges have a few defined properties.
A graph model has the following properties:
Labeled, attributed, directed multigraph: A graph consists of nodes. These nodes are labeled containing a few properties. All the nodes are related to one another. They are represented through directional edges.
[Related Article: EY Interview Questions]
Ways to deploy NoSQL databases
NoSQL databases can be deployed in the following manners:
- Columnar Databases: It reads or writes the data columns instead of rows. Here, each column is just like a container of the RDBMS inside which a key represents the row and a row comprises various columns.
- Document Databases: You can deploy through document databases which can keep and retrieve semi-structured data in a document format. It can be XML, JSON, etc. To access such data in document databases like MongoDB, you can use rich queries provided by them.
- Graph Databases: These keep the data in the form of entities relating to one another. Thus, it can achieve quick traversal and perform joining operations. You may wonder why these graphs are created through SQL as well as NoSQL databases.
- In-Memory Key-Value Stores: It is best for reading large workloads. These databases can store sensitive information in memory to improve overall system performance.
Advantages of NoSQL
A few of the biggest advantages of NoSQL are:
They have big data abilities.
- Zero downtime and not a single point of failure.
- It can be easily replicated and is simple to implement.
- You can use it as a main or analytic data source.
- It can deal with all kinds of data: structured, semi-structured, and unstructured.
- Scalability is performed horizontally with quick performance.
- It doesn't require any separate layer for the cache.
- It leverages OOPs (Object Oriented Programming) making it flexible. For online applications, you can use it as the main data source.
- They don't require an expensive high-performance server for execution.
- It has the ability to handle distributed database operations.
Disadvantages of NoSQL
Apart from the several advantages, NoSQL has a few drawbacks too. Let's figure them out:
- It has just a limited number of queries to access information.
- It doesn't come with any standard rules.
- For relational data sets, choosing NoSQL will be a bad option.
- Traditional databases potentials like consistency during various transactions’ execution are unavailable.
- When the amount of data increases, handling unique key values becomes challenging.
How will learning NoSQL Course help you enhance your career?
For an enterprise, NoSQL looks pretty useful. Modern applications throwing information at a massive rate are leveraging this technology. Well, since companies are using this information in pattern analysis, recommendations, personalizations, and various other tasks which require healthy data, so NoSQL is the best solution for that. The insights gathered from these data help an organization to stand tall among its competitors.
The cloud vendors like Amazon, Microsoft, and Google are also making efforts with their products like DynamoDB, Cosmos DB, etc. These companies are offering NoSQL as a critical commercial service over the cloud.
If you want to grow your career in this field, you must start learning this database. You can go through the Mindmajix MongoDB training and learn the key phases involved in the database creation to their deployment. So why waste your precious time? move forward and mark your presence in such courses.
Conclusion
After learning this NoSQL tutorial, now you must have understood how these modern NoSQL databases are taking over the traditional RDBMS. The modern applications getting used in retail, IT, e-commerce, FinTech, etc., are throwing a significant amount of information every minute which needs to get handled in real-time. Thanks to NoSQL databases for making their execution smooth and faster.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Cassandra Training | Aug 04 to Aug 19 | View Details |
| Cassandra Training | Aug 08 to Aug 23 | View Details |
| Cassandra Training | Aug 11 to Aug 26 | View Details |
| Cassandra Training | Aug 15 to Aug 30 | View Details |

Ravindra Savaram is a Technical Lead at Mindmajix.com. His passion lies in writing articles on the most popular IT platforms including Machine learning, DevOps, Data Science, Artificial Intelligence, RPA, Deep Learning, and so on. You can stay up to date on all these technologies by following him on LinkedIn and Twitter.


