
If you're looking for EMC Interview Questions for Experienced or Freshers, you are at the right place. There are a lot of opportunities from many reputed companies in the world. According to research, EMC has a progressive market share. So, You still have the opportunity to move ahead in your career in EMC Engineering. Mindmajix offers Advanced EMC Interview Questions 2024 that helps you in cracking your interview & acquire your dream career as EMC Engineer
Frequently Asked EMC Interview Questions
- What is Q-Depth? How to calculate it?
- How will you discover SAN disks on Hosts?
- What are Buffer-to-Buffer Credits?
- What is Drooping? How to check it?
- What is the difference between Hard and Soft Zoning?
- What is Port Zoning?
- Why we need LUN Masking?
| If you want to enrich your career and become a professional in EMC, then enroll in "EMC Training". This course will help you to achieve excellence in this domain. |
EMC Interview Questions For Freshers
1. As a SAN administrator, how will you tell your boss how many drives are required for a requirement?
I will use the formula:
Total Approximate Drives required = (RAID Group IOPS / (Hard Drive Type IOPS)) + Large Random I/O adjustment + Hot Spares + System Drives
2. How to calculate HDD capacity?
Capacity = Heads X Cylinders X Sectors X Block Size
3. You need to provision SAN storage with a certain IOPS. How will you find what kind of disks you need?
Input/output operations per second (IOPS) is the measure of how many input/output operations a storage device can complete within one second.
IOPS is important for transaction-based applications.
IOPS performance is heavily dependent on the number and type of disk drives.
To calculate the IOPS of a Hard disk drive:
1
IOPS = —————————————
(Average Latency) + (Average Seek Time)
To calculate IOPS in a RAID:
(Total Workload IOPS * Percentage of workload that is read operations) + (Total Workload IOPS * Percentage of workload that is read operations * RAID IO Penalty)
4. How will you calculate Max IOPS an HBA Port can generate to any LUN?
Max IOPS an HBA Port can generate to any LUN = (Device Queue Depth per LUN * (1 / (Storage Latency in ms/1000)))

5. What is Q-Depth? How to calculate it?
The queue depth is the maximum number of commands that can be queued on the system at the same time.
Q is the Queue Depth =Execution Throttle= Maximum Number of simultaneous I/O for each LUN on a particular path to the Storage Port.
Calculation of the maximum queue depth: The queue depth is the number of I/O operations that can be run in parallel on a device.
Q = Storage Port Max Queue Depth / (I * L),
I is the number of initiators per storage port
L is the quantity of LUNs in the storage group.
T = P * q * L
T = Target Port Queue Depth
P = Paths connected to the target port
Q = Queue depth
L = number of LUN presented to the host through this port
Execution Throttle= (Maximum Storage Port Command Queue) / (Host Ports)
6. How will you calculate the number of drives required?
Total Approximate Drives required = (RAID Group IOPS / (Hard Drive Type IOPS)) + Large Random I/O adjustment + Hot Spares + System Drives
7. If you know I/O load and IOPS, how will you calculate how many drives will be needed?
Total Approximate Drives = (RAID Group IOPS / (Hard Drive Type IOPS)) + Large Random I/O adjustment + Hot Spares + System Drives
8. How will you calculate HDD Capacity?
Capacity = Heads X Cylinders X Sectors X Block Size
9. What is the relation between rotational speed and latency time?
The Rotational speed and latency time are related as follows:
Latency time = (1/((Rotational Speed in RPM)/60)) * 0.5 * 1000 milliseconds
Latency and RPM:
HDD
Spindle RPM Average rotational latency [ms]
7,200 4.17
10,000 3.00
15,000 2.00
10. What SAN design you will choose? Why?
Core-Edge:
- This design includes redundant paths between switches,
- As the fabric has two or more “core” switches in the centre of the fabric,
- This interconnects a number of “edge” switches. Hosts,
- Storage and other devices connect to the free ports on the edge switches, in some cases also connect directly to the core switch.
- It makes the fabrics highly scalable, without disruption to service.
- I consider Core-Edge the most versatile form of SAN design.
Here a picture of Core-Edge Topology:
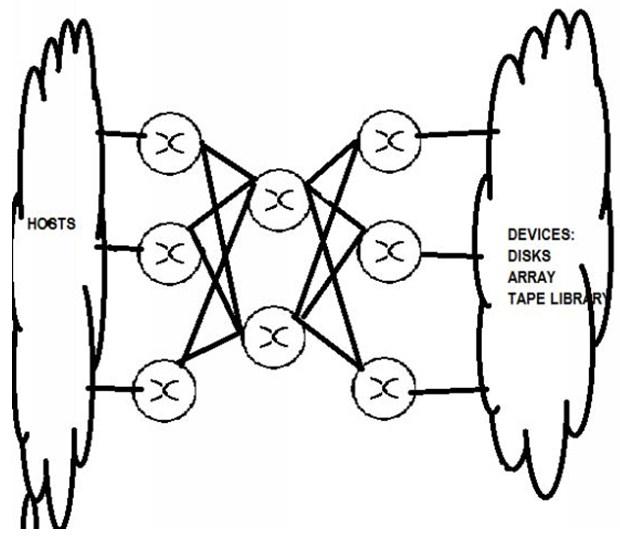
Benefits are:
- Higher ROI meets RTO, RPO & SLA and helps with consolidation, utilization of storage, and ability to access any storage system from any host.
- Core Edge Fabric Nomenclature: n1e*n2c*n3i
- Where n1e= number of edge switches, n2c= number of core switches, n3i=number of ISL
11. What are multi-pathing schemes and which one to use for optimal performance?
Servers/ hosts use multipathing for failover from one path to the other when one path from the Servers/host to the SAN becomes unavailable, the host switches to another path.
Servers/ hosts can also use multipathing for load balancing.
Types of policy:
- Most Recently Used: The path used by a LUN is not be altered unless an event instructs the path to change. I will use this policy is for Active/Passive arrays and many pseudo active/active arrays. Most recently used (mru) selects the path most recently used to send I/O to a device.
- Fixed: The path used by a LUN is always the one marked as preferred, unless that path is unavailable I use this policy is for Active/Active arrays. Fixed (fixed) uses only the active path.
- Round Robin: Round robin (rr) uses the mru target selection policy and any HBA selection policy to select paths.
- Custom (custom) sets the LUN to expect a custom policy.
12. With Active- Passive storage array what multipathing policy you will choose?
I will use a Fixed, or Preferred, path management policy to intelligently segment workload across both controllers.
13. Tell us a generic method to provision SAN Storage from an Array?
- Plan
- Validation with Support Matrix for Host Connectivity
- Provide Connectivity
- Pick Volumes
- Make Meta Volumes if necessary
- Map out Zoning
- Map to storage arrays Ports
- Create Zones
- LUN Mask
- Discover on Server
14. How will you discover SAN disks on Hosts?
- Windows - Disk Management console, Diskmgmt.msc
- HP-UX
Rescan the devices:
# /usr/sbin/ioscan -C disk
ioscan – scan the I/O system
SYNOPSIS:
driver | class] instance] hw_path] | [devfile]
instance]
driver | class] instance] hw_path] [devfile]
driver | class] instance] lun hw_path] [devfile]
[devfile]
hw_path]
Generate device files: insf –e
Verify the new devices: ioscan funC
- AIX
Rescan the devices: cfgmgr vl fcsx, x is FC adapter number
Verify the new devices: lsdev Cc
echo scsi add-single-device > /proc/scsi/scsi
- Solaris
Determine the FC channels: cfgadm -al
Force rescan: cfgadm o force_update c configure cx
Where x is the FC channel number
Force rescan at HBA port level: luxadm e forcelip /dev/fc/fpx
Force rescan on all FC devices: cfgadm al o show_FCP_dev
Install device files: devfsadm
Display all ports: luxadm e port
Display HBA port information luxadm -v display
Display HBA port information: luxadm e dump_map
To force Fibre Channel SAN disk rescan, Use device path from luxadm -e port output.
# luxadm -e forcelip
- ESX/ESXi
Sign in to VMware Infrastructure Client. Select the ESX host and then click the “Configuration” tab. Select “Storage Adapters” from under Hardware. Click “Rescan”
ESXESXi 4.x and before
esxcfg-rescan
ESXi 5.x and later
esxcli storage core adapter rescan –all
15. How will you get the WWN of all your HBA’s to provision SAN storage?
1. AIX
lscfg –v –l fcs#
(fcs – FC Adapter)
SMIT
2. HP-UX
fcmsutil /dev/td#
(td – Tachyon Adapter)
SAM
3. WIN
emulexcfg –emc or
hbanywhere
I can use Storage Explorer to see detailed information about the Fibre Channel host bus adapters (HBAs).
4. Solaris
/usr/sbin/lpfc/lputil
Also I can use:
more /var/adm/messages | grep –i wwn |more dmesg
5. VMware vSphere ESX/ESXi host
There are several ways to get HBA WWNs on VM
vSphere Client;
Using ESXi Shell;
Using Powershell / PowerCLI script.
6. LINUX
/sys/class/scsi_host/hostN/device/fc_host/hostN/port_name
Where “N” is the number of device for your fibre HBAsEMC Interview Questions For Experienced
16. How will you find errors on various OS operating systems to troubleshoot problems?
I will check the OS log files/event logs for errors:
- AIX: errpt -a
- Windows: event logs
- Solaris: /var/adm/messages
- linux: /var/log/messages
- HPUX: /var/adm/syslog/syslog.log
- Tru64: /var/adm/syslog
- SGI Irix: /var/adm/SYSLOG
- ESX: /var/log/vmkernel
- ESXi: /var/log/messages
17. For troubleshooting have you collected logs from a SAN Switch?
Yes. I have been using Brocade Fabric and I have used “support save “to collect various logs for any issues.
Syntax:
supportsave [ os | platform | l2 | l3 | custom | core | all ]18. What are Buffer-to-Buffer Credits?
Buffer credits, also called buffer-to-buffer credits (BBC) are used as a flow control method by Fibre Channel technology and represent the number of frames a port can store. Fibre Channel interfaces use buffer credits to ensure all packets are delivered to their destination. Flow-control mechanism to ensure that Fibre Channel switches do not run out of buffers, so that switches do not drop frames .overall performance can be boosted by optimizing the buffer-to-buffer credit allotted to each port.
19. How will you calculate the Number of Buffers required?
Number of Buffers: BB_Credit = [port speed] x [round trip time] / [frame size]
20. Which load balancing policies are used between Inter-Switch Links? Explain with an example?
I have used Brocade SAN and it has these load balancing policies:
- DLS – Dynamic Load Sharing. FSPF link balancing by FSPF routing protocol
- DPS – Dynamic Path Selection by effectively striping IOs at SCSI level
- Frame-level load balancing – Each successive frame on a different physical ISL.
21. What best practices you will follow to set up ISL Trunking?
- I will directly connect participating switches byInter-Switch Link (ISL) cables.
- I will keep the Trunk ports in the same port group
- I will make sure Trunk ports run at the same speed
- I will ensure that all Trunk ports are set to the same ISL mode (L0 is the default).
- I will convert Trunk ports to be E_Ports or EX_Ports
22. How will you decide how many storage arrays can be attached to a single host?
I will use:
Fan Out
For example 10:1.
I will determine this ratio, based on the server platform and performance requirement by consulting Storage vendors.
23. What is Drooping? How to check it?
Ans: Drooping= Bandwidth Inefficiency
Drooping begins if: BB_Credit Where RTT = Round Trip Time
SF = Serialization delay for a data frame
| Explore EMC Tutorial |
24. What Factors you will consider for designing a SAN?
- ISL over Subscription Ratio
- SAN Fan–in and Fan-Out
- Storage Ports
- Server I/O Profiles
- Fabric Features
- Continuity Requirements
Design should address three separate levels:
Tier 1: 99.999% availability (5 minutes of downtime per year)
Tier 2: 99.9% availability (8.8 hours average downtime per year, 13.1 hours maximum)
Tier 3: 99% availability (3.7 days of downtime per year)
25. Explain your experience with disk sparing?
SAN Storage array has data integrity built into it.
A storage array uses spae disk drives to take the place of any disk drives that are blocked because of errors. Hot spares are available and will spare out predictively when a drive fails.
There are two types of disk sparing:
- Dynamic Sparing: Data from the failed or blocked drive is copied directly to the new spare drive from the failing drive
- Correction Copy: Data is regenerated from the remaining good drives in the parity group. For RAID 6, RAID 5, and RAID 1, after a failed disk has been replaced, the data is copied back to its original location, and the spare disk is then available.
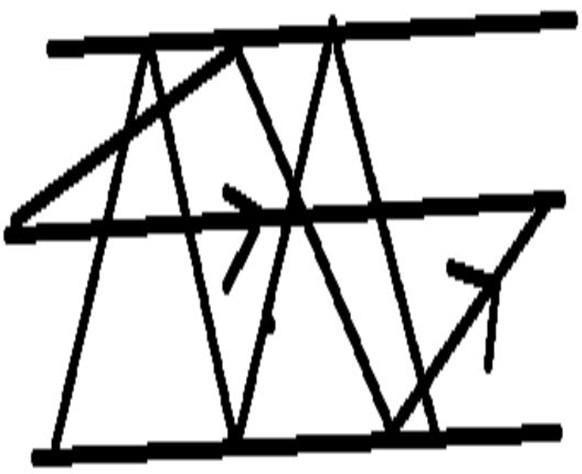
26. What is the difference between multimode and single-mode fiber?
Multimode fiber =large light carrying core, 62.5 microns or larger in diameter for short-distance transmissions with LED-based fiber optic equipment.
I have hand-drawn a picture of Multimode Fibre core as you can see Multimode fibers have a much larger core than single-mode shown below (50, 62.5 μm or even higher), allowing light transmission through different paths
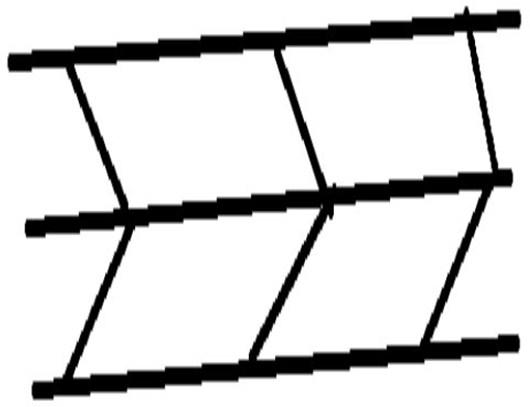
Single-mode fiber =small light carrying core of 8 to 10 microns in diameter used for long-distance transmissions with laser diode-based fiber optic transmission equipment.
A Single-mode fiber core has a much smaller core, only about 9 microns so that the light travels in only one ray as shown below.
27. How to troubleshoot a fiber optic signal?
By using a Fibre Optic Loopback Fibre Optic LoopBack
Fibre Optic Loopback modules are also called optical loopback adapters. I use the best practice of sending a loopback test to equipment, one at a time for isolating the problem
I have used different types:
- LC loopback modules
- SC loopback modules
- MT-RJ fibre optic loopback
Others
It helps in testing the transmission capability and the receiver sensitivity of network equipment.
To use I connect One connector into the output port, while the other is plugged into the input port of the equipment.
28. Can you allocate a LUN larger than the 2.19TB limit of MBR?
- I will use GPT.
- GUID Partition Table, GPT is a part of the EFI standard that defines the layout of the partition table on a hard drive. GPT provides redundancy by writing the GPT header and partition table at the beginning of the disk and also at the end of the disk.
- GPT Uses 64-bit LBA for storing Sector numbers. GPT disk can theoretically support up to 2^64 LBAs. Assuming 512-byte sector emulation, maximum capacity of a GPT disk = 9.4 x 10^21 bytes = 9.4 zettabytes (ZB)
29. Explain how BB Credits and port speeds are related?
Number of Buffers: BB_Credit = [port speed] x [round trip time] / [frame size]
Q30. How can you see the Load on the open systems connected to SAN?
| Platform | Tool |
| AIX | iostat |
| HPUX | SAR |
| iostat | |
| Glance+ | |
| vxstat | |
| Linux | iostat |
| Windows | Performance Monitor |
| Solaris | iostat |
| Vmware | esxtop |
FAQs
31. How will you calculate IOPS per drive?
To calculate IOPS per drive the formula I will use is:
1000 / (Seek Time + Latency) = IOPS
32. How to calculate RPMs of SSD?
SSD drives have no movable parts and therefore have no RPM.
33. How will you calculate the required bandwidth with write operations?
The required Bandwidth=the required bandwidth is determined by measuring the average number of write operations and the average size of write operations over a period of time.
34. How will you calculate Raw Capacity?
Raw Capacity= Usable + Parity
35. How do you know what type of fiber cable is needed?
I select it on the basis of transmission distance.
If the distance is less than a couple of miles, I will use a multimode fiber cable.
If the distance is more than 3-5 miles, I will use a single-mode fiber cable.
36. Explain the Device Masking Architecture in storage arrays?
The device masking commands allow you to:
- Assign and mask access privileges of hosts and adapters
- Connected in a Fibre Channel topology to storage arrays and devices.
- Specify the host bus adapters (HBAs) through which a host can access storage arrays devices.
- Display or list device masking objects and their relationships: Typical objects are hosts, HBAs, storage arrays devices, and Fibre Channel Adapter (FA) ports.
- Modify properties, such as names and access privileges associated with device masking objects (for example, change the Name of a host).
37. Explain SAN zoning?
SAN zoning is a method of arranging Fibre Channel devices into logical groups over the physical configuration of the fabric.
SAN zoning may be utilized to implement compartmentalization of data for security purposes.
Each device in a SAN may be placed into multiple zones.
The base components of zoning are
1. Zones
2. Zone sets
3. Default zone
4. Zone members
A zone is a set of devices that can access each other through port-to-port connections. When you create a zone with a certain number of devices, only those devices are permitted to communicate with each other. This means that a device that is not a member of the zone cannot access devices that belong to the zone.
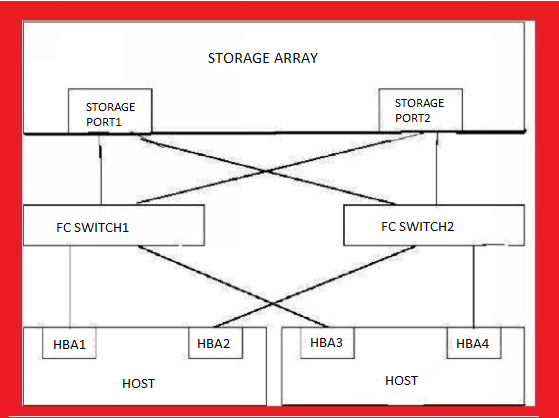
The figure shows the SAN Connectivity and accordingly zoning must be done.
38. What is the difference between Hard and Soft Zoning?
Hard zoning is zoning that is implemented in hardware.
Soft zoning is zoning that is implemented in software.
Hard zoning physically blocks access to a zone from any device outside of the zone.
Soft zoning uses filtering implemented in fibre channel switches to prevent ports from being seen from outside of their assigned zones. The security vulnerability in soft zoning is that the ports are still accessible if the user in another zone correctly guesses the fibre channel address.
39. What is Port Zoning?
Port zoning utilizes physical ports to define security zones. A user’s access to data is determined by what physical port he or she is connected to. With port zoning, zone information must be updated every time a user changes switch ports. In addition, port zoning does not allow zones to overlap. Port zoning is normally implemented using hard zoning, but could also be implemented using soft zoning.
40. What is WWN zoning?
WWN zoning uses name servers in the switches to either allow or block access to particular World Wide Names (WWNs) in the fabric. A major advantage of WWN zoning is the ability to re-cable the fabric without having to redo the zone information. WWN zoning is susceptible to unauthorized access, as the zone can be bypassed if an attacker is able to spoof the World Wide Name of an authorized HBA.
41. What is LUN, Logical Unit Number?
A Logical Unit Number or LUN is a logical reference to the entire physical disk or a subset of a larger physical disk or disk volume or portion of a storage subsystem.
42. What is LUN masking?
LUN (Logical Unit Number) Masking is an authorization process that makes a LUN available to some hosts and unavailable to other hosts.
LUN Masking is implemented primarily at the HBA (Host Bus Adapter) level. LUN Masking implemented at this level is vulnerable to any attack that compromises the HBA. Some storage controllers also support LUN Masking.
43. Why we need LUN Masking?
LUN Masking is important because Windows-based servers attempt to write volume labels to all available LUN’s. This can render the LUN’s unusable by other operating systems and can result in data loss.
Device masking lets you control your host HBA access to certain storage arrays devices. A device masking database, based in the storage arrays unit, eliminates conflicts through centralized monitoring and access records. Both HBA and storage arrays director ports in their Channel topology are uniquely identified by a 64-bit World Wide Name (WWN). For ease of use, you can associate an ASCII World Wide Name (AWWN) with each WWN.
44. How will you ensure that SAN-attached tape devices are represented consistently in a host operating system?
I will use the Persistent Binding for Tape Devices.
Persistent binding is a host-centric enforced way of directing an operating system to assign certain SCSI target IDs and LUNs.
Persistent Name Binding support is for target devices.
Persistent binding is provided for users to associate a specified device World Wide Port Name (WWPN) to a specified SCSI target ID.
For example, where a specific host will always assign SCSI ID 3 to the first router it finds, and LUNs 0, 1, and 2 to the three-tape drives attached to the router.
Practical examples:
For Emulex HBA on a Solaris host for setting up persistent binding:
# lputil
MAIN MENU
- List Adapters
- Adapter Information
- Firmware Maintenance
- Reset Adapter
- Persistent Bindings
Using option 5 will perform a manual persistent binding and the file is: /kernel/drv/lpfc.conf file.
lpfc.conf file looks like:
fcp-bind-WWNN=”50060XY484411 c6c11:lpfc0t1″,
“50060XY4411 c6c12:lpfc1t2”;
sd.conf file looks like:
name=”sd” parent=”lpfc” target=1 lun=0;
name=”sd” parent=”lpfc” target=2 lun=0;
Reconfigure:
# touch /reconfigure
# shutdown -y -g0 -i6
45. Have you used CLI to create Zones on a SAN switch?
Yes, on brocade:
1. I will create an alias.
aliCreate “aliname”, “member; member”
2. I will create a zone.
zonecreate “Zone Name”, “alias1; alias2″
3. I will add the zone to the defined configuration.
cfgadd “ConfigName”, “ZoneXYZ″
# cfgadd “configuration_Name”, “Zone_name”
4. I will save the defined configuration to persistent storage.
# cfgsave
5. I will enable the configuration.
cfgenable “ConfigName”
# cfgenable ” configuration_Name
| Explore EMC Sample Resumes Download & Edit, Get Noticed by Top Employers! |
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| EMC Training | Jul 21 to Aug 05 | View Details |
| EMC Training | Jul 25 to Aug 09 | View Details |
| EMC Training | Jul 28 to Aug 12 | View Details |
| EMC Training | Aug 01 to Aug 16 | View Details |

Ravindra Savaram is a Technical Lead at Mindmajix.com. His passion lies in writing articles on the most popular IT platforms including Machine learning, DevOps, Data Science, Artificial Intelligence, RPA, Deep Learning, and so on. You can stay up to date on all these technologies by following him on LinkedIn and Twitter.














