- Home
- Blog
- Apache Kafka
- Kafka Tutorial

Kafka is a stream processing software developed by LinkedIn previously and now functioning under the Apache foundation. Kafka is written in Scala, it is a publish-subscribe based messaging system.
In this Kafka tutorial, you will gain knowledge on concepts like Kafka Introduction, messaging system, terminologies, workflow, cluster setup, use-cases and real-time applications.
| The following topics will be covered in the Kafka tutorial |
What is Apache Kafka
Apache Kafka is a messaging system that allows interaction between producers and consumers through message-based topics. Kafka is becoming popular because of the features like easy access, immediate recovery from node failures, fault-tolerant, etc. These features make Apache Kafka suitable for communication, integrating the components of big data systems. It is integrated with Apache spark and storm for analyzing the streamed data. This tutorial teaches you the Kafa basics, Advantages, Disadvantages, workflow, Installation and basic operations. In the end, we will conclude with real-time applications of Kafka.
| Do you want to master in Apache Kafka? Then enroll our "Apache Kafka Online Training" This course will help you to master Apache Kafka |
Kafka Messaging System
The main job of the messaging system is to transfer the data from one application to another. As a result, applications can concentrate on data, not on how to share it. Messages are distributed using a message queuing system. The consumer consumes messages present in the queue by following specific messaging patterns, they are:
Point-to-Point
In this pattern. Messages remain in the queue. Anyone can consume the messages present in the queue, but only one consumer can consume a specific message. When the consumption is over, that particular message goes away from the queue.
Publish-Subscribe
This pattern is popularly known as pub-sub, and it is the most widely used messaging pattern. In this pattern, Messages remain in a topic. In this system, publishers are those who produce the messages and subscribers are those who consume the messages. To explore this system, we can take Dishtv as an example. Dishtv publishes various channels, and anybody may subscribe to their group of channels and have them at any time.

Kafka Advantages
- Reliable: It is reliable because of the features like distributed, replicated, and fault-tolerant.
- Scaleable: The messaging system of Kafka works without any time outs.
- Durable: Kafka is durable because messages exist on the disk right away with the help of the “Distributed commit log”.
- Throughput: The throughput of Kafka is high, and it remains high even if a huge amount(TB) of messages are saved.
| Related article: Apache Kafka Interview Questions |
Kafka Terminology
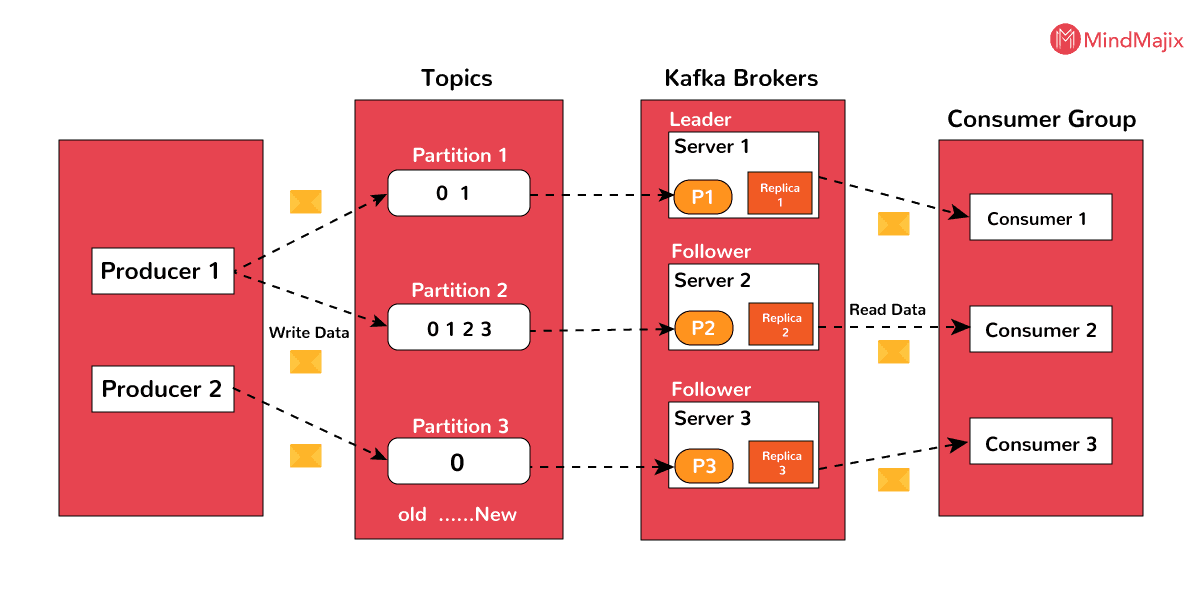
- Topics: A flow of messages associated with a specific category is known as a topic. Data or Messages are stored according to topics.
- Partition: Topics are divided into partitions so that they can manage any random data.
- Partition offset: The messages which are partitioned will have an individual sequence id, which is known as Partition offset.
- Replicas of Pattern: Replicas are also known as “backups” of a partition. They are not at all used for reading or writing data. Preventing data loss is the job of replicas.
- Brokers: Brokers are defined as a system established for managing the published data. Each broker may be allocated to zero or more partitions of a topic.
- Cluster: The Kafka's who has more than one broker is known as Kafka cluster. Clusters are utilized to handle the existence and replicance of message data.
- Producers: Producers are known as publishers of the messages to more than one Kafka topic. Producers may send messages to brokers or partition.
- Consumers: consumers are known as readers of the messages. consumers consume the messages by extracting the data from brokers,
- Leader: The node responsible for all the reads and writes of a given partition is known as a leader. Each partition will have one server operating as a leader.
- Follower: A follower is known as the node which follows the leader's instructions.
Kafka Cluster Architecture
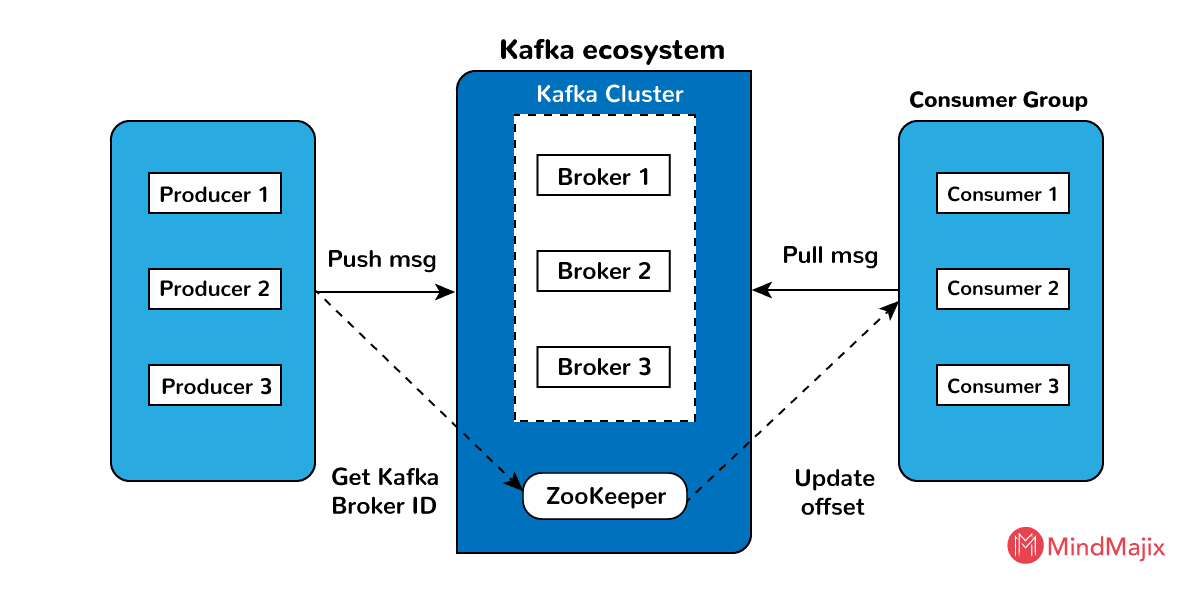
The above diagram shows the Kafka cluster architecture. The elements of the Kafka cluster architecture can be explained in the following way:
Broker: Usually Kafka cluster contains several brokers to preserve load balance. As Kafka clusters do not have states, they take zookeeper’s help to sustain cluster state. In a second, the number of reads and writes are handled by the single Kafka broker instance. Zookeeper does Kafka broker leader election.
ZooKeeper: The primary responsibility of Zookeeper is to manage and synchronize the Kafka broker. The zookeeper will notify the producer and consumer regarding the existence of the new broker or the breakdown of the broker. According to this notification, the producer and consumer will take the decision and starts synchronizing their activities with another broker.
Producer: The producer's main job is to move data to the brokers. If producers find the existence of a new broker, automatically they will forward the data to that broker. Producers do not wait for the recognition of the broker, they will send messages as soon as a broker can manage.
Consumer: As brokers are stateless, consumers have to record how many messages are spent by utilizing Partition offset. If the consumer recognizes a specific message offset, it indicates that all the previous messages are consumed by that consumer. For consuming the next message, the consumer sends an asynchronous request to the broker to make a set of bytes ready. The consumer can rewind or skip anywhere in the partition by using message offset.

Kafka WorkFlow
Kafka allows both pub-sub and queue-based messaging systems. In both systems, the producer's only job is to send the messages and the consumer's job is to choose any messaging system depending upon the requirement. Let us see the steps required for a consumer to select a messaging system.
Pub-sub messaging Workflow
- Producers send messages to the topic frequently.
- After receiving the messages from the producer, the broker stores all the messages in the partitions which are arranged for that particular topic. The broker’s other responsibility is to distribute the messages uniformly. For example, if a broker gets four messages, and there are four partitions, then the broker will store one message in each partition.
- Consumer subscribes to a particular topic.
- When the consumer subscribes to a topic, Kafka will give the current offset of the topic to the consumer and store the offset in the ZooKeeper’s ensemble.
- Consumer frequently requests Kafka for new messages.
- After receiving the messages from the producer, Kafka forwards them to consumers.
- After receiving the messages, the consumer will process them.
- After processing the messages, consumers send recognition to the Kafka broker.
- After receiving the acknowledgment, it updates the offset value, and the updated value is stored in ZooKeeper.
- The above workflow is repeated until the consumer is requesting the resource.
- At any moment, the consumer can rewind/skip to the required offset of a topic and read all ensuing messages.
Queue Messaging Workflow.
In a queue messaging system rather than a single consumer, a group of consumers who are having the same ‘group ID’ will subscribe to a topic. Consumers who are subscribed to a topic with same “group ID” are considered as one group, and the messages of that topic are shared among them. The real workflow of this system is as follows:
- At regular intervals, producers send messages to a topic.
- Like the earlier strategy, messages are stored by Kafka in the partitions designed for that particular topic.
- One consumer subscribes to a particular topic say “topic1” with “Group ID” say “Gr1”.
- The communication between Kafka and the consumer is carried out in the same manner as the pub-sub messaging system until the new consumer subscribes to that topic.
- After the arrival of the new consumer, Kafka changes its function to share mode, to share the messages between the old consumer and new consumer. This process of sharing is continued till the number of consumers equals the number of partitions designed for that topic.
- When the number of consumers surpasses the number of partitions, then the new consumer will not receive any subsequent message until any current consumer unsubscribes. This situation emerges because, in Kafka, every consumer is allocated to at most one partition. When all the partitions are allocated to current consumers, then new consumers have to wait for the partition.
- This property is known as a consumer group. Likewise, Kafka will offer the finest of both systems effectively.
[Related Article: Pega Integration]
Kafka Cluster Setup
Before installing Apache Kafka, we should check whether Java is installed in our system. To check the java installation, we should follow the below step :
Step-1: Checking Java
$ java -versionIf java is installed in your system, the java installed version is displayed. If java is not installed, you have to follow the below steps for installing java
Step 1.a: Downloading JDK
JDK can be downloaded by clicking on the URL
By clicking the above URL, you can download JDK based on your system configuration.
Step 1.b: Extracting the JDK files.
After downloading JDK in your system, open the downloads folder and check whether JDK is stored or not. After checking, extract the files from the JDK archive file(tar or rar) by using the below commands:
$cd /my/dir/downloads/path
$tar -zxf jdk-8u241-win-x32.gz.Step 1.c: Move to my directory.
Java files are made accessible to every user by extracting java files from my directory.
$su
Password: (type the password of the root user)
$mkdir /my/jdk
$mv jdk-13.0.2_windows-x64_bin.tar.gz /my/jdk/Step 1.d: Setting environment Variables and Path
For setting environment variables and paths, you should follow the below commands.
export JAVA_HOME = /user/jdk/jdk-13.0.2
export PATH=$PATH: $JAVA_HOME/bin Step 2: Installing the Zookeeper Framework
Step 2.a: Downloading Zookeeper
By visiting the below link, you can download the zookeeper framework. Click here
Zookeeper’s latest version is 3.5.6
Step 2.b: Tar file Extraction
We can extract files from tar files by following the below commands.
$cd my/
$tar -zxf zookeeper-3.5.6.tar.gz
$cd zoo3.5.6
$mkdir mydir1Step 2.c: Creation of configuration file
By executing command vi “conf/zoo.cfg” we can open the configuration file which is named as “conf/zoo.cfg”
$ vi conf/zoo.cfg
tickTime=2000
mydir1 Dir = /path/for/zookeeper/mydir1
clientPort=2181
initLimit=10
syncLimit=5After this configuration file is saved, a zookeeper can be started.
Step 2.d: Starting Zookeeper server
$ bin/zkserver.sh start
When you execute the above command, the System displays the following response:
$ JMX is enabled default
$ Using config: /user1/../zookeeper-3.5.6/bin/ ../conf/zoo.cfg
$ Starting zookeeper … STARTEDStep 2.e: Connecting to the Zookeeper server.
For connecting to the zookeeper server, you should execute the following command.
$ zkCli.shAfter executing the command, your Zookeeper server is started.
Step 2.f: Stopping the server of Zookeeper
After completing your work, the zookeeper server is stopped by executing the below command:
$ bin/zkserver.sh stopWe have successfully finished the installation of java and zookeeper. Now, let us see the installation of Apache Kafka.
Step 3: Installing Apache Kafka
To install apache Kafka into our system, the following steps are executed
Step 3.a: Download Apache Kafka
For installing the Apache Kafka into your system, you have to download it from the following URL
Step 3.b: Extracting Tar file
By executing the below commands, tar file is extracted.
$ cd my/
$ tar -zxf kafka_2.11.0.9.0.0 tar.gz
$cd kafka_2.11.0.9.0.0You have successfully downloaded the Apache Kafka into your system.
Step 3.c: Starting Apache Kafka server
The Apache Kafka server is started by executing the below command.
$ bin/kafka-server-start.sh config/server.propertiesWhen we execute the above command, your Apache Kafka will be started. You will see the parameters of the server like timeout, protocol version, roll hours, etc.
Step 3.d: Stopping the Apache Kafka server.
The Apache Kafka server can be stopped by executing the following command.
$ bin/kafka-server-stop.sh config/server.propertiesKafka use-cases
- Messaging
- Tracking Website Activity
- Metrics
- Log Aggregation
- Stream Processing
- Event Sourcing
- Commit Log
Real-time Application of Kafka
Apache Kafka is widely used on the Twitter Platform. Due to Apache Kafka users can send and receive tweets. In Twitter, logged users can view and post tweets, but users who are not logged can only see the tweets. For its stream processing, Twitter uses Storm-Kafka.
For data streaming and operational measures, Apache Kafka is used in LinkedIn. Many products of LinkedIn like LinkedIn Newsfeed, LinkedIn Today, take the help of Apache Kafka. The durability factor of Apache Kafka helps LinkedIn to use it.
Netflix
Netflix is another online platform that uses Apache Kafka for carrying out its services. It uses Apache Kafka only for event processing and video streaming.
Apache Kafka is also used by Mozilla, Oracle and many other enterprises.
Conclusion
Apache Kafka, introduced by Apache, plays a vital role in managing real-world data feeds. It offers fault tolerance if any machine fails. Kafka is speedy, it does two million writes/sec. It provides messaging in two different ways. Its simple terminology makes us understand the procedure for message passing. This Kafka tutorial is enough to acquire basic knowledge about Apache Kafka. For more information about Apache Kafka, please attend Apache Kafka Training.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Apache Kafka Training | Jul 28 to Aug 12 | View Details |
| Apache Kafka Training | Aug 01 to Aug 16 | View Details |
| Apache Kafka Training | Aug 04 to Aug 19 | View Details |
| Apache Kafka Training | Aug 08 to Aug 23 | View Details |

As a Senior Writer for Mindmajix, Saikumar has a great understanding of today’s data-driven environment, which includes key aspects such as Business Intelligence and data management. He manages the task of creating great content in the areas of Programming, Microsoft Power BI, Tableau, Oracle BI, Cognos, and Alteryx. Connect with him on LinkedIn and Twitter.














