- Home
- Blog
- Apche Spark
- Use of Graph Views with Apache Spark GraphX

- Spark Interview Questions
- Apache Spark Tutorial
- Top 5 Apache Spark Use Cases
- A Delight for Developers to Work with Apache Spark
- Apache Spark Architecture and Its Core Components
- Apache Spark Resource Administration and YARN App Models
- Building Lambda Architecture with the Spark Streaming
- Creating Apache Spark Standalone Cluster
- Rapid Application Development with Apache Spark
- Installation of Spark on Google Compute Engine
- How to Launch Apache Spark On YARN
- How to Manipulate Structured Data Using Apache Spark SQL
- Apache Spark Installation on Cluster
- Interactive Data Analysis with the Apache Spark Shell
- Learn How to Configure Spark
- Learn about What is Apache Spark Batch Processing
- REPL Environment for Apache Spark Shell
- Streaming Big Data with Apache Spark
- Spark vs Hadoop: Which is the Best Big Data Framework?
- What is Apache Pulsar
Spark GraphX and Its Importance
Use of graph has become very important in every sector. Whether it is targeted advertising or social network, graph has become mandatory. In spite of the massive demand of graphs, it is hard to find the right tool that work efficiently. This is why the graph computation task has become tiresome and difficult to maintain. For developers, it is just another name of burden. This necessity has influenced Spark to launch GraphX. It is one of the best tools that are capable to deal with extremely tough tasks.
Spark has proved itself efficient from the beginning of its journey. Spark’s GraphX is just another proof of its efficiency. GraphX is the new API of Spark for graphs like social network and web-graphs. It is also tremendous for graph-parallel computation like collaborate filtering and Page Rank. GraphX pull out the Spark RDD abstraction, at extreme level, by simply commencing the Resilient Distributed Property Graph. Resilient Distributed Property Graph indicates a directed multi-graph that has properties attached to every edge and vertex. GraphX exposes some elementary operators like mapReduce Triplets, joinVertics and subgraph along with optimized variant of Pergel API to shore up graph computation. Graphx also includes a superior collection of graph builders and algorithms. GraphX is capable of every possible task that can be expected from its kind. It will also facilitate you superior speed, efficiency and performance like always. In short, it is a complete package to serve its purpose truly.

Graph Views
Sometimes you might require extracting the edge and vertex views (RDD) of the graph. For example, if you are saving or arranging result of a calculation, you might need these. Graph class includes element like graph.edge and graph.vertexId while accessing the edges and vertices of graph. This also influences the internal representation of GraphX for the graph data.
To display user names which are above thirty years, you should use graph.vertics.
The output might look like this:
Jason is 52
Morgan is 50
Nicolas is 55
john is 45
Remember, there will be other log files too.
Checkout Apache Spark Interview Questions
A Hint for You to Keep Going
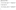
The Solution Might Look Like This
Solution – I

Solution – II

Solution – III

In Scala 2.10 the String Interpolation feature is utilized:
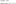
GraphX also facilitates triplet view along with the edge and vertex view for property graph. Triplet view is very important for advanced tasks. This is a view that logically connects the Edge and vertex properties. The connection is made by yielding the RDD [Edge – Triplet [ VD, ED ] ]. This also contains the class of Edge_Triplet instances. The Edge class is extended by the EdgeTriplet class by accumulating the dstAttr and srcAttr elements. This also contains the destination and source properties respectively.
If you employ graph_triplets view to show people’s likings, the output might be:
Jack likes Sara
Jack likes Dev
Al Pacino likes Jack
Al Pacino likes Fran
Dev likes Sara
Robert likes Jack
Sara likes Al Pachino
Robert likes Al Pacino
Robert likes Fran
Sara likes Fran
The Solution Which Might Be Partial
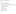
A Simple Solution
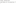
If you are willing to locate someone who likes something else five times then you can use this:
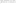
Graph Algorithms
GraphX possess a superior set of algorithms. It is the algorithm that is making GraphX popular. Graph algorithms are capable of maintaining complex tasks. These algorithms simplify the analytical tasks. Graphx algorithms are efficient and they serve the purpose greatly. These algorithms are introduced below:
PageRank
The importance of every vertex in a graph is measured by the PageRank algorithm. In another word, an edge from U to V signifies an endorsement of V’s significance by U. For example, if you are a pinterest user and you are followed by numerous people, you are likely to be ranked higher. This is a simple but significant algorithm of GraphX.
GraphX complies with both dynamic and static implementations of PageRank according to the methods on the Pagerank Object. Dynamic PageRank operates as long as the ranks congregate but the static PageRank operates for a specific number of iterations.
Social network dataset example of PageRank:
If users are listed in the graphx/data/users.txt and relationship data is listed under graphx/data/followers.txt, you can calculate the PageRank of each user.
The procedure is as follows:
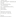
Connected Components
This algorithm tags every connected component of graph with the lowest-numbered vertex ID.
Example of Connected Component Algorithm:
Connected components can estimate clusters in a social network. In the Connected Components object, GraphX can enclose the execution of the algorithm. You can calculate the connected components from the social network datasets of the PageRank segment as follows:
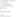
Triangle Counting
A vertex can be a triangle if it has two joined vertices with an edge among them. GraphX execute the triangle counting algorithm in the TriangleCount object. This object calculates the triangles intersecting the vortex. It also provides measure of clustering. Triangle count can be like this with the social network datasets of the PageRank segment.
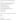
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Apache Spark Training | Aug 01 to Aug 16 | View Details |
| Apache Spark Training | Aug 04 to Aug 19 | View Details |
| Apache Spark Training | Aug 08 to Aug 23 | View Details |
| Apache Spark Training | Aug 11 to Aug 26 | View Details |

Ravindra Savaram is a Technical Lead at Mindmajix.com. His passion lies in writing articles on the most popular IT platforms including Machine learning, DevOps, Data Science, Artificial Intelligence, RPA, Deep Learning, and so on. You can stay up to date on all these technologies by following him on LinkedIn and Twitter.














