- Home
- Blog
- Apche Spark
- How to Launch Apache Spark On YARN

- Spark Interview Questions
- Apache Spark Tutorial
- Top 5 Apache Spark Use Cases
- A Delight for Developers to Work with Apache Spark
- Apache Spark Architecture and Its Core Components
- Apache Spark Resource Administration and YARN App Models
- Building Lambda Architecture with the Spark Streaming
- Creating Apache Spark Standalone Cluster
- Rapid Application Development with Apache Spark
- Use of Graph Views with Apache Spark GraphX
- Installation of Spark on Google Compute Engine
- How to Manipulate Structured Data Using Apache Spark SQL
- Apache Spark Installation on Cluster
- Interactive Data Analysis with the Apache Spark Shell
- Learn How to Configure Spark
- Learn about What is Apache Spark Batch Processing
- REPL Environment for Apache Spark Shell
- Streaming Big Data with Apache Spark
- Spark vs Hadoop: Which is the Best Big Data Framework?
- What is Apache Pulsar
Apache Spark On YARN
No doubt, Spark had grown rapidly with additional frameworks, such as the Spark Streaming, SparkML, Spark SQL, Spark GraphX, and in addition to these “official” frameworks bring a lot of additional projects – various connectors, algorithms, libraries, and so on. It is enough to quickly and confidently look into it when a serious lack of documentation, especially given the fact that the Spark contains all sorts of basic pieces of other projects Berkeley (eg BlinkDB), is not easy.
RDD – The Classic Concept of Spark
In fact it is reliable distribution table (actually RDD containing an arbitrary collection, but it’s best to work with the tuples in a relational table). RDD can be completely virtual, and just to know how it generated to, for example, in the event of a node failure, recover. And maybe it materialized – distribution in memory or on disk (or in the memory of displacement on the disc). Also, inside RDD is divided into partitions – a minimum amount of RDD, which will be processed by each work unit.
All the fun is happening in Spark, occurs through the operation of the RDD. There is a usual structure of any Spark application developing – creating RDD (eg pull out the data from HDFS), working with it (map, reduce, join, groupBy, aggregate, reduce, etc.), and doing something with the results – such as throwing back to HDFS.
And the basis of this understanding should be Spark regarded as a parallel environment for complex analytical tasks, especially where there is the master, who coordinates the mission, and a lot of operating units that are involved in the implementation.
Getting Started: How to Launch Spark on Yarn
For a start, it is necessary to make sure that YARN – CONF – DIR or HADOOP – CONF – DIR indicates needed a directory which stores files for configuration in the cluster Hadoop Later. These configurations will be used to write the Apache Spark in HDFS and will establish direct connection to Resource Manager YARN. Configurations from this directory are supposed to be distributed on a cluster, that’s because all the containers located within the boundaries of the application also use these configurations. All of configurations that are referred to Java system environment variables also need to be set in Apache Spark for its correct usage.
Also YARN uses two different deploy modes for loading Spark applications on it. The first is YARN cluster mode that provides Spark drivers a possibility to run inside applications that YARN manages on cluster, so client may go away once the initialization of processes in the app is done.
The second one is a Mesos mode that uses specifications of master’s address like a parameter. So, there are some differences between YARN mode and Mesos mode, because the first one is taken from configuration of Hadoop. Below is program code for loading cluster-mode YARN:
Checkout Apache Spark Interview Questions

More examples:
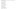
The code of program begins a process of run default Application-Master which is one of component of Apache Spark. After completing of loading AM runs SparkPi as a child-thread. Then traditionally the client’s status updates with some period and console displays the result. Also, if client exits from session, application would be finished. You also have to do the same when you require launching the Spark in the Mode of Yarn Client. However don’t forget to swap the yarn cluster with the yarn client. So if you want to start it, just run this code:
$./bin/spark-shell –master yarn-client
Using Additional JARs for Completing
As mentioned above, Apache Spark has 2 different modes, so let’s talk about the first one which is YARN-clustered. In this mode client and driver run different machines, so one of jars which is SparkContext.addJar wouldn’t be launched, because it is not stored in local files of needed repository on client side. So, to solve the problem you should add this jar-file to repository for making it available by client and include –jars option:
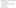
After this command SparkContext.addJar will be loaded on client-side
Something That’s Better to Do Before
If you want to run Spark on Yarn – it’s better to pre-install package with binary distributed Spark, which has a support of YARN. This package can be also downloaded from official Spark web-site.
Installation and Configuration
When all of actions, that are written above are done, your next step is configuration of Apache Spark. A lot of configurations are similar for YARN Spark, so it shouldn’t be difficult to set this software on. But also, it’s better to look through configuration page on Spark web-site to find additional information about configs. All of these configurations are only specified on YARN version of Spark, please, notice this fact.
Application Debug
There are some special determinations, which say us that all of application masters and executers of application run in “containers”. Also, we already know about two different deploy modes that YARN uses for handling logs of container. If you turned aggregation log on, all of logs of container will be copied into HDFS, and then will be erased from local machine. Also, below is example of such command:

This command will display all log-files in all containers, which are used in application. Also, you have a possibility to review files of log in HDFS or to use API or HDFS Shell. In reason to find the local directory, where configs are saved, you can simply view on config-name path.
The next variant is disabled log aggregation. In this way, all of logs are saved on local machines under the YARN APP (LOGS – DIR), that is normally constituted to the tmplogs. However, it depends on version of Hadoop and your installation preferences. So, in reason to review the container logs, you should go on localhost, where these logs are contained and review them in given directory. You should notice that logs are organized by container ID or application id in subdirectories.
There is a feature for reviewing launching of per-container. Because of delay of process is pretty small, you should change this property to large amount. But this is not the end: you should get access the cache of application through the yarn – node_manager – local.dirs. It is very useful when there is a reason to debug problems. But don’t forget, that you should have admin privileges to do it.
If you want to utilize a custom configuration log4j, you’ll be provided with two variants of further continuation:
- Uploading custom properties. If you choose this option, you should upload log4j properties while using the spark_submit, and then add –files to the file-lists, which are uploaded using the app.
- Adding new properties in log. You should change -Dlog4j.configuration= in spark.executor.extraJavaOptions (for executors) or spark.driver.extraJavaOptions (for the driver). Also, you should note, that you have to explicitly provide file protocol and files will exist automatically on all local machines.
Sometimes, you have situations, when you need to get some references of proper location for putting files of log into YARN, and you are already provided for this option by YARN. Just execute these commands:

If you want to stream an application just configure RollingFileAppender, but the main problem that you should solve is disk overflow, so it’s better to clean cache and files, that you don’t need.
There are a lot of Spark properties, which you may use in future. If you want to know more about it, just look through official Spark web-site and find page with Spark properties. You’ll find proper information, which includes Property Name, Default Value and Description of what this property does.

Additions to Apache Spark
- SparkSQL: SQL engine on top of Spark. As we have already seen, Spark has almost everything needed for this, other than storage, index and its statistics. This seriously hampers the optimization, but the team SparkSQL claims that they are establishing a new optimization framework, as well as AMP LAB (Laboratory where grown Spark) is not going to give up the project Shark – complete replacement of Apache HIVE
- Spark MLib: This is essentially the replacement of Apache Mahaout, only much worse. Apart from efficient parallel machine learning (not only by means of RDD, and additional primitives) SparkML still much higher quality work with local data. Also it uses linear algebra package, which will draw you in to the cluster Fortran code. Well, very well thought out API. A simple example is that parallel are trained on a cluster with cross-validation.
Are you looking to get trained on Apache Spark, we have the right course designed according to your needs. Our expert trainers help you gain the essential knowledge required for the latest industry needs. Join our Apache Spark Certification Training program from your nearest city.
Apache Spark Training Bangalore
These courses are equipped with Live Instructor-Led Training, Industry Use cases, and hands-on live projects. Additionally, you get access to Free Mock Interviews, Job and Certification Assistance by Certified Apache Spark Trainer
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Apache Spark Training | Jul 28 to Aug 12 | View Details |
| Apache Spark Training | Aug 01 to Aug 16 | View Details |
| Apache Spark Training | Aug 04 to Aug 19 | View Details |
| Apache Spark Training | Aug 08 to Aug 23 | View Details |

Ravindra Savaram is a Technical Lead at Mindmajix.com. His passion lies in writing articles on the most popular IT platforms including Machine learning, DevOps, Data Science, Artificial Intelligence, RPA, Deep Learning, and so on. You can stay up to date on all these technologies by following him on LinkedIn and Twitter.














