
Data arrives from all directions, increasing in scale and difficulty. So, enterprises need a high-performance data platform that is developed for self-service and automation, that grows among the changes and adapts to the latest realities, and that can resolve the hardest data management and data processing challenges in business computing.
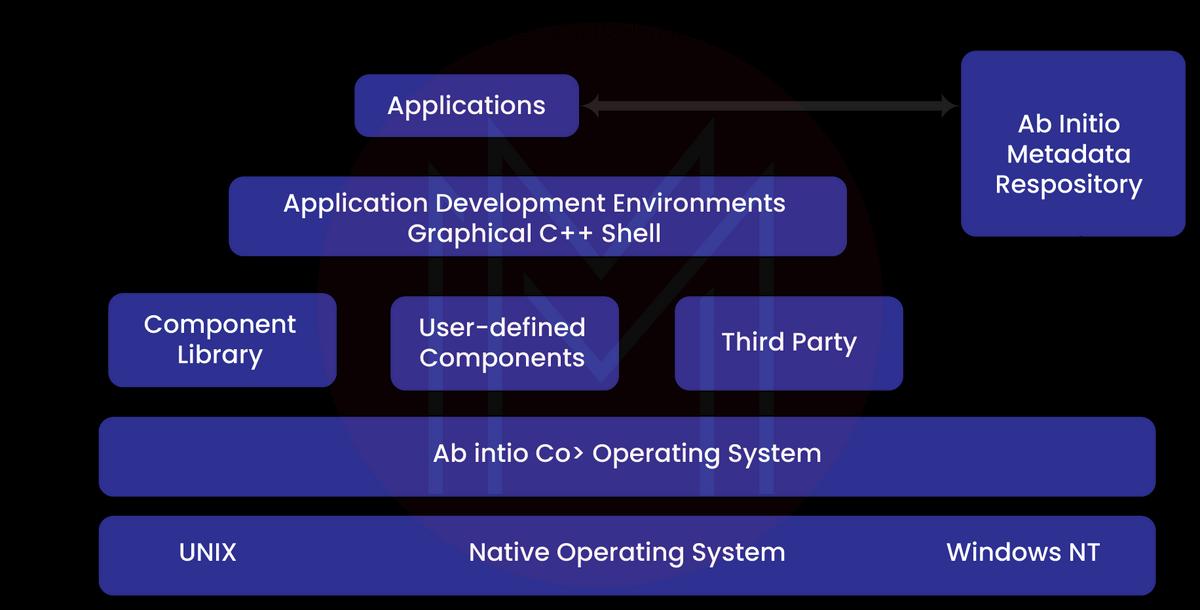
Ab Initio is a fourth-generation data analysis, data manipulation, graphical user interface, and parallel processing-based software for extracting, manipulating, and importing data. Ab Initio keeps up with advanced technologies such as Hadoop and Big Data by providing equitable interfacing mechanisms and by undergoing constant development.
It is primarily utilized by data warehouse companies, and the utilization is increasing by other verticals in the IT industry. So, it is the right time to learn Ab Initio and make a career. This Ab Initio tutorial will help you learn to perform ETL operations using Ab Initio.
What is Ab Initio?

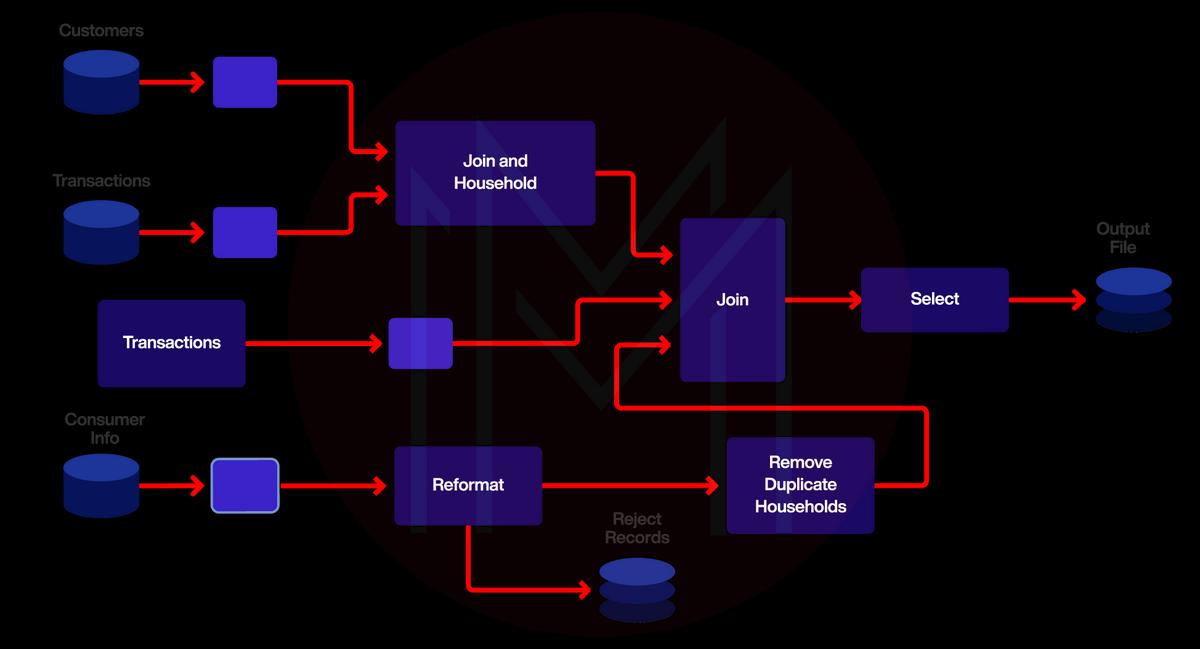
A data warehouse is just one part of the Ab Initio suite of applications. A system that works well "from scratch" is often called "Ab Initio" or "from scratch" cooperation. This is also known as an ETL tool with a graphical user interface. It's as simple as dragging and dropping to connect the various parts. Ab Initio is a technology for processing huge datasets in parallel that is used in the ETL. Extract, Transform, and Load is the acronym for the three processes involved in this workflow.
Extract
The extract is the process of fetching the required data from the supply file, like a computer fle, information, or a different supply system.
Transform
This process transforms the extracted data into an understandable format. It involves the following tasks:
- Using Business Rules (derivations, hard new values, and dimensions)
- Cleaning
- Filtering (only the selected columns to load)
| If you want to enrich your career and become a professional in ETL Tool, then enroll in "ETL Testing Training". This course will help you to achieve excellence in this domain. |
Ab Initio ETL Tool Architecture
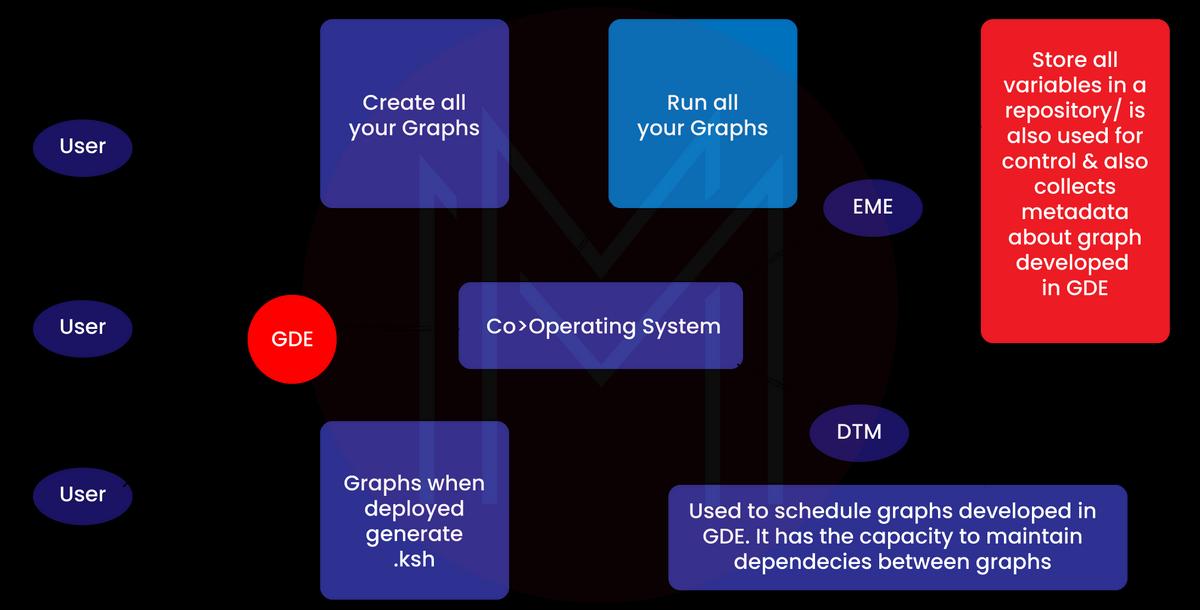
In the beginning, there can be the business intelligence code with the half-dozen processing products:
- Cooperating system
- Graphical Design Environment
- Enterprise Meta>Environment
- Data Profiler 5
- IT Conduct
Cooperating System
This section includes the following features:
- Run and manage graphs and ETL processes at the start.
- ETL processes for monitoring and debugging.
- The software system receives ab initio extensions.
- Assists in interacting with the managing data and EME.
Graphical Development Environment (GDE)
- This part shows the developers how to run and build abinitio graphs.
- Ab Initio graphs depict the ETL method at the beginning and include parts, information streams (flow), and parameters.
- This offers an easy-to-use front-end application to create ETL graphs.
- It runs and corrects the jobs at the beginning. It monitors the execution logs.
- At the beginning, we used the compilation method. ETL graphs result from knowledge of an operating system shell script that can be monitored.
Enterprise Meta Environment
- This comes at the beginning of the atmosphere and repository used for managing and storing data.
- It has the skill to store all the business and technical data.
Data Profiler
This runs on a high-performance operating system in a graphical environment and is an analytical application that can confirm information variation, quality, distribution, variance, and scope.
Conduct IT
This is a place where people can work together to make the first systems for integrating information. The main goal of this environment is to make at-the-start plans, which are special graphs. As a first step, Conduct IT comes with both a command line and a graphical interface.
| Related Article: Ab Initio Interview Questions |
Differences Between ETL and BI
Data warehouses rely heavily on ETL technologies, which are used to gather information from several sources, convert it, and then put it into a centralized repository. A business integration tool can produce dashboards, data visualizations, and reports for senior-level data management that are both interactive and generated on-the-fly for end-users.
The most commonly used ETL tools are data Informatica, SAP BO data service technology (BODS), Oracle data integrator ODI tool, and power center, MSIS. There are many popular BI tools included, such as Oracle business intelligence platform, SAP business objects, Microsoft BI platforms, Jasper soft, SAP lumira, Etc.
Implementation of Application Integration Using AB Initio
Here, we'll go through the fundamentals of application integration. The following diagram describes the comprehensive design architecture and structure utilized to consolidate data from many sources into a centralized repository, which was then loaded into the CRM system.
The following are the major challenges:
Multiple sources: Data comes from many places, like Oracle tables or mainframes, and is stored in different ways and formats and is loaded at different rates.
Complex business logic: Data purification methods, target systems, and generic entities will help you reach your goal of a standardized data format.
Redundancy: Same data from multiple data sources due to data duplication.

AB Initio System Tool Functions

The following are the features of the AB Initio system tool:
- It offers access to the PAI query facility.
- Generate new codes with the help of a rules engine that is driven by metadata.
- It transfers the information to the operational databases.
- Data before and after "delta" photographs are also provided.
- Data extraction and loading are both handled graphically through the database interface.
- Provides data to the intended system and any related reporting or messaging tools.
AB Initio Method Advantages
The following are the benefits of AB Initio methods:
- Ab initio can provide information about folding mechanisms.
- Aids in the comprehension of protein misfolding.
- Does not need homolog techniques.
- A new protein can be designed using the ab initio model.
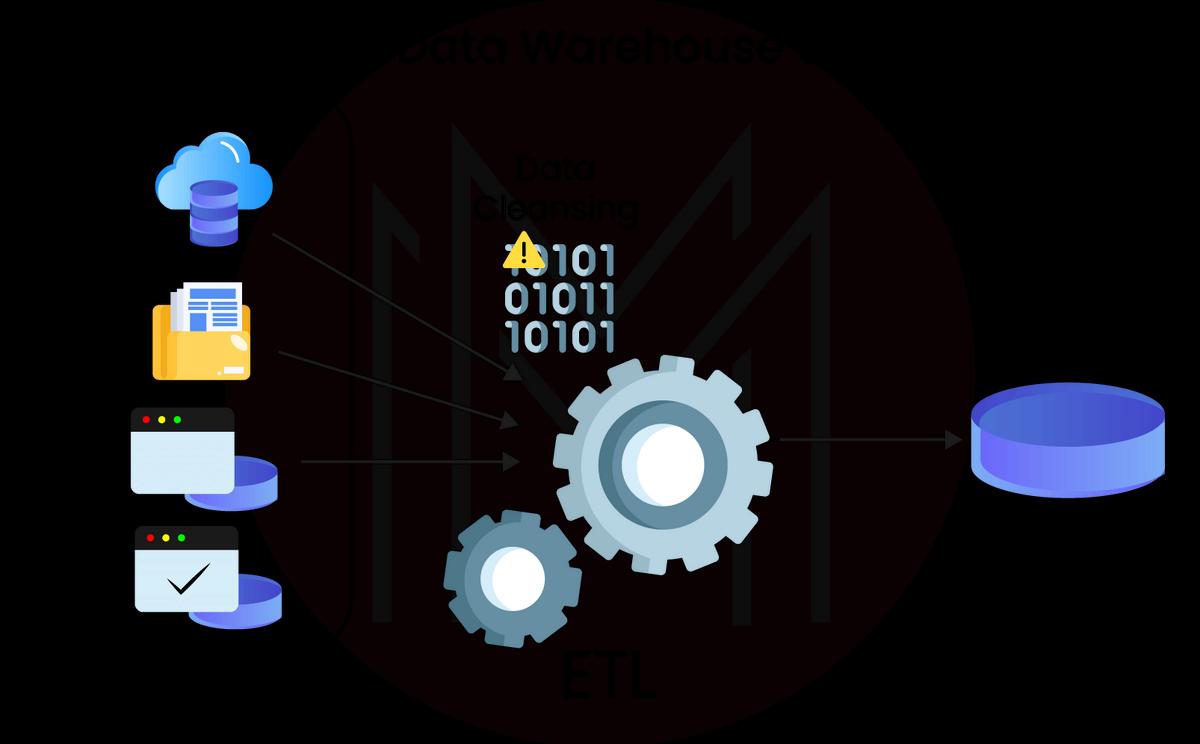
ETL Process Overview
Obtaining the data: During this step, you can pull data from a variety of different data sources. The process of getting the data varies based on what the organization needs.
Changing the data: At this point, you can change the data into a format that can be used to load it into a data warehouse system. Data transformations include things like applying calculations to data, joining procedures, and setting up the primary key and foreign key. These changes include correcting data, getting rid of data, making partial data, and fixing mistakes. This also combines and formats conflicting data before it is loaded into a data warehouse system.
Loading data warehouse systems: At this point, you may start importing your data into your preferred data warehouse of choice and begin generating insightful insights. The envisioned solution has the flexibility to store information from both flat files and data warehouses.
ETL Tool Functions
The staging layer: Also known as the staging database, stores data extracted from various data source systems.
Data integration layer: This layer is in charge of transforming and transmitting data from the staging layer to the database. The information is categorized using dimensions, which are subsequently turned into facts or aggregate facts. A data warehouse schema is a table containing both factual and dimensional aggregates.
Access layer: This layer is generally used by the end-user to retrieve data for information storage and analytical reporting.
ETL Testing
Important tasks in ETL testing include:
- Know the data utilized for analysis and reporting.
- Analyze the data model's architecture.
- Source-to-target mapping is performed.
- Facilitates the cross-referencing of data from several sources.
- Validation of packing and schema.
- Facilitates data verification within the data source system of interest.
- Data transmission, calculation, and validation of aggregation rules.
- Sample data comparison between any source and any target system.
- In the source system, data integration and quality assurance tests are performed.
- Contributes to diverse data testing
ETL Testing Categories
Objective testing and data reporting can categorize ab initio ETL testing. The ETL Testing is classified as follows.
1. Source to target count testing
In this kind of testing, both the target system and the source system must have the same number of data records.
2. Source to target data testing
Data from the source system is checked against data in the target system to ensure accuracy. This testing is useful for deleting duplicate data values in the target system, checking data for thresholds, and integrating new data.
3. Testing Data mapping or Data transformation
This sort of test double-checks that the mapped data between the source and target systems is accurate for every given object. This also includes checking how data is handled in the intended system.
4. End-user evaluation
Making sure the information provided in the reports is sufficient necessitates generating them for end-users. In order to validate the report, this testing also looks for discrepancies within it and compares it to data in the intended system.
5. Retesting
Data in the target system must be validated by eliminating any errors and running reports to determine the state of the data.
6. Testing the system integration
This requires testing each unique source system and aggregating the data to determine if there are any deviations. There are three primary options available here:
- Top-down strategy
- Bottom-up strategy
- A hybrid strategy
Other Categories for ETL Testing are as Follows
1. Testing of a new data warehouse system
During this ETL testing, your new data warehouse system can be built, and the data can be checked to make sure it is correct. End users or customers can provide data from different data sources, which can be used to build a new data warehouse.
2. Testing for migration
In this kind of testing, the customer already has a data warehouse and an ETL tool, but they want a new ETL tool to make their data more efficient. For this testing, data needs to be moved from the old system to a new ETL tool.
3. Alteration Testing
New information from a wide variety of sources will be included into the preexisting system as part of this round of testing. Here is also where customers can make adjustments to, or completely replace, any preexisting ETL rules.
4. Test results
In this kind of check, the user can generate reports to validate data. Any data warehouse should ultimately produce reports. Reports can be tested in many ways, including with different layouts, data reports, and computed values.
AB Initio ETL Testing Techniques
Testing for production validation: This testing method is used to do analytical data reporting and analysis, as well as checks for the system's validation data. Data that is sent to the production system can be tested for production validation. This type of testing is called "critical testing" because it uses a method for validating data and compares the data to the source system.
Testing of the source to target count: This kind of test can be carried out when the test team has limited resources and is thus unable to do comprehensive testing. During the targeted testing phase, the number of records in both the source and target databases is compared. Keep in mind, too, that there is no need to sort the numbers in any particular order.
Data testing from source to target: In this kind of testing, a testing team changes the values of the data that is being sent from the source system to the target system. As a result, the values of the linked data in the target system are checked. This way of testing takes a long time and is usually used in things that have to do with financial services.
Data integration: In this form of testing, a team will verify the data ranges. If the intended system requires reliable results, then we must verify all threshold data values. With this method, you can combine information from many sources in the target system after data transfer and loading have been finished.
Application migration testing: Testing done in preparation for a migration from one application system to another can help you save a lot of time and effort during the migration process by facilitating the extraction of data from legacy systems.
Constant testing and data verification: This testing comprises an index, data type, and data length checks, among others. In this situation, the testing specialist does checks for the foreign key, primary key, Unique, NULL, and NOT NULL.
Testing for data duplication: To use this approach, one must search for instances of duplicate information in the intended database. When the data in the target system is extensive, it's also likely that there are copies of such information in the live system.
Testing for Data Transformation: Testing a data transformation does not include just one SQL statement. Although it is time-consuming, this approach allows you to perform many SQL queries to verify transformation rules. The SQL statement queries will be executed and compared by the testing team.
Data quality assurance testing: Operations like checking numbers, dates, for null numbers, and precision checks are all part of this category of testing. Syntax checks are also performed by the testing team to identify typos like invalid characters or wrong case ordering. To further guarantee that the data is accessible in accordance with the data model, reference tests are also carried out.
Iterative testing: It is possible to verify the integrity of the data insert and the SQL queries with incremental testing. The anticipated outcomes can be obtained by using these SQL commands. This method of testing is carried out in phases, during which both the old and new values are put to the test.
Regression analysis: Whenever a new capability is added via a change to the rules that transform or aggregate data. The testing crew can use this information to help find regression testing for new errors. This flaw manifests itself during regression testing as well.
Retesting: The process of running the tests again once any flaws have been fixed is referred to as retesting.
Testing for system integration: Component testing and module integration are both part of system integration testing. Top-down, bottom-up, and hybrid methods of system integration can be used depending on the specifics of the situation.
Navigation evaluation: Testing of the user interface is also known as testing of the navigation system. All features, including individual fields, aggregates, and calculations, can be tested from the perspective of the final consumer.
Ab Initio – ETL Process
This Ab Initio testing includes ETL lifecycles and aids in the understanding of business requirements. The following are the typical steps in the ETL life cycle:
Step 1: Aids in the comprehension of business requirements
Step 2: Business requirement process validation.
Step 3: The time required to execute the test cases is estimated in this phase of the test process, and a report summarising the test process is generated.
Step 4: Methods for designing tests involve selecting approaches for testing based on data inputs and business needs.
Step 5: Helpful for creating test plans and test cases.
Step 6: After the test cases have been reviewed and are ready to run, any pre-execution checks can be carried out.
Step 7: Allows you to run all of the test cases.
Step 8: Producing a thorough test summary report and documenting the test closing procedure is the last and most critical step.
Query Surge Process
Query surge is a tool for testing data that can be used to test big data, test a data warehouse, and do the ETL process. This process can fully automate testing and works well with your DevOps strategy.
Here are the most important things about query surge:
1) It is made up of automated query wizards that produce results for testing. It's easy to make query pairs without having to write any SQL.
2) There is a design library with query snippets that can be used more than once. Also, you can make your own query pairs.
3) This thing can compare the values of the data in the source files to the values of the data in the target big data warehouse.
4) It can quickly and easily compare the values of millions of columns and rows of data.
5)With Query Surge, the user can also set tests to run right away at any time or date.
The ETL tool's query surge using command API to automate any operation should begin as the ETL software load procedure is complete. The United Nations monitors and controls all testing procedures and the process of inquiry surge is automated.
Future of Ab Initio ETL
ETL tools such as Ab Initio are seeing a shift toward more versatile technologies such as Big Data. That being said, Ab Initio will undoubtedly be around for a long time because companies have invested heavily in licenses, training, and system development.
Ab Initio FAQs
1. What is Ab Initio used for?
The Ab Initio tool is a fourth-generation batch-processing application, data manipulation, and data analysis with a graphical user interface (GUI) that is used to Extract, Transform, and Load (ETL) data.
2. Who uses Abinitio?
Customers of Ab Initio work in data-intensive industries such as finance, telecommunications, retail, healthcare, manufacturing, insurance, e-commerce, transportation, and logistics, to name a few.
3. What is the role of an Ab Initio developer?
An Ab Initio Developer will oversee software integration and system testing. An Ab Initio Developer is also responsible for creating and running user acceptance tests and implementing software changes.
4. Is it easy to learn Ab Initio?
There aren't many requirements to start and finish the course. However, having a basic understanding of BI tools and databases will aid in understanding the subject.
5. Is Ab Initio a good ETL tool?
This application is excellent for Big Data processing and all extract, transform, and load tasks. This application's components are diverse and designed for various complex scenarios. Overall, a very good data cleansing and processing tool.
6. Does ab initio require coding?
Non-programmers can create complex logic using Ab Initio's visual programming model and graphical development environment.
7. What is an ab initio ETL developer?
The ETL Ab Initio Developer is in charge of creating the next generation of global financial data systems to help our clients with front, middle, and compliance reporting, regulatory reporting, KYC, banking needs, and capital markets.
8. What is the prerequisite to learning Ab Initio?
Because AB Initio is a simplified coding tool, no special knowledge is required. Anyone with a basic understanding of any programming language and some industry experience.
Explore Ab Initio Admin Sample Resumes! Download & Edit, Get Noticed by Top Employers!
Conclusion
Ab Initio is an extensively used business intelligence data processing system for building several business applications - from operating systems and complex event processing to data quality and warehousing management systems. This Ab Initio tutorial includes every core concept of Ab Initio, like Architecture, Functions, ETL testing, Ab Initio ETL Process, etc. If you’re looking forward to learning and master in ETL then enroll in this Testing Course by MindMajix today.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| ETL Testing Training | Jul 28 to Aug 12 | View Details |
| ETL Testing Training | Aug 01 to Aug 16 | View Details |
| ETL Testing Training | Aug 04 to Aug 19 | View Details |
| ETL Testing Training | Aug 08 to Aug 23 | View Details |

Madhuri is a Senior Content Creator at MindMajix. She has written about a range of different topics on various technologies, which include, Splunk, Tensorflow, Selenium, and CEH. She spends most of her time researching on technology, and startups. Connect with her via LinkedIn and Twitter .














