- Home
- Blog
- Data Science
- Data Cleansing

- Big Data Vs Data Science Vs Data Analytics
- Data Science Interview Questions
- Top Data Science Tools
- Data Science Tutorial
- Data Science with R Interview Questions
- Overview of Data Modeling for Unstructured Data in Data Science
- What is Data Scientist?
- What is Data Visualization?
- What is Data Science
- What is Data Analytics?
- Job Roles For A Data Science Enthusiast
- RapidMiner Tutorial - Introduction To RapidMiner
- Top 12 Data Science Resources
- Data Scientist Interview Questions
- Programming Languages For Data Science
- MATLAB Interview Questions
- Data Engineer Interview Questions
- Data Visualization Interview Questions
- Toughest Courses in India
- Data Mining vs Data Science
- Data Scientist Job Description
As a business continues to grow, the number, size, types, and formats of its data assets also increase along with it. Evolution in business-associated technologies, the addition of new hardware and software, and the combination of data from various sources will eventually create a data storage that includes duplicate records, redundancies, missing information, corrupted data, and more.
The process to rectify and alter such data in a given storage resource and make sure that all the data are correct and accurate is called Data cleansing or data cleaning or data scrubbing.
Enthusiastic about exploring the skill set of Data Science? Then, have a look at the Data Science Certification Course Today.
The topics which we are going to cover in this article are as follows.
| Table of Content - Data Cleansing |
How Data Cleansing is useful?
Managing data optimally and ensuring that it is clean can offer significant business value. Marketing surveys found that nearly half of the departments in a large business enterprise do not use data effectively due to redundancies and data complexity. Data cleansing can help businesses to achieve a long list of benefits which can lead to maximizing profits with less operational costs.
| If you want to enrich your career and become a professional in Data Science, then enroll in "Data Science Online Training" - This course will help you to achieve excellence in this domain. |
List of Data Cleaning Benefits
Improves Custom Acquisition-Related Activities: No matter the size, businesses can significantly boost their customer acquisition activities by cleaning their data. A more efficient potential prospect list with accurate data can be created more efficiently. Clean data will also ensure the highest returns on email campaigns as chances of encountering outdated addresses will be exceptionally low.
Better Decision Making: Precise data is the cornerstone of effective decision making Clean data supports better analytics as well as complete business intelligence which facilitates better decision-making and execution of business decisions.
Streamlined Business Process: Removing duplicates and unnecessary databases will eventually magnify business practices and save a good amount of money for businesses. With data cleansing, particular job descriptions of an organization can be determined. The accurate sales information obtained from a service or product can be easily assessed. Access to the right analytics with data cleansing will help enterprises to identify the right opportunities to launch services and products in the market.
Increased Productivity and Revenue: Access to a properly maintained and clean database can help businesses to ensure complete productivity of employees, and optimal use of manhours on productivity, thus resulting in increased revenue. Clean data reduces the risk of fraud, making sure staffs have accurate customer or vendor data for various steps of business operation.
| Related Article: Data Science Interview Questions and Answers |
Steps For Data Cleansing
1. Removal of Unwanted Observations
This is the first and foremost step of data cleaning. It removes the unwanted observations from the targeted dataset. It has two steps; duplicate and irrelevant.
- Irrelevant Observations: These observations don’t fit accurately with the specific problem that the user is trying to solve. During this step, the user has to review charts from the Exploratory Analysis.
- Duplicate Observations: This type of observation arises frequently during data collection and user-associated processes to it such as scraping data, a combination of datasets from multiple destinations, and receiving data from different departments or clients.

2. Fixing Structural Errors
The next step of data cleaning is the fixation of structural errors. These types of errors mostly arise during data transfer, measurement, and poor data-keeping. Structural errors include mislabelled classes, name feature typos, use of the same attribute with different names, etc.
3. Managing Unwanted Outliers
Unwanted outliers can cause serious issues with certain types of data models. When a user legitimately removes an outlier, it exceptionally improves the model’s performance. Thing to remember here is, that unless the outlier is proven unwanted or included with suspicious measurements, the user should never remove it.
| Related Article: Which One is Better? - Big Data vs Data Science vs Data Analytics |
4. Handling Missing Data
This one is probably the most complex step of data cleansing. As most of the algorithms don’t accept missing values, the user has to manage the missing data in some way. The two most commonly recommended ways to manage missing data are:
- To drop observations for data that have missing values.
- To impute the required missing values based on observations.
Both of these steps are sub-optimal. The users simply drop information when they drop information. The second step is sub-optimal because of originally missing values that users have to fill. No matter how sophisticated the imputation method is, this always leads to a loss of information.
Data missingness is always informative in itself and the user requires to inform an algorithm if a value was missing. Even if the user builds an effective model to impute the values, it will not add any real information as it will be like reinforcing the patterns that are already provided by other features.
- Missing Categorical Data: As per data science, labeling the missing data for categorical features as ‘missing’ is the best way to handle them. This step includes essentially adding a new class for the feature. This also nullifies the technical requirement for no missing values.
- Missing Numeric Data: The user has to flag and fill in missing numeric data. To perform this, the user needs to flag the observation with a missingness indicator variable. Then, replace the missing values with zero to meet the technical requirement of missing values.
| Related Article: Data Science Tutorial for Beginners |
What are the Tools in Data Cleansing?
OpenRefine
Previously known as Google Refine and Freebase Gridworks, OpenRefine is a popular open-source desktop application for data cleanup and transformation to other formats. Launched in 2010, it is available for Windows, macOS, and Linux.
Trifacta Wrangler
It enables users of all skill levels to work with diverse, complex data within a desktop application without any cost. It works for self-service data preparation and data exploration analysis. It works both on on-premise and cloud data platforms.
TIBCO Clarity
This data cleansing tool brings self-cleansing capabilities to businesses. It is available both as a cloud service as well as a desktop application and has the extreme capability to cleanse data for a wide range of business purposes.
Cloudingo
Cloudingo expertly consolidates data and eliminates redundancies to help organizations taking better and smarter decisions. It will help with better data load, data duplication, data confusion removal, and plenty more other data management purposes.
IBM Infosphere Quality Stage
IBM Infosphere QualityStage offers an exclusive graphical framework that can be used to perform activities related to data cleansing and transformation. The programs run on the IBM InfoSphere Information Server engine.
JASP
JASP is an open-source and free graphical program designed for easy statistical analysis. It offers standard analysis procedures in both Bayesian and classical forms. It has a great user-friendly interface and is specially developed for publishing analysis.
RapidMiner
RapidMiner is an advanced and multipurpose data science software platform that can be used for data preparation, model deployment, machine learning, predictive analysis, and text mining. It can help businesses to drive better revenue, reduce costs and avoid data risks.
Orange
It’s a completely open-source machine learning and data visualization software available for both experts and novices. It can be used to perform simple data analysis with great data visualization, statistical distribution, box plots, decision trees, hierarchical clustering, linear projections, MDS, and more.
Talend Data Preparation
Talend data preparation is a free desktop tool that simplifies and automates data cleansing with a user-friendly visual platform. It enables users to quickly build reusable data preparation and it can also combine import and export data from an excel database or CSV file.
| Related Article: Goldman Sachs Interview Questions |
Data Cleaning Methods in Excel
Get Rid of Extra Spaces
The TRIM function can be used to exclude the extra space. CLEAN and SUBSTITUTE functions can also be used combined with it. The TRIM function takes a single argument which can be a text that user manually types or a cell reference.
Syntax: =TRIM(Text)
Select and Treat All Blank Cells
Select the entire database. Now access the find and select and select the Go to Special option which will open a special dialog box for your use. Click on the Special button and again it will open a special dialogue box.

Select the Blanks option which will select all the blank cells present in the data at the same time. To type not appear in all the blank cells just start typing not appear and press ctrl+enter and this will get into all the cells.

Convert Numbers Stored as Text into Numbers
There are two steps to converting numbers from text format back into number formats. The first one is to go to the formatting box and type general and press enter. The second option is used for numbers in text format with the use of the apostrophe. To take care of this data issue, follow these steps.
- Type in any of the blank cells
- Go to the cell and copy that
- Now select these cells and go to paste
- Select paste special button which opens a special dialog box
- Access the operation category and select multiply and press okay
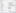
It will change all the numbers with apostrophes back into a plain number format.
| Related Article: Overview of Data Modeling in Data Science |
Remove Duplicates
There are two ways available to remove duplicate values in excel. The first one is conditional formatting. To perform this:
- First, select the data set
- Go to Home and access conditional formatting
- Select Highlight Cells Rules, then Duplicate Values
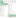
- It will open options to highlight duplicates and the formatting
- Select your preference and it will reflect on all duplicate values
- And, then manually delete them
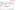
The second process starts by selecting the entire set. Now, go to the Data and select the option to remove duplicates. It will open the remove duplicate dialog box. Select the preference and press okay.
Highlight Errors
- To address this data issue, follow the below-mentioned steps.
- First, select the entire dataset
- Go to Home and select Conditional Formatting
- Now Choose the New Rule option
- The new formatting rule dialog box will open now
- Select the format only cells that contain
- Now select Errors to access the option to format the cells with error
- Choose your preference and select okay
- Now all the cells highlighted with the selected preference

Change Text to Lower/Upper/Proper Case
We can use three formulas to address this issue. The LOWER() receives one argument, either the text that the user types in or a cell reference. This will convert all the alphabets into lowercase. The formula UPPER() will transform all the alphabets into uppercase. The PROPER() formula is used to change the first letters of the sentence and name to capital and the rest will stay in lowercase.
Spell Check
As Microsoft Excel doesn’t have an automated spell check facility, it may create data errors. To address such errors, select the data set and click press F7. It will run spell check and correct the errors and show suggestions as well.
Delete All Formatting
To clear all the formatting in an excel sheet, do follow these steps.
- Select the entire data
- Go to Home
- Then select Clear and Clear Formats
- Select Clear All to remove everything from the sheet including content
- Select only Clear Content to keep the formatting intact
- There are Clear Comments and Clear Hyperlinks options for user preference also
Challenges and problems in Data Cleansing
Error Correction and Loss of Information
This one is the most challenging problem with data cleansing. The value correction to erase invalid entries and duplication removal is extremely necessary. But, in many cases, the information available for such data anomalies may get limited and inadequate to perform the necessary transformation.
In this case, the deletion of such wrongful entries is the only primary solution, which will ultimately lead to a loss of information.
Maintenance of Cleansed Data
No doubt, data cleansing is a highly time-consuming and expensive process. Having performed data cleansing, businesses have to avoid re-cleansing the data after values in data collection change. So, highly efficient data management and collection techniques may get required to properly maintain the cleansed data.
| Related Article: Python For Data Science |
Data Cleansing in Virtually Integrated Environments
In a few virtually integrated data cleansing processes such as IBM’s DiscoveryLink, every time the data is accessed, a data cleansing gets performed which highly increases the response time and decreases efficiency.
Data-cleansing Framework
Due to the incapability of deriving a complete data-cleansing graph to operate the whole process in advance, data cleansing lists as an iterative process which involves significant interaction and exploration. It will require an appropriate framework consisting of error detection, elimination, addition, and data auditing methods.
The framework can also be integrated with other data processing layers such as integration and maintenance.
Conclusion
Data cleansing is a must required step to maintain the data integrity of any business organization. The ability to detect and rectify problems, filter out unnecessary data and enrich the day to day operations, make this a necessity for any type and size of business. Where large corporations hire data scientists and engineers to monitor their data collections, small and medium businesses can rely on easily online available data cleansing tools to validate their data from time to time.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Data Science Training | Jul 18 to Aug 02 | View Details |
| Data Science Training | Jul 21 to Aug 05 | View Details |
| Data Science Training | Jul 25 to Aug 09 | View Details |
| Data Science Training | Jul 28 to Aug 12 | View Details |

Ravindra Savaram is a Technical Lead at Mindmajix.com. His passion lies in writing articles on the most popular IT platforms including Machine learning, DevOps, Data Science, Artificial Intelligence, RPA, Deep Learning, and so on. You can stay up to date on all these technologies by following him on LinkedIn and Twitter.






