- Home
- Blog
- Machine Learning
- Machine Learning Tutorial

- TensorFlow Interview Questions
- How Oracle Embeds Machine-Learning Capabilities Into Oracle Database
- Machine Learning Applications
- Machine Learning Datasets
- Machine Learning Examples In Real World
- Machine Learning Interview Questions
- Machine Learning Techniques
- Artificial Intelligence Vs Machine Learning
- Machine Learning with Python Tutorial
- Machine Learning with Spark
- Support Vector Machine Algorithm - Machine Learning
- Top 10 Machine Learning Algorithms
- Top 10 Machine Learning Books
- Top 10 Simple Machine Learning Projects For Beginners
- Skills Required for Machine Learning
- Keras Tutorial
- TensorFlow Object Detection
- TensorFlow Tutorial
- Installing TensorFlow
- TensorFlow 2.0 - A comprehensive platform that supports machine learning workflows
- What is Reinforcement Learning?
- Keras vs TensorFlow
- Machine Learning Projects and Use Cases
What is Machine Learning Language?
How does Machine Learning Work?
What is Machine Learning used for?
Difference Between Artificial Intelligence and Machine Learning
Difference Between Deep Learning and Machine Learning
Types of Machine Learning Algorithms
Best Machine Learning Algorithms
Programming Languages for Machine Learning
Open Source Machine Learning Tools
Machine Learning is Utilized Today in Our Daily Life
Today, machine learning is one of the hot buzzwords. It is a field of computer science and is quite different from conventional computational approaches. It can be regarded as a vehicle that is driving AI (Artificial Intelligence) forward with the speed it has at present. Machine learning has a wide range of applications in today’s world. Facebook’s News Feed is one of the most well-known examples.
Machine learning also has a major role to play in self-driving cars, CRM (Customer Relationship Management) systems, Analytics, BI (Business Intelligence), and many other areas. This Machine Learning tutorial will explore all the aspects of machine learning and offers a comprehensive overview of this continuously developing field.
Machine Learning Tutorial For Beginners - Table of Contents
- What is Machine Learning?
- What is Machine Learning Language?
- How does Machine Learning Work?
- What is Machine Learning used for?
- Difference Between Artificial Intelligence and Machine Learning
- Difference Between Deep Learning and Machine Learning
- Types of Machine Learning Algorithms
- Best Machine Learning Algorithms
- Programming Languages for Machine Learning
- Open Source Machine Learning Tools
- Machine Learning Examples
- Machine Learning Applications
- Machine Learning is Utilized Today in Our Daily Life
- What is the Future of Machine Learning?
- How Can I Learn Machine Learning?
What is Machine Learning?
Machine learning is the application of AI that offers computers the capability to learn and act like humans without being explicitly programmed. This process of learning can be improved over time by feeding them with information and data in the form of real-world interactions and observations.
| If you want to enrich your career and become a professional in Machine Learning, then enroll in "Machine Learning Online Training". This course will help you to achieve excellence in this domain. |
What is Machine Learning Language?
Today, machine learning systems are considered powerful tools for solving many complex classification problems. But, as these systems continue to evolve, there will be a huge demand for smarter languages that can process a number of general paradigms and complex issues, a few of which may be quite complicated to process for humans. In simple, a machine-learning language is defined as a language that can process a complex machine learning task.
As the industry’s experience with smart machine learning systems is growing day by day, the entire machine learning field is being staged to shift from solving a simple problem to the creation of complex and powerful algorithms that operate based on an advanced level.
Having said that, a number of machine learning languages that can deal with complex problems (as said earlier in this section) have paved the way for the future of artificial intelligence and integration. Some of the top machine learning languages are MATLAB/Octave, Python, Java/C-family, ELM (Extreme Learning Machines), and R.
How Does Machine Learning Work?
Machine learning system consists of 3 major components. They are the model, parameters, and the learner. A model is a system that makes identifications or predictions. Parameters are the factors or signals that the model uses to form its decisions. A learner is a system that adjusts the model (by adjusting the parameters) by observing the differences in actual outcome versus predictions.
The working of machine learning begins with the model. Initially, you have to give the model ( a prediction) to the system. The model depends on parameters utilized to make its calculations. The machine learning system uses a mathematical equation for expressing the parameters, to efficiently form a trend line of what actually is expected. So, real-life information is entered once the model is set. Most times, the real scores don’t match the model; some may be below or above the predicted line. Now, the learning component of machine learning begins.
The real-life information that is given to the machine learning system is known as the training data or training set as it is utilized by the learner present in the machine learning system for training itself in order to create a better model. The learner observes the scores and determines the difference between them and the model. Then, it uses math for adjusting the initial assumptions. Now, with a new set of scores, the system is run again.
After this, the comparison is done between the revised model by the learner and the real scores. If successful, the scores will be much closer to the prediction than the previous one. However, these won’t e ideal. So, the parameters have to be again adjusted by the learner for reshaping the model. You have to input another test data set and a comparison will happen again. Now, the learner will adjust the model again. This is a cycle that keeps repeating till the model correctly predicts the outcome.
The machine learning system will make adjustments again and again in this manner till it gets things right. This is known as gradient learning or gradient descent. This is how a machine learning system works.
What is Machine Learning Used For?
Machine learning has numerous uses in many sectors. Let’s have a look at them.
- Machine learning has a wide range of applications in healthcare, publishing, retail, and various other industries.
- Facebook and Google are using machine learning for pushing relevant advertisements based on the past search behavior of users.
- Machine learning can handle multi-variety and multi-dimensional data in dynamic environments.
- Machine learning enables efficient utilization and time cycle reduction of resources.
- In data entry, machine learning simplifies time-intensive documentation.
- Machine learning improves the precision of financial models and rules.
- Machine learning eases the detection of spam.
- Machine learning allows for appropriate lifetime value prediction and better customer segmentation.
- Machine learning assists inaccurate forecasts of sales and simplifies product marketing.
Check out Why Machine Learning is one of the latest trending technology in 2024?
Artificial Intelligence Vs Machine Learning
Machine learning and AI are often used interchangeably, mainly in the realm of big data. However, these aren’t the same and it’s important you understand the difference between them. Artificial Intelligence is a branch within the computer science field and can be defined as the ability of a machine or a computer program to learn from experience and perform tasks in the same way as humans. Now, let’s understand the differences between AI and Machine Learning from the below table.
What is the Difference Between Artificial Intelligence and Machine Learning?
| Artificial Intelligence | Machine Learning |
| Artificial Intelligence is a broader concept addressing the use of machines to perform tasks considered as “smart.” | Machine Learning is the application of Artificial Intelligence based on the idea of giving machines access to data and allowing them to learn for themselves. |
| The goal is to enhance the chances of success but not accuracy. | The goal is to enhance accuracy, but it doesn’t care about success. |
| AI is a higher cognitive process. | Machine learning enables the system to learn from data. |
| AI functions like a computer program that performs smart work. | Machine learning is a simple concept in which the machine takes data and learns from it. |
| AI leads to wisdom or intelligence. | Machine learning leads to knowledge. |
| AI involves the creation of a system that mimics human behavior. | Machine learning leads to the creation of self-learning algorithms. |
[ Related Article: Machine Learning Vs Artificial Intelligence ]
Machine Learning vs Deep Learning
Deep learning is an approach to AI and is widely used in the development of self-teaching, autonomous systems. It is used by Google in its image and voice recognition algorithms. You have already learned it all about.
The basic difference between machine learning and deep learning is, in machine learning, you must tell the algorithm how to make an accurate prediction by giving more information to it, while, in deep learning, the algorithm will be able to learn it by processing data on its own. No, let’s understand the differences between machine learning and deep learning.
What is the Difference Between Deep Learning and Machine Learning?
| Machine Learning | Deep Learning |
| Machine Learning is an approach to AI. | Deep learning is a subfield of machine learning and is an approach to AI. It powers the most human-like AI. |
| In machine learning, algorithms are used to parse data and learn from it. Then, informed decisions are taken on what was learned previously. | In deep learning, the algorithms are structured in layers for the creation of an artificial neural network (ANN). The ANN then learns and takes an intelligent decision on its own. |
| The machine learning algorithms are directed by analysts for analyzing different variables in the datasets. | Once implemented, the deep learning algorithms are self-directed for analyzing relevant data. |
| Few thousand data points are utilized for the analysis. | Few million data points are utilized for analysis. |
| Usually, the output is a numerical value, like classification or a score. | Usually, the output can be an element, free text or sound, a score, etc. |
| Machine learning algorithms can work on low-end machines. | Deep learning algorithms depend heavily on high-end machines. |
| Machine learning algorithms take very little time to train when compared with deep learning algorithms. | Deep learning algorithms usually take a very long time to train. |
[ Related Article: Machine Learning vs Deep Learning ]
Types of Machine Learning Algorithms
In order to break down a real problem and to develop a machine learning system to tackle it, you should get to know the types of machine learning algorithms. In this section, we will list out the types of machine learning algorithms and have a good understanding of each one of them.
- Supervised machine learning algorithms.
- Unsupervised machine learning algorithms.
- Semi-supervised machine learning algorithms.
- Reinforcement machine learning algorithms.
[ Note: Labeled data: Labeled data is known as the data that contains a set of training examples, and each example is a pair that consists of the desired output value (also known as labels, supervisory signal, etc.) and an input value.]
1. What is a Supervised Machine Learning Algorithm?
The supervised machine learning algorithm contains an outcome/target variable (or a dependent variable) that has to be predicted from a given independent variable set. A function that maps the inputs to desired outputs can be generated with this set of variables.
2. What is an Unsupervised Machine Learning Algorithm?
We don’t have any outcome or target variable for estimating/predicting, in this algorithm. So, we do not tell the system where to go. Instead, the system has to understand where to go from the data we provide to it. The unsupervised machine learning algorithms utilize techniques on input data to detect patterns, mine for rules, and group and summarize the data points that help in deriving meaningful insights and describe data to the users in a much better way.
Unsupervised algorithms are used mainly in descriptive modeling and pattern detection. These algorithms are mainly used in instances where human experts don’t know what to look for in data. Examples of unsupervised learning include K-means, Apriori algorithm, etc.
3. What is a Semi-supervised Machine Learning Algorithm?
In the previous two machine learning algorithms, either the labels are present for all the observations or there are no variables for all the observations. The semi-supervised machine falls in between unsupervised and supervised machine learning, i.e., it uses both unlabeled and labeled data. Accuracy can be improved significantly with this learning as we can use a small amount of labeled data along with unlabeled data in the train set. The examples include Transductive Support Vector Machine (TSVM), label propagation, etc.

4. What is a Reinforcement Machine Learning Algorithm?
We don’t have any unlabeled or labeled datasets in reinforcement learning, and, so, it’s not like any of the three previous algorithms. It works in a way that the machine is subjected to an environment where it continuously trains itself using trial and error.
The machine is trained to take accurate business decisions by learning from previous experience and capturing the best possible knowledge. Reinforcement learning is a really complex and powerful algorithm to apply for problems. Examples of reinforcement learning include Q-learning, Deep Q Network (DQN), Markov Decision Process, etc.
Supervised algorithms are used for predicting continuous values (classification) and discrete values (regression). Supervised learning is accurate and very fast. Examples of supervised machine learning algorithms include Naive Bayes, Linear Regression, Nearest Neighbor, Neural Networks, Support Vector Machines, etc.
[ Check out What is Reinforcement Learning? ]
The Best Machine Learning Algorithms
It’s a fact that no one machine learning algorithm can solve every problem. For example, you can’t say that decision trees are always better than neural networks and vice-versa. Many factors like the structure and size of your dataset will play a crucial role in determining the most suitable algorithm for a given problem. Having said that, let’s talk about the top machine learning algorithms used by data scientists.
- Naive Bayes Classifier Algorithm
- K Means Clustering Algorithm
- Support Vector Machine (SVM) Algorithm
- Apriori Algorithm
- Linear Regression
- Logistic Regression
- Artificial Neural Networks (ANNs)
- Random Forests
- Decision Trees
- K-Nearest Neighbors (KNN).
[ Related Article: Top Machine Learning Frameworks ]
1. Naive Bayes Classifier Algorithm
A Naive Bayes Classifier can be defined as a probabilistic machine learning model utilized for tasks related to classification. This is a supervised machine learning algorithm and represents a statistical method for classification. This algorithm can solve predictive and diagnostic problems. Naive Bayes Classifier is based on the Bayes theorem. The Bayes Theorem is represented below.
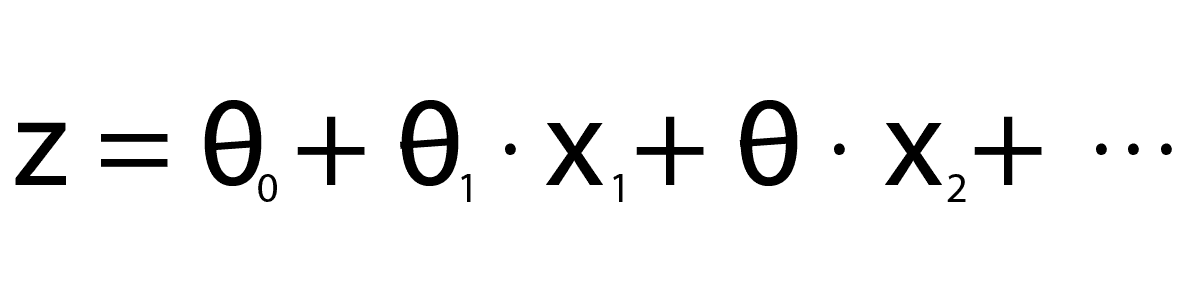
Given that B has occurred, we can find the probability of A using the Bayes Theorem. Here, A is the hypothesis and B is the evidence. The features/predictors are independent is the assumption made here.
2. K Means Clustering Algorithm
K-Means Clustering is an unsupervised machine learning algorithm and is utilized when you have unlabeled data. The algorithm locates the groups in the data while the K variable represents the number of groups. The algorithm works in an iterative manner for assigning each data point to one among the K number of groups depending on the features that are provided. Depending on feature similarity, the data points are clustered. Some examples of use cases are behavioral segmentation, sorting sensor measurements, inventory categorization, etc.
3. Support Vector Machine (SVM) Algorithm
A support vector machine (SVM) is a supervised machine learning algorithm and based on the decision plane concept that defines decision boundaries. A decision plane separates between object sets consisting of different class memberships as shown in the below image. Two classes, Green and Red, are considered here.
The separating line is defined as the boundary and all the objects to its left are Red and the ones to its right are Green. Any new object is classified or labeled as Green when it falls to the right. This one is an example of a linear classifier (a classifier that separates a set of objects into different groups (Red and Green in this case)).
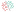
SVM is commonly employed for regression and classification purposes.
4. Apriori Algorithm
The Apriori algorithm operates on database records, especially on records including certain numbers of fields or items, or transactional records. It uses a bottom-up approach for incrementally contrasting complex records and is quite useful in complex AI and machine learning projects. The Apriori algorithm contrasts or scores each component of a larger dataset with other sets in some ordered manner. The resulting scores are utilized for the generation of sets that are classified as frequent appearances in a larger database for the purpose of aggregated data collection. One practical use case of this algorithm is the market basket tool.
5. Linear Regression
A method of modeling a target value depending on independent predictors is known as regression. Linear regression is a method used for the prediction of the dependent variable (Y) based on the independent variables’ values (X). This algorithm is used in instances where we should predict some continuous quantity. The use cases of this algorithm include predicting traffic in a retail store, the number of pages visited on mindmajix.com, etc.
6. Logistic Regression
The logistic regression algorithm is utilized for classification tasks. This algorithm utilizes a linear equation with independent predictors for predicting a value. The value that is predicted can be anywhere between positive infinity and negative infinity. We require the algorithm’s output to be in the form of a class variable (i.e., 1-yes, 0-no). So, we squash the linear equation’s output into the range of [0,1]. We use the sigmoid function for squashing the predicted value between 0 and 1. The below images depict the linear equation (a) and sigmoid function (b).

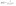
The use cases of this algorithm include classifying whether a tumor is benign or malignant, classifying whether an email is a spam or not, etc.
7. Artificial Neural Networks (ANNs)
It’s a well-known fact that our brains interpret the context of real-world situations in a way that’s not possible for computers. An artificial neural network (ANN) is a simulation of the neural networks that make up a human brain so that the computer can interpret things and make decisions just like humans do. Conventional computers are programmed to behave like interconnected brain cells and, this way, artificial neural networks are created.
ANNs utilize different layers of mathematical processing for making sense of data it is fed. A simple neural network consists of 3 layers and is represented in the below image.
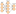
[ Check out: What are Artificial Neural Networks (ANNs)? ]
8. Random Forests
Random Forest is a flexible supervised machine learning algorithm. It is very easy to use and, most of the time, it yields great results, even in the absence of hyper-parameter tuning. It creates a forest and makes it random as you can view from its name. The forest here is a group of decision trees trained with the bagging method most of the time.
The idea behind the bagging method is that a combination of learning models improves the overall result. Thus, a random forest develops multiple decision trees and merges them to acquire a more stable and accurate prediction. Random Forest algorithm can be used for both regression and classification problems. An image that depicts a random forest with two trees is given below.
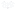
The use cases of this algorithm include the stock market, banking, e-commerce, medicine, etc.
9. Decision Trees
A Decision tree is a supervised machine-learning algorithm and can be used for both classification and regression problems. The goal of the decision tree algorithm is to create a training model which can be used to predict the target variables’ value or class by learning decision rules inferred from training data (prior data).
This algorithm uses a tree representation to solve a given problem. Each leaf of the tree represents a class label, each branch represents a decision, and each internal node represents an attribute. So, a tree is created for the entire data and a single outcome is processed at every leaf. The decision trees are easy to understand and less data cleaning is required. Examples include IBM SPSS Modeler, SAS Enterprise Miner, Salford Systems CART, etc.
10. K-Nearest Neighbors (KNN)
The K-Nearest Neighbors algorithm is a supervised machine learning algorithm and can be used for both regression and classification problems. However, it is most widely used for classification problems. The output of KNN depends on whether it’s used for regression or classification. The output is a class membership in KNN classification and the property value for the object in KNN regression.
Here, k represents a small positive integer and is assigned to the class of a single nearest neighbor. It is a non-parametric algorithm, i.e., it doesn’t make any underlying assumptions about data distribution. We are given some training data here, and it classifies coordinates into various groups identified by an attribute. KNN is a simple algorithm but yields high competitive results. The use cases of this algorithm include pattern recognition, recommender systems, concept search, etc.
Most Used Programming Languages for Machine Learning
The demand for machine learning experts has witnessed rapid growth in recent years. You must gain knowledge of certain programming languages to work in this field. So, before landing a machine learning job, what programming languages should one learn? The answer to this lies in the languages listed below.
- Python
- C/C++
- Java
- R
- Javascript.
1. Python for Machine Learning
Python is the most popular programming language used by machine learning professionals. Syntax of Python is elegant and very simple. So, it can be learned very easily. Hence, many machine learning algorithms can be implemented in it. Python takes very little development time when compared with other programming languages such as Ruby, C++, or Java.
Python supports procedure-oriented, functional, as well as object-oriented styles of programming. Also, Python has many libraries which make machine learning tasks quite easier. Python community has built many modules that help programmers in implementing machine learning.
Visit Here to Learn Machine Learning with Python Training
2. C/C++ for Machine Learning
C/C++ may not be your first choice when you are working on machine learning problems, but, it can be the answer when you cannot afford the overhead of a Python or a Java Virtual Machine interpreter. However, you need to get back to the world of pointers when you need to squeeze every last bit of performance from the system.
Honestly, C/C++ is very pleasant to write. You can either use Caffe or TensorFlow to acquire access to high-level flexible APIs or you can use libraries such as CUDA for writing your own code that runs directly on your GPU. Rust is a great choice for attaining production performance eliminating security headaches when you combine the speed of C/C++ with data safety and type.
3. Java for Machine Learning
Java is also a great choice for the development of machine learning applications. Whether it’s DL4J (full GPU-accelerated deep learning stack), ND4J (tensor operations), or Core NLP (natural language processing), Java libraries are available for all components of the pipeline. Also, you can have access to big data platforms such as Apache Hadoop and Apache Spark.
Writing Java code is not a hateful experience anymore with new language constructs made available in java 8 and Java 9. Writing a machine learning application Java can get the job done and you can utilize all your existing Java infrastructure for monitoring, development, and deployment. You can have a look at the most popular Java ML libraries and tools here.
4. R for Machine Learning
R is one of the highly effective programming languages for machine learning. Using R, you can analyze and manipulate data effectively for statistical purposes. R is a highly specialized and well-suited programming language for data visualization, data analysis, and statistics.
The packages of R such as Class, Gmodels, and RODBC are used in the field of machine learning. You can use R with H2O, Keras, or TensorFlow for experimentation, prototyping, and research. While you can write R code and deploy it on production servers, it’s also easy to recode the R prototype in Python or Java.
Many view R as superior to Python for data visualization and statistics in terms of final aesthetic results, implementation details, and packages for visualizations. R has a very large and significant repository of curated packages known as CRAN. R also enjoys a large community of professionals who are highly specialized in the fields of data visualization, data analysis, and statistics.
5. JavaScript for Machine Learning
TensorFlow.js is a JavaScript library that allows you to train and deploy machine learning models on Node.js and in the browser. You can use intuitive and flexible APIs to train as well as build models from scratch with the help of high-level layers API or the low-level JavaScript linear algebra library.
TensorFlow.js also includes the Keras API and the capability to load and utilize models which are trained in regular TensorFlow. With the help of TensorFlow.js model converters, you can run pre-existing TensorFlow models under Node.js or in the browser. You can also retain pre-existing machine learning models with the help of sensor data connected to other client-side data or the browser. A community mailing list exists for people to receive technical help, ask questions, and let others know what they are doing with TensorFlow.js.
The Best Open Source Machine Learning Tools
The increase in the number of open-source machine-learning tools has made it easier for us to implement machine learning at scale or on a single machine, and in highly popular programming languages. In this section, we will learn about the open-source machine-learning tools that are taking your machine-learning projects to the next level.
- Scikit-learn
- Shogun
- Apache Mahout
- Spark MLlib
- H2O.
1. Scikit-Learn
Scikit-Learn is a very powerful open-source Python library developed for machine learning. This library is widely used in building models and it’s built on foundations of other libraries such as matplotlib, Numpy, and SciPy. It is also one of the highly efficient tools for statistical modeling techniques such as clustering, regression, and classification. This tool is quite efficient for data mining and supports most practical and complex tasks.
2. Shogun
Shogun is a free and open-source toolbox written in C++. However, it can also be used with Matlab, Octave, Lua, R, Ruby, C#, and Python. The latest version of Shogun (6.0.0) adds native support for the Scala language and Microsoft Windows. Shogun is designed for large-scale unified learning for a wide range of feature types and learning settings, such as clustering, regression, classification, etc. The features of Shogun include structured output learning, one-time classification, pre-processing, built-in model selection strategies, etc.
3. Apache Mahout
Apache Mahout is an open-source library of scalable and distributed machine-learning algorithms that are mainly focused on the areas of classification, collaborative filtering, and clustering. Using the MapReduce paradigm, Apache Mahout is implemented on top of Apache Hadoop. However, many algorithms of Apache Mahout run outside of Hadoop as well.
It is aimed at developing intelligent machine learning applications easier and faster. Mahout consists of Java libraries for general math operations and algorithms focused mainly on linear algebra and statistics. There is a diverse, responsive, vibrant, and vast community to facilitate discussions on the Mahout project and its potential uses.
4. Spark MLlib
Spark MLlib is the ML library for Apache Spark and Apache Hadoop. Spark MLlib runs everywhere Spark runs, on Kubernetes, Apache Mesos, Hadoop, in the cloud, or standalone, against diverse data sources. This machine-learning library consists of many useful data types designed to run at scale and high speeds.
Spark MLlib consists of high-quality algorithms that can leverage iteration and produce better results than MapReduce. Though Java is the primary programming language for working in Spark MLlib, R users can plug into Spark (as of version 1.5), users of Scala can write code against Spark MLlib, and Python users can connect Spark MLlib with the NumPy library.
5. H2O
H2O is an open-source machine-learning platform aimed at making machine learning easier for all. It is a distributed in-memory platform with linear scalability. It supports widely used ML and statistical algorithms including deep learning, generalized linear models, gradient-boosted machines, and more.
This platform has an AutoML functionality that runs through all the algorithms (and their hyperparameters) for yielding a leaderboard of the best models. H2O.ai is a company that has manufactured the H2O tool, and it consists of a community that includes 14,000 organizations. Also, it is highly popular in both Python and R communities
Machine Learning Examples
There are many ways in which machine learning impacts our daily lives, optimizes operations, and informs business decisions for some of the world’s leading organizations. There is a possibility that you are using it in one way or the other and you are absolutely unaware of it. In this section, we will focus on a few amazing practical examples of machine learning.
- Voice & Image Recognition Systems
- Smart Email Categorization
- Search Recommendations & Suggestions
- Traffic Analysis & Predictions in Maps
- Determining Arrival Times & Pricing.
1. Voice & Image Recognition Systems
It is quite difficult for computers to identify the difference between two distinct images (a tiger and a cat, for example), read a sign, or recognize a human’s face. With the help of deep convolutional neural networks, machine learning has made tremendous progress in addressing the problems related to image recognition.
The machine learning models are at the center stage of speech recognition methodology. Speech recognition has been evolved in recent years due to advancements in deep learning. The two important machine learning models that are used in automatic speech recognition systems are SVM and ANN.
2. Smart Email Categorization
A classifier based on machine learning could help a person or an organization reduce work hours spent on email support. This machine learning-based classifier is trained to forward the emails to personnel or groups that manage different type of errands. These machine learning models are less prone to error and are more consistent.
3. Search Recommendations & Suggestions
Recommendation systems are one of the widespread and most successful applications of machine learning. The recommender systems make use of machine learning algorithms and provide customers with tailored suggestions based on their attributes or recommend items similar to those liked by them in the past. This is known as content-based filtering. Today’s modern recommender systems contain collaborative filtering along with content-based filtering.
Machine learning is used in almost all the components of a search engine. Examples of search engines using machine learning are Google and Bing. Machine learning is used in places such as search ranking, query understanding (detecting navigational vs transactional queries), document/URL understanding, recommending search queries based on users’ previous searches, etc.
4. Traffic Analysis & Predictions in Maps
Traffic is rapidly growing day by day in major cities all over the world, given the slow development of road infrastructure and an increase in the densities of cars on roads. To tackle this problem, several organizations are using machine learning methods to develop predictive models for traffic.
These models infer and estimate the traffic flow at different times into the future by analyzing large amounts of data on traffic over several months and years. This work is leveraged in traffic maps that provide information to users on how traffic is increasing over time, and in services that offer traffic-sensitive directions by contemplating the inferred speeds on roads that aren’t sensed directly.
5. Determining Arrival Times & Pricing
Here, we will deal with an example of determining flight arrival times and pricing for flight tickets. The machine learning models are used to predict the prices of flights with a high amount of accuracy depending on historical fare data. The machine learning models that can be used here are linear SVM, logistic regression, Partial Least Squares Regression, etc. Based on data related to historical flight departures and arrivals, and weather observations, the Deep Neural Networks accurately determine the arrival times of flights.
How is Machine Learning is Utilized Today in Our Daily Life?
The use of machine learning is implemented across the world and it is not limited to the following:
1. Fraud Detection
Based on your buying pattern if the system observes any uncertainty it quickly alerts the authorities and at the same time intimates the user.
The best example is your Gmail account login. If you have logged into your Gmail account from a different city or country or logged into your Gmail account from a new device, immediately you will get an email to your account. This means your regular device and the internet connection is been logged somewhere and a system is monitoring for uncertainties.
2. Web Search Results
All your search results are tracked and based on your search history pattern, real-time ads are displayed on the web browsers.
For example: If you have searched for any Televisions on Amazon and closed your browser and then started browsing or reading something over the internet, TV-related ads will be shown in the browser prompting the user to buy.
3. Text-Based Sentiment Analysis
The best example of this is your Gmail app on your iPhone or your Android phone. If you have the latest app updated on your phone, whenever a user reads the email, predefined options are displayed for the user to reply back. This way the user doesn’t have to manually type. This is one such example where the email is read by the system already and it has come to certain conclusions and the keywords are displayed for the user.
A lot of software companies have built a product using text-based sentiment analysis concepts and minting money on these products. Once the product is utilized by companies they can understand their customer’s reviews and comments. All the comments and reviews put forward by their customers are read and analyzed and categorized into meaningful data for the business. With this, they can classify if their customers are satisfied or if they have a problem the business would understand how many individuals have faced this particular problem.
Thus helping the business in every aspect and helping them to correct themselves and maintain a profitable business for themselves.
4. Prediction of Equipment Failures
This is more widely utilized in developed countries. For example, we have transformers that are prone to wear and tear because it is directly exposed to sunlight. So understanding their lifespan and their maintenance activities, the machine learning systems are capable enough to predict what it is the life expectancy of this equipment. This should be more widely used in all the sectors so that it will be helpful for the businesses.
5. Pattern and Image Recognition
Artificial Intelligence has played a vital role in terms of facial recognition. Using the capability a lot of security systems have been built and border crossing has been more clear and monitored.
Machine Learning Applications
Many industries that deal with huge amounts of data have realized the value of machine learning and are coming up with various innovations developed using machine learning algorithms. We see every day that a new service or product, or a new application is making use of machine learning to get smarter and better. In this section, I am going to share a few major machine-learning applications that we are using in our daily lives.
- Siri, Cortana, Alexa, and Google Now - Virtual Personal Assistants
- Amazon Echo and Google Home - Smart Speakers
- Samsung Bixby on Samsung S8 - Smartphones
- Google Allo - Mobile Apps
- Gmail Smart Email Categorization - Gmail categorizes emails into primary, social, and promotion inboxes
- Google Search, Google Maps - Search suggestions and traffic analysis
- Uber, Lift, and Ola Cabs - Estimates the arrival times & price of the ride.
- Yelp Image Curation
- Facebook Chatbot
- Amazon Product Recommendations.
Siri, Cortana, Alexa, and Google Now - Virtual Personal Assistants - A virtual personal assistant is an application program that understands the voice commands of humans and accomplishes tasks for them.
The technologies behind these virtual assistants require huge amounts of data that feeds AI platforms such as machine learning, speech recognition platforms, and natural language processing. The machine learning algorithms learn from the data they receive and become better at predicting the needs of end-users.
1. Amazon Echo and Google Home - Smart Speakers - Amazon Echo and Google Home are the devices you can talk to for getting your stuff done. Machine learning and data are the foundation of the power of these devices. These devices get stronger based on the amount of data every day. Every time they make a mistake, they use that data to make them smarter the next time around. Machine learning is the main reason for the improvement in the abilities of the voice-activated user interface.
2. Samsung Bixby on Samsung S8 - Smartphones - Bixby is Samsung’s own voice assistant. It is an AI system designed to make device interaction much easier and was first introduced on the Samsung Galaxy Note 8 and S8 devices. Bixby uses machine learning models, and it gets better with usage as it becomes smarter with the amount of data it receives.
3. Google Allo - Mobile Apps - Google Allo is a machine learning messaging app. This app uses the machine learning software of Google and automatically generates appropriate responses unlike iMessage, Messenger, and WhatsApp. The responses get better with the number of messages sent by the user. This is because the app will learn the ways a user usually prefers to reply.
4. Gmail Smart Email Categorization - Gmail categorizes emails into primary, social, and promotion inboxes - Google uses machine learning for smart email categorization. Google’s machine learning software considers many factors such as sender IP address, HTML code, email content, etc., and classifies the message as either promotional, social, or primary.
5. Google Search, Google Maps - Search suggestions and traffic analysis - Google Maps uses a lot of machine learning capabilities like prediction, recommendations, image analysis, etc. It uses some of the variations of Temporal difference algorithms for updating you with a better route and neural networks for blurring sensitive information.
Google search is using machine learning in various ways. The major ones are pattern detection (for identifying duplicate or spam content), identifying new signals (for improving the quality of search query results), an image search for understanding photos, identification of similarities between words in search queries, etc. RankBrain is Google’s machine learning algorithm and it analyzes and processes search results and ranks them accordingly.
6. Uber, Lift, and Ola Cabs - Estimates the arrival times & price of the ride - Uber, Lift, and Ola cab companies are using machine learning models which leverage data related to distance of the vehicle from location, average traffic of the area, etc for estimating arrival times. They are estimating the price of the ride with the help of machine learning models that use data related to many factors such as past fare data, the situation in the city, festival days, etc.
7. Yelp Image Curation - Yelp collections is using a combination of manual curation, algorithmic sorting, and machine learning. Yelp hosts millions of photos that Yelpers upload from all over the world. Yelp uses deep convolutional neural networks to build photo classifiers (sorting photos into several predefined classes). It has introduced a custom ads platform powered by machine learning. The custom ads platform enables businesses to select which photos and reviews to be highlighted in their ads.
8. Facebook Chatbot - Facebook chatbots work with natural language processing systems and engage with the visitors of Facebook to provide information, answer questions, recommend products, etc. The Facebook chatbots powered by machine learning are termed smarter and answer more ambiguous questions and will be able to learn as they go. This makes for an efficient, personal, and proactive customer experience. The famous Facebook messenger chatbot technologies are Niki.ai, HealthTap, Poncho, CNN, etc.
9. Amazon Product Recommendations - Amazon product recommendations provide customers with a shopping experience in which the most relevant products are shown in real-time. Amazon uses recommendations software that is powered by machine learning. This software uses machine learning algorithms for tasks such as categorization, clustering, content-based filtering, and collaborative filtering. Thus, with the help of machine learning, Amazon integrates recommendations in almost all parts of the purchasing process.
What is the Future of Machine Learning?
Machine learning has evolved as a critical aspect of today’s numerous established and burgeoning industries. This technology is enabling computers to predict outcomes by accessing hidden insights, thus leading to remarkable business transformations. We are yet to witness its full potential beyond image and voice recognition, fraud detection devices, self-driving cars, etc.
The major forecasts about machine learning’s future are improved unsupervised algorithms, enhanced personalization, increased adoption of quantum computing, improved cognitive services, and the rise of robots.
[Related Article: Deloitte Interview Questions]
How Can I Learn Machine Learning?
With the amount of data in the world getting increased day-by-day, there is a growing demand for scientists and engineers with knowledge in machine learning. So, in order to gain extensive knowledge and become an expert in this field, you can opt for MindMajix's Machine Learning Training.
In this course, you will learn the most efficient machine learning techniques, and implement them in real-time, and getting them to work for yourself. This course will also introduce you to numerous applications and case studies so that you will learn how to apply machine learning models to build smart robots, text understanding, medical informatics, text understanding, and other areas.
Conclusion
Industries working with large varieties and amounts of data that have incorporated machine learning into their business processes are able to benefit from intelligent, real-time data analysis. Unlike traditional analytics, machine learning is scalable, continuously learning, and automated.
To adopt and integrate machine learning into your business processes, data availability and data governance issues need to be addressed. In order for machine learning algorithms to truly benefit your business, you should refine them continuously based on data and adjust them according to your business objectives. So, it is in the best interest of the organization to provide as much data as possible to machine learning algorithms as their decision-making capability depends on the amount of data you provide to them.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Machine Learning Training | Aug 04 to Aug 19 | View Details |
| Machine Learning Training | Aug 08 to Aug 23 | View Details |
| Machine Learning Training | Aug 11 to Aug 26 | View Details |
| Machine Learning Training | Aug 15 to Aug 30 | View Details |

Ravindra Savaram is a Technical Lead at Mindmajix.com. His passion lies in writing articles on the most popular IT platforms including Machine learning, DevOps, Data Science, Artificial Intelligence, RPA, Deep Learning, and so on. You can stay up to date on all these technologies by following him on LinkedIn and Twitter.






