
- Django Interview Questions
- Python Array Examples
- Python enum
- Python Enumerate with Example
- Python Flask Tutorial For Beginners
- Python For Beginners - Way To Success
- Python For Data Science Tutorial For Beginners
- Python for loop
- Python GET and POST Requests
- Python IDEs for Python Programmers
- Python Interview Questions
- Python Lists with Examples
- Python Partial Function Using Functools
- Python Print
- How to generate random numbers in python
- Python Regular Expression (RegEx) Cheatsheet
- Python Sleep Method
- Python List Methods
- Python Split Method with Example
- Python String Functions
- Python Variable Types
- Python vs Java
- Python vs SAS vs R
- Python Operators
- Code Introspection in Python
- Comprehensions in Python
- Python Exception Handling
- Defining Functions - Python
- Generators & Iterators in python
- Install Python on Windows and Linux
- Introduction to Python Programming
- Lists concepts in Python
- Loops in Python
- Regular Expression Operations in Python
- Python Serialization
- String Formatting - Python
- R vs Python: Which is better R or Python?
- Six Digit Salary With Python
- Top 20 Python Frameworks List
- Why Learn Python
- Python Substring
- OOPs Interview Questions
- Career Shift To Python : Success Guaranteed
- Face Recognition with Python
- Go vs Python
- Pyspark Interview Questions
- Python Pandas Interview Questions
- OpenCV Interview Questions
- Python Project Ideas
- Flask Interview Questions and Answers
- Array Interview Questions
- What is PyCharm?
- What is Seaborn in Python?
- What is Anaconda Navigator
- Numpy Broadcasting - Detailed Explanation
- Python Data Science Interview Questions
- Genpact Interview Questions
- Python Developer Job Description
- Pandas Projects and Use Cases
- DataFrame Tutorial
- How to install Python on Windows
- Pyspark DataFrame
Introduction to Python
Python Created in 1989 by Guido Rossum, Python is an object-oriented programming language. Python had been designed to offer rapid prototyping for complex applications. This language has interfaces to a lot of system calls of the operating system. Not only that, but it is also extensible to C and C++. Lots of large multinational corporations like Google, NASA, BitTorrent, and others use Python for development.
Python is also gaining huge popularity in fields like Artificial Intelligence, Neural Networks, Machine Learning, Natural Language Processing, Cloud Computing, and other advanced fields of Computer Science. One of the main focuses of the language had been on the reliability of code.
Python Tutorial - Table of Contents
- History of Python
- How to Install Python?
- Python Main Function
- Variables in Python
- Learning Python Strings
- Python Tuple
- Python Dictionary
- List of Python Operators
- Functions in Python
- If Statement
- Python Loops
- Python Class & Objects
- Python Regular Expressions
- Ways in Python to find out if a file or a directory exists
- Python COPY File
- Python Rename File
- Python ZIP file with Example
- Manipulating XML with Python
- Advantages of Python
- Characteristics of Python / Python Features
- Differences between Python, Ruby, PHP, TCL, PERL, and Java
- Python DateTime
- Python Range Function
- Python Database
| If you would like to become a Python-certified professional, then visit Mindmajix - A Global online training platform for “Python Training” Course. This course will help you to achieve excellence in this domain. |
Python Tutorial for Beginners
Python has always been easy to learn and offers a powerful programming language in the hands of programmers. This language offers high-level data structures and constructs and is yet a very simple and effective approach to object-oriented programming. The syntax is elegant and coupled with dynamic typing and the interpreted nature. So, the language is ideal for rapid application development and scripting. Not only that, Python can be used on most platforms.
The interpreter along with the extensive standard library for Python is freely available in source code or binary form for all the major platforms. It can be availed from the online website and can be distributed freely. Extending the Python interpreter is easy with the new functions and the data types that are implemented in C or C++. Python is also suitable as an extension language. It can be customized for specialized applications.
The language is dynamic and interpreted and there are no type declarations for the functions, parameters, variables or methods in the source code. Thus the code is quite short as well as flexible. There would be no compile-time checking of the source code. Python would be tracking the types of all the values at runtime and would flag a piece of code that does not carry sense. Using an interpreter for the language is one of the best ways to work with it. The beginners would have lots of questions about the basic concepts and would need to figure things out by themselves. Whenever there is a doubt that the programmer wants to clear, the interpreter would do the job best.
Experimenting with the operators and variables is quite easy. If there is a runtime error, the interpreter would raise appropriate flags to let the programmer know about the bug. Python is a case-sensitive language. The statements would also not require a semicolon to end. It is easy to use comments in the language as well.
The source files would have a '.py' extension and they are known as modules. The easiest way to run the Python module is the shell command 'python' followed by the module name would call the Python interpreter to execute the code.
Thus, Python is a very versatile language and it can be used for a wide range of applications. The language can help you to develop a lot of different applications in diverse fields.
History of Python

Though the implementation of the language began in December 1989, The conception of the Python programming language had already begun in the late 1980s. Guido van Rossum started the implementation AT CWI. The Python was designed to be capable of exception handling and forming an interface with the Amoeba operating system. The principal author of the language is Guido van Rossum. He is still one of the central characters in deciding how the language would proceed in the future. The language had received its name from Monty Python's Flying Circus.
How to install Python?
You need to have access to the Python interpreter to start working with the language. There are a few ways for this to be done. It can just be availed at the website python.org from the Python Software Foundation. It would involve downloading the proper installer for the operating system and running it on the computer. Package managers can be run in some operating systems to install the language. In Android systems, a mobile app that provides the Python programming environment can be used.
Installation of Python on Windows
To create Python programs on Windows systems, you would need to have the Python interpreter.
- This can be done by downloading the Python installer from the website.
- You would need to navigate to the Download page for Windows at python.org.
- Under the column Python Releases for Windows, you should click on the Latest Python 3 Release. You should be scrolling to the bottom. The Windows x86-64 executable installer is for the 64-bit systems and the Windows x86 executable installer is designed for the 32-bit systems.
- After that, you would need to run the installer by double clicks on the downloaded file.
- The 'Install Now' button needs to be clicked on the dialogue box. Once the installation finishes in a few minutes, you would be having a Python 3 installation on the system.
Installation of Python on Windows Subsystems for Linux
If you already have the Windows 10 Anniversary or Creators Update, you would be able to install Python in another way. There is a feature called Windows Subsystem for Linux which would allow running a Linux environment on the Windows platform. No virtual machines would be required for this.
Installation of Python on Linux
With Linux, there are high chances that the Python would already be installed. But, you might have problems with the fact that you would not have the latest version. You can, however, find out the version. You might want to have the latest installation of the interpreter.
Installation of Python on Ubuntu
The installation instructions could vary depending on the Ubuntu distribution.
- Ubuntu 18.04 or above, Ubuntu 17.10 - Python 3.6 would come as default and can be invoked with the python3 instructions.
- Ubuntu 16.10, Ubuntu 17.04 - Python 3.6 is not by default and can be found in the Universe repository. The following commands need to be entered into the terminal:
sudo apt-get update
sudo apt-get install python3.6Ubuntu 14.04, Ubuntu 16.04 - Python 3.6 would not be available in the Universe repository. You need to get it from the Personal Package Archive (or PPA). The following commands must be put in the terminal:
sudo add-apt-repository ppa:deadsnakes/ppa
sudo apt-get update
sudo apt-get install python3.6[ For More Info Check: Install Python on Windows and Linux ]
Installation of Python on Debian
The Ubuntu 16.10 method would work for Debian as well. But no path can be found to make it work on Debian 9. An issue with Debian is that it would not install the sudo command by default. The following commands would do the job:
su
apt-get install sudo
vi /etc/sudoersThe following line should be added to the end of the /etc/sudoers file. You would need to replace with the one you are using:
your_username ALL=(ALL) ALL
Installation of Python on CentOS
Newer versions of software for 'Enterprise Linux' is offered by the IUS Community. With their help, you can install Python 3. You just need to run the following commands:
sudo yum update
sudo yum install yum-utils
sudo yum install https://centos7.iuscommunity.org/ius-release.rpm
sudo yum install python36u
sudo yum install python36u-pipThese are some of the ways you can install Python on your system.
Related Article: MongoDB Projects
Python Main Function
The Python main function needs to be executable if the file is a Python program. These files can also be imported as modules. So, the main method can be executable depending on how the main method is to be used.
The main() function
The main() function would act as the entry point of a program. However, the interpreter would be executing the source file code sequentially. A function would not be called if it is not part of the code. However, if it is a part of the direct code, then it would be executed if the file is imported as a module. There is a special technique to let it get executed if the program is run directly and not as part of a module. The following definition would hold:
print("Hello")
print("__name__ value:", __name__)
def main():
print("python main function")
if __name__ = '__main__':
main()The python interpreter would start executing the code inside when this program is run. A few implicit variables are set as well, one being __name__ with the value as __main__. A function needs to be defined for the Python main function. The if statement can be used to execute the main function. The python interpreter would set the value of __name__ as the name of the module if the python file is imported as a module. The condition would be false and the main method would not be executed. A Python programmer is offered the flexibility to keep any name for the main method. However, keeping the name as main() is in best practice.
Why is the main function needed?
Breaking a piece of code into logical parts is important as it would help to modularize the code. Each part of the program would be responsible for a particular task. The first part of the program consists of import statements. However, there are few statements that would be performing the basic main functions that the program is required to perform. In many languages, the lines of code cannot exist separately and need to be a part of a special function called the 'main' function.
Python does not require a separate function
Although it is true that you do not need to create the main function in the Python programming language, it is considered to be good practice. It is a good idea to incorporate the statements into the logical structure of the program using the main() function. Since the functions help to break the program into a few logical parts, naming this function as main() is quite understandable.
A few special variables are created by the Python interpreter during the execution. __name__ is one of the variables and the value "__main__" is automatically set to it. This happens when the program is executing itself.
If the program is being imported by another program, then the __name__ variable would have the name of the module. This variable helps to know if the program is being run by itself or by some other program.Thus, even though the main() function is not mandated in the language, it can be quite helpful.

Variables in Python
In order to perform calculations, there needs to be a location where the operands can be kept. Without these places or memory locations, even the most basic functions cannot be performed. All types of calculations would need some memory location or a reference to it. This is where variables come in.
Variables are temporary memory locations that are used to store values on which operations can be performed. Variables can be of different types, depending on the requirement of the user.
What are the variables in Python?
A Python variable is basically a reserved memory location where you would be able to store values. The variables offer data to the computer for processing. Actually, every value in Python would have a data type. The different data types are Numbers, Strings, Tuple, List, Dictionary and others. The variables can be defined by any name.
How should a variable be declared in Python?
To declare a variable y and then print it, the following code will be used:
y = 12345
print yCan a variable be re-declared?
A variable can be re-declared even after it has been declared once. For instance, a variable x is being assigned 0 as the initial value. Then, we are re-assigning "abc" to it.
Variable re-declaration example:
x = 0
print (x)
x = 'abc'
print (x)Concatenation of Variables
Now, it is time to try and concatenate the values of variables. It would be a good idea to try and start with different data types and concatenate them together, like a string and a number. Python would require you to declare the number as a string before you can concatenate them. This is unlike Java, where no such declarations need to be made. For instance,
print("abc"+55) would generate an error
A similar case would occur with
x = "cat"
y = 73
print x+y
However, the problems can be resolved by writing them as follows:
"abc" + str(55)
x = "cat"
y = 73
print(x+str(y))Local and Global Variables
If you would like to use the same variable for the rest of the module or the program, you should be declaring a global variable. However, if you would like to use the variable in one particular function or method, you need to use a local variable.
We would be using the concept of global and local variables in the following program.
A variable x, which has a global scope, is given the value of 69 and printed on the output. However, x is again declared in function and a local scope is assumed. It is given a value "abc" and printed on the output. This variable is different. After the function call, the local variable would be destroyed.
x = 69
print(x)
def check():
x = 'abc'
print(x)
check()
print(f)Output:
69
abc
69How should a variable be deleted?
There is a “del” command that can be used to delete a variable. The following example shows how a variable can be deleted and then we give a try to print it.
a = 48
print(a)
del a
print(a)After printing 48, there would be an error message showing that the variable name is not defined.
[ Check out: Python Variable Types ]
Learning Python Strings
Strings are basically text. When strings are to be defined, they are put inside quotes as stated below:
x = "Hello world!"
print(x)
len() function
The above example shows something very simple. This shows how a string can be simply stored in a variable and then displayed. But, printing them is not the only thing that can be done with them. Lots of other things can be done too. Both double and single quotes can be used to assign a string. There might be problems if the value that is to be assigned itself has the same type of quotes. To overcome this, we do the following:
print("This is how we use 'single quotes'")
Now, there are some other functions as well. The output would be 3 in the following case:
x = "abc"
print(len(x))
index() functionWe can also print the index of a character in a string. However, we would only be able to print the first occurrence of the character. The output would be 1 in the following case:
x = "abcbe"
print(x.index("b"))
count() functionMost programming languages start counting from 0 instead of 1. We can even find out the number of times a particular character occurs in a string. For instance, if there be a string "aabbbcccc", the count of "b" would be 3.
x = "aabbbcccc"
print(x.count("b"))Slicing
A slice of string can also be shown on the output. But, it needs to be kept in mind that Python would start counting from 0 and not 1. Let us take a string "aabbbcccc" and print a slice of it.
x = "aabbbcccc"
print(x[2:5])bbb would be displayed on the output. This needs to be understood that the slicing would begin from the first index and continue to the index before the second. If there is just one character, a single character at that very index would be displayed. However, the following would be displayed if try and play around a little.
x = "aabbbcccc"
print(x[2:])This would display everything to the end starting from index 2, i.e. bbbcccc. If the starting index is left out and there is a second index value, everything from the beginning to the one before the second index would be displayed. If both the indices are left blank, the entire string would be displayed. Negative indices would be displayed as well. When a negative index is given, the counting starts from the right. Thus, -6 would simply mean the 6th character from the end of the string.
There is another modification of the slice syntax, where three parameters can be entered. The third parameter is used to mean how many characters are to be skipped while displaying the slice. It is like a step parameter. The following snippet would display "bbcc"
x = "aabbbcccc"
print(x[2:8:2])There is also a way to reverse a string using slice. You need to write the code just like the following:
x = "aabbbcccc"
print(x[::-1])These are some of the most basic ways to work with string in Python. There are a lot of other functions as well.
[ Learn Python String Functions ]
Python Tuple
More often than not, there is a necessity to work with some sequences of strings that would not be changed. The Python tuples offer just that. They are sequences, just like the Python lists. The primary point of difference between the two is that while lists can be changed, tuples cannot. While parentheses are used in tuples, there would be square brackets around the lists.
Creating a tuple is quite simple. You would only need to put some comma-separated values next to each other within parentheses or without them. For instance, they can be declared as follows:
tuple_1 = ('akash', 'vaibhav', 94, 97);
tuple_2 = (0, 1, 2, 3, 4);
tuple_3 = "x", "y", "z";An empty tuple can be created as well. If you would want to do this, you would just need to write nothing within the parentheses. For instance,
tuple_4 = ();
There is another important thing to be noted. If you would want to create a tuple but there is a single value, you would need to leave a comma after the value. This would be like the following:
tuple_5 = ("God",);
The tuple indices and not just the string indices begin with 0. The same operations like slicing and concatenation can be performed on them as well.
How to access the values in the tuples?
The square brackets are used for accessing the values in tuples. The indices are to be provided as well. You can even slice them on will. For instance,
tuple_1 = ('akash', 'vaibhav', 94, 97)
tuple_2 = (0, 1, 2, 3, 4);
print(tuple_1[2])
print(tuple_2[1:3])The output would be as follows:
94
[1, 2]
How to update tuples?
Since tuples are immutable, their values cannot be changed or updated. However, you can take some parts of the existing tuples and create new ones with their help. For instance, you can use concatenation and do the following.
tuple_x = (56, 9)
tuple_y = ('a', 'b')
tuple_0 = tuple_x + tuple_y
print(tuple_0)The result would be as follows:
(56, 9, 'a', 'b')How to delete tuple elements?
Deletion can be said to be a form of updating and since the tuples are immutable, this is not possible as well. However, a new tuple can be created without the unwanted elements of the old tuple. If you would like to remove the entire tuple, this can be performed with the help of the del statement.
What are the basic operations on tuples?
The + and * operations can be used on tuples as well much like strings. That would mean you can have repetition and concatenation in tuples as well. The only difference is that the result obtained would be a new tuple and not a string.
Not only that, all the different operations that can be applied to sequences in Python can also be applied to the tuples. There are a few built-in functions like cmp(tuple_1, tuple_2), len(tuple), max(tuple), min(tuple) and tup(sequence). The last function is used to convert a list into a tuple. The rest can be understood by their respective names.
Python Dictionary

Among the different important data collections in Python, one of the most important ones is a dictionary. More often than not, there would be a necessity to work with them. Hence, it becomes essential to know how to create and access them and even add or remove elements if need be. There are lots of built-in methods as well if needed.
What is a Python Dictionary?
According to the Python language, an unordered collection of items would be a dictionary. There are other compound data types as well which has only one value, the dictionary is unique due to the fact that it would have a key: value pair. This data type is optimized in those cases to retrieve values when the key is known. It can be said that it is quite analogous to vectors and maps.
How should a dictionary be created?
The creation of a dictionary is quite simple. You would just need to put the items within {} and separate them by commas. The items should have a key and a corresponding value, thus forming a pair. The values can be anything but the keys must be some immutable data type, like a number, string or tuple. They should also be unique. Creation of an empty dictionary is also possible.
Code snippets:
dic = {}
dic = {1: 'cat', 2: 'mat'}
dic = {1: [1, 2, 3], 'name': 'Adam'}
dic = dict({1: 'cat', 2: 'ball'})
dic = dict([(1, 'cat'), (2, 'ball')])These are some of the ways a dictionary can be created. There is a built-in function as well dict() that can be used to create dictionaries.
How can elements be accessed from a dictionary?
It is already known that other container types use keys, but dictionaries use keys to access the values. The keys can be used square brackets or with the get() method. The only difference would be that get() would be returning None and not KeyError if the key cannot be found.
dic = {'name': 'Adam,' 'age': 5}
print(dic['name'])
print(dic.get('age'))The output would be:
Adam
5How can the elements be added or changed in a dictionary?
Dictionary is a mutable container type. New elements can be added or the existing elements can be changed. If the key is already present, the value would get updated. Otherwise, a new key: value pair would be added to the dictionary.
dic = {'name': 'Adam', 'age' = 5}
dic['age'] = 6
print(dic)
dic['marks'] = 98
print(dic)The output would be displayed as follows:
{'name' = 'Adam', 'age' = 5}
{'name' = 'Adam', 'age' = 6, marks = 98}How can elements be removed from the dictionary or be deleted entirely?
A particular item can be removed from the dictionary using the pop() method. The method would return the value with the given key and it would be removed from the dictionary. The method popitem() can also be used to remove and return an arbitrary item from the dictionary.
squares = {1:1, 2:4, 3:9, 4:16, 5:25}
# remove a particular item
print(squares.pop(4))
# remove an arbitrary item
print(squares.popitem())You can even clear all the items in the dictionary using the clear() method. Even the del statement can be used. Individual items or the entire dictionary can be removed.
squares.clear()
List of Python Operators
The basic function of a computer is to perform calculations. No matter what is being done digitally, it involves some type of calculations and processing of binary digits. Be it an image file or simulating the launch of a rocket, each and everything would involve some kind of operations with numbers or variables. Thus, operators are a must in any language.
Operations are those constructs which can be used to manipulate the value of operands. The following different operators are supported by Python.
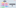
- Arithmetic Operators
- Assignment Operators
- Logical Operators
- Relational Operators
- Bitwise Operators
- Identity Operators
- Membership Operators.
1. Arithmetic Operators
The arithmetic operators are the first that come to mind when we talk about operators. Python offers more operators than you generally have with other languages. In addition to the ones for addition, subtraction, multiplication, division and modulus, you also get the exponent (**) and floor division operators (//).
- The +, -, * and / are quite common and are used to perform arithmetic operations.
- The modulus operation (%) can be used to find out the remainder when the second operator divides the first.
- The exponent operator would be used to perform exponential power.
- The importance of the floor division operator emerges if one of the operands is negative.
- The arithmetic operators are used very commonly and it needs to be understood that they follow the same precedence rules as in normal arithmetic.
2. Relational Operators
Commonly known as the comparison operators, the operators compare the values on the two sides of the operators and decide what relation is held among them. There are 7 such operators. These include
- equal to (==)
- greater than (>)
- less than (<)
- not equal to (!=) or (<>)
- greater than or equal to (>=)
- less than or equal to (<=)
These operators would generally return a true or false value depending upon the result of the operation.
3. Assignment Operators
In addition to the classical assignment operator =, there are also some other assignment operators. These include
- add and assign (+=)
- subtract and assign (-=)
- multiply and assign (*=)
- divide and assign (/=)
- modulo and assign (%=)
- exponent and assign (**=)
- floor divide and assign (//=)
Though the compound assignment operators can be broken down into two steps, they look more elegant.
4. Bitwise Operators
The bitwise operators are used to perform binary operations on the operands.
- The & would perform a Binary AND
- The | performs a Binary OR
- The ^ is the Binary XOR operator
- The ~ is used as the Binary complement operator
- There are shift operators as well
- The << is the Binary Left Shift operator where the bit pattern is shifted to the left.
- The >> is the BInary Right Shift operator where the bit pattern would be shifted to the right.
5. Logical Operators
The three logical operators are
- logical AND
- logical OR and
- logical NOT
These operators can be used to combine two relational operations.
6. Membership Operators
There are two membership operators which are used in sequences to check the presence of elements. They are the 'in' and 'not in' operators. The 'in' is used to check if there is an element present in the sequence. The 'not in' is just the complement of that.
7. Identity Operators
These operators are used to check if they refer to the same memory and hence identical. The operators are 'is' and 'is not'
[Check out: What is Site Reliability Engineering]
Operator Precedence
Operator precedence determines which operates would be given importance over others. The operator precedence is as follows:
1. **
2. ~ +(Unary) -(Unary)
3. * / % //
4. + -
5. >> <<
6. &
7. ^ |
8. <= < > >=
9. <> == !=
10. = -= += //= %= /= *= **=
11. is is not
12. in in not
13. not or and
This is all there is to know about the Python operators.
[ Related Article: Python Operators with Examples ]
Functions in Python
More often than not, there would be a job that might need to be repeated several times in a program. Now, if the same thing needs to be done multiple times at random instances, it would be meaningless to write the same code over and over again. Also, you might want to group together pieces of code and keep them separate. There might be some jobs that need to be done for the overall program but does not have much in common with the code. All of these can be done with the help of a function.
A function is a block of reusable and organized code that can be used to perform a related and single action. The functions allow proper modularity for the application and would also allow reusability of code. Python offers many built-in functions like print(). However, you can even create functions on your own. They are known as user-defined functions.
How should a function be defined in Python?
A few simple rules should be followed while defining a function in Python. The function would start with the def keyword followed by the function name and parentheses. The arguments and the input parameters need to be placed within the parentheses. The code block within the functions would start with a colon. The return statement would exit a function. It can even be used to pass an expression to the caller. The definition should be something like the following:
def ():
function_suite
return The parameters should be entered in the same order you would want to be using them.
Invoking or Calling a Function
The definition of the function would only offer the name and specify the parameters that should be included in the function. Also, the block of code is structured. After the function has been given a basic structure, it can be executed by calling from another function. It can also be called directly from the Python prompt.
Pass by reference and value
The parameters in the Python language would always be passed by value. This means that if you change the parameters within the function, the same would get reflected on the original value.
def func_1(mylist):
mylist.append([17, 19, 23]);
print "Added values: ", mylist
return
mylist = [2, 3, 5, 7, 11, 13;
print "Original values: ", mylist
func_1(mylist);The output would be as follows:
Original values: [2, 3, 5, 7, 11, 13]
Added values: [2, 3, 5, 7, 11, 13, [17, 19, 23]]What are function arguments?
A function can be called by using the following different types of formal arguments. These are:
- Default arguments - These arguments assume a default value if there is nothing provided in the function call. They have to defined in the function definition.
- Keyword arguments - The keyword arguments are related to the calls. The caller would identify the arguments with the help of the parameter name. This would allow you to skip arguments.
- Required arguments - These are those arguments that are passed to a function in the correct order according to their defined positions.
- Variable-length arguments - There might be the need to write a function that can accept more parameters than what had been defined. These arguments are known as variable-length arguments.
These are some of the salient points of functions in Python.
If Statement
The if statement is a part of the decision-making construct of any language. The decision-making helps to anticipate conditions that are not known during the creation of the code. This statement helps the program to function differently in different conditions depending on the execution.
The actions would be taken depending on the way certain things proceed. The decision structures can be used for the evaluation of multiple expressions. These expressions should yield a boolean value, i.e. TRUE or FALSE as their outcomes.
The outcome of these statements depends on the value of TRUE or FALSE. This is how the structure of the code is to be implemented. A typical decision-making structure can be found in most of the programming languages. There would be a given condition. If the condition is evaluated to be true, a certain code would be executed, otherwise not.
Any value that is non-null or non-zero is assumed to be TRUE by the Python interpreter. A null or zero value would be automatically seen as FALSE. There are a few different types of selection or decision-making statements that are allowed by Python. These are the:
- if statements - This statement would be consisting of a boolean expression which would be followed by one statement or more.
- if..else statements - The if statement can even be followed by an optional else statement. This would be executed if the boolean expression evaluates to be false.
- nested if statements - In addition to those, the if and else if statements can be used another if or else if statement.
1. The IF Statement
It is quite similar to that found in other languages. It would contain a logical expression. Some comparisons would be made and a decision would be made depending on the output of the result. The syntax is like the following:
if expression:
statement(s)
If the expression that follows the if the keyword is evaluated to be TRUE, then the block of statement(s) would get executed. If it so happens that the expression is evaluated to be FALSE, then the code that follows the blocks of statements would be the ones where the control would jump to.
2. The IF..ELIF..ELSE Statements
An else statement can follow the if statement. The else statement is made to contain that block of code that is to be executed in case the result to the expression is FALSE. The else statement is actually optional and it is possible to have only one else statement following if.
If you are wondering what can be done if there are multiple expressions to consider, the elif statement can help you out. You can check multiple expressions and see if one is TRUE and execute that block of a statement(s). The elif statement is also optional like the else statement. However, there is no limit to the number of elif statements that can follow an if statement. The syntax would be something like:
if expression1:
statement(s)
elif expression2:
statements(s)
elif expression3:
statement(s);
..
..
elif expressionN:
statement(s);
else:
statement(s)Python does not allow switch..case statements like many other languages. But the structure can be implemented with the help of the if..elif..else statements.
3. Nested IF Statements
A condition might arise when checked on the basis of the result of another condition. The nested if statement becomes necessary in such a case. In these constructs, the if..elif..else statements can be present within another if..elif..else construct. The syntax can be quite varied in this case. There is no particular syntax. The if..elif..else constructs will lie inside other such constructs.
[ Related Article: What is Anaconda Navigator ]
Python Loops
When there is an occasion where you need to repeat something over and over again, python loops may come into use. However, this would be dependent on the requirement of the problem statement. In general, the statements would be executed sequentially.
This means that the first statement would be followed by the second statement. This would follow until the last statement of the function or the program. But the loops would be necessary when there is a certain block of statements that need to be repeated multiple times.
Python and even other programming languages would offer control structures that allow such complicated execution paths. The loop statement would allow executing the statement or the groups of statements multiple times. The Python programming language offers a few different types of loops. These loops would fulfil the following requirements.
- While loop - The while loop repeats the statements or the group of statements while the given condition is TRUE. It would be testing the conditions before entering the execution of the body of the loop. The condition could be any expression and a non-zero value would return TRUE. The loop would keep iterating as long as the condition is true.
- For loop - The for loop would be executing a sequence of statements multiple times and the abbreviations of code would manage the loop variable.
- Nested loops - One or more loops can be used another loop, like for or do..while loop. Any type of loop can be put inside any other type of loop. A while loop can be put inside a do..while loop, a for loop can be put inside a while loop and all the different combinations.
[ Related Article: Python For Loops with Examples ]
What are the loop control statements that should be understood?
The loop control statements would help to change the execution from the normal sequence. All the automatic objects would be destroyed that had been created in the scope after leaving it.
The following are some of the control statements that are supported by Python.
- break statement - The break statement would terminate the loop statement and transfer the execution to the statement that follows after the loop. The most common use for the break statement is found when there is some external condition that requires a premature exit from the loop. This statement can be used in any type of loop.
- continue statement - The continue statement would make the control skip the remainder of the body and the loop condition is checked before reiteration. The continue statement would be rejecting all the statements in the current iteration and the control would be moving to the top of the loop. This statement can also be used in the different types of loops.
- pass statement - It is a statement in Python that is used when you need to have a command according to the syntax but there is nothing to execute. It is just a null operation and nothing would happen when it is executed.
These are some of the most important facts about Python loops.
Python Classes and Objects

Since the inception of the language, Python has been object-oriented. Creating and using classes have been easy due to this fact. A few concepts about object-oriented programming should be clear before classes and objects can be created. Here are a few points that should be understood clearly.
- Class - A class would act as a user-defined prototype for the object. It would define the set of attributes characterizing an object of the class. The attributes are the data members, i.e. the instance variables and the class variables. There are methods as well which can be accessed via the dot notation.
- Class variable - It is a variable that would be shared by all the instances of the class. They are defined within the class but outside the methods. They are not used as frequently as the instance variables.
- Instance variables - This variable would be defined inside the method and would belong to the current instance of the class.
- Function overloading - Function overloading would mean assigning more than a single behavior to the particular function. The operation that is performed would vary by the types of arguments or objects involved.
- Data member - They can be class variables or instance variable. They hold the data that are associated with the class and its objects.
- Inheritance - Inheritance is a property of object-oriented languages where classes can be defined such that their characteristics can be transferred to another.
- Instance - An instance is an individual object of a certain class. An object that belongs to a class Circle would be an instance of the class Circle.
- Object - It is a unique instance of a data structure that would be defined by the class. An object would comprise both data members and methods.
- Operator overloading - It means assigning more than one function to a particular operator.
- Method - A method is a special kind of function that is defined in a class definition.
How are classes created?
The creation of a new class definition can be done with the class keyword. The name of the class should follow the class keyword immediately and it should be followed by a colon.
The syntax should be like the following:
class :
class_suite
The class can have a documentation string, which would be accessed with the help of ClassName.__doc__. All the important component statements of the class, including data attributes, class members and functions should be within the class_suite. Other class methods like normal functions can be declared. The exception is that the first argument to each method should be itself. Python would be adding the self-argument to the list.
Related Article: Numpy Broadcasting
How should the instance objects be created?
The creation of instances in a class can be performed by calling the class with the class name. Then you should pass whatever arguments the method would accept.
How can the attributes be accessed?
The attributes of the object can be accessed with the help of the dot operator. The class variable can be accessed using the class name.
[Checkout What is PyCharm?]
Python Regular Expressions
Strings have a very important role in every aspect of coding. There are many real-life scenarios where there would e a need for parsing the strings and operate on them. One of them could be working with regular expressions. A special sequence of characters is called a regular expression if it can help you to find or match other strings or sets of strings. A specialized syntax is used which is in a pattern. The regular expressions are quite common.
Python offers full support for the regular expressions using the module re. If there is an error while using the regular expression or during compilation, the re.error exception would be generated. There are two important functions which can be used for handling the regular expressions. Raw Strings are used as expressions to avoid confusions while dealing with regular expressions.
Working with the match function
The match function is used to match the regular expression patterns with the optional flags. The syntax for the function is:
re.match(pattern, string, flags=0)
- pattern - The pattern is the regular expression that has to be matched.
- string - This parameter should contain the string. The pattern would be expected to be present at the beginning of the string.
- flags - The different flags can be specified with the help of bitwise OR (|). They are modifiers.
The re.match function would be returning a match object is the process is a success. On failure, None would be returned. group(num) or groups() function of the match object can be used to get a matched expression.
Working with the search function
Another one is the search function which would be looking for the first occurrence of the regular expression in a string. There can be optional flags. The syntax is quite similar and is as follows:
re.search(pattern, string, flags=0)
- pattern - Like in the match function, this parameter would have a similar function
- string - The string here would be searched to match with the given pattern anywhere within it.
- flags - Different flags can be specified using the bitwise OR.
This function would also behave in a similar way and a match object would be returned on success. none would be returned on the failure of the matching process.
Visit here to learn Python Online Training in Bangalore
What is the difference between matching and searching?
There are two different primitive operations that can be based on the regular expressions - “match”, which would be checking for a match only at the beginning of the string, and “search” which would check for the match anywhere within the string.
How to work with Search and Replace?
One of the most important regular expression methods using regular expression is a sub. This method can be used to remove all the occurrences of the RE in a string with. All occurrences would be substituted until a certain max value is provided. The method would be returning a modified string value. The syntax should be as follows:
re.sub(pattern, repl, string, max=0)
These are some of the most popular ways of working with regular expressions in Python.
[ For More Info: Regular expression operations ]
Ways in Python to find out if a file or a directory exists
It would be required of many Python programs to check if there is a particular file available on the disk. There might be a need to make sure that the data is available before it can be loaded. You might even want to refrain from overwriting an existing file. The same can be so for directories. You might want to know if an output folder is available before the program is run.
There are actually several ways in Python to find out if a file or a directory exists. These can be performed using functions that have been put into the core language as well as the Python standard library. The following are three different techniques to look for the existence of a file in Python.
1. os.path.exists() and os.path.isfile()
One of the most popular way to look for the existence of a file in Python would be to use the exists() or the isfile() method. They can be availed in the os.path module and are present in the standard library. These functions can be availed both on Python 2 and Python 3. They are the most popular suggestions when you are trying to solve such a problem.
When the os.path.exists() function is called, it would be returning TRUE for directories and files alike. The os.path.isfile() function would then help you to differentiate between a file and a directory.
However, it is important to keep in mind that this function would only check if the file exists and would not care if the program would have access to them. If there is a need to verify the access, trying to open the file is just the thing you would need to do.
2. open() and try..except
The open() method is a built-in function that attempts to open the file. It is a pretty straightforward way to check if a file does exist. The open call will be completed successfully if the file does exist and a valid filehandle would be returned. A FileNotFoundError exception would be raised otherwise. You would be able to watch for the FileNotFoundError exception in your code and it can be used to detect whether the file exists. This can be done with the help of the try..except construct. The close() method on the file object should also be called to release the filehandle.
There is also an os.access() function available in the standard library which would help to check if a file exists and whether access is available to it.
3. pathlib.Path.exists()
The Python versions from 3.4 and above offer a pathlib module where you can find an object-oriented interface to deal with the file system paths. This module is much better than treating the file paths like simple string objects. This would offer abstractions and helper functions for the file system operations. There would be existence checks and you would be able to find out if a path points to a directory or a file.
The Path.exists() method can be used to check if the path points to a valid file. If you would want to find out if the path is a file or a symbolic link, you should be using Path.is_file() method.
| Learn Top Python Interview Questions and Answers |
Python COPY File
Copying a file is a very simple job and can prove to be very essential at times. Hence, it would be good if you would know how to copy files using Python. There are lots of important modules from the language like subprocess, os, and shutil that help in I/O operations. Here are some unique ways to copy a file in Python.
Before starting out, it is important to find out which copy files should be the best for you. The I/O operations are performance-intensive and might lead to bottlenecks. There are some programs that might copy in blocking mode and some perform them asynchronously. Copying both files and folders can be automated with the help of the shutil module. The module has an optimized design and would save you from time-intensive operations.
1. shutil.copyfile() method
The contents of the source can be copied to that of the destination considering that the target is writable. An IOError would be raised if the right permissions are not available to you. The input file is opened and the file type is ignored. Special files are not treated differently and no clones would be created.
The copyfileobj() is a lower-level function that is used by the copyfile() method. The file names would be taken as arguments, opened and the filehandles are passed to the copyfileobj() method. There is a third optional argument that can be used to specify a buffer length.
2. shutil.copy() method
This method is very much like the cp command that can be found in Unix. If the target is a folder, a new file would be created inside it with the same name as the source file. The method would be syncing the permissions of the target file with the source file and the contents would be copied. If you are copying the same file, the SameFileError would be thrown.
3. shutil.copyfileobj() method
The job of this method is to copy the file to a target path or file object. It is needed to be closed explicitly if the target is a file object. An optional argument is assumed which can be used to supply the buffer length. The buffer has a default size of 16 KB.
4. shutil.copy2() method
The copy2() method is quite like the copy() function. The difference is that the modification times and access would also be added in the meta-data while the data is copied. The SameFileError is raised while trying to copy the same file.
While the copy() method would just get the permissions, the metadata with the timestamps is only offered by copy2(). Internally, the copy() method would call copyfile() and copymode(), while the copy2() would be calling copymode() and copystat().
These are some of the best ways to copy a file in Python. Python is a language that is rich in features. One can utilize all of the features and perform the single task in multiple ways. The shutil, subprocess and os modules offer a lot of support for the I/O operations.
Python Rename File
I/O operations are very important and might be required by any program. One such important operation is renaming a file. This is often required during file handling. You can rename files using Python. Both single and multiple files can be renamed in this way. Let us look at how this can be performed easily. The rename() method from the os module would be used for this purpose. Now we need to see how the renaming of files using Python can actually be achieved.
The os.rename() method
In Python, the method used for renaming files is os.rename(). It would be helpful to take a look at the method from the os module. Just as the name would suggest, it is used for the renaming of files and directories. The syntax of the os.rename() method is as follows:
os.rename(src, dst)
src would mean the source file or directory and dst is the destination file or directory. The function does not return any value. The following is an example of the rename() method:
os.rename('New_Folder', 'Python_Code')
This piece of code would rename a directory by the name of New_Folder to "Python_Code". However, if you try to rename a file or directory to an already existing folder, an error would be raised.
How would you be renaming multiple files using Python?
Manually renaming each file might not be an option if there are hundreds or thousands of files. You would need to have a way where you would be able to rename many files at a single go. Python makes it possible for you. You can do it by simply using a for-each loop. You should then be renaming all the files using a certain regulated pattern. This is a very successful way of renaming files in Python.
But in most cases, we would be trying to rename a single file among hundreds. We can do that by searching for a file. We can use Python code to locate the file and rename it. But if we are renaming multiple files, we would want to name them differently.
This can be done in for a loop by using a counter or an iterator variable. Thus the use of the function can be quite flexible. You can use the function in any way you would like to depend on what you would want out of it.
The rename() method can be used in conjunction with a piece of code where the user can be asked for the general name of the files and a number to start with. There can even be increment or decrement counts depending on the choice of the user.
Thus the Python rename() method can be used in different ways and single as well as multiple files can be renamed depending on the requirement.
[ Check out: Selenium With Python Interview Questions ]
Python ZIP file with Example
ZIP files can help save a lot of space and are a convenient way of sharing files. They also provide a way by means of which folders can be shared as attachments. Thus the creation of zip or tar archives can be of a lot of help. Fortunately, all of that can be done with Python quite easily. The following command can be used to create a zip directory:
shutil.make_archive(output_filename, 'zip', dir_name)
The command that would allow you to control on the files that you would like to archive is as follows:
ZipFile.write(filename)
The following steps need to be followed to create a zip file in Python.
- Step 1 - You need to ensure that you have the proper import statements and that they are in order. You would need to import the make_archive class from the shutil module. Then the split function is to be used to split the directory out and the file name from the path to the location of the text file.
- The shutil.make_archive() is then called to create the archive file which would be in zip format. Following this, we would be passing the root directory which we would like to be zipped up. When the code is run, the archived zip file can be seen.
- Step 2 - Once the archive file has been created, it can be right-clicked and the O.S. is to be selected. The archived files would be shown in order. The archive.zip file would appear on the O.S.
- Step 3 - When you do double-click on that file, the list of files present in there can be seen.
- Step 4 - Python gives much more control over the archive as it can define which specific files should be present in the archive. The Zip file class should be imported. This module would allow full control over creating zip files. A new zip file can be created. Creating a new Zip file class would require passing in permission since it is a file. You would need to write information into the file as new zip. A variable is to be used to refer to the new zip file created. The write function can be used to add the files. No command to close the files is given since "with" scope lock is used. If the program falls outside the scope, the file would be cleaned up and closed automatically.
- Step 5 - When you right-click on the file and select the O>S>, the archived files would be shown in the folder.
Let us look at an example of how it can be performed.
import os
import shutil
from zipfile import ZipFile
from os import path
from shutil import make_archive
def main():
# Check if the file is present
if path.exists("books.txt")
# get the path to the file in the present directory
src = path.realpath("books.txt");
# rename the original file
os.rename("store.books.txt", "books.txt")
# now put the files into a ZIP archive
root_dir.tail - path.split(src)
shutil.make_archive("books archive", "zip", "root_dir")
# more fine-grained control over ZIP files
with ZipFile("","w") as newzip:
newzip.write("books.txt")
newzip.write("books.txt.bak")
if __name__ == "__main__":
main() Manipulating XML with Python
Often applications are needed that can be read by other applications without any heed to the developmental language or the operating system working underneath. XML is one such open-source and portable language that allows programmers the power to do so.
The Extensible Markup Language (XML) is a markup language like SGML or HTML and is actually recommended by the World Wide Web Consortium. The language is available as an open standard.
XML would be extremely useful to keep track of the small to medium amounts of data and there is no need for requiring a SQL-based backbone.
What should you know about the XML Parser Architectures and APIs?
You would get a minimal set of interfaces from Python while working with XML, but they are very useful. The APIs that are the most basic and broadly used are the DOM and SAX interfaces. They are as follows:
- Document Object Model or DOM API - This API acts as a World Wide Web Consortium recommendation when the entire file is read into the memory and stored in the hierarchical form to represent the features of the ML document.
- Simple API for XML or SAX - The events of interest are call backed by the register and then the parser is let to proceed through the document. This becomes helpful when there are memory limitations or the documents are large. The file is parsed as it is read from the disk. The entire file would never be stored in memory.
For obvious reasons, DOM is much faster than SAX when large files are being used. DOM, if used exclusively, can kill the resources, if they are used on a lot of small files. However, DOM would allow making changes to the XML file, while SAX is just read-only. These two APIs are somewhat of a complement to each other and this makes it easier to use them for the large projects.
How would you be using SAX APIs for parsing XML?
SAX is much like a standard interface for event-driven XML parsing. Parsing XML with SAX would generally have the requirement of creating a ContentHolder of your own. This is done by subclassing xml.sax.ContentHolder. The ContentHandler would be handling the particular tags and the attributes of XML. The object is also responsible for providing methods to handle the various parsing events. The methods are called as the XML files are parsed.
The start document and endDocument methods are called at the beginning and the end of the XML file. The characters(text) method passes the character data of the XML file through the parameter text.
The ContentHandler would be called at the start and the end of each element. The methods startElement(tag, attributes) and endElement(tag) methods are called if the parser is not in namespace mode. The corresponding startElementNS and end elements methods would be called otherwise.
Some of the most useful syntaxes are as follows:
xml.sax.make_parser([parser_list])
xml.sax.parse(xmlfile, contenthandler[, errorhandler])
xml.sax.parseString(xmlstring, contenthandler[, errorhandler])Parsing with DOM APIs can be the easiest if a minidom object is created using the xml.dom module. It would offer a simple parser method that would quickly create a DOM tree from the XML file.
[ Check out Top Python Project Ideas For Practice ]
Advantages of Python
Python has been topping the charts among popular programming languages for quite a few years. It is being preferred by programmers over C, C++ or even Java. Over the 25 years of its reign, Python has undergone some drastic changes. Lots of features have been added. While Python 1 had the module system and interacted with the Amoeba Operating System, Python 2 had a garbage collector and Unicode Support. Python 3 avoids duplicate modules and constructs.
Python is preferred for the versatile features and fewer codes. Python has lots of interesting characteristics like being modular, object-oriented, portable, dynamic, interpreted and interactive. It is also extensible in C and C++.
Python also finds great use in diversified applications. These include web frameworks, language development, applications, graphic design applications, prototyping and gaming. Thus the language is very useful to software development companies.
The advantages of Python are as follows:
- Integration Feature - The Enterprise Application Integration is supported in Python making it quite easy to develop web services through the COBRA and COM components. There are powerful control capabilities as it has the capacity to call directly through Java, C, or C++ via Jython. The language can also process XML and the other markup languages as it can run on all the modern operating systems with the same bytecode.
- A Huge Collection of Support Libraries - Large standard libraries are provided by Python which would include areas like the Internet, string operations, operating system interfaces, web service tools and protocols. The highly used programming tasks would already be scripted into it which further limits the lengths of code that need to be written in Python. This means programmers can get easy to access to different modules and can create programs without the need for writing lengthy bits of code. All the necessary classes and modules are easily available for further development and direct applications.
- Improved Productivity of the Programmer - Extensive support libraries that are present for the language helps the programmer immensely. The clean object-oriented designs also help to increase the productivity of the programmer. This makes Python a very much preferred language and has led to an increase in the demand of the language.
- Productivity - The amazing features of Python has led to increased overall productivity. The unit testing framework and the strong process integration features help to create pieces of code that are not only elegant but are versatile and can be used to create programs that are quite useful. The enhanced control capabilities also allow an increase in speed for most of the applications. The applications created using Python are quite secure and offer great performance. Thus the language offers a great option to produce scalable multi-protocol network applications.
Characteristics of Python/ Python Features
It has not been too long ago that the number of programming languages could be counted with the fingers in our hand. But today there are lots of languages out there, each with its own specialty. The unique features of Python make it stand apart from the crowd. The characteristics of a language decide if it would be chosen for a certain project. It is important to look at the features of the language. The following are some of the most important characteristics of Python:
1. A Language for the Beginner - Python is a language for the beginner. If someone has never programmed before, using a statically typed language like Python would make sense. Python is a language that would set the pace of the course by offering the beginner the important programming concepts to learn, like procedures and loops. The beginners can even be introduced to user-defined objects. Extreme syntactic simplicity can be found in the language.
2. Simple Language, Easy to Learn - It is extremely easy to start with Python. The setup is simple and so is the syntax. Not only that, in addition to simplicity, there are lots of practical applications in important fields like web development. Compared to other languages, the syntax is not confusing. Some modules can be imported easily which would make the job much easier. There is no need to learn about IDEs, build systems, or special text editors. You can do everything with the interactive editor.
3. A cross-platform language - The language can run on different platforms like Linux, Unix, Windows, and even Macintosh. The Python programs written on Windows systems would run on Linux and vice versa.
4. Interpreted Language - Python is an interpreted language. This means the code would be executed line by line. There would be no separate compilation process when an interpreted language like Python is used. The program would be run from the source code itself. Thus debugging would be quite easy for beginners. The source code is converted into an intermediate form called bytecodes, which is then transformed into the respective machine code. There would be no need to worry about the loading or linking with libraries.
5. Object-Oriented - Object-oriented features are supported by Python. The class mechanism of the language allows the addition of classes with minimal syntax. The classic mechanisms that can be found in Modula-3 and C++ form the heart of Python. Strong encapsulation is one of the things that is not offered by Python.
6. Open Source and Free - Python is a free open-source software. You are free to distribute copies of the software. You can read the source code of the software and make changes to it. You can even use it in new programs. The language is freely available at the official website www.python.org. The source code can also be availed.
7. Extensive Libraries - The standard library is quite huge. There are built-in modules that would provide access to the system functionality and be accessible to the Python programmers worldwide. You can also do other things like document generation, threading, unit testing, and use regular expressions.
Differences between Python, Ruby, PHP, TCL, PERL, and Java
The choice of a programming language requires the consideration of real-world constraints like cost, prior investment, availability, training, and sometimes, even emotional attachment. These aspects are, however, quite variable. The following comparison would only consider language issues.
| Python | Ruby | PHP | TCL | PERL | Java |
| Python programs are very easy to develop and code. It is a scripting language and is very useful for generating small scripts. | Ruby does not have a lot of data structures and internal functions. | PHP syntax is much like C/C++ and uses a structural approach. | TCL is s standalone programming language and the data structures are very weak. | Perl is generally suited for common application-oriented tasks like scanning a file and generating reports. | Java programs take more time to develop but are quite fast. The programs are robust and handy and are written in an object-oriented approach. |
| Python uses high-level data types but it is farther away from machine code and is an object-oriented language. | Ruby is generally preferred for web development and functional programming. | Development features are available as built-in features in PHP, unlike most other languages. |
The language is slow in executing commands, slower even than Python. | Perl is not meant for high-level data structure design and creating easily readable code like in OOP languages. | Java has high-level data types as well as containers. However, it is not as easy to code in Java as some other languages, like Python. |
Python DateTime
Python provides a package DateTime, which contains inbuilt functions and classes that enables you to manipulate dates or times individually or as a single entity. There are two kinds of date and time objects that are available with Python – naïve and aware. An aware object has enough details (such as daylight savings, time zone and etc) to locate itself in relation to the other aware objects and on the other hand, naïve objects are the ones that do not hold enough details to relate with other objects.
With this little background knowledge, let’s get down to business in understanding the classes provided by Python. Starting with date classes:
Classdatetime.date :Returns a naïve date object, provides attributes such as year, month & dayClassdatetime.time: Returns a time object and also provides attributes such as hour, minute, second, microsecond and tzinfoClassdatetime.datetimeClassdatetime.timedelta: Provides the difference of two date, time or DateTime objects to microsecond resolutionClassdatetime.tzinfo: Is an abstract class for providing time zone information.
Let’s now look at a small example of how to access today’s data in Python using the classes provided earlier:
Now look at a small example to display the current local time:
Getting the formatted time from Python is a bit tricky, uses more than one function at once to achieve what we want to show in a single line of code. The best method available from Python is to use asctime() method.
Let us look at the various methods and attributes provided by the time class:
- time.altzone : This is to be used only when the daylight savings is zero
- time.asctime([tupletime]) : This method accepts a tuple-time and returns a very well readable string as like this – ‘Mon Aug 28 20:25:14 2017’
- time.clock(): Returns the current CPU’s time as a floating point number of seconds. On a computational costs approach, this method is preferred over time.time().
- time.ctime([secs]) : Just like time.asctime()
- time.gmtime([secs]) : Accepts an instant expressed (seconds) since the epoch and in return, gives time-tuple t in UTC time zone.
- time.localtime([secs]): Just like time.gmtime(secs)
- time.sleep(secs): Puts the calling thread on sleep for the number of seconds specified in the command
- time.strftime(fmt[,tupletime]): Takes an instance as input and returns a string representing the instant in the format provided to the command above.
- time.strptime(str,fmt=’%a %b %d %H:%M:%S %Y’): Parses the string as per the format provided and returns the instance in a time-tuple format.
- time.time(): Returns the current time instant.
[ Check out Python Sleep() Method ]
Let us now look at the Calendar class and also as an example, let us look at the month of August 2017.
Now let us take a look at the functions provided by the Calendar class:
calendar.firstweekday():This function returns the current weekday starting each week. By default, when the calendar is first imported, this is 0 – Monday by default.calendar.isleap(year):This function is going to return true if the year passed as an argument is a leap year and returns false if it is a non-leap year.calendar.leapdays(y1,y2):This function is going to return the total number of leap days between the years specified within the range of y1 and y2.calendar.monthrange(year,month) :This function is going to return a list of lists of ints. Each sublist denotes a week.calendar.setfirstweekday(weekday):This function is going to set a specific weekday code as a week-day.calendar.timegm(tupletime):This is exactly the opposite of time.gmtime(). This function accepts a time-tuple and returns a floating-point number of seconds since the epoch.calendar.weekday(year,month,day):This function returns the week-day code of the date specified by the input parameters to this function. 0 being Monday and progressing until 6, which is being a Sunday.
Python Range Function
As a newbie programmer in Python, you should have encountered the range() function amidst your learnings in loop constructs. If you have not encountered it earlier, you are now at the correct place to understand what this function is for and how this can be used at all. The range() function is provided by Python to generate an automatic sequence of integers in the form of a list.
A point to note is that the given endpoint is never the part of the range that this function generates, as range() function generates a sequence of integers starting from 0 and ends just one integer below the range provided for. Let us take a look at one of the simplest examples to understand what this function does:
The range() function is available in two sets of parameters, as listed below:
range(stop)
This method will just take the end of the sequence and the function generates the sequence excluding the number specified in the stop input parameter.
range([start],stop[,step])
This method will start the sequence from the start as provided in the function until the stop is reached with a user-defined step size. The parameter step is an optional parameter if nothing is provided then by default the step size is picked up as 1.
The example needs a lot of discussions for us to understand the specifics of it.
- All parameters should be integers only
- All parameters can be positive, negative, or a combination of both.
- range() function is 0-index based (just as like lists are)
- If the range() function is given a beginning and end of the sequence that it needs to generate, then it will generate as per input excluding the end number provided in the input to the function.
- If the range() function needs to generate a sequence of numbers not with a step of 1 (which is by default), you can specify this on the function itself and the sequence would be generated as per the step size mentioned.
- If the range() function is not given any beginning number then it by default starts from 0 and this is the same that we have tried to display in the example below.
- Now with these points discussed, the example (below) and the concept should be absolutely clear.
Example:
<script.py>
print(‘range(1,5) is created & iterated over to prrint it’)
rangeVar = range(1,5)
for intNum in rangeVar:
print(intNum)
print(‘range(‘range of numbers starting from 25 with a step of -5’)
for intNum in range(25, 0, -5) :
print(intNum)
print(‘if we ddo not give the beginning, starts from 0’)
rangeVar = range(5)
for intNum in rangeVar :
print(intNum)
<script.py>output:
range(1,5) is created & iterated over to print it 1 2 3 4 5 range of numbers starting from 25 with a step of -5 25 20 15 10 5 If we do not give the beginning, starts from 0 0 1 2 3 4Python Database
Object-relational database management system (ORDBMS) are software, which stores the data in a permanent manner.
- The object-relational database management system allows performing the ‘random read’ and ‘ random write’ operations on the data of the ORDBMS.
- ORDBMS provides security for the data.
- Online transaction processing (OLTP) operations implementations purpose we have to use ORDBMS.
Difference ORDBMS are:
- ORACLE
- MYSQL DB2
- SQLITE3
- SQL SERVER
- TERA DATA.
To provides the communication between the python program to the corresponding ORDBMS, we use databases-related external modules. Databases related to external modules we can install by using:
“PHP” applications
www.oracle.com
10G
11G
12C
Download & install the oracle database 11g or 12c Enterprise edition
Username=SCOTT
Password=tiger
Service name (0r) logical database name (0r) SID or host storing name=oracle
Part no=1521
IP address=local host- Download & install ‘python 2.7 version”
- Microsoft visual c++ compiler for python 2.7 version” download and install.
Download & Install the “cx_oracle” module by using the following command:
Search in command prompt
c:/users/mindmajix>cd….
c:/users>cd….
c:/>cd python 2.7
c:/python 2.7 > cd scripts
c:/python 2.7/scripts>PIP install cx_oracleWe can establish a connection with the database by calling connect function of cx_oracle module
Syntax:
Import cx_oracle
con=cx_oracle.connect (‘dbusername’, ‘dbpwd’,ipadd of the computer where database is installed: portno/ database service name’)
- Connect function establish the connection with database with the given details, store the connection details into connection object and that object address will be stored into the given variable.
- After establishing the connection with database to sent the SQL queries to the database we have to create “cursor object”
- Cursor objects can be created by the calling cursor method of the connection object.
Syntax:
cur=con.cursor()
- By calling method of cursor objects, we can execute the sql queries or psql programs
- By calling the methods of cursor objects we can read the data from the cursor object which is given by the database (sql) queries or psql programs
- After reading the data from the cursor object we have to close the cursor object by calling close method of cursor object.
- After closing the cursor object we have to close the connection object by calling close method of connection object.
Example:
Import cx_oracle
con.cx_oracle.connect(‘scott’, ‘tiger’, ‘localhost:1521/orcl’)
cur=con.cursor()
cur.execute(“select*from dept”)
For row in cur:
Print (row)
cur.close()
con.close()
Output:
(10, ‘ACCOUNTING’, ‘NEW YORK’)
(20, ‘RESEARCH’, ‘DALLAS’)
(30, ‘SALES’, ‘CHICAGO’)
(40, ‘OPERATIONS’, ‘BATSON’)Whenever a connection is established with the database connection should get closed before terminating the program.
To close the connection if the connection is established we use exception-handling techniques.
[ Related Article: Python SQLite Tutorial ]
Conclusion
Thus, Python is a really wonderful language and offers great functionalities. Started in the year 1991 by Guido van Rossum, this language has reached new heights in recent years. It is perfect for developing anything, from small scripts to huge applications. Bigger organizations are taking up Python as their language of choice and this is, in turn, improving Python and its huge extensive libraries.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Python Training | Jul 21 to Aug 05 | View Details |
| Python Training | Jul 25 to Aug 09 | View Details |
| Python Training | Jul 28 to Aug 12 | View Details |
| Python Training | Aug 01 to Aug 16 | View Details |

Madhuri is a Senior Content Creator at MindMajix. She has written about a range of different topics on various technologies, which include, Splunk, Tensorflow, Selenium, and CEH. She spends most of her time researching on technology, and startups. Connect with her via LinkedIn and Twitter .














