
- Django Interview Questions
- Python Array Examples
- Python enum
- Python Enumerate with Example
- Python Flask Tutorial For Beginners
- Python For Beginners - Way To Success
- Python For Data Science Tutorial For Beginners
- Python for loop
- Python GET and POST Requests
- Python IDEs for Python Programmers
- Python Interview Questions
- Python Lists with Examples
- Python Partial Function Using Functools
- Python Print
- How to generate random numbers in python
- Python Regular Expression (RegEx) Cheatsheet
- Python Sleep Method
- Python List Methods
- Python Split Method with Example
- Python String Functions
- Python Tutorial
- Python Variable Types
- Python vs Java
- Python vs SAS vs R
- Python Operators
- Code Introspection in Python
- Comprehensions in Python
- Python Exception Handling
- Defining Functions - Python
- Generators & Iterators in python
- Install Python on Windows and Linux
- Introduction to Python Programming
- Lists concepts in Python
- Loops in Python
- Regular Expression Operations in Python
- Python Serialization
- String Formatting - Python
- R vs Python: Which is better R or Python?
- Six Digit Salary With Python
- Top 20 Python Frameworks List
- Why Learn Python
- Python Substring
- OOPs Interview Questions
- Career Shift To Python : Success Guaranteed
- Face Recognition with Python
- Go vs Python
- Python Pandas Interview Questions
- OpenCV Interview Questions
- Python Project Ideas
- Flask Interview Questions and Answers
- Array Interview Questions
- What is PyCharm?
- What is Seaborn in Python?
- What is Anaconda Navigator
- Numpy Broadcasting - Detailed Explanation
- Python Data Science Interview Questions
- Genpact Interview Questions
- Python Developer Job Description
- Pandas Projects and Use Cases
- DataFrame Tutorial
- How to install Python on Windows
- Pyspark DataFrame
PySpark is an open-source distributed computing software. It helps to frame more scalable Analytics and pipelines to enhance processing speed. It also acts as a library for large-scale data processing in real time. When you utilise PySpark, you may expect a 10x increase in disc processing performance and a 100x increase in memory processing speed.
But, before we begin with the PySpark interview questions 2024, allow us to present in front of you some essential facts about PySpark:
- From 2019 to 2026, the PySpark service market is expected to increase at a CAGR of 36.9%, reaching $61.42 billion. This shows that the demand for Big Data Engineers and Specialists will skyrocket in the coming years.
- PySpark Developer's salary range is from $124,263 per annum.
Now that you know the demand for PySpark, let's begin with the list of PySpark Interview Questions to help you boost your professional spirit.
PySpark 2024 (Updated) questions and solutions weblog had been created through us into stages; they are:
Top 10 Pyspark Interview Question And Answers
- Explain PySpark.
- What are the main characteristics of PySpark?
- What is PySpark Partition?
- Tell me the different SparkContext parameters.
- Tell me the different cluster manager types in PySpark.
- Describe PySpark Architecture.
- What is PySpark SQL?
- Can we use PySpark as a programming language?
- Why is PySpark helpful for machine learning?
- List the main attributes used in SparkConf.
PySpark interview questions and answers for freshers
1. Explain PySpark.
PySpark is software based on a python programming language with an inbuilt API. It was developed in Scala and released by the Spark community. It supports the Data Science team in working with Big Data. PySpark is a good learn for doing more scalability in analysis and data science pipelines.

2. Tell me the differences between PySpark and other programming languages.
- It has an inbuilt API, whereas, in other programming languages, we need to integrate API externally from a third party.
- Implicit communication can be done in PySpark, but it is impossible in other programming languages.
- Developers can use the map to reduce functions as PySpark is map-based.
- We can address multiple nodes in PySpark, which is impossible in other programming languages.
3. Why should we use PySpark?
- Due to the most helpful ML algorithms implemented in PySpark, we can use it in Data Science.
- We can manage synchronization points and errors.
- Easy problems can be resolved quickly because all code is parallelized.
4. What are the main characteristics of PySpark?
The primary characteristics of PySpark are listed below:
- Nodes are abstracted - This means we can’t address an individual node.
- Network is abstracted - Only implicit communication is possible here.
- Based on Map-Reduce - Additionally, programmers provide a reduce and map function.
- API for Spark - PySPark is a Spark API.
| Looking forward to a career in a Big Data Analytics? Check out the "PySpark Training" and get certified today |
5. What are the advantages of PySpark?
- Easy to write - For simple problems, it’s easy to write parallelized codes.
- Error handling - Framework easily handles errors when it comes to synchronization points.
- Algorithms - Most of the algorithms are already implemented in Spark.
- In-memory computation - Through in-memory processing, Spark helps you to increase the processing speed. And the best thing is data is cached, thus allowing to fetch data from the disk every time, saving time.
- Swift processing - One of the significant benefits of working with Spark is it provides a high processing speed of 10x faster on the disk and 100x faster in memory.
- Fault-tolerance - Spark is specially designed to manage the malfunction of any worker node in the cluster, assuring that data loss is decreased to zero.
6. Tell me the disadvantages of PySpark.
- While using the Mapreduce process, we may face some errors.
- It is more efficient for a significant amount of data, so we can face less accuracy when dealing with a small data set.
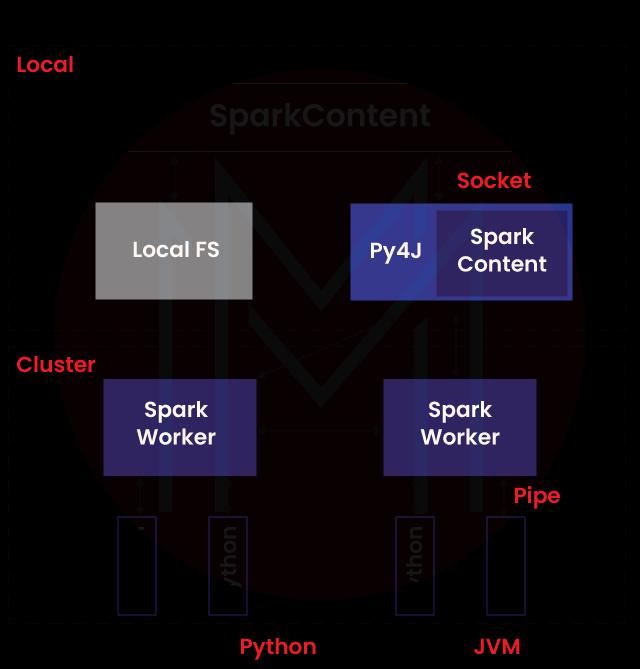
7. What do you mean by SparkContext?
SparkContext is the software entry point for PySpark developers. When the developers try to launch this software, CparkContext will launch JVM using Py4J ( One of Python Library). This is a default process to provide as'sc' to the PySpark API.
8. Explain SparkConf and how does it work?
Once the developer wants to run the Spark API locally in a cluster, they need to use SparkConf to configure the declared data parameters. We can write conf=new SparkConf().setMaster(local[2]) to declare the particular parameters.

9. What do you know about SparkFiles?
To get the actual path of a file inside Apache Spark, we need to use SparkFiles. This is one of the Spark objects and can be added through SparkConf. We can access Spark jobs using SparkFiles. We can get the directory path through SparkFiles. We can set the recursive value to true so that directory will open.

10. Why do we need to mention the filename?
Developers can find out the files by their filenames as the file extension is attached... Developers can understand file names by the filename first portion. For say, "setup" is the first part of setupact.log, so the file name is a setup that developers can understand easily.
11. Describe getrootdirectory ().
The developers can obtain the root directory by using getrootdirectory().
It assists in obtaining the root directory, which contains the files added using SparkContext.addFile().
12. What is PySpark Storage Level?
Storage level defines how RDD( Resilient Distributed Dataset) will be stored in a database. It also determines the storage capacity and focuses on data serialization.
13. Explain broadcast variables in PySpark.
Developers can save the data as a copy into all nodes. All the data are variable fetched from machines and not sent back to devices. Broadcast variables will do code block to save the data copy as one of the classes of PySpark.
14. Why does the developer needs to do Serializers in PySpark?
We can manage the data by serializers to tune the process. cPickle serializers are most effective for Python PySpark. It can handle any Python object. There are other serializers like Marshal, which doesn't support all Python objects.
15. When do you use Spark Stage info?
In PySpark, developers can see the information about the Spark stages by using spark stage info. This is a physical unit that executes multiple tasks in computation. Spark stage info is controlled by DAG(Directed Acyclic Graph to process and transform any data.
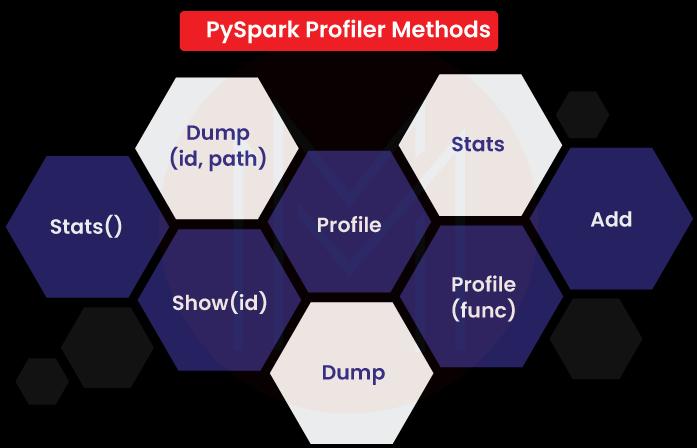
16. Which specific profiler do we use in PySpark?
Only one profiler is supported in PySpark and manages the usages of the custom profiler data. That means we can configure another profiler to maintain the output. We need to also declare the required methods for custom profilers :
- Add: we can add another profiler or add to an existing profile. SparkContext build-up usually initiates the different profile classes.
- Dump: To dump all the profiles to a particular path, we need to use the Dump profiler.
- Stats: We can get back the gathered stats by using this stats profiler.
- Profile: We need to use this to create a system profile as a defined object.
17. How would you like to use Basic Profiler?
By default, this is the standard profiler. We can use this while doing conjunction in cProfile and the accumulator.
18. Can we use PySpark in the small data set?
We should not use PySaprk in the small data set. It will not help us so much because it's typical library systems that have more complex objects than more accessible. It's best for the massive amount of data set.
19. What is PySpark Partition?
PySpark Partition allows you to split a large dataset into smaller ones using one or more partition keys. You can also use partitionBy() to create a partition on multiple columns by simply passing columns you want to partition as an argument.
Syntax:
Syntax: partitionBy(self, *cols)20. How many partitions can you make in PySpark?
PySpark/Spark creates a task for each partition. You can transfer data from one partition to another using Spark Shuffle operations. By default, 200 partitions are created by DataFrame shuffle operations.
21. Why are partitions immutable in Pyspark?
Generally, in Pyspark, every transformation creates a new partition. Partitions utilise HDFS API for making the partitions distributed, immutable, and fault-tolerant. Partitions are also knowledgeable about data locality.
22. What are the main differences between a Dataframe, Dataset, and RDD?
Following are the critical differences between an RDD, a dataframe, and a Dataset:
RDD
- RDD refers to the Resilient Distributed Dataset. It is the core data structure of the Pyspark.
- It is the low-level object that is highly effective in carrying out the distributed tasks.
- RDD is suitable for performing low-level operations and transformations and controlling the dataset.
- RDD includes all the DataFrames and datasets in the Pyspark.
- RDD is primarily used to alter the data with functional programming structures rather than domain-based expressions.
- If you have the same arrangement of data, that must be calculated again, and RDDs can be effectively preserved.
Dataset
- A dataset is the distributed collection of the data. It is the subset of the DataFrames.
- Dataset is the newly added interface in Spark 1.6 that provides the RDD benefits.
- The dataset includes the best encoding element. It offers similar security in an organised way, contrary to the information edges.
- Through the Dataset, we can benefit from the catalyst optimisation. We can also utilise it to get an advantage from the fast code generation of Tungsten.
DataFrame
- A data frame is the same as the relational table in Spark SQL. It promotes the visibility of structures like segments and lines.
- If we are working on Python, it is best to begin with the DataFrames and then switch to the DataFrames if we want more flexibility.
- One of the significant drawbacks of the DataFrames is the compilation time. For instance, if the structure is unknown, we cannot control it.
23. What do you mean by data cleaning?
Data Cleaning is preparing the data by analysing it and modifying or removing it if it is incomplete, incorrect, irrelevant, or incorrectly formatted.
24. Explain PySpark ArrayType with an example.
PySpark ArrayType is the collection data type that scales PySpark’s DataType class, which is superclass of all types. The PySpark ArrayType includes all kinds of items. The ArrayType() method includes only the similar types of items. The ArrayTye() method can be used for constructing the instance of the ArrayType. It accepts two arguments:
- valueType: The valueType must extend the DataType class in Pyspark
- valueContainsNull: It is the optional argument. It defines whether the value can receive the null and is set to True by default.
25. Explain Parquet File
In the Pyspark, the Parquet file is a column-type format supported by various data processing systems. Spark SQL can carry out read and write operations through the Parquet file. The Parquet file will have a column-type format storage, which offers the following advantages:
- It is small and utilises less space.
- It allows us to fetch particular columns for access
- It uses type-specific encoding
- It provides better-summarised data
- It includes very restricted I/O operations.
26. Why is Pyspark quicker than the Pandas?
Pyspark is quicker than the pandas as it endorses executing the statements in the distributed environment. For instance, Pyspark will be executed on different machines and cores, which are not available in Pandas. This is the primary reason why Pyspark is quicker than the Pandas.
27. Describe Cluster Manager.
In the Pyspark, a cluster manager is the cluster mode platform enabling Spark to run by offering all the resources to the worker nodes per their requirements. A Spark cluster manager environment includes the controller node and multiple worker nodes. The controller node offers the worker nodes with the resources like processor allocation, memory, etc., as per the nodes’ requirements through the cluster manager. PySpark endorses the below cluster manager types:
- Apache Mesos: This cluster manager is utilised to run the PySpark apps and Hadoop MapReduce.
- Standalone: This is the simple cluster manager that comes with the Spark.
- Kubernetes: This Cluster Manager is the freeware cluster manager that allows you to automate deployment, scaling and automatic management of the containerised applications.
- Hadoop YARN: This cluster manager is utilised in Hadoop2.
- Local: This cluster manager is the mode to run the Spark applications on desktops or laptops.
28. What are the significant advantages of PySpark RDD?
The following are the significant advantages of PySpark RDD:
- Fault Tolerance: The PySpark RDD offers fault tolerance features. Whenever the operation fails, the data gets reloaded automatically from available partitions. This offers continuous experience in the execution of PySpark applications.
- Immutability: The PySpark RDDs are immutable. If we generate them once, we cannot change them later. We should create a new RDD whenever we try to apply the transformation operations on the RDD.
- In-Memory Processing: The PySpark RDD is utilised for loading the data from disk to memory. We can continue RDDs in memory to reuse the computations.
- Partitioning: When we generate the RDD from the data, the components in the RDD are partitioned to cores available by default.
- Lazy Evolution: PySpark RDD uses the Lazy Evolution process. In the PySpark RDD, transformation operations can be stored in DAG and are assessed when it discovers the first RDD action.
29. How can we implement machine learning in Spark?
By using MLlib, we can implement machine learning in Spark. Spark offers a scalable machine learning record known as MLlib. It is primarily utilised for making machine learning scalable and straightforward with standard learning use cases and algorithms like weakening filtering, clustering, and dimensional lessening.
30. What is the use of DStream in PySpark?
In PySpark, DStream refers to the Discretized Stream. It is the group gathering or information of RDDs divided into little clusters. It is also called Apache Spark Discreted Stream and is utilized to gather the RDDs in grouping. DStreams based on Spark RDDs are used to enable streaming to coordinate perfectly with some other Apache Spark segments like Spark SQL and Spark MLlib.
31. How can we restrict information moves while working with Apache Spark?
We can restrict the information moves while working with Apache Spark in the following ways:
- Accumulator Factors
- Communicate
32. How can we invoke automatic cleanups in Spark to handle the accumulated metadata?
In Spark, we can invoke the automatic cleanups by setting the parameter to "Spark.cleaner.ttl" or dividing the long-running jobs into disparate batches and writing the mediator results to disk.
33. What are the primary attributes of SparkConf?
Following is the list of primary attributes used in SparkConf:
- Set(key, value): It sets the configuration property.
- setSparkHome(value): It allows the Spark installation path to be set on the worker nodes.
- setAppName(value): It is used to set the application name.
- get(key, defaultvalue=None): It will support retrieving the configuration of the key.
- setMaster(value): It is used to set the master URL.
34. How can we associate Spark with the Apache Mesos?
We can utilize the below steps for associating Spark with Mesos:
- First, set up the sparkle driver program for associating with the Mesos.
- The Apache Spark paired bundle should be in the area opened by the Mesos.
- After that, install the Apache Spark in the same way as the Apache Mesos and develop the property "spark.mesos.executor.home" for pointing to the area where it is introduced.
35. What do you mean by RDD Lineage?
The RDD Lineage is the procedure that is utilized for reconstructing the lost data partitions. The Spark does not store the data replication in the memory. If the data is lost, we should redevelop it through the RDD lineage. This is the best application since RDD remembers how to build from other datasets.
36. Can we create the PySpark DataFrame from the external data sources?
We can create the PySpark DataFrame from the external data sources. The real-world applications utilize external file systems like HDFS, local, HBase, S3 Azure, etc. The example below displays how to create data frames by reading the data from the CSV file available in the local system.
df = spark.read.csv("/path/to/file.csv") 37. Explain startsWith and endsWith methods in PySpark.
The “startsWith” and “endsWith” methods in PySpark are related to the Column class and are used for searching the DataFrame rows by checking whether the column value starts with one value and ends with another. Both are utilized to filter the data in the applications:
- startsWith() method: This method returns the Boolean value. It displays TRUE when the column's value begins with a particular string and FALSE when match is not satisfied in the column value.
- endsWith() method: It is used for returning the boolean value. It displays TRUE when the column's value finishes with a particular string and FALSE when the match is not satisfied in that column value.
38. What is the purpose of the Spark execution engine?
The execution engine of the Apache Spark is the chart execution that streamlines us in analyzing data sets using high presentation. We have to detain the Spark to catch the performance rapidly if we want the data to be changed with the manifold changes of the processing.
39. What machine learning APIs does PySpark support?
Similar to Apache Spark, PySpark also offers a machine learning API called MLlib. MLlib endorses the following kinds of machine learning APIs:
- mllib.Classification: It supports different methods for multiclass or binary classification or regression analysis, such as decision trees, naive Bayes, random forests, etc.
- mllib.fpm: FPM refers to Frequent Pattern Matching in the Machine Learning API. This machine learning API utilises for mining the frequent items, subsequences, or other structures that are utilized for mining the frequent items, subsequences, or other structures that are used to analyze massive datasets.
- mllib.linalg: This Machine Learning API is utilized for solving the problems on linear algebra.
- mllib.Clustering: This Machine Learning API resolves the clustering problems by grouping the entities' subsets with one another depending on their similarity.
- mllib.recommendation: It is utilized for collaborative filter and recommender systems.
40. What are the different ways to create RDD in PySpark?
Following are the different ways to create RDD in PySpark:
1) By using "sparkContext.parallelize()": The parallelize method of SparkContext can be utilized to create the RDDs. This method loads the available collection from the Driver and parallelizes it. This is the fundamental approach for creating the RDD and is utilized when we have the data already available in memory. This also needs the presence of all the data on Driver before creating the RDD. Code for creating the RDD through the parallelize method for the Python list displayed in the following image:
list = [1,2,3,7,8,11,12,13,14]
rdd=spark.sparkContext.parallelize(list)
2) By using the sparkContext.textFile(): We can read the ".txt" file and transform it into RDD through this method. Syntax:
rdd_text = spark.sparkContext.textFile(“/path/to/textfile.txt”)
3) By using the sparkContext.wholeTextFiles(): This function returns the pair RDD with the file path being the file content, and the key is the value.
rdd_whole_text = spark.sparkContext.wholeTextFiles(“/path/to/textFile.txt”)
4) Empty RDD with no partition by using "sparkContext.emptyRDD": RDD which does not have data is known as empty RDD. We will create such RDDs containing no partitions through the emptyRDD() method, as displayed in the following code:
empty_rdd = Spark.sparkContext.emptyRDD
empty_rdd_string = Spark.sparkContext.emptyRDD[String]
41. Explain Spark Streaming.
PySpark Streaming is fault-tolerant, scalable, and high throughput per the streaming system that endorses streaming and batch loads to support real-world data from data sources like TCP Socket, Kafka, S3, File system folders, Twitter, etc. The processed data will be sent to live dashboards, databases, Kafka, HDFS, etc.
We can utilize readStream to perform the streaming from the TCP socket.format("socket") method of the spark session object to read the TCP socket data and offer the streaming source host and port as options.
PySpark interview questions and Answers for experienced:
42. Tell me a few algorithms which support PySpark.
There few algorithms which we can use in PySpark:
- mllib. classification
- mllib. clustering
- smllib.fpm
- mllib. linalg
- smllib. recommendation
- spark. Mllib
- Mllib. Regression
43. Tell me the different SparkContext parameters.
Please find out the different SparkContext parameters:
- The cluster's master URL from which it connects.
- Our job's name is appName.
- Py files These are the.zip or.py files that need to be sent to the cluster and added to the PYTHIONPATH.
- Variables in the context of worker nodes.
- RDD serializer is a serializer for RDD data.
- Conf is an object of LSparkConf that allows you to set all of the Spark properties.
- JSC is a joint-stock company. It's a JavaSparkContext object.
44. What is RDD? How many types of RDDs are in PySpark?
The complete form of RDD is Resilient Distributed Datasets which are the elements used to run and operate on multiple nodes simultaneously on the same cluster. It can perform parallel processing as they use immutable characteristics. Once developers create an RDD, they can not change it anymore. Once any failure happens, this RDD will be recovered automatically.
There are two types of RDD:
- Transformation: This type of RDD is applicable in creating a new RDD or transforming any filter or map.
- Action: This type of RDD performs some computations on the return values. It sends data from the executor to the driver.
45. Tell me the different cluster manager types in PySpark.
There are many types of the cluster, few of them are:
- Local: It simplifies the running mode for Spark application through API.
- Kubernetes: It helps in automated deployment and data scaling as an open-source cluster.
- Hadoop YARN: This type of cluster manages the Hadoop environment.
- Apache Mesos: In this cluster, we can run Map-reduce.
- Standalone: This cluster can operate the Spark API.
46. What do you understand about PySpark DataFrames?
DataFrames can create Hive tables, structured data files, or RDD in PySpark. As PySpark is based on the rational database, this DataFrames organized data in equivalent tables and placed them in named columns. As a result, it has better optimization to compare the data set.
47. Explain SparkSession in PySpark.
We use usually get entry in PySpark through SparkContext in version 2.0. But from version 3.0, we can get into it by using SparkSession. It acts as the starting point to access all PySpark functionalities like RDD or DataFrames. We can also use this to unified API.
48. What do you know about PySpark UDF?
The complete form of UDF is User Defined Functions. It will be created when no functionalities do not support the PySpark library. Developers can create UDF by using the Python function and wrapping. SQL or DataFrames can reject it.
48. Describe PySpark Architecture.
This architecture is mainly based on mater slave pattern. Here driver means master node, and worker means slave nodes. Worker nodes are the main operational point. The cluster manager can manage the whole operation on the worker nodes.
50. What do you know about the PySpark DAGScheduler?
The complete form of DAG is Direct Acyclic Graph. It controls the scheduling layer of Spark for executing the stage-oriented scheduled tasks. This scheduler executes stages DAG for each job. Developers can keep track of all stages in RDD. Even this DAG scheduler reduces the running time.
51. Which workflow do we need to follow in PySpark?
The typical workflows are:
- We need to create input RDD on the external data. These data can be taken from another source.
- Intermediate RDD needs to be created for later purposes.
- parallel computation is present in this workflow.
52. Tell me how RDD is created in PySpark?
- Apply sparkContext.parallelize(): Method parallelize() of SparkContext is used to create RDD by loading existing collection from the driver and then parallelizing. If the data is present in memory, we can only use this process.
- Apply sparkContext.textFile(): If we are going to read from the text file and transfer them into RDD, we can use this method.
- Apply sparkContext.wholeTextFiles(): The value of the file and file path can find out by using this method.
- Empty RDD with no partition using sparkContext.emptyRDD: one empty RDD can be created by the method.
- Empty RDD with partitions using sparkContext.parallelize: New empty RDD can be created without data in the partition.
53. Can we create a Data frame using an external database?
We can create the data frame locally in HDFC, HBase, MySQL, and any cloud.
| Check Out: Steps To Set-Up Your MySQL Reporting |
54. Explain Add method.

55. What is PySpark SQL?
Spark SQL is a module in Spark for structured data processing. It offers DataFrames and also operates as a distributed SQL query engine. PySpark SQL may also read data from existing Hive installations. Further, data extraction is possible using an SQL query language.
56. Do you think PySpark is similar to SQL?
In SQL database is maintained in tabular form. As well as in PySpark API, all information is stored in Data Frames. This Data Frame is immutable and stored in columns. That's why this is similar to SQL.
57. Why use Akka in PySpark?
Spark makes use of Akka for scheduling primarily. After registration, all workers request a task to complete. The master simply assigns the work. Spark uses Akka to communicate between workers and masters in this case.
58. How is PySpark exposed in Big Data?
The PySpark API is attached with the Spark programming model to Python and Apache Spark. Apache Spark is open-source software, so the most popular Big Data framework can scale up the process in a cluster and make it faster. Big Data use distributed database system in-memory data structures to smoother the processing.
59. What is the Workflow of a Spark Program?
Every Spark program will have a typical workflow. The first step will be creating input RDD as per the external data. Data will come from a wide range of data sources. After making the RDD, as per the business logic, RDD transformation operations like filter() and map() are carried out to create a new RDD. If we have to reuse the mediate RDDs for rapid requirements, we can store them. Lastly, if there are action operations like count(), first, etc, Spark triggers them to begin the parallel computation. The Spark program utilizes this workflow.
60. What are the regularly used Spark environments?
The following are the most regularly used Spark Environments:
- Developers use SparkSQL, which is also called Shark.
- Spark Streaming is used to process the live data streams.
- Machine Learning Algorithms(MLlib)
- Graphx is used to generate and calculate the graphs.
- SparkR is utilized for promoting the R programming language in the Spark engine
61. Describe PySpark Serializers.
In PySpark, we use a serialization process for performing the spark performance tuning. PySpark integrates serializers because we should continuously check the data received or sent throughout the network to the disk or memory. In Pyspark, we have two kinds of serializers:
- PickleSerializer: It will serialize the objects through the PickleSerializer and class PySpark.
- MarshalSerializer: It carries out the object's serialization. It can be utilized in the class.pyspark.MarshalSerailizer. It is more rapid than the PickleSerializer.
62. What is the use of Broadcast Variable in PySpark?
In PySpark, the Broadcast Variable is used to save copies of the massive input dataset in the memory of every worker node in the Spark cluster. It optimizes the effectiveness of the distributed tasks that require access to the common dataset.
63. How do we optimize the PySpark performance?
We can optimize the PySpark performance through lazy evolution and minimizing data shuffling. Performance can also be optimized through proper data structure for the jobs.
64. How do we join two data frames in PySpark?
In PySpark, we can join two data frames through the join() function. It takes two data frames as the input and the join condition.
65. What are the advantages of caching?
Caching will enhance the performance by minimizing the time data required to be read from the disk. Caching can also utilize a lot of memory. Thus, it must be used carefully.
66. What are Window Functions?
A window function is defined as the function that carries out the calculations throughout the rows in the DataFrame. Windows functions can be utilized to calculate cumulative sums, rolling averages, and other kinds of Windows aggregations in PySpark.
67. What is a Pipeline?
In PySpark, a Pipeline is a sequence of data processing stages implemented in a particular order. Pipelines can be utilized for processing the data effectively. It can be maximized to reduce the data movement and optimize the parallelism.
68. Explain PySpark Join.
PySpark will combine two data frames. Encapsulating these can join multiple data frames. It allows you to access all the basic join-kind operations of conventional SQL like Left Outer, Right Outer, Inner, Self Join, and Cross. PySpark joins are the transformations that utilize data shuffling across the network.
69. Differentiate map() and flat map()?
In PySpark, the map() method is used to implement the function for the elements of the RDD or DataFrame. The flat map () method is the same as the map(); however, it can return all the multiple elements for every input element.
70. How does PySpark support real-time data processing?
PySpark endorses real-time data processing using its structured streaming feature, which enables fault-tolerant, high-throughput stream processing of the live data streams.
Most Commonly PySpark FAQs
1. Why do we use PySpark?
Python and its set of libraries in real-time for large-scale data. It can be used through an open-source Apache Spark. Software industries are using this PySpark as Python API.
2. Do you think that PySpark and Python are similar?
Yes, they are directly related. It is a Python-based API that is based on the Spark framework. As a programming language, Python helps Spark manage big data.
3. Can we use PySpark as a programming language?
No, we can not use PySpark as a programming language. It's a computing framework.
4. Which one is the faster, PySpark or Pandas?
The processing speed depends upon the platform we are using to manage the vast amount of data. As PySpark is easy to use through inbuilt API, as a result, speed is faster. However, at the same time, Pandas is not running with any API; as a result, the rate is slower than PySpark.
5. Why is PySpark helpful for machine learning?
As PySpark is working with Machine Learning on a distributed database system so they can work together efficiently. We can use PySpark in extensive data analysis by using ML and Python. It also runs smoothly with Tableau. Moreover, we can run different machine learning algorithms due to the PySpark ML library.
6. What do you think PySpark is important in Data Science?
Data Science is based on two programming languages like Python and ML. PySpark is built into Python. It has the interface and inbuilt environment to use Python and ML both. That's why PySpark is an essential tool in Data Science. Once we process the data set, prototype models will be converted into production-grade workflows.
7. Name a few of the companies that are using PySpark?
Most of the E-commerce industry, Banking Industry, IT Industry, Retail industry, etc., are using PySpark. A few of the companies' names are Trivago, Amazon, Walmart, Runtastic, Sanofi, etc.
8. What are the different MLlib tools available in Spark?
MLlib can perform machine learning in Apache Spark. The different MLlib tools available in Spark are listed below:
- ML Algorithms: The core of MLlib is ML Algorithms. These include common learning algorithms like classification, clustering, regression, and collaborative filtering.
- Featurization: It includes extraction, transformation, selection, and dimensionality reduction.
- Pipelines: Pipelines provide tools to construct, evaluate, and tune ML Pipelines.
- Persistence: It aids in saving and loading models, algorithms, and pipelines.
- Utilities: Utilities for statistics, algebra, and handling data.
| Check out: Machine Learning Tutorial |
9. Explain the function of SparkCore.
SparkCore is the base engine for distributed data processing and large-scale parallel computation. SparkCore performs vital functions like memory management, fault-tolerance, job scheduling and monitoring, and interaction with storage systems. Furthermore, additional libraries built at the top of the core allow diverse SQL and machine learning workloads.
10. List the main attributes used in SparkConf.
Below-listed are the most commonly used attributes of SparkConf:
- set(key, value) - It sets the configuration property.
- setMaster(value) - It sets the master URL.
- setAppName(value) - It sets the application name.
- get(key, defaultValue=None) - It gets the configuration value of a key.
- setSparkHome(value)
11. What is the latest version of PySpark?
The latest version of PySpark is 3.5.1, and it was released on Feb 26, 2004.
What are the roles and responsibilities of a PySpark Developer with 3-5 years of experience?
- Design, Build, and Unit test applications on the Spark Framework and Python
- Develop and Execute the data pipeline testing process and authenticate the business policies and rules
- Processing massive amounts of structured and unstructured data and integrating data from multiple sources.
- Performing code release and production deployment.
- Optimizing the performance of spark applications in Hadoop
12. What are the roles and responsibilities of a PySpark Developer with more than five years of experience?
- Developing APIs and Microservices using Python
- Architecting Data Pipelines and Automating Data Ingestion
- Experience with Data Ingestion and Gathering
- Handing Streaming Data and Messages
13. What are the new features of PySpark?
Following are the latest enhancements of PySpark:
- Spark endorses more scenarios with the general availability of Scala client, endorsement for distributed interference and training, parity of the Pandas API on the Spark and enhanced compatibility for the structured streaming.
- Arrow-Optimized Python UDFs: The Python UDFs will utilize the columnar format to enhance performance using Spark.sql.execution.pythonUDF.arrow.enabled configuration is set to TRUE, or the “use arrow” is set to “TRUE” through the UDF decorator. Through this optimization, Python UDFs can perform two times more quickly than the canned Python UDFs on advanced CPU architectures because of the vectorized I/O.
- In-Built SQL Functions to manipulate the arrays: Apache Spark offers new built-in functions to assist users in controlling the array values.
- Testing API: Apache Spark 3.5 inducts the new data frame equality test utility functions like details and colour-coded test error messages, which indicate differences between the DataFrame schemas and data within the DataFrames.
14. What are the secondary skills required for a PySpark Developer?
A PySpark Developer requires knowledge of SQL, Python, Spark, and Cloud platforms like AWS, Azure, and GCP.
Conclusion
Enhance your technical skill on PySpark as popularity has risen in recent years, and many businesses are capitalizing on its benefits by creating a plethora of job possibilities for PySpark Developers. We are confident that this blog will surely assist you in better understanding of PySpark and help you qualify for the job Interview.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| PySpark Training | Jul 28 to Aug 12 | View Details |
| PySpark Training | Aug 01 to Aug 16 | View Details |
| PySpark Training | Aug 04 to Aug 19 | View Details |
| PySpark Training | Aug 08 to Aug 23 | View Details |















