
- Django Interview Questions
- Python Array Examples
- Python enum
- Python Enumerate with Example
- Python Flask Tutorial For Beginners
- Python For Beginners - Way To Success
- Python For Data Science Tutorial For Beginners
- Python for loop
- Python GET and POST Requests
- Python IDEs for Python Programmers
- Python Interview Questions
- Python Lists with Examples
- Python Partial Function Using Functools
- Python Print
- How to generate random numbers in python
- Python Regular Expression (RegEx) Cheatsheet
- Python Sleep Method
- Python List Methods
- Python Split Method with Example
- Python String Functions
- Python Tutorial
- Python Variable Types
- Python vs Java
- Python vs SAS vs R
- Python Operators
- Code Introspection in Python
- Comprehensions in Python
- Python Exception Handling
- Defining Functions - Python
- Generators & Iterators in python
- Install Python on Windows and Linux
- Introduction to Python Programming
- Lists concepts in Python
- Loops in Python
- Regular Expression Operations in Python
- Python Serialization
- String Formatting - Python
- R vs Python: Which is better R or Python?
- Six Digit Salary With Python
- Top 20 Python Frameworks List
- Why Learn Python
- Python Substring
- OOPs Interview Questions
- Career Shift To Python : Success Guaranteed
- Face Recognition with Python
- Go vs Python
- Pyspark Interview Questions
- OpenCV Interview Questions
- Python Project Ideas
- Flask Interview Questions and Answers
- Array Interview Questions
- What is PyCharm?
- What is Seaborn in Python?
- What is Anaconda Navigator
- Numpy Broadcasting - Detailed Explanation
- Python Data Science Interview Questions
- Genpact Interview Questions
- Python Developer Job Description
- Pandas Projects and Use Cases
- DataFrame Tutorial
- How to install Python on Windows
- Pyspark DataFrame
Pandas is a popular Python software toolkit for performing high-level data analysis and manipulating the data. Pandas provide data structures and other advanced tools to run complicated data applications, allowing analysts and data engineers to alter time series characteristics, tables, and other factors. The Pandas interview questions revolve around the tool's features, data structures, and functions in Python interviews.
Pandas is a popular Python data munging tool. This data analysis package can handle a wide range of data types. We've compiled a list of the most important Panda Interview Questions and Answers in this article.
Panda Interview Questions and Answers 2024 (Updated) weblog had been created into the following stages; they are:
Commonly Asked Pandas Interview Questions
- What is the basic use of pandas?
- Is Panda a module or library?
- What is the full form of pandas?
- What type of inputs are accepted by pandas?
- Which are the data structures available with Pandas?
Basic Pandas Interview Questions and Answers
1. Define Python Pandas?
Ans: Pandas refer to a data analysis and manipulation software library built specifically for Python. Wes McKinney designed Pandas, an open-source, cross-platform library. It was first released in 2008, and it included data structures and procedures for manipulating numerical and time-series data. Pandas can be installed with the pip package manager or the Anaconda distribution. Pandas make doing machine learning algorithms on tabular data a breeze.
| If you would like to Enrich your career with a Python certified professional, then visit Mindmajix - A Global online training platform: “Python Online Training” Course. This course will help you to achieve excellence in this domain. |
2. Mention different types of Data Structures in Panda?
Ans: Series and DataFrames are the two types of data structures that the Pandas library supports. Numpy serves as the foundation for both data structures. A DataFrame is a two-dimensional data structure in Pandas, while a Series is a one-dimensional data structure. A panel, a three-dimensional data structure that includes items, a major axis, and a minor axis, is another axis label.

3. What is Python Panda used for?
Ans: Pandas is a data manipulation and analysis software library for the Python programming language. It includes data structures and methods for manipulating numerical tables and time series, in particular. Pandas is open-source software licensed under the BSD three-clause license.
| Also Read Related Article: Python Tutorial |
4. List out the key features of Panda Library?
Ans: The pandas library has a number of features, some of which are shown here.
- Memory Efficient
- Time Series
- Reshaping
- Data Alignment
- Merge and join
5. Give a brief description about time series in Panda?
Ans: A time series is an organized collection of data that depicts the evolution of a quantity through time. Pandas have a wide range of capabilities and tools for working with time-series data in all fields.
Supported by pandas:
- Analyzing time-series data from a variety of sources and formats
- Create time and date sequences with preset frequencies.
- Date and time manipulation and conversion with timezone information
- A time series is resampled or converted to a specific frequency.
- Calculating dates and times using absolute or relative time increments is one way to
6. Explain how to create and copy a series in Pandas?
Ans: To copy the series in pandas:
pandas. series.copy
series.copy (deep=True)
pandas. series. copy. Make a significant copy of everything, including the data and indices. Deep=False copies of neither the indices nor the data. When deep = True, data is transferred, only the connection to the object is emulated recursively, not the actual Python objects.

7. Characterize the Data Frames in Pandas?
Ans: A DataFrame is a panda-specific lewis structure that functions with a two-dimensional display with tomahawks (rows and columns). A DataFrame is a typical way of storing data that has two separate indices, namely a row index and a column index. It includes the following characteristics:
Columns such as int and bool are heterogeneous.
It's commonly thought of as a term reference for a series structure that includes both rows and columns. If there are columns, it is denoted as "columns," and if there are lines, it is denoted as "index."
Syntax: import pandas as pd
df=pd.Dataframe()
8. Explain how to create a series from dict in Pandas?
Ans: A Series is a one-dimensional designated array that can hold any form of data (python objects, strings, integers, floating-point numbers, etc.). It's important to understand that, unlike Python lists, a series always contains the same type of data.
Let's look at how to make a Panda Series using the Dictionary.
The Series () method is used without the index parameter.
9. Explain about the operation on Series in Pandas?
Ans: The Pandas Series is a one-dimensional classified array that may hold any type of data (python objects, strings, integers, floating-point numbers, etc.). The axis identifiers are referred to as an index. The Pandas Series is merely a column in an excel spreadsheet.
Putting Together a Pandas Series-
A Pandas Series is built in the real world by loading datasets from existing storage, which can be a SQL database, a CSV file, or an Excel file. Pandas Series can be made from lists, dictionaries, and other things. A series can be developed in a number of ways; here are a few examples: cheval cheval cheval cheval cheval cheval cheval cheval cheval cheval cheval cheval cheval cheval cheval cheval cheval
Creating a series from an array: To construct a series from an array, we must first load a NumPy module and then use its array() functions.
# import pandas as pd
import pandas as pd
# import numpy as np
import numpy as np
# simple array
data = np.array([‘M’,’I’,’N’,’D’,’M’,’A’,’J’,’I’,’X’])
ser = pd.Series(data)
print(ser)
Output: MINDMAJIX
| Read Also: Array Example in Python |
10. Explain different ways of creating Data Frames in Panda?
Ans: A data frame can be created in 3 different ways:
By making use of lists:
d = [[‘a’, 2], [‘b’, 3], [‘c’, 4]]
Creating the Pandas Dataframe:
df = pd.DataFrame (d, columns = [‘Strings’, ‘Integer’])
print(df)
By making use of a dictionary of lists:
All of the arrays in a data frame made from a list's dictionaries must be the same length. If the list is passed, the running time of the list will match the running time of the shows. If no document is specified, the items will be a range (n), where n is the array length, as is conventional.
By using arrays:
import pandas as pd
d = {‘Name’:[‘XYZ, ‘ABC’, ‘DEFC’, ‘ASWE’], ‘marks’:[85, 80, 75, 70]}
df = pd.DataFrame(d, index =[‘first’, ‘second’, ‘third’, ‘fourth’])
print(df)
11. Explain how to create empty DataFrames in Panda?
Ans: To make a Pandas data frame that is fully empty, perform the following:
import pandas as pd
MyEmptydf ()= pd.DataFrame
This will result in a data frame that has no columns or rows.
We do the following to construct an empty dataframe with three empty columns (columns A, B, and C):
df= pd.DataFrame(columns=['A', 'B', 'C'])
12. How will you add a column to the Existing Data Frames in Panda?
Ans: Import pandas as a package, import pandas as pd
# Define a dictionary containing employee data.
Employee ={ ‘Emp_name’:{‘Name’: [‘Ravi’, ‘Roshan', ‘Vinod’, ‘Sailu’],
‘ Emp_id’: [123, 234, 145, 125],
‘Emp_qualification’= [‘Msc’, ‘BA’, ‘MBA’, ‘Msc’]}
# Convert the dictionary into DataFrame
df = pd.DataFrame(Employee)
# Declare a list that is to be converted into a column
Emp_address = [‘Hyderabad’, ‘Delhi’, ‘Lucknow’, ‘Vijayawada’]
# Using ‘Address’ as the column name
# and equating it to the list
df[‘Address’] = Emp_address
# Observe the result
df
Output:
| Emp_name | Emp_id | Emp_qualification | Emp_address | |
| 0 | Ravi | 123 | MSC | Hyderabad |
| 1 | Roshan | 234 | BA | Delhi |
| 2 | Vinod | 145 | MBA | Lucknow |
| 3 | Sailu | 125 | MSC | Vijayawada |
13. Tell us now how to retrieve a single column from a Panda Dataframe?
Ans: Use the query $django-admin.py to start a Django project, and then use the following queries:
Project
_init_.py
manage.py
settings.py
urls.py
14. Explain about Categorical Data in Pandas?
Ans: Categorical is a data type in Pandas that corresponds to categorical variables in statistics. A categorical variable has a limited and usually fixed, set of possible values (categories; levels in R). Gender, social class, blood type, national affiliation, observation time, or rating using Likert scales are some examples. All categorical data values are either in categories or np. nan.
In the following situations, categorical data is useful:
A string parameter with a small number of distinct values. Transforming a string parameter to a category variable can help you save memory.
A variable's lexical order differs from its analytical order ("one," "two," and "three"). Indexing and min/max will utilize the analytical order rather than the lexical order after transforming to a categorical and providing order on the categories.
To indicate to other Python libraries that this column is a categorical variable (so that appropriate statistical technique or plot types can be used).
15. Explain about Multi Indexing in pandas?
Ans: Multiple indexing is classified as fundamental indexing because it simplifies information inspection and control, especially when dealing with higher-dimensional data. It also allows us to store and handle data in lower-dimensional data structures like series and dataframes with an unlimited number of measurements.
Advanced Pandas Interview Questions and Answers
16. Explain about Pandas index?
Ans: Indexing in Pandas is the process of extracting specific rows and columns of data from a DataFrame. Indexing could simply be selecting all of the rows and some of the columns, or part of the rows and all of the columns, along with some of each row and column. Indexing is often referred to as subset selection.
Pandas Indexing with [],.loc[],.iloc[], and.ix []
There are numerous methods for obtaining the objects, elements, items, rows, and columns from a data frame. In Pandas, some indexing methods can be used to retrieve an object/element/item from a data frame. These indexing systems look to be extremely similar. However, they perform significantly differently. The Pandas support four methods of multi-axis indexing, which are as follows:
- Dataframe. []: This method is also known as the indexing operator.
- Dataframe. loc []: This method is used for labels.
- Dataframe.iloc[] : This method is utilized for integer or position based
- Dataframe. ix[]: This function is utilized for both integer and label based
They are referred to collectively as indexers. All of those are, by far, the most popular methods of indexing data. These four functions assist in retrieving the object/elements/items, rows, and columns from a DataFrame.
| Also Read: Python Partial Function Using Functools |
17. Explain about Reindexing in Pandas?
Ans: The DataFrame is reindexed to adhere to a new index with configurable filling logic. It inserts NA/NaN in the areas where the elements are missing from the previous index. Unless the new index is constructed as equivalent to the present one, in which case the copy value becomes false. It is used to modify the index of the dataframe's rows and columns.
18. Can you explain multi-indexing columns in Pandas?
Ans: Because it involves data manipulation and analysis, multiple indexing is characterized as vital indexing. This is certainly relevant when operating with hyperdimensional data. It also allows us to store and modify data in lower-dimensional data structures like DataFrame and series with an indefinite number of dimensions.
Multiple Index Columns
Two columns will be used as index columns in this case. The drop option is used to remove a column, whereas the append attribute is used to append given columns to an index column that already exists.
Example:
# importing pandas library from
# python
import pandas as pd
# Creating data
Information = {'name': ["Saikat", "Shrestha", "Sandi", "Abinash"],
'Jobs': ["Software Developer", "System Engineer",
"Footballer", "Singer"],
'Annual Salary(L.P.A)': [12.4, 5.6, 9.3, 10]}
# Data Framing the whole data
df = pd.DataFrame(dict)
# Showing the above data
print(df)
Output:
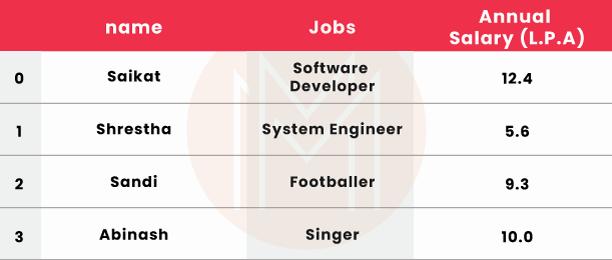
19. What is meant by set the index in Pandas?
Ans: Python is an excellent language for analyzing data, particularly with its vast ecological community of data-driven Python packages. Pandas is another of those packages, and it makes data import and analysis considerably easier.
Pandas set_index () is a function for modifiying the index of a data frame from a data frame, series, or list. The index column can also be set while creating a data frame. However, because a data frame might be made up of two or more data frames, the index can be altered later using this method.
Syntax:
DataFrame.set_index(keys, drop=True, append=False,
inplace=False, verify_integrity=False
Parameters:
keys: The name of the column or a list of column names.
If True, drop is a Boolean value that removes the index column.
If True, the column is appended to the existing index column.
Inplace, If True, the changes are made in the data frame.
If True, verify_integrity will check the new index column for duplicates.
Example:
# importing pandas library
import pandas as pd
# creating and initializing a nested list
students = [['jack', 34, 'Sydeny', 'Australia',85.96],
['Riti', 30, 'Delhi', 'India',95.20],
['Vansh', 31, 'Delhi', 'India',85.25],
['Nanyu', 32, 'Tokyo', 'Japan',74.21],
['Maychan', 16, 'New York', 'US',99.63],
['Mike', 17, 'las vegas', 'US',47.28]]
# Create a DataFrame object
df = pd.DataFrame(students,
columns=['Name', 'Age', 'City', 'Country','Agg_Marks'],
index=['a', 'b', 'c', 'd', 'e', 'f'])
# here we set Float column 'Agg_Marks' as index of data frame
# using dataframe.set_index() function
df = df.set_index('Agg_Marks')
# Displaying the Data frame
df
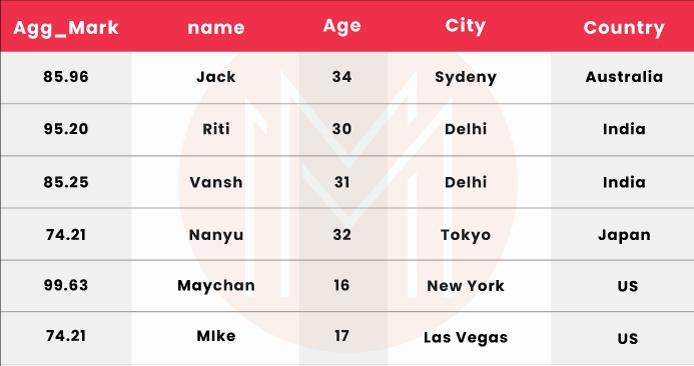
20. Explain how to reset the index in pandas?
Ans: Pandas is a one-dimensional ndarray with identifiers on the axes. The identifiers do not have to be distinct, but they must be of the hashable type. The entity allows both label-based and integer indexing, as well as a set of techniques for handling the index.
The pandas function series.reset_index () creates a reinvigorated series or data frame with the index reset. This is useful when an index must be utilized as a column.
Syntax:
reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill='')
Parameters:
level: int, str, tuple, or list None(default)
Only the specified levels should be removed from the index. By default, all levels are removed.
drop: default False, bool
Inserting indexes into data frame columns is not recommended. This returns the index to its original integer value.
inplace: False by default bool
Modify the existing DataFrame (do not create a new object).
col_level: default 0 for int and str
This determines the level the labels are inserted into if the columns have several levels. It is inserted into the first level by default.
col_fill: default object
Evaluate how the other levels are named if the columns have different levels. If there is no value, the index name is replicated.
# Import pandas package
import pandas as pd
# Define a dictionary containing employee data
data = {'Name':['Jai', 'Kanth', 'Vinod, 'Seeraj', 'Kokila'],
'Age':[27, 26, 23, 30, 25],
'Address':['Delhi', 'Gujart', 'Hyderabad', 'Vizag', 'Noida'],
'Qualification':['MCA', 'Ms', ‘BA’, 'Phd', 'MS'] }
index = {'a', 'b', 'c', 'd', 'e'}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data, index)
# Make Own Index as index
# In this case default index is exist
df.reset_index(inplace = True)
df
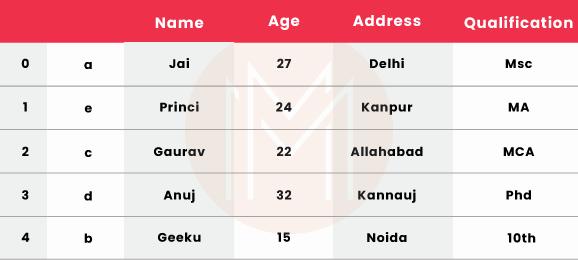
21. Explain about Data operations in Pandas?
Ans: There are several useful data operations for DataFrame in Pandas, which are as follows:
-> Row and column selection:
We can retrieve any row and column of the DataFrame by specifying the names of the rows and columns. It is one-dimensional and is regarded as a Series when you select it from the DataFrame.
-> Filter Data:
By using some of the boolean logic in DataFrame, you may filter the data.
-> Null values:
When no data is being sent to the items, a Null value can appear. There may be no values in the respective columns, which are commonly represented as NaN. Pandas provide several useful functions for identifying, deleting, and changing null values in Data Frames. The following are the functions:
- isnull(): isnull 's job is to return true if either of the rows have null values.
- notnull(): It is the inverse of the isnull() function, returning true values for non-null values.
- dropna(): This function evaluates and removes null values from rows and columns.
- fillna(): It enables users to substitute other values for the NaN values.
- replace(): It's a powerful function that can take the role of a regex, dictionary, string, series, and more.
- interpolate(): It's a useful function for filling null values in a series or data frame.
-> String Operation:
Pandas provide a set of string functions for working with string data while ignoring missing/NaN values. The .str. option can be used to conduct various string operations. The following are the functions:
- lower(): Any strings in the index or series are converted to lowercase letters.
- upper(): Any strings in the index or series are converted to uppercase letters.
- strip(): This method eliminates spacing from every string in the Series/index, along with a new line.
- split(' '): It's a method that separates a string according to a pattern.
- cat(sep=' '): With a defined separator, it concatenates series/index items.
- contains(pattern): If a substring is available in the current element, it returns True; otherwise, it returns False.
- replace(a,b): It substitutes the value b for the value a.
- repeat(value): Each element is repeated a defined multiple times.
- count(pattern): It returns the number of times a pattern appears in each element.
- startswith(pattern): If all of the components in the series begin with a pattern, it returns True.
- endswith(pattern): If all of the components in the series terminate in a pattern, it returns True.
- find(pattern): It can be used to return the pattern's first occurrence.
- findall(pattern): It gives you a list of all the times the pattern appears.
- swapcase: It is used to switch the lower/upper case.
- islower(): If all of the characters in the Series/Index string are lowercase, it returns True. Otherwise, False is returned.
- isupper(): If all of the characters in the Series/Index string are uppercase, it returns True. Otherwise, False is returned.
- isnumeric(): If all of the characters in the Series/Index string are numeric, it returns True. Otherwise, False is returned.
-> Count Values:
Using the 'value counts()' option, this process is used to count the overall possible combinations.
22. How Can A Dataframe Be Converted To An Excel File?
Ans: Using the to excel () function, we can export the data frame to an excel file. We must mention the target file name to write a single object to an excel file. If we wish to write to many sheets, we must build an ExcelWriter object with the target filename and the sheet in the file that we want to write to.
Visit here to learn Python Training in Bangalore
23. How To Format The Data in Your Pandas DataFrame?
Ans: Almost all of the time, you'll want to be ready to execute operations on the absolute measurements in your data frame.
Replacing All String Occurrences in a DataFrame:
The Replace() method can be used to easily replace specific strings in your data frame. Simply pass the values you are trying to enhance, accompanied by the values you would like to substitute them with.
It's worth noting that there's a regex argument that can come in handy when dealing with unusual string combinations. In a nutshell, replace() method is used when you wish to substitute values or strings in your DataFrame with those from elsewhere.
Removing Parts From Strings in the Cells of Your DataFrame:
Removing unnecessary strings is a time-consuming task. Fortunately, there is a remedy! You apply the lambda function to each element or element-by-element of the column using map() on the column result. The function takes the string value and removes the + or — on the left, as well as any of the six aAbBcC on the right.
Splitting Text in a Column into Multiple Rows in a DataFrame:
It's difficult to divide your text into many rows.
Applying A Function to Your Pandas DataFrame’s Columns or Rows:
You might want to use a function to alter the information in the DataFrame. The code pieces illustrate how to implement a method to a DataFrame.
24. Explain about Data Aggregation in Pandas?
Ans: To implement any aggregation method across one or more columns, use the Dataframe. aggregate() method. Use strings, callables, dictionaries, or a collection of strings to aggregate. The following are the most common aggregations:
- Sum: This method returns the sum of the values for the requested column.
- Min: This method returns the minimum value for the requested column.
- Max: This method returns the maximum value for the requested column.
Syntax: DataFrame.aggregate(func, axis=0, *args, **kwargs)
function: string, callable, list, or dictionary of callables. Use this function to aggregate the data. If a function is handed a data frame, it must either work or be allowed to pass to the data frame. apply. If the variables are DataFrame column names, you can give a dict to a DataFrame.
the axis (default 0) 1 or 'columns', 0 or 'index' Apply the method to each column with a 0 or index. 1 or 'columns': for each row, apply the function.
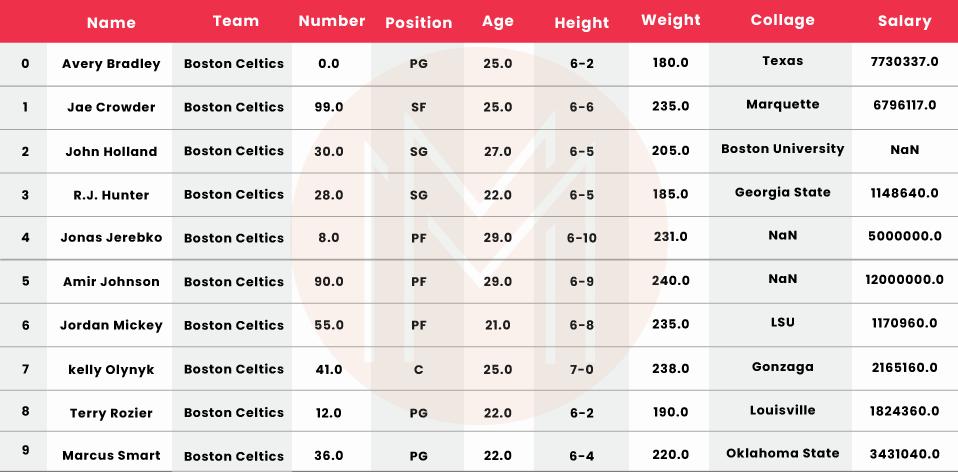
Let us see an example for data aggregation:
# importing pandas package
import pandas as pd
# making data frame from csv file
df = pd.read_csv("nba.csv")
# printing the first 10 rows of the dataframe
df[:10]
| Explore Python Sample Resumes! Download & Edit, Get Noticed by Top Employers! |
25. What is the use of GroupBy Pandas?
Ans: The data is divided into groups using GroupBy. It organizes the data according to certain parameters. Labels are mapped to group names when using grouping. It has a lot of different versions that can be made using the parameters, and it makes separating data a breeze.
Syntax: DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs)
26. What is Pandas Numpy?
Ans: Pandas Numpy is an open-source Python package that would be used to work with a huge number of datasets. It includes a robust N-dimensional array object as well as complicated mathematical algorithms for data processing with Python.
Fourier transformations, linear programming, and pseudo-random capabilities are among the prominent features provided by Numpy. It also includes integrated tools for C/C++ and Fortran programming.
27. What is Vectorization in Python pandas?
Ans: The procedure of executing operations on the full array is known as vectorization. This is intended to limit the number of iterations that the methods do. Pandas have a series of vectorized methods, such as string functions and aggregations, that are optimized for use with series and dataframes. As a result, it is preferable to use vectorized pandas methods to perform the tasks quickly.
28. How will you combine different Data Frames in Panda?
Ans: Following are the ways to combine different Data Frames in panda:
-> append() method: This is used to horizontally stack the dataframes.
Syntax: df1.append(df2)
-> concat() method: This is used to sequentially stack data frames. This works best because the data frames have the same fields and columns.
Syntax: pd.concat([df1, df2])
-> join() method: This is used to extract data from different dataframes that have one or more common columns.
Syntax: df1.join(df2)
29. How can you iterate over the Data frame in Pandas?
Ans: Iterating over a DataFrame in pandas for loop can be merged with an iterrows () call.
| Read Related Article: Python for loop |
30. What Method Will You Use To Rename The Index Or Columns Of Pandas Dataframe?
Ans: The .rename method is used to rename DataFrame index values or columns.
Frequently Asked Pandas Interview Questions
1. What is the basic use of pandas?
Ans: Pandas is a popular open-source Python library used for analyzing the data, Machine learning and data science.
2. Is Panda a module or library?
Ans: Pandas is a programming interface for Python. It offers ready-to-use high-performance data analysis tools and data structures. Pandas is a Python package for analyzing the data and data science that runs on top of NumPy.
3. What is the full form of pandas?
Ans: The acronym for "Python Data Analysis Library" is "Python Data Analysis Library." The phrase comes from the multiple linear regression term "panel data," which applies to dimensional discrete classes "Pandas," according to the Wikipedia article. However, I feel it is a catchy moniker for a fantastic Python package!
4. What type of inputs are accepted by pandas?
Ans: Like Series, DataFrame accepts many different kinds of input:
- Dict of 1D ndarrays, lists, dicts, or Series.
- 2-D numpy. ndarray.
- Structured or recorded ndarray.
- A Series.
- Another DataFrame.
5. Which are the data structures available with Pandas?
Ans: Series and Data Frames are the two basic types of data structures supported by Pandas. Series is a one-dimensional data structure, whereas DataFrames are two-dimensional data structures.
Conclusion
Since we've gone over all of the most significant Panda Interview Questions and Answers, it's crucial to remember that we should constantly remember these concepts when coding. The Pandas questions represent fundamental data science operations such as importing, cleaning, and manipulating data. If you've got any queries, please do comment below.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Python Training | Jul 25 to Aug 09 | View Details |
| Python Training | Jul 28 to Aug 12 | View Details |
| Python Training | Aug 01 to Aug 16 | View Details |
| Python Training | Aug 04 to Aug 19 | View Details |

Madhuri is a Senior Content Creator at MindMajix. She has written about a range of different topics on various technologies, which include, Splunk, Tensorflow, Selenium, and CEH. She spends most of her time researching on technology, and startups. Connect with her via LinkedIn and Twitter .














