
- Django Interview Questions
- Python Array Examples
- Python enum
- Python Enumerate with Example
- Python Flask Tutorial For Beginners
- Python For Beginners - Way To Success
- Python For Data Science Tutorial For Beginners
- Python for loop
- Python GET and POST Requests
- Python IDEs for Python Programmers
- Python Interview Questions
- Python Lists with Examples
- Python Partial Function Using Functools
- Python Print
- How to generate random numbers in python
- Python Regular Expression (RegEx) Cheatsheet
- Python Sleep Method
- Python List Methods
- Python Split Method with Example
- Python String Functions
- Python Tutorial
- Python Variable Types
- Python vs Java
- Python vs SAS vs R
- Python Operators
- Code Introspection in Python
- Comprehensions in Python
- Python Exception Handling
- Defining Functions - Python
- Generators & Iterators in python
- Install Python on Windows and Linux
- Introduction to Python Programming
- Lists concepts in Python
- Loops in Python
- Regular Expression Operations in Python
- Python Serialization
- String Formatting - Python
- R vs Python: Which is better R or Python?
- Six Digit Salary With Python
- Top 20 Python Frameworks List
- Why Learn Python
- Python Substring
- OOPs Interview Questions
- Career Shift To Python : Success Guaranteed
- Face Recognition with Python
- Go vs Python
- Pyspark Interview Questions
- Python Pandas Interview Questions
- Python Project Ideas
- Flask Interview Questions and Answers
- Array Interview Questions
- What is PyCharm?
- What is Seaborn in Python?
- What is Anaconda Navigator
- Numpy Broadcasting - Detailed Explanation
- Python Data Science Interview Questions
- Genpact Interview Questions
- Python Developer Job Description
- Pandas Projects and Use Cases
- DataFrame Tutorial
- How to install Python on Windows
- Pyspark DataFrame
OpenCV is a BCD licensed open-source computer vision module that analyzes and processes all videos and pictures. Many computer vision algorithms are included in this open-source library. By analyzing photos and videos, it is capable of recognizing handwriting, objects, and faces.
Those who are interested in artificial intelligence and Machine Learning may want to consider a career in computer vision. It's a new field with less competition, but it promises a bright future. Companies such as Google Cloud platform, Volvo, BMW, Tesla, Amazon Cloud, and a slew of other AI tech industry giants that are developing self-driving cars and algorithms based on AI require knowledgeable people. Here are the top OpenCV interview questions and answers that can help you develop a better understanding of the OpenCV concepts while also making a positive impression on your interviews.
Our team categorized the OpenCV Interview Questions and Answers as follows:
Frequently Asked OpenCV Interview Questions and Answers
- What is meant by Computer Vision?
- What are the features of OpenCV?
- What are the applications of OpenCV with Python?
- Define Digital Image in OpenCV?
- How to store the images in OpenCV?
- How to write the images in OpenCV?
- How to display the image using JavaFx?
- How to display the image using AWT/Swing?
- Explain about Dilation in OpenCV?
- Explain about Erosion in OpenCV?
OpenCV Interview Questions and Answers for Frehsers:
1. What is meant by OpenCV?
OpenCV is an open-source computer vision, image processing, and machine learning toolkit. OpenCV supports Python, C++, Java, and other application programming interfaces. It can analyze photos and movies to recognise items, even human word recognition and face recognition. When it's combined with other packages, like Numpy, a highly optimised package for mathematical operations, the number of items in your inventory grows, as any operation that Numpy can do may be merged with OpenCV.
2. What is meant by Computer Vision?
Computer vision is a process that discusses how to rebuild, analyze, and interpret a three-dimensional image from its two-dimensional images to define the scope inherent in the scene. It is concerned with employing computer hardware and software to model and replicate human vision.
Computer Vision has a lot of overlap with the following fields:
- Image processing is concerned with the alteration of images.
- Pattern Recognition demonstrates how to classify patterns using different strategies.
- Photogrammetry is the process of extracting precise measurements from photographs.
| Want to enhance your skills in dealing with the world's best Programming & Frameworks Courses , enroll in our Python Training Online |
3. Tell us the advantages of OpenCV?
Following are the advantages of OpenCV:
- Speed: Because OpenCV is a collection of methods written in C/C++, it will provide machine language directly to the computer. When it comes to execution time, OpenCV is lightning quick. There are at least 30 frames per second in this, which aids with real-time detection.
- Memory: OpenCV only requires a small amount of memory to save its programs. The software can be saved to run in real-time with over 70MB of RAM.
- Cost: OpenCV is distributed under the BCD license, which means you won't have to pay anything. It is completely free to use.
- Portability: OpenCV is fairly portable and runs well on macOS, Linux and Windows. It can also be run on any gadget that can run C.
4. What are the limitations of OpenCV?
Following are the limitations of OpenCV:
- Development Environment: OpenCV does not require any special development environment. Instead, based on the operating platform you're using, you'll need to use a C programming IDE. For example, the NetBeans IDE has been used on Windows, while Eclipse is used on Linux.
- Easy of Use: In comparison to MATLAB, OpenCV is not more user-friendly.
- Memory management: We've established that OpenCV is written in C. As a result, each time you create a memory block, you must relinquish it. It is incapable of locating and releasing the memory in the process.
5. What are the features of OpenCV?
Following are the essential features of OpenCV:
Open-Source:
- The package is open-source, which indicates the source code is available to the public.
- We can adapt the code to replicate according to the customers ’ requirements.
- We can even add more functionality by writing more code.
- It can be used in commercial items for free.
Easy to Integrate:
- The OpenCV Python package uses Numpy, a highly effective package for performing mathematical operations on multidimensional data.
- As a result, all OpenCV array-like frameworks are transformed into NumPy arrays, making it easier to interface with other NumPy-based packages like SciPy and Matplotlib.
- More than 2500 algorithms are implemented in OpenCV. It also includes interfaces for a variety of languages, including Python, Java, and others, making it simple to integrate.
Fast-Prototyping:
- Python makes prototyping applications quick.
- We can use web frameworks like Django to integrate our application. Django is a high-level programming language that supports quick development.
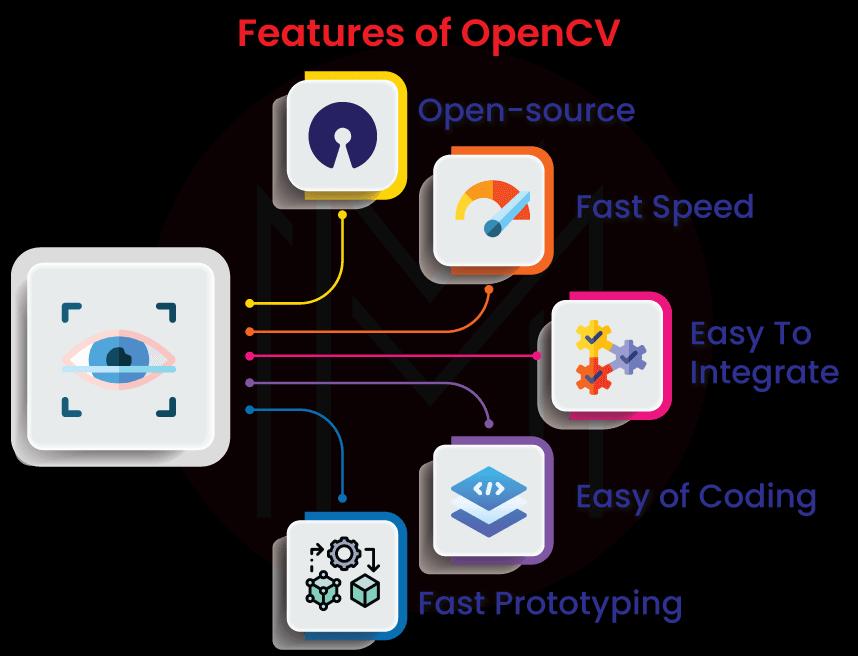
Easy of Coding:
- Python has a large number of packages that make it a great tool for performing scientific calculations.
- Complex jobs in Python were made easier with packages like matplotlib, SciPy, sci-kit-learn, and NumPy.
Fast Speed:
- The OpenCV packages are quick and effective because they were created in C/C++.
- Even though Python is slower than C++, it is easily expanded with C/C++, allowing us to develop computationally heavy code in C++.
- Making Python wrappers that can be used as Python modules is simple.
- Because the original code in the backend is written in C++, the application will run as quickly as in C++.

6. What are the OpenCV Library modules?
Here in this blog we are going to discuss a few essential OpenCV libraries/packages.
- Core Functionality: This module introduces the essential data structures used in OpenCV applications, such as Scalar, Point, and Range. It also contains the multidimensional matrix Mat, that will be used to capture the pictures, in addition to these. This module is offered as a package in the OpenCV Java library.
- Video: The fundamentals of object tracking, background subtraction, and motion estimation are covered in this module. This module is offered as a package in the OpenCV Java library.
- calib3d: Basic multiple-view geometric methods, solitary and stereo object pose estimation, camera calibration, stereo correspondence, and aspects of 3D reconstruction are all covered in this topic. This module is offered as a package in the OpenCV Java library.
- Objdetect: Objects and instances of preset classes, such as eyes, people, faces, mugs, cars, and so on, are detected in this module. This module is offered as a package in the OpenCV Java library.
- Image Processing: Image filtering, histograms, geometrical image modifications, color space transformations, and other image processing processes are covered in this module. This module is offered as a package in the OpenCV Java library.
- Video I/O: The OpenCV library is used to demonstrate video codecs and video capturing in this section. This module is offered as a package in the OpenCV Java library.
- features2d: The fundamentals of object recognition and description are covered in this module. This module is offered as a package in the OpenCV Java library.
- Highgui: This is a user-friendly interface with basic UI features. The functionalities of this module are divided into two packages in the OpenCV Java library.
7. What are the applications of Computer Vision?
Following are the few applications of Computer Vision:
-
Machine Vision: Machine vision has been utilized by businesses to improve efficiency, operations, and quality in a variety of ways. Cameras, lights, and sensors all work together to ensure that machine vision systems function effectively. Metal halide, LEDs, fluorescents, and quartz halogen are all popular illumination options for machine vision systems.
Machine vision methods are usually utilized for quality assurance. Harvesting machines, for example, use it to identify where grapes are on a vine so that the equipment may pick bunches of grapes without damaging them.
-
Transportation: Computer Vision is important in the automobile sector since it is used in transportation systems (ITS). Computer Vision is used in both self-driving cars and pedestrian motion detectors.
Cars can use Computer Vision to collect data about their environment, evaluate it, and respond appropriately. Computer Vision makes driving safer, more effective, and dependable by allowing people to operate autonomous cars (AVs).
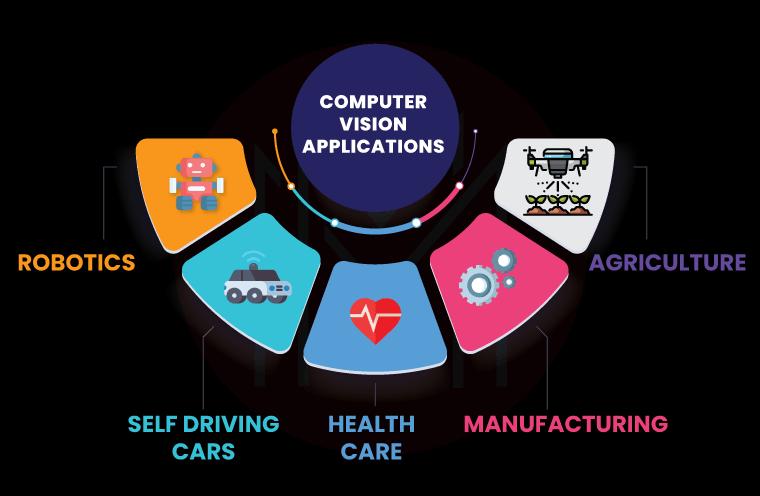
- Health Care: Computer Vision is used in health care to enhance the quality of care and aid surgery. The following are some of the primary advantages of employing computer vision in a healthcare context:
- Medical diagnosis optimization
- Preventing hemorrhage in pregnant women
- This allows doctors to spend much more time with patients at the bedside.
- Detecting severe issues in CT scans faster than a manual can
- Computer Vision will almost certainly become standard practice in modern medicine, but there are still obstacles to overcome. Finding viable answers to these obstacles may take some time for healthcare professionals.
-
Manufacturing: Computer Vision has been employed by manufacturers since the 1950s, and as the technology has advanced, more applications have emerged. Computer Vision can scan text and barcodes on products, detect defective parts, and assist with product assembly for manufacturing organizations.
Everyone in the supply chain wins when Computer Vision can assist manufacturers in removing bad items. Overall, Computer Vision has aided the manufacturing industry in overcoming some of its most pressing issues, and this trend is expected to continue.
-
Construction: Prescriptive analytics, keeping machinery working properly, and avoiding downtime during major building projects are all things that computer vision can help construction organizations and their personnel with.
Workers can be alerted to equipment faults by computer vision and be able to take proactive measures to resolve them before it's too late. Computer Vision can also identify PPE to ensure worker safety, which is something the industry works hard to achieve.
Computer vision is still in its early stages, and developers and designers are facing some challenges. They've already achieved significant technological advancements. It will be fascinating to see how computer vision becomes more extensively utilized and accessible to businesses of all sizes.
- Robotics:
- Determine the robot's location automatically via localization.
- Navigation
- Avoiding stumbling blocks
- Installation (peg-in-hole, welding, painting)
- Manipulation is the manipulation of information (e.g. PUMA robot manipulator)
- Intelligent robotics to engage with and serve people is known as Human-Robot Interaction (HRI).
- Security:
- Biometrics is a term that refers to a set of ( face recognition, fingerprint, and iris )
- Detecting certain malicious activities or actions through surveillance.
8. What are the applications of OpenCV with Python?
With the aid of OpenCV in Python, you can simply process photos and videos and extract relevant information from them, thanks to the numerous functions provided. The following are some examples of common applications:
- Image Processing: OpenCV can process, show, write and read images, such as generating a new image from an existing one by modifying its shape or color, or extracting something useful from an existing one and writing it into a new image.
- Face Detection: Using Haar- Cascade Classifiers, either from live streaming using a webcam or from locally recorded videos/images.
- Face Recognition: Face detection from movies was done through open cv by creating bounding boxes, such as rectangles, and then model building using machine learning methods to recognize faces.
- Object Detection: An object detection technique can be used with OpenCV and the YOLO to detect motion or solid objects in images and movies.
| Want to know more about Python - Check Python Tutorial |
9. What is Dynamic Range?
A quantity's dynamic range is the ratio of tiny and big values it assumes. Signals, light, sound, and photography all employ it. From a photographic standpoint, it is a ratio of the specified range of light intensity or the lightest and darkest parts, also known as color contrast.
10. Define Digital Image in OpenCV?
A digital image is made up of the picture's constituents, which are also known as pixels. Each pixel has finite and discrete numerical representations that correspond to its intensity and grey level, which are outputs from two-dimensional functions fed by spatial coordinates designated by the y-axis and x-axis.
OpenCV Interview Questions and Answers for Intermediate:
1. How many types of image filters in OpenCV?
Filters typically employ multiple pixels to compute each new pixel value, whereas point operations can conduct image processing with just one pixel. The filters can be used to smooth out hazy or fuzzy images of local intensity. The concept is to replace each pixel with the average of its neighbours. Filters are classified into two types:
- Linear Filters
- Non-linear Filters
A. Linear Filters:
Kernel matrix and convolution of matrix pixels to reduce the image intensity, resulting in blurring. There are three types of linear filters as follows:
- Box filter:
The boxfilter() function can be used to perform this filter. It works in the same way as the typical blur operation. The function's syntax is as follows:
Syntax:
cv2. boxfilter(src, dst, ddepth, ksize, anchor, normalize, bordertype)-
- src– This specifies the image's origin. It might be a single-channel, 8-bit or floating-point picture.
- dst– It stands for the same-size destination picture. It will have the same kind as the src picture.
- ddepth– The depth of the output image.
- ksize–It blurs the kernel size with ksize.
- Anchor– The anchor points are indicated by the word anchor. The anchor is in kernel center by default, with the value Point to coordinates (-1,1).
- normalize– This is a flag that specifies whether or not the kernel should be normalized.
- borderType– The type of border utilized is represented by an integer object.
- Gauss Filter:
Instead of using the box filter, the picture is fused with a Gaussian filter in the Gaussian Blur process. The Gaussian filter is a type of low-pass filter that reduces high-frequency components.
The imgproc class's Gaussianblur() method can be used to execute this operation on a picture. This method's syntax is as follows:
Syntax:
GaussianBlur(src, dst, ksize, sigmaX)The following parameters are accepted by this method:
-
- src– A Mat object that represents the operation's source (input image).
- dst-- A Mat object that represents the operation's destination (output image).
- ksize-- It is a size object that represents the kernel's size.
- sigmaX-- It is a double-valued variable that represents the Gaussian kernel standard deviation in the X-direction.
- Laplace Filter:
OpenCV contains a function named "Laplacian" that calculates the pixel integration to generate the kernel matrix to compute the Laplace filter.
Syntax:
LaplacePic = cv2.Laplacian(img, 24, (5,5))The number "24" stands for "DDepth," which represents the depth of the destination image. The Laplace filter produced this result.
B. Non-linear Filters:
Using a nonlinear function to calculate the value of the source pixel. The goal is to use some sort of sequencing method or function to substitute the target pixel's value with that of its neighbors.
There are many other types of non-linear filters, but we're discussing three in this blog.
- Minimum Filter: This technique selects the lowest value of each pixel from the target's adjacent pixels and replaces it.
- Maximum Filter: This algorithm is similar to the minimal filter, only it chooses the highest option.
- Median Filter: The median blur method works in the same way as the other averaging procedures. The median of all the pixels in the core area is used to replace the image's core element. This procedure removes noise while processing the edges. The medianBlur() method of the imgproc class can be used to conduct this action on a picture. This method's syntax is as follows:
Syntax:
medianBlur(src, dst, ksize)-
- src-- A Mat object that represents the operation's source (input image).
- dst-- A Mat object that represents the operation's destination (output image).
- ksize-- It is a Size object that represents the kernel's size.
2. Explain about Sampling and Quantization?
To transform analogue images into digital ones, we use sampling and quantization. There are two aspects to an image.
- Coordination: Sampling is the process of digitizing coordinates. That is, transforming analogue image coordinates into digital image coordinates.
- Amplitude/Intensity: Quantization is the process of digitizing amplitude or intensity. That is, converting an analogue image's amplitude or intensity to a digital image.
3. How to store the images in OpenCV?
We employ equipment like scanners and cameras to capture images. These gadgets keep track of the image's numerical values (Ex: pixel values). We need to store these photos for processing because OpenCV is a library that processes digital images.
The picture values are stored in the Mat class of the OpenCV library. It is used to hold image data such as voxel volumes, point clouds, histograms, grayscale or color images, vector fields, tensors, and other n-dimensional arrays. The header and an indicator are the two data elements of this class.
- Header: The header contains information such as the matrix's size, storage type, and address (constant in size).
- Pointer: The image's pixel values are stored in the pointer (which keeps on varying).
4. What are the constructions of Mat class?
This class (Mat) is provided by the OpenCV Java environment within the package.
- Constructors: The Mat class in the OpenCV Java environment provides several constructors that can be used to create Mat objects.
- Mat(): In most circumstances, this is the default constructor with no parameters. We generate an empty matrix using this constructor and give it to other OpenCV methods.
- Mat(int rows, int cols, int type): This constructor takes three integer arguments to represent the number of columns and rows in a two - dimensional array, as well as the array type (that is to be used to store data).
- Mat(int rows, int cols, int type, Scalar s): This constructor admits an entity of the class Scalar in addition to the preceding constructor's parameters.
- Mat(Size size, int type): This constructor takes two arguments: an object describing the matrix's size and an integer specifying the array type used to hold the data.
- Mat(Size size, int type, Scalar s): This constructor acknowledges an entity of the class Scalar in addition to the preceding constructor's parameters.
- Mat(long addr)
- Mat(Mat m, Range rowRange): This constructor takes an object from another matrix and a Range object defining the row range to be used in the new matrix.
- Mat(Mat m, Range rowRange, Range colRange): This constructor acknowledges an object of the class in addition to the preceding constructor's parameters. The range denotes the column range.
- Mat(Mat m, Rect roi): This constructor takes two objects, one of which represents the other matrix and the other the Region Of Interest.
OpenCV Interview Questions and Answers for Experienced:
1. How to create and display the Matrix in OpenCV?
Below steps are followed to create and display the Matrix in OpenCV:
Step-1 - Load the OpenCV native library:
The first step in building Java code that uses the OpenCV environment is to load the OpenCV native library operating the loadLibrary method (). As seen below, load the OpenCV native library.
Syntax:
#Loading the core library
System.loadLibrary(Core.NATIVE_LIBRARY_NAME);
Step-2 - Instantiate the Mat class:
Use any of the functions given earlier in this article to instantiate the Mat class.
//Creating a matrix
Mat matrix = new Mat(5, 5, CvType.CV_8UC1, new Scalar(0));Step-3 - Fill the matrix using the methods:
By supplying index values to the functions row()/col(), you can obtain specific rows/columns of a matrix ().
You can use any of the setTo() functions to set values to these variables.
# Retrieving the row with index 0
Mat row0 = matrix.row(0);#setting the alues of all elements in the row with index 0
row0.setTo(new Scalar(1));2. How to read the images in OpenCV?
Methods for reading and writing images are found in the Imgcodecs class. OpenCV allows you to read a picture and store it in a matrix (along with any necessary transformations). You can save the processed matrix to a file later.
To read a picture using OpenCV, utilize the read() function of the Imgcodecs class. This method's syntax is as follows.
imread(filename)It takes a single argument (filename), which is a String variable that represents the path to the file to be read.
3. How to write the images in OpenCV?
The Imgcodecs class's write() method is being used to write an image utilizing OpenCV. Rep the first three stages from the last example to create a picture. The imwrite() function of the Imgcodecs class is used to write an image.
This method's syntax is as follows:
imwrite(filename, mat)The following parameters are accepted by this method:
- filename-- It is a string variable that represents the file's location.
- mat-- The image to be written is represented by a Mat object.
| Checkout - Python Interview Questions |
4. How to convert Mat to Bufferedimage in OpenCV?
The function imread is used to read an image (). This method returns a matrix representation of the picture read. However, to use this picture with GUI frameworks (JavaFX and AWT/Swings ), it must be turned into an item of the class BufferedImage from the java. awt. image package. BufferedImage
The following are the steps to convert an OpenCV Mat object to a BufferedImage object.
Step-1: Encode the Mat to MatOfByte
To begin, you must transform the matrix into a byte matrix. You can achieve it with the imencode() function of the Imgcodecs class. This method's syntax is as follows.
Syntax:
imencode(ext, image, matOfByte);The following arguments are accepted by this method:
- ext-- It specifies the image format as a string parameter (.jpg,.png, etc.).
- image-- A Mat entity defining the image
- matOfByte-- It's a MatOfByte class object that's empty.
Step-2: The MatOfByte object is converted to a byte array
Transform the MatOfByte item into a byte array using the toArray function.
array().
byte[] byteArray = matOfByte.toArray();Step-3: Getting the InputStream object ready
To create the InputStream object, pass the byte array created in the preceding phases to the constructor of the ByteArrayInputStream class.
InputStream in = new ByteArrayInputStream(byteArray);Step-4: Getting the BufferedImage object ready
The read() function of the ImageIO class accepts the Input Stream object produced in the preceding step. A BufferedImage object will be returned.
BufferedImage bufImage = ImageIO.read(in);5. How to display the image using JavaFx?
To use JavaFX to display a picture, first read it with the imread () function and convert it to a BufferedImage. Then, as seen below, transform the BufferedImage to WritableImage.
WritableImage writableImage = SwingFXUtils.toFXImage (bufImage, null);Transmit this WritableImage item to the ImageView class's constructor.
ImageView imageView = new ImageView (writableImage);6. How to display the image using AWT/Swing?
To use the AWT/Swings frame to display an image, first read/import an image with the imread () function and then convert it to BufferedImage using the procedures above.
Then, as shown below, initialize the JFrame class and add the buffered picture to the JFrame's content pane.
# Initializing the frames
Instantiate JFrame1
JFrame1 frame1 = new JFrame1();
#Set Content to the JFrame
frame1.getContentPane().add(new JLabel(new ImageIcon(bufImage)));
frame1.pack();
frame1.setVisible(true);
7. Explain about morphological operations in OpenCV?
Morphological operations, as the name suggests, are a set of actions that manipulate images based on their shapes.
A "structural element" is created based on the provided image. This might be accomplished using either of the two methods. These are used to reduce noise and smooth out defects in order to make the image more clear. The two forms of morphological procedures are erosion and dilation.
8. Explain about Dilation in OpenCV?
Convolution with a kernel of a specified shape, such as a square or a circle, is used in this technique. The center of this kernel is indicated by an anchor point.
This kernel is overlapped across the image to compute the maximum pixel value. The image is replaced with an anchor in the center after it has been calculated. The areas of bright regions grow in size as a result of this procedure, and the image size grows as a result.
The size of an item in a white or bright shade, for example, increases, whereas the size of an object in a black or dark shade diminishes.
The dilate() function of the imgproc class can be used to dilate an image. This method's syntax is as follows.
Syntax:
dilate(src, dst, kernel)The following parameters are accepted by this method:
- src-- A Mat item that represents the operation's source (input image).
- dst-- A Mat item that represents the operation's destination (output image).
- kernel-– A Mat item that represents the kernel.
9. Explain about Erosion in OpenCV?
Dilation and erosion are both related processes. However, in dilation, the pixel value obtained here is minimum instead of maximum. The picture gets replaced with that pixel value under the anchor point.
Dark regions expand and light regions shrink as a result of this operation. For example, an object's size increases in a dark or black shade but diminishes in a white or brilliant shade.
Syntax:
erode(src, dst, kernel)The following parameters are accepted by this method:
- src-- A Mat item that represents the operation's source (input image).
- dst-- A Mat item that represents the operation's destination (output image).
- kernel-- A Mat item that represents the kernel.
The getStructuringElement() function can be used to create the kernel matrix. This method takes an object of type Size and an integer indicating the morph rect type.
10. Explain about the sobel() method in OpenCV?
Users may detect the edges of a picture in both vertical and lateral dimensions with the sobel technique. The method sobel can be used to apply the sobel operation to an image (). This method's syntax is as follows:
Syntax:
Sobel(src, dst, ddepth, dx, dy)The following parameters are accepted by this method:
- src--The source (input) image is represented by an element of the class Mat.
- dst--The destination (output) image is represented by dst, a Mat element.
- ddepth-- It is an integer number that represents the image's depth (-1)
- dx--The x-derivative is represented by the integer variable dx. (0 or 1)
- dy--The y-derivative is represented by the integer variable dy. (0 or 1)
11. Explain about the Scharr() method in OpenCV?
Scharr is also used to find a picture's horizontal and vertical second derivatives. The Scharr method can be used to conduct the Scharr operation on a picture. This method's syntax is as follows:
Syntax:
Scharr(src, dst, ddepth, dx, dy)The following parameters are accepted by this method:
- src--The source (input) image is represented by an element of the class Mat.
- dst--The destination (output) image is represented by dst, a Mat element.
- ddepth-- It is an integer number that represents the image's depth (-1)
- dx--The x-derivative is represented by the integer variable dx. (0 or 1)
- dy--The y-derivative is represented by the integer variable dy. (0 or 1)
Conclusion:
Here our blog ends and It makes no difference how much knowledge you gather to study a concept; what matters is how clear and precise you make it. In this blog, we've endeavored to compress basic to advanced concepts of OpenCV Interview questions and answers. I hope that these questions and answers have given you a better understanding of concepts. Please let us know if you come across any similar questions that aren't answered here in the comments section.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Python Training | Aug 04 to Aug 19 | View Details |
| Python Training | Aug 08 to Aug 23 | View Details |
| Python Training | Aug 11 to Aug 26 | View Details |
| Python Training | Aug 15 to Aug 30 | View Details |

Madhuri is a Senior Content Creator at MindMajix. She has written about a range of different topics on various technologies, which include, Splunk, Tensorflow, Selenium, and CEH. She spends most of her time researching on technology, and startups. Connect with her via LinkedIn and Twitter .














