- Home
- Blog
- Machine Learning
- Top 10 Machine Learning Algorithms

- TensorFlow Interview Questions
- How Oracle Embeds Machine-Learning Capabilities Into Oracle Database
- Machine Learning Applications
- Machine Learning Datasets
- Machine Learning Examples In Real World
- Machine Learning Interview Questions
- Machine Learning Techniques
- Machine Learning Tutorial
- Artificial Intelligence Vs Machine Learning
- Machine Learning with Python Tutorial
- Machine Learning with Spark
- Support Vector Machine Algorithm - Machine Learning
- Top 10 Machine Learning Books
- Top 10 Simple Machine Learning Projects For Beginners
- Skills Required for Machine Learning
- Keras Tutorial
- TensorFlow Object Detection
- TensorFlow Tutorial
- Installing TensorFlow
- TensorFlow 2.0 - A comprehensive platform that supports machine learning workflows
- What is Reinforcement Learning?
- Keras vs TensorFlow
- Machine Learning Projects and Use Cases
Machine learning is one of the buzzwords that’s making the rounds in the present IT industry. It is finding its usage in more and more common scenarios like suggesting related videos after watching a particular genre of videos or Amazon suggesting products that go along with a product that you already purchased. Not just these, but there are countless examples that are truly leveraging its potential to its fullest capacity.
In this process, raw historic data is provided as an input and based on the available techniques, allows organizations to derive the possible outcome from the same. Organizations have already started mining over their potential and are also contributing towards its growth further. we discuss in detail about Machine Learning basics and Machine Learning Algorithms that come into play, and the related topics.
Learn how to use Machine Learning, from beginner basics to advanced techniques. Enroll in our Machine Learning Certification Course today!
The following topics are covered in this Machine Learning Algorithms blog:
- What is a Machine Learning Algorithm?
- How do Machine Learning Algorithms work?
- What are the benefits of using Machine Learning Algorithms?
- How to choose Machine Learning Algorithms based on the use case?
- Difference between regular Algorithm and Machine Learning Algorithm
- Types Of Machine Learning Algorithms
- Top 10 Machine Learning Algorithms
- Machine Learning Algorithms (with Python)
- Machine Learning Algorithms Examples and Applications
- Best Machine Learning Algorithm Books
- MindMajix Machine Learning Algorithms Course
In this section, let us try and gather some understanding of the concepts of Machine Learning as such. These details are much more important as and when we progress further in this article, without the understanding of which we will not be able to grasp the internals of these algorithms and the specifics where these can apply at a later point in time. Now to get some understanding about the required nomenclature and the keywords, let us go through the following:
What is a Machine Learning Algorithm?
Machine Learning is firstly a subset of Artificial Intelligence and this should not be understood the other way round. Machine Learning is the technique to train your computers or systems without even explicitly programming them. And in the process of doing just that, there are algorithms that come into place which help these systems to train themselves better on each passing day which is referred to as Machine Learning Algorithms. It can be understood that these are the catalysts that churn Machine Learning into a reality.
How do Machine Learning Algorithms work?
Machine Learning works on the concepts of either Supervised or Unsupervised training model. It comes more evident in the further sections of the article where this is explained in better detail after the necessary information is provided. The process by which the input and output are mapped to yield a better model is called Supervised Learning. The means by which you don’t have control over the learning process or where it gets unpredictable is called Unsupervised machine learning.
What are the benefits of using Machine Learning Algorithms?
The following are the benefits of using Machine learning algorithms.
- Finds its usage in almost all the available industries ranging from Banking, Healthcare, Publishing, Retail and etc.
- Targeted advertisements to the users based on their choices, requirements and also based on their search patterns/behaviors
- Provides capabilities in handling multi-dimensional and varied data requirements in the most dynamic environments as well.
- Provides efficient resource usage and time cycle reduction.
- Provides scope to improve upon quality, process with its constant feedback process.
- Automation of certain tasks is made possible based on the feedback that is generated in various other systems.
[Related Article: What Is The Difference Between Artificial Intelligence, Machine Learning, And Deep Learning?]
How to choose Machine Learning Algorithms based on the use case?
This can be done by having a better understanding of the problem and the available types of solutions. There are 4 variants of algorithms that exist and we will discuss these in the next sections. Based on the problem there can be solutions amongst these 4 that can be put to use. Apart from this classification of algorithms, there are some commonly used algorithms that find their usage very specific to the use case than anything else. With the forthcoming sections in this article, you should be able to choose amongst the available algorithms to go for based on the use case that you take up.
Difference between regular Algorithm and Machine Learning Algorithm
Here is the tabular form that helps you understand the differences between regular algorithms and machine learning algorithms. Though on a broader sense these are just algorithms, the context in which these find their usage makes them two very different entities. Let us now try to understand these in detail:
| Regular Algorithm | Machine Learning Algorithm |
| Classic algorithms are nothing but step by step instructions based on the input that is provided, that determines the specific output. Hence, these can be termed as RULE BASED algorithms. | Machine learning algorithms process labeled or unlabelled input data to deduce the probable output that is based on the input data that is fed into this algorithm. |
| Classic algorithms produce an output to the provided input values | Machine learning algorithm predicts an output to the provided input data. |
| Classic algorithms are intended for tasks that are not related to predicting anything | Machine learning algorithms are specifically intended to predict the outputs based on the provided input data. |
| Classic algorithms are hardcoded to provide the same output how many ever attempts the input data is processed | Machine learning algorithms refine themselves processing data on a continuous process and hence making them much more powerful after a certain point in time than in comparison with the classic algorithms. |
Types of Machine Learning Algorithms
In this section, let’s take a look at the types of Machine Learning Algorithms:
#1) Supervised Learning Algorithms
Introduction:
Supervised learning can be defined as that learning task where a function is obtained which maps input to an output model based on input and output pairs. In this method, a pair of input objects and the output object (vector, supervisory signal) is analyzed by a supervised learning algorithm to produce the much required inferred function. This function can be further used to map newer examples.
When to use?
This algorithm finds its usage when you have an outcome that needs prediction based on the values provided for all the dependent parameters. With the provided set of variables, a function is generated which maps all these input variables to the necessary or the desired outputs. The supervised learning algorithm is allowed to learn until the model generated reaches a certain level of accuracy on the provided input data.
Example Algorithms:
- Logistic Regression
- Decision Tree
- KNN
- Regression
- Random Forest
[Related Article: Machine Learning Examples In Real World]
#2) Unsupervised Learning Algorithms
Introduction:
Unsupervised Learning Algorithm uses nonclassified and nonlabeled information. In the process of doing that, it also allows the actual algorithm to act and react to the information at hand without any guidance as such. The Artificial Intelligence system will be able to identify and classify similar and dissimilar entities even when there are no categories associated with them.
When to use?
- Unsupervised learning also falls into similar lines of Supervised learning with the only difference that, Unsupervised learning algorithms are totally unpredictable in nature.
- Unsupervised learning algorithms find their usage in much more complex processing tasks such as Chatbots, Facial Recognition, Self-driving cars, and the like.
Frequently Asked Machine Learning Interview Questions
Example Algorithms:
- K-Means
- Apriori algorithm
#3) Semi-supervised Learning Algorithms
Introduction:
A working combination of both supervised learning and unsupervised learning is called semi-supervised machine learning. In the case of supervised learning, as we understood above, there is a machine learning algorithm that processes labeled data consisting of input and outcome details. Using this, patterns can be identified and deduced, and also relationships between the dataset and the target variable itself can be established. On the contrary, unsupervised learning algorithms process the dataset without any outcome variable - imbibing both of these qualities, a semi-supervised algorithm inculcates both the labeled and unlabelled data.
When to use?
A semi-supervised learning algorithm finds its usage in the cases where there isn’t enough labeled data that can be used to deduce an accurate model. Using the semi-supervised learning algorithms the training data size can be increased to a level from where a working model can be deduced.
#4) Reinforcement Learning Algorithms
Introduction:
The reinforcement learning algorithm is an artificial learning agent that helps identify an optimized way to accomplish goals. This helps in identifying the best way possible in realizing a goal, and better ways to improve performance on specific tasks. In the simplest way possible, it is to take the best possible steps in order to achieve the ultimate or the final reward.
When to use?
This finds its usage where there is a specific decision making required. The whole setup is exposed to such an environment where the system itself can train itself using the trial and error methods. This particular model trains itself using past experiences and learns the best possible knowledge in order to make necessary business decisions.
Example Algorithms:
Markov Decision Process

Best Machine Learning Algorithms
From the earlier sections of this article, you should have got a fair idea about what these Machine Learning algorithms are and how they find their usages in most of the complex situations or scenarios. Now, it is time to learn in detail about these specific algorithms, so that you may be able to put them into use at a later point in time. Let us go through the topmost machine learning algorithms that we have listed down here:
#1) Ensemble Methods in Machine Learning
Introduction:
Ensemble Methods in Machine Learning is a technique that is a combination of various base models to produce a single predictive and optimal model. Ensemble Methods generally use Decision Trees and to be precise, it uses other models as well but the most commonly used ones are the Decision Trees. From a series of Decision Trees, it allows taking a sample of these outcomes and lets you evaluate which factors to ponder upon in making the final prediction based on these aggregated results that are provided in the step earlier.
When to use?
- Ensemble Methods (Bagging) is used when you want to decrease the Variance but also at the same time, try to keep the bias the same.
- Ensemble Methods (Boosting) is used when you want to train your model from the previous phase mistakes to correct the high bias in the training sets.
Example applications:
Finds its usage in Kaggle problems
[Related Article: Skills Required For Machine Learning Jobs]
#2) Decision Trees in Machine Learning
Introduction:
Decision Trees, as explained earlier, are supervised machine learning algorithms where the data is continuously split on the basis of one parameter to arrive at a final decision or prediction. The Decision Tree works on two parameters, the decision nodes and leaves. The points where the data is split are known as decision nodes and the final decisions or predictions are called leaves. The following picture gives you a better understanding of this:
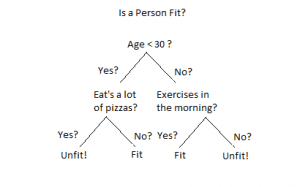
When to use?
- When you’re planning to achieve maximum profit or optimize cost
- When there is more than one course of action
- When there is more uncertainty on the probable outcome
- When there are more environmental factors that tend to imbalance the decision control
Example applications:
- Chemical Material evaluation for the respective manufacturing or production
- Optimization in the processes in Electrochemical Machining
- Astronomy - Filtering noise from Hubble Space telescope images
- Development of efficient analysis of drugs
[Related Article: Top 10 Machine Learning Projects]
#3) Neural Networks in Machine Learning
Introduction:
Neural Networks or Artificial Neural Networks (ANN) defines the thinking of a human as a computer, by which we mean that the answer for any question would be between a YES or a NO. These Neural Networks acquire this knowledge through a definitive and continuous learning process. The knowledge thus acquired is stored in the form of weights in the interconnections. As and when these Neural Networks are trained further with the updated weights, they keep acquiring new knowledge.
When to use?
- We can use Convolutional Neural Networks (CNN) where the data are images
- CNN's can be used when it is Classification or Regression prediction problems
- We can use Recurrent Neural Networks (RNN) where the data is text, speech, or audio.
- RNNs can still be used apart from CNNs for Classification or Regression prediction problems.
Example applications:
- Suits best with the LSTM (Long Short Term Memory network) problems
- When your dire need is Sequence prediction
#4) Conjoint Analysis
Introduction:
Conjoint analysis is a machine learning technique to understand the relative importance and also the preference that is given to various attributes of every unique product that the customer is willing to purchase. These details are used to strategize the marketing techniques to push sales into the consumer markets.
When to use?
When you are in need to build machine learning models of consumer preferences
When you are in need to build models that are choice-based and preferential over other competitive offerings from various manufacturers
Example applications:
- Understand consumer psychology in consumer product purchases.
- Marketing for strategies
#5) PCA (Principal Component Analysis) in Machine Learning
Introduction:
The objective of Principal Component Analysis (PCA) is to be able to have a set of data points where you can identify a hyperplane closest to them and project the data onto it. It is one of the most prominent algorithms available in the fields of Data Science (Machine Learning) that handles the dimensionality reduction most efficiently.
When to use?
- When you are aware that there is a definite need to reduce the larger set of variables to a smaller set that contains most of the information that it held earlier.
- When you are aware that the available data set is a square symmetric matrix
Example applications:
- PCA for image compression for efficient storage
- Usage in programming
#6) Anova Machine Learning
Introduction:
ANOVA, which is an acronym for Analysis of Variance, is actually a combination of various statistical models that are used to analyze the differences, variances amongst group means, and also amongst their associated procedures. It allows or enables to check the impact of one or more of these factors by comparing the means of different samples of the data available.
When to use?
ANOVA can be used to either prove or disprove if the available medical treatments were effective or not.
Example applications:
- To compare the mileage of different vehicles and the same vehicles but different fuel types
- To evaluate catalysts on Chemical reaction rates
- To evaluate the impact of pressure, temperature, and chemical concentration on Chemical reactions.
[Related Article: Machine Learning Applications]
#7) Clustering in Machine Learning
Introduction:
Clustering is a technique which involves grouping data points. There can be any clustering algorithm that could be used to group these sets of data points and classify each of these data points into specific groups. In theory, data points that fall into the same group should have identical properties or features whereas data points that fall into different groups should be very much dissimilar to each other.
When to use?
Clustering is unsupervised learning that can be used for statistical data analysis. This finds its usage in many fields as such.
Example applications:
- To mine on details of various species of birds that find their habitat in various places
- Analyze how many wickets does a bowler has taken by giving away runs.
[Related Article: A Guide To Machine Learning With Python]
#8) Logistic Regression in Machine Learning
Introduction:
It is a little confusing to digest the fact that the Logistic Regression Machine Learning algorithm is actually for classification-related tasks than for regression problems. It is in specific a logistic function that deals with a linear combination of features that help predict the outcome of a variable (categorical dependent) based on the predictor variables that we have already used.
When to use?
- Usage of Logistic regression machine learning algorithms can be observed in scenarios where we need to model probabilities of a response variable as a function of another variable. Eg: Probability of purchasing Perfume X as a function of gender
- We can use the Logistic regression machine-learning algorithm to predict the probabilities of a categorical dependent variable will fall into categories of possible binary responses, and all of this is a function of another variable.
- It can also be used when there is a requirement to classify categories based on an explanatory variable. Eg: Classify women into younger and grown-up adults based on age.
Example applications:
- It can be used to classify a provided set of words like pronouns, nouns, verbs, and adjectives.
- It can be used in Weather forecasting to predict rains
- It can be used in Credit Scoring systems wherein risk management is assessed.
- Used to evaluate wins in political elections
[Related Article: Machine Learning Techniques]
#9) Linear Regression in Machine Learning
Introduction:
The linear regression machine learning algorithm helps in depicting the relationship between two variables and also evaluates the impact of changing one variable on the other. The impact is depicted when a change of independent variable causes changes in the dependent variable. The independent variables are termed as explanatory variables because they tend to describe the factors that most impact the dependent variable and the dependent variable is termed as the factor of interest.
When to use?
- Linear regressions can be used in machine learning wherever there are demand and supply problems
- It finds its usage to evaluate or predict the price hikes of commodities based on market conditions.
Example applications:
- Linear regression machine learning algorithm is used for the sales estimation
- It can also be used for evaluating risk assessments in the Financial domain.
[Related Article: Machine Learning Datasets]
#10) Hypothesis in Machine Learning
Introduction:
A Hypothesis can be considered as that function which we want to believe is similar to the true function. To put it in much simpler words, if the number of parameters in the given model are too small then the model is said to be underfitting (hypothesis space is then considered limited). If in the case of the number of parameters in the given model are higher then it is said to be overfitting (hypothesis space is then considered expressive).
[Related Article: Support Vector Machine Algorithm]
Machine Learning Algorithms (with Python)
Machine Learning is a way by which one can imbibe the necessary intelligence which enables computers to learn without having programmed explicitly. It allows computers evolve from strict programmed behavior to continuously improving these systems’ development. Programs do change their behavior based on the learning that they yield from the provided input data. Machine Learning can be achieved using simplistic algorithms using languages like Python or R. Let us go through this section in understanding Machine Learning using Python.
Python is one of the top players amongst the Machine learning enthusiasts. There are three types:
#1) K-nearest neighbor (KNN) Classifier:
The KNN (K Nearest Neighbour) method is an ideal case which can find implementation in both Regression and Classification problems. It is a simple algorithm that maintains all the possible cases and further classifies the possible cases by a factor of k neighbors which are the majority in number. It is usually measured using a distance function. There are 4 different variants of the distance functions that are available for usage - Euclidean, Minkowski, Manhattan, and the last one being Hamming distance. The first three find their usage in continuous function and the Hamming function is used for the categorical variables.
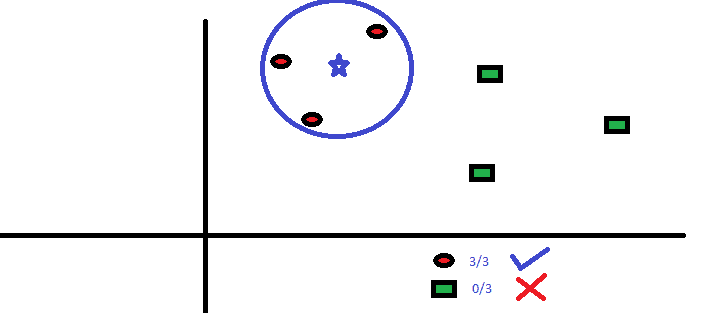
KNN can be easily applied to our lives without any modification. In order to understand a person whom you’ve not known before, you would want to understand more about his or her close friends. You would then want to gain information by moving in circles where he moves. Let us understand at least one use case with an actual Python implementation:
Things that we might need to consider before we select our ideal KNN are as follows:
- That it is expensive computationally
- Need to normalize variables or else we might end up with a higher range of variables biasing it
- More work on the preprocessing state before even reaching the KNN
[Related Article: What Is Artificial Neural Network And How It Works?]
Sample Python implementation of K Neighbors Classifier algorithm:
#Import the necessary library
from sklearn.neighbors import KNeighborsClassifier
#Assume that you have, X (as the predictor) and Y (as the target) for training your available dataset and x_test(predictor) of test_dataset
# Create KNeighbors classifier object model like the below
KNeighborsClassifier(n_neighbors=6) # default value for n_neighbors is 5
# Train the model using the provided training sets and finally check the score at a later stage
model.fit(X, y)
#Predict the Output as shown below:
predicted= model.predict(x_test)#2) Naive Bayes Classifier:
In the context of Machine Learning, it is considered as a Classification technique finding its origin from the Bayes theorem. It is based on an assumption that the predictors are independent of each other. In layman terms, the existence of a class feature is not at all related or dependent on the existence of any other feature in that class.
When to use the Naive Bayes Classifier Machine Learning Algorithm?
- When you are dealing with moderate to large data sets for training purposes
- When there are several attributes for your instances
- When the attributes that define instances are conditionally independent
Applications of Naive Bayes Classifier Machine Learning Algorithm:
- Sentiment Analysis - Facebook or WhatsApp statuses that express positive or negative emotions.
- Document Classification - To provide PageRank to index documents and also providing them relevancy scores by Google.
- Email Spam Filtering - Google puts the Naive Bayes Classifier Machine Learning algorithm to use in classifying your emails as Spam or not.
#3) K-Means Classifier:
This is an unsupervised machine learning algorithm that attempts to solve the clustering problem in specific. The procedure that this algorithm follows is to simply classify the given dataset into a set of clusters and data points. Within these clusters, there are homogenous and heterogeneous to other peer groups at the same time. As the number of clusters increases, the sum of the squares of the difference between the data points and centroid decreases and slows down after an optimum value, which is then identified as the K-Means Classifier.
[Related Article: How Oracle Embeds Machine-Learning Capabilities Into Oracle Database]
When to use the K-Means Classifier Machine Learning algorithm?
- When the values of K are relatively smaller, the K-Means algorithm computes quicker in comparison with the hierarchical clustering for a bigger set of variables.
- When global clusters are in use, the K-Means Classifier Machine learning algorithm provides tighter clusters than hierarchical clustering.
Applications of K-Means Classifier Machine Learning algorithm:
- Finds its usage in Search results by prominent search engines like Yahoo or Google - to identify the relevance rate of the provided search results.
- Data Science libraries that implement K-Means clustering in Python are SciPy, Python Wrapper, and Sci-Kit learning.
- Data Science libraries that implement K-Means clustering in R are stats.
Machine Learning Algorithms Examples and Applications
There are a varied number of examples of how Machine Learning is put to use in our day to day life. In this section, we shall take a look at some of these examples and / or applications.
Image Classification:
Image Classification can be understood as supervised learning wherein a provided set of target classes - in our case would object that is used to identify an image. We will have to train a model that recognizes these using labeled example pictures. Earlier models used to depend completely on the raw pixel data which may or may not provide the required representation of the desired image. There are factors like the object’s position, camera angle, lighting, a focus that produces these elements from the raw pixel data.

In the picture above, the left side denotes the pictures of cats in various angles and postures with different light conditions, etc. On the right, we have an averaged picture with a variety of pictures that are fed into the model, finally produce not so meaningful data.
Sample algorithms that can be used in this kind of scenario are Convolutional Neural Networks (CNN). A Convolutional Neural Network is, in specific, nothing more than a regular Neural Network but has an additional convolution layer at the beginning.
[Related Article: Machine Learning With Spark]
Voice Recognition:
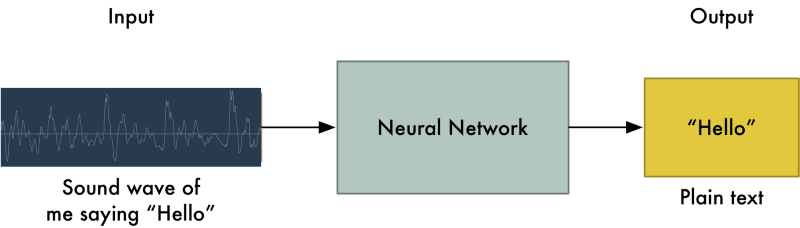
The systems that are used in analyzing an individual’s voice and further used to fine-tune it for recognition purposes, results in an accurate model. There are systems that do not use any further training which are termed as Speaker independent and there are systems that do use training to be more precise and accurate, which are termed as Speaker dependent. Following is an image that helps understand the whole process of how the system is trained to understand or recognize an individual’s voice per se.
The algorithms that come to use here are the Recurrent Neural Networks. A Recurrent Neural Network is a top-class algorithm that finds its usage with sequential data. It keeps a track of the inputs provided because of its internal memory and hence is considered one of the finest of the available algorithms from the bunch that is already available. Speech that we are internally processing is transformed into a series of sounds, which then by the usage of Fourier Transform be converted to numbers based on its signal strength.
Smart Email Classification:
Emails have now become one of the integral parts of our everyday life. Not just that it provides a medium through which we as individuals communicate with our friends, colleagues, and family - it also forms a large part of data that can be processed using machine learning. The best algorithms that could come to rescue here are the Unsupervised Machine learning. Yes, you read that right. One good thing about the emails is that we might be able to come up with the addresses predicted based on the from addresses, but the email body is totally unexpected and hence an unsupervised machine learning algorithm will find its perfect usage, such as KMeans.
Analyzing the keywords from the message body, the messages are grouped by the common words or most frequently used words in the messages. These words define the activity and also provide the decision making to where to classify this email into. At the same time, it also trains the learning model with more information to process the upcoming email messages as well.
[Related Article: Why Azure Machine Learning?]
Estimated Time & Price Prediction in Travel application:
If you would have seen an ETA (Expected Time of Arrival) on a flight or a train, it is an average value based on the prior travel times of that specific train or flight in that route. The same holds good with cab providing services like Uber and Ola as well. The interesting part is on the process of mining on these details to arrive at a near accurate time that is expected.
As mentioned earlier, gaining better insights into these near accurate figures involves a combination of various machine learning algorithms such as Random Forest, Linear Regression, and Long Short Term Memory (LSTM) and also along with it, the ensembling techniques to produce optimal results.
Best Machine Learning Algorithm Books
Though books provide you with the required knowledge in understanding the concepts well, you will need to have a thorough hands-on along with these books and the related material.
Here is the list of Top 10 books that we have compiled to provide you with the best of the knowledge to gain from:
- Machine Learning for Absolute Beginners: A Plain English Introduction
- Advances in Financial Machine Learning
- Deep Learning (Adaptive Computation and Machine Learning series)
- Deep Learning with Python
- Introduction to Machine Learning with Python: A Guide for Data Scientists
- Machine Learning: A Probabilistic Perspective (Adaptive Computation and Machine Learning series)
- Machine Learning; The Ultimate Beginners Guide for Neural Networks, Algorithms, Random Forests, and Decision Trees made simple
- Pattern Recognition and Machine Learning (Information Science and Statistics)
- Hands-on Machine Learning with Scikit-Learn and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems
- The Elements of Statistical Learning: Data Mining, Inference and Prediction 2nd Edition (Springer Series in Statistics)
[Related Article: Top 10 Machine Learning Books]
MindMajix Machine Learning Algorithms Course
MindMajix’s Machine Learning Algorithms course takes a deep dive into the Machine Learning concepts yet provides all the needed nitty-gritty details that one requires for a better understanding of the subject altogether. The course is carefully designed to provide the best of the background for the newcomers from various other development areas or genres of work. It also imbibes the values that Machine Learning provides to our real-world problems. Having said that, it also introduces you to the available classification of machine learning methodologies.
On the other hand, it also details out the topmost algorithms that find its usage in the Machine Learning use cases and gives the most useful learnings from the real world. Practical examples, use cases, and scenarios when and why each of these algorithms is used give the audience the best of knowledge for their specific use cases. These details can be used as a base and then the necessary learning can be put to use. Each of these examples that are discussed provides the details of how these algorithms are implemented as well.
To be abreast with the current market trends, we could choose either R or Python for the needed development of use cases along with Machine Learning. Due to the prominence that Python has over R, this course has carefully jotted down the use of Python in these and explained with necessary code snippets and diagrams to provide better visualization of the use case and also the solution.
[Related Article: Comparing R Language vs Python]
Conclusion:
In this article, we have tried to understand the importance of Machine Learning and also what benefits it could bring to your organization. Machine Learning has the ability to scale based on your organization’s requirements and also provides you with the much-needed automation in all the required processes. Its benefits to your organization increase multiple folds when you continuously refine based on the data that is provided as input, and based on your business objectives, the outcome is achieved.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Machine Learning Training | Jul 25 to Aug 09 | View Details |
| Machine Learning Training | Jul 28 to Aug 12 | View Details |
| Machine Learning Training | Aug 01 to Aug 16 | View Details |
| Machine Learning Training | Aug 04 to Aug 19 | View Details |

Ravindra Savaram is a Technical Lead at Mindmajix.com. His passion lies in writing articles on the most popular IT platforms including Machine learning, DevOps, Data Science, Artificial Intelligence, RPA, Deep Learning, and so on. You can stay up to date on all these technologies by following him on LinkedIn and Twitter.






