- Home
- Blog
- Apache Solr
- What is Apache Solr

Solr is an open-source application, and it helps in building search applications. Fast, scalable, and enterprise-ready are all qualities of Solr. It exposes Lucene Java APIs as REST-Full services. One can put documents in it (called indexing) via XML, JSON, CSV, or binary over HTTP, create the via HTTP GET, and receive XML, JSON, CSV, or binary results.
Due to its ability to index, search, and deliver recommendations for relevant information depending on the taxonomy of the search query, Solr is a popular search platform for websites. Additionally, its ability to index and search documents and email attachments makes Solr another well-known search engine for workplace searches.
If you are curious to learn about Apache Solr keep reading, below is a detailed study about the same.

| Table of Contents: What is Apache Solr |
Why is Apache Solr popular?
- Solr for end users: Searched results can be presented in several dimensions, which makes the search effective for end users. Apache Solr provides a distinctive feature for searching. For example, if we are trying to buy a camera, the Apache Solr will provide information based on a product's various factors, such as camera resolution, dimensions, etc.
- Strong Full-Text Search: Apache Solr offers a robust full-text search function. In addition to standard search, Solr users can search certain fields, such as 'error id: severe'. In the queries, Apache Solr accepts wildcards. All terms in the field in which it is used will match a search pattern that contains one or more asterisks, such as 'book title:*'.
- Results in ranking, pagination, and sorting: Many rich document file types, including HTML, Word, Excel, Presentations, PDF, RTF, Email, ePub formats, the.zip file format, and many more, can be indexed by Apache Solr search. You can combine various packages, including Lucene and Apache Tika. When these documents are uploaded to Apache Solr, Solr parses them and creates an index for searching. By developing customer handlers or adapters, Solr can also be enhanced to support additional formats. With the help of this capability, Apache Solr can function at its best for businesses handling various data kinds.
- Comprehensive Administration Interfaces: One can perform administration actions like managing logs, adding, deleting, editing, or querying documents using Solr's integrated responsive user interface.
- Extensible architecture for plugins: Index and query time plugins are simple to add using Solr's extension points.
- Provides Facets for better browsing experience: Apache Solr provides facets to improve the surfing experience and assist users in filtering their search results using various factors. It offers context-specific, schema-driven facets that make it easier for users to find more information quickly. Based on the attributes of the schema that is defined before setting up the instance, Solr facets can be built. Although Apache Solr uses a user-defined schema, it gives users flexibility in the schema through dynamic fields, allowing them to interact with dynamic content.
| Want to become a certified Apache Solr Professional? then Enrol here to get Apache Solr Training & Certification Course from Mindmajix |
Applications of Apache Solr
- Intranet Portal: It provides easy access to search, application launching, news, and event notification and has a single sign-on authentication feature for security.
- Federated Client: Solr simplifies presentation, helps search across all content, has authorized access only, and allows document viewing.
- Multilingual Support: Solr and Lucene support a wide range of languages in addition to English, including Chinese, Japanese, Korean, Arabic, German, French, Spanish, and many more. It contains built-in language identification and offers text analysis tools appropriate for each language.
- Embedded in PLM (Product Lifecycle Management) Application: Solr provides a late binding security model, and document actions are open and exposed on the toolbar.
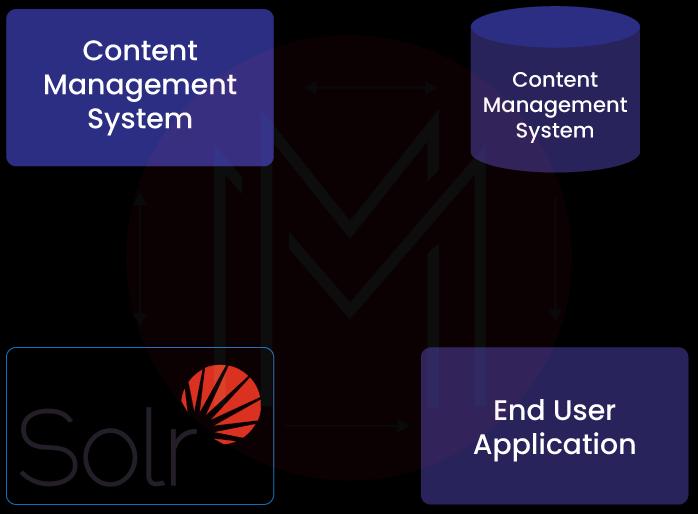
Solr Working
Step 1: Indexing
Solr uses fields to index a document. Data is first put through a field analyzer, where Solr uses char filters, tokenizers, and token filters to make the data searchable before it is uploaded to the index. The string as a whole can change as a result of char filters. Tokenizers divide field data into lexical units, or tokens, which are then sent through filters that determine whether to maintain, change (such as by changing all of the data's case or eliminating word stems), delete, or even create new tokens. These last tokens are searched or added to the index at query time.
Step 2: Querying
Search phrases may include everything from keywords to photos to geographical information. For example, when a query is sent, Solr processes it using a query request handler (also known as a "query handler" ), which works similarly to an index handler except that it retrieves documents from the Solr index rather than posting them.
Step 3: Ranking the Results
The aptest hits are displayed at the top of the matched documents as Solr matches indexes documents to a query and rank the results based on relevance scores.
Components of Apache Solr
- Query: The queries we must send to Solr are parsed by the query parser. It validates our query to look for syntactical mistakes. The queries are translated into a format that Lucene is familiar with after being parsed.
- Request Handler: The request handler processes the requests sent to Apache Solr. The request could be for an index update or a query. You must choose the request handler based according to your needs. Map the handler to a specific URL end-point to send a request to Solr.
- Response Writer:A response writer will produce prepared outputs for input queries. It supports several formats, including XML, JSON, and CSV. For various types of requests, you might have different response writers.
- Update Handler: An update request sent to Apache Solr is processed by several plugins, including signature, logging, and indexing. The update request processor is the name of this procedure. The update handler is also in charge of changes like adding or removing fields, etc

| Related Article: Apache Solr Interview Questions |
How is Solr scalable?
Solr collects organized, semi-structured, and unstructured data from various sources, stores and indexes it, and then make it quickly searchable. You may perform a faceted product search, log/security event aggregation, social media analysis, and other analytical tasks with Solr are analytical features.
In what is known as master-slave mode, Solr can handle a lot of data, but SolrCloud mode also supports further scaling through clusters.
A rich collection of basic capabilities in Solr's search platform allows you to enhance the user experience and underlying data modeling. Solr is a stable, dependable, and fault-tolerant search platform. Spell checking, geospatial search, faceting, or auto-suggest are a few functionalities that contribute to a positive user experience. Backend developers may profit from features like joins, clustering, the ability to import rich document formats, and many other features.
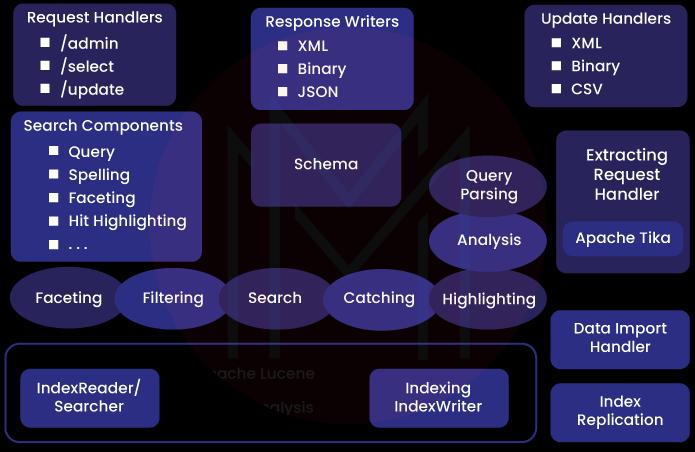
Apache Solr Architecture
- The J2EE-based Apache Solr application uses the Apache Lucene libraries internally to create the indexes and offer a user-friendly search.
- It is a client-server paradigm, and the Apache Solr instance can run on a single or several cores. However, the search access pattern may vary when using a multicore.
- Earlier versions of Apache Solr only had one core, which restricted users to using a single schema and configuration file to operate Solr across several applications. Later, it was possible to create several cores.
- One can run a single Solr instance for numerous schemas and configurations with unified administrations due to this feature. Apache Solr can operate in a distributed fashion for high availability and scalability requirements.
- The whole functionality of Solr can be separated into four logical layers. Index and configuration metadata management falls under the purview of the storage layer.
- The application package that runs on top of the J2EE container is known as the container and is the J2EE container on which the instance will execute.
- The request handler contacts the query parser based on the request.
- The task of processing and transforming the queries into Lucene query objects falls on the query parser. There are various parser kinds available. The index searcher receives a query once it has been parsed. The index reader is responsible for executing queries against the index store and compiling the response writer's information.
Conclusion
Apache Solr is an open-source search engine with a REST-API called Apache Solr. Yonik Seeley created Apache Solr at CNET as an internal business project.
Some of the crucial parts of Apache Solr are queries, request handlers, request writers, and update handlers. Apache Solr helpful applications include Intranet Portals, Federated Clients, Instrument Datasets, Regulatory Documents, and Embedded PLM Applications. The primary benefit of Apache Solr is that it shortens the time it takes to find information. Some of Apache Solr's scopes are quick lookups and intriguing text search improvements. Scalability makes it convenient across numerous servers, and web service for indexing and searching with clean deployment allows suggested content blocks determined by a node's taxonomy.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| SOLR Training | Jul 18 to Aug 02 | View Details |
| SOLR Training | Jul 21 to Aug 05 | View Details |
| SOLR Training | Jul 25 to Aug 09 | View Details |
| SOLR Training | Jul 28 to Aug 12 | View Details |

Madhuri is a Senior Content Creator at MindMajix. She has written about a range of different topics on various technologies, which include, Splunk, Tensorflow, Selenium, and CEH. She spends most of her time researching on technology, and startups. Connect with her via LinkedIn and Twitter .














