
To ease the above processes, Michael DeHaan developed an IT engine, Ansible. After some years, Red Hat acquired the Ansible tool in 2015. To use the Ansible tool smoothly, a user needs to be good at running commands in the Linux shell. Having sound knowledge of Linux can be considered a prerequisite for using the Ansible tool.
The Ansible tool is generally an open-source IT engine or tool that automates various application deployments, cloud provisioning activities, intra-service orchestration, etc. Not having any need for an agent or custom security on the client side is regarded as a big advantage of using Ansible.
It is created for multi-tier deployment and it is easy to use as it is completely agentless. It simplifies the process of connecting to clients by using SSH-Keys. When we create an inventory file in which clients’ details like IP addresses, hostnames, and SSH port details are stored, it can connect by using the details.
Ansible describes and carries out automation tasks by using the playbook. The playbook uses a simple language, Yet Another Markup Language (YAML). This language is easily readable and understandable by humans and is mainly used for configuring files but it can be used in various applications where data storage is involved.
It is free of cost so it became very popular soon. Another benefit of using the Ansible tool is the playbook can be read and debugged if needed by IT support staff.
Ansible manages and stores the inventory in the form of simple text files. It connects to your (system) nodes and then pushes small programs, generally known as Ansible Modules to the nodes. It runs the modules on the nodes and removes them when the process is finished
Ansible Tutorial for Beginners
| In this Ansible Tutorial, You will Learn the following topics |
What is Ansible
To deploy applications, do cloud provisioning and manage other Information Technology tools, any agent or custom security is required on the client-side. It is not always possible and easy to have these requirements to run and manage applications. There was a need to have an application or IT engine that can help us perform these functions without the need for any agent or custom security on the client-side.
Ansible Architecture
An Ansible user writes the playbook and interacts with the Ansible orchestration engine to execute the Ansible orchestration. The Ansible tool interacts with configuration management databases and public or private cloud. The below diagram shows the Ansible architecture.
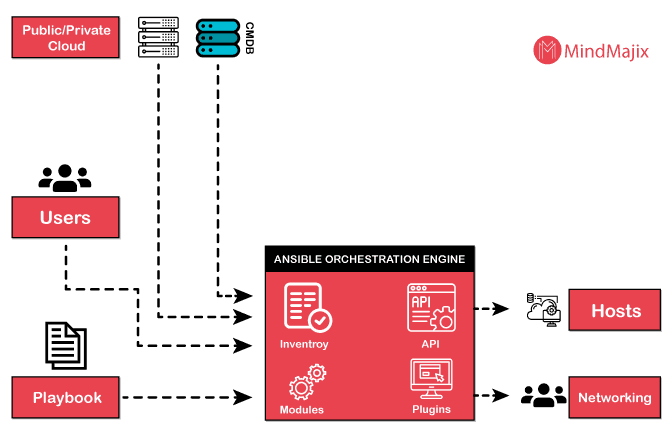
Below is the description of the Ansible architecture:
- Playbook: Users write the playbook so it consists of written codes. Codes are written in YAML format (as it is easy to use). The playbook describes the tasks and executes them through Ansible. The tasks can be launched synchronously and asynchronously with the playbook.
- Cloud: It is a network of remote servers that are used to store, process, and manage data. The servers are hosted on the internet and are remote. The data is stored remotely, not on physical servers.
- CMDB: CMBD acts as a data warehouse for IT installations and is a type of repository.
- Inventory: It consists of lists of nodes having IP addresses, servers, databases, etc. They are managed by inventory.
- API: It works as a transport for private or public cloud services.
- Modules: When the Ansible tool connects the nodes, Modules are executed on the client side and removed after completion by the Ansible tool. They can reside on any machine without the need for any server or database. Users can keep track of changes in the content while working with the text editor or version control system.
- Plugins: Plugins are generally considered the core functionality of the Ansible tool. There are many useful plugins and they can be written easily as users want.
- Hosts: Hosts are generally nodes that are automated by the Ansible tool and other machines such as Linux, RedHat, Windows, etc.
- Networking: Ansible uses a powerful & automated networking system. It can manage automation of different networks as it uses a secure, simple and agentless framework for IT installation and operations.
[Related Article: Accenture Interview Questions]
Ansible Workflow
Ansible connects to your nodes and runs a small program called Ansible modules on the client side. After running the modules, it removes them. These Ansible modules can reside on any machine and do not require any database or server.
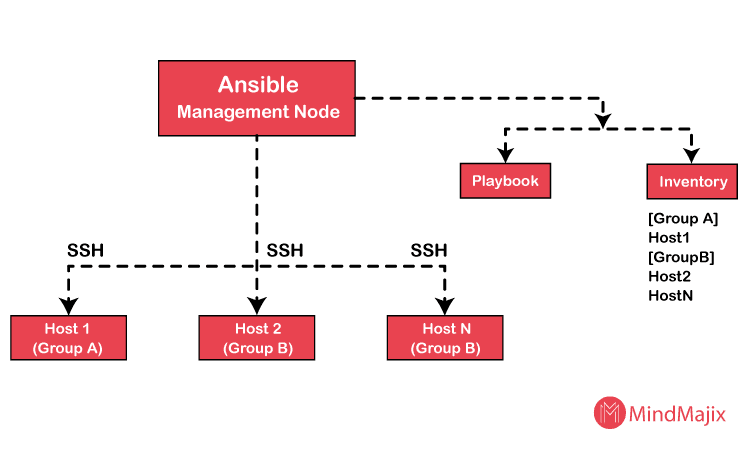
Workflow:
Ansible Management Node plays the most important and crucial role in the whole operation of Ansible. It gets the lists of hosts where the Ansible modules are to be run from the Inventory. Ansible Management Node manages and controls all the executions perfectly and remotely. After getting the list of hosts from the Inventory, Ansible Management Node then connects with the hosts through SSH connections and runs the modules. After the successful execution of modules, it removes them.
Ansible Inventory
Ansible Inventory can be defined as a group of lists of hosts, servers, IP addresses, etc. and it is used to manage multiple hosts or groups in a single point of time. The inventory needs to be defined first to execute the workflow. Users can edit or write the inventory as per their needs.
The (default) location of inventory is a file: /etc/ansible/hosts. A different inventory can be specified in the command line using -i<path> option. To work smoothly, the Ansible tool has many Inventory plugins. Users can pull the Inventory file from private clouds or public clouds by using different formats like (YAML & INI).
| Want to become a Certified Ansible Specialist, then enroll in our “Ansible Online Training”. This course will help you to achieve excellence in this domain. |
Groups & Hosts
As given above, the default location is /etc/ansible/hosts. Hosts are in INI format in the below example. Headings in the bracket are considered as group names used for classifying the systems. Systems can be put in more than one group. Two servers are given (webservers & dbservers) below.
Examples:
[webservers]
abc.example.com
[dbservers]
ball.example.com
Host variables: Variables can be assigned to the hosts and they are used in the playbook.
Examples:
[atlanta]
Host1 http_port=50 maxRequestsPerCase=505
Host2 http_port=450 maxRequestsPerCase=495
Group variables: Application of variable to a group or more can be done at once.
Examples:
[atlanta]
host1
host2
[atlanta:vars]
proxy=proxy.atlanta.example.com
ntp_server=ntp.atlanta.example.com

Ansible Vault
There is a lot of sensitive data that should be protected by encryption. The sensitive data may include passwords, usernames, important data, etc. The Ansible Vault plays an important part in securing the data on the Ansible tool. It effectively encrypts the data so that Ansible can decrypt it with the help of the key at runtime. It helps users to keep their data safe and protected with the help of encryption. Ansible vault provides the key to decrypt to Ansible to run the vault-encrypted content at runtime.
File-level granularity is implemented by Ansible Vault so the files are either encrypted or unencrypted entirely. It uses an algorithm (AES256) to provide a single password for decryption. A single password is used to do both encryption and decryption of content and it makes it easy to use. Ansible can identify any vault-encrypted data while executing a task.
Encryption & Decryption:
Encryption: First, a user needs to choose a password for encrypting any existing file.
Creating an encrypted file: Ansible vault is used to encrypt a file. Create & confirm a password for encryption and decryption after choosing a file name. Below is the command for creating an encrypted file -
$ansible-vault create <file name>
Decryption: After encryption, the key is sent by the Ansible vault to the Ansible tool. The key is to be entered to decrypt the content or file to extract the encrypted data.
Decrypting an encrypted file: To decrypt an encrypted file, the Ansible vault decryption key or command is used by using the following command - $ansible-vault decrypt <file1> <file2> <file3>
- There are various other commands used to perform other functions using Ansible Vault that can be learned by referring to the official Ansible documentation.
| Related Article: Frequently Asked Ansible Interview Questions & Answers |
Ansible vs Chef
Ansible is mainly used for automating application deployment, cloud provisioning, etc.
The chef is an automated platform used to transform infrastructure into code. It automates the deployment, configuration, and management of the infrastructure across a network. It is an open-source cloud configuration that can translate tasks related to system administration into reusable definitions also known as cookbooks and recipes. The chef can run on various platforms like Windows, Solaris, Nexus, etc. and it also supports other cloud platforms like AWS, Microsoft Azure, etc.
Some differences between Ansible & Chef are listed below based on different parameters.
| Parameters | Ansible | Chef |
| Configuration language | YAML (Python) language is used in Ansible because it is very easy to learn and use. Mostly all Unix and Linux deployments have Python inbuilt which makes it easier to use. | Chef uses a developer-oriented language called Ruby Domain Specific Language (DSL). |
| Availability | Ansible can run with a single active node but if it does not work, a second node becomes active instead of that node. | The chef usually runs on a primary chef-server. If the primary chef-server fails, a secondary server becomes active and works instead of the primary server. |
| Ease of setting up | Since Ansible is an agentless tool, there is only a master running on the server. As it uses SSH connection to login to the client system (nodes), the client machine does not require any additional setup so setting it up is quicker. | A Master-agent architecture is present in Chef. Chef server is run on the master machine and the Chef client is run on a client machine as an agent. It is difficult to set up as it also has an additional component known as a workstation which contains all tested configurations |
| Management | As Ansible uses YAML, it is easy to manage. It has quick remote execution so it is mostly suitable for real-time applications because the server pushes applications to the nodes. | As Chef uses Ruby DSL, strong programming knowledge is required to use and manage it. The clients need to pull the configuration from the server in Chef. |
| Interoperability | Though it supports Windows & Linux/Unix, the Ansible server has to be on Unix/Linux machines. | Though workstation and Chef client can be used on Windows & Linux/Unix, the Chef server operates on only Linux/Unix machines. |
| Authoritative configuration | It derives its authoritative configurations from the deployed playbooks that serve as perfect source-control systems so it is more accessible. | It derives its authoritative configuration from the Chef server that requires cookbooks to be uploaded so Chef is identical and consistent. |
| Pricing | The cost for Ansible tower up to 100 nodes is $10,000 per year including 8*5 support for standard IT operations. The premium service offers 24*7 service support for $14,000 per year. | The cost of operation and deployment of Chef is $137/ node for a year. |
Ansible supports the task of setting up and maintaining remote servers but there are certain commands that are used to operate it. The collection of these commands most commonly used is called Ansible Cheat Sheet.
Some of the most common commands used in the Ansible tool are listed below.
- For testing Connectivity to nodes: $ ansible all -m ping
- For connecting as a different user: $ ansible all -m ping -u danny
This also applies to the playbook: $ ansible playbook myplaybook.yml -u danny
- For using a custom SSH key to connect to a remote server: $ ansible all -m ping --private-key=~/.ssh/custom_id
This also applies to the playbook: $ ansible playbook myplaybook.yml --private-key=~/.ssh/custom_id
- For using password-based authentication: $ ansible all -m ping --ask-pass
This applies to the playbook too: $ ansible playbook myplaybook.yml --ask-pass
- For running playbooks: $ ansible-playbook myplaybook-yml
- For editing an encrypted file: $ ansible-vault edit credentials.yml
Above are some of the commands but for more cheat-sheet commands, please refer to the Ansible official documentation.
Advantages of Ansible
Some of the advantages of using the Ansible tool is given below
- It is completely free of cost.
- It is very easy to set up & use.
- It is flexible and compatible with many systems and operating systems.
- It does not involve any agent because it is agentless.
- It is more efficient in performing tasks.
- It is more powerful and faster as it can handle complex IT functions easily.
Are you looking to get trained on Ansible, we have the right course designed according to your needs. Our expert trainers help you gain the essential knowledge required for the latest industry needs. Join our Ansible Certification Training program from your nearest city.
| Visit here to learn Ansible Online Training in Bangalore |
These courses are equipped with Live Instructor-Led Training, Industry Use cases, and hands-on live projects. Additionally, you get access to Free Mock Interviews, Job and Certification Assistance by Certified Ansible Trainers
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Ansible Training | Aug 04 to Aug 19 | View Details |
| Ansible Training | Aug 08 to Aug 23 | View Details |
| Ansible Training | Aug 11 to Aug 26 | View Details |
| Ansible Training | Aug 15 to Aug 30 | View Details |

Ravindra Savaram is a Technical Lead at Mindmajix.com. His passion lies in writing articles on the most popular IT platforms including Machine learning, DevOps, Data Science, Artificial Intelligence, RPA, Deep Learning, and so on. You can stay up to date on all these technologies by following him on LinkedIn and Twitter.














