- Home
- Blog
- Apache Certification Courses
- What is Apache Spark - The Definitive Guide

The most commonly utilized scalable computing engine right now is Apache Spark. It is used by thousands of companies, including 80% of the Fortune 500. Apache Spark has grown to be one of the most popular cluster computing frameworks in the tech world. Python, Scala, Java, and R are among the programming languages supported by Spark. We shall learn what Apache Spark is in-detail in this blog.
| Table of Contents - Apache Spark |
What Is Apache Spark?
Apache Spark is a cutting-edge cluster computing platform that is optimized for speed. It is based on Hadoop MapReduce and extends the MapReduce architecture efficiently for a broader range of calculations, such as interactive queries and stream processing. Spark's key feature is in-memory cluster computing, which boosts an application's processing speed.
Spark is built to handle various tasks, including batch applications, iterative algorithms, interactive queries, and streaming. Apart from supporting all of these workloads in a single system, it also alleviates the administrative effort of maintaining many tools.
| If you want to enrich your career and become a professional in Apache Spark, then enroll in "Apache Spark Training" - This course will help you to achieve excellence in this domain. |
Why Spark?
Spark is used to cache data in memory across multiple parallel operations; it is much faster than MapReduce, which requires more disc reading and writing. Spark runs multi-threaded jobs within JVM processes, whereas MapReduce runs heavier-weight JVM processes. Spark has a faster startup time, higher parallelism, and better CPU utilization today. Spark uses a more robust functional programming method than MapReduce. Spark is particularly well-suited to iterative algorithms that process large amounts of data in parallel.
History of Apache Spark
Matei Zaharia created Spark in 2009 as a Big Data Analytics research project at UC Berkeley's AMPLab. The framework was created with the primary purpose of overcoming MapReduce's inefficiencies. Despite its enormous success and widespread acceptance, MapReduce could not be used for a wide range of issues. For multi-pass applications requiring low-latency data sharing across numerous concurrent operations, MapReduce is inefficient.
Apache Spark vs. Hadoop
Both Apache Hadoop and Apache Spark are open-source big data processing frameworks with significant vital distinctions. Hadoop processes data using MapReduce, whereas Spark uses robust distributed datasets (RDDs). Hadoop uses a distributed file system (HDFS), which allows data to be stored on several machines. The file system is scalable because servers and devices may be added to accommodate growing data quantities. Because Spark lacks a distributed file storage system, it is mainly utilized for computation on top of Hadoop. Spark does not require Hadoop to run, although it can generate distributed datasets from HDFS files.
Key Components of Apache Spark
Spark Core, Spark SQL, Spark Streaming, MLlib, GraphX, and Spark R are the components of the Apache Spark framework. Spark Core Engine can be combined with any of the other five features. All of the Spark components do not have to be used simultaneously. Depending on the use case and application, one or more can be combined with Spark Core. Let's take a closer look at each one.
Spark Core
- Spark Core powers the Apache Spark framework. Spark Core is the execution engine for the Spark platform, and it is required and used by other components that are developed on top of it.
- Spark Core has built-in memory computation and can reference datasets from external storage systems.
- Spark is in charge of all essential I/O functions, scheduling, monitoring, and so on.
- Spark Core also performs critical operations such as fault recovery and memory management.
- The RDD is a unique data structure used by Spark Core. Because of the serialization and deserialization of I/O stages, data sharing in distributed processing systems like MapReduce requires the data to be saved in intermediate phases and then retrieved from permanent storage like HDFS or S3, which makes it highly slow.
- RDDs solve this problem since they are in-memory and fault-tolerant data structures shared across multiple jobs inside the same Spark session.
| Check out Apache Spark vs Apache Storm |
Spark SQL
- Spark SQL, Apache Spark's 'go to' tool for unstructured data, supports querying data using SQL and Hive Query Language, Apache Hive's version of SQL (HQL).
- It also accepts data from various sources, including parse tables, log files, and JSON.
- In Python, Java, Scala, and R, Spark SQL enables programmers to combine SQL searches with programmed updates or manipulations supported by RDD.
- The primary abstraction in Spark SQL is DataFrame. A DataFrame is a distributed collection of data organized into named columns in Spark. DataFrames were previously known as SchemaRDDs in previous versions of Spark SQL.
- Spark's DataFrame API works hand-in-hand with procedural code to provide seamless integration between procedural and relational processing. To assist relational optimizations and optimize the overall data processing workflow, DataFrame API analyses operations slowly.
- The SparkSQL or HiveContext context can encapsulate all relational functionalities in Spark.
Spark Streaming
- Tathagat Das and Matei Zaharia are the primary maintainers of this Spark library. This library is for streaming data, as the name implies.
- This is a popular Spark library because it boosts the speed of Spark's enormous data processing power. Gigabytes per second can be streamed with Spark Streaming.
- This ability to process large amounts of data quickly has potential. Spark Streaming is a technique for analyzing data in a continuous stream.
- Spark streaming may communicate with several different data sources. So we may either listen to a port that is receiving a lot of data or connect to data sources like Amazon Kinesis, Kafka, Flume, and so on.
- Spark can be connected to these sources using connectors. Spark streaming has the advantage of being consistent. It uses a technique known as "checkpointing" to save state to disc regularly, and depending on the data sources or receivers we're using, it can even pick up data at the point of failure.
MLlib(Machine learning library)
- Many businesses focus on developing customer-centric data goods and services, requiring machine learning to create predictive insights, suggestions, and tailored outcomes.
- Data scientists can handle these difficulties with popular programming languages like Python and R. Still; they must invest a significant amount of time setting up and maintaining the infrastructure for these languages.
- Spark provides built-in support for leveraging clusters to perform machine learning and data science at scale. The library’s name is MLLib, which stands for Machine Learning Library.
- MLlib is a machine learning library written in C. It may be accessed using Java, Scala, and Python. It's easy to use, scalable and integrates various other tools and frameworks.
- MLlib makes it easier to deploy and construct scalable machine learning pipelines.
GraphX
- GraphX is useful for providing general information about a graph network, such as counting the number of triangles in the graph and using the PageRank algorithm.
- It can assess a graph's "connectedness," "degree distribution," "average path length," and other high-level metrics. It can also swiftly link graphs together and change them. It also enables traversing a graph using the Pregel API.
- Spark Resilient Distributed Graph (RDG- an abstraction of Spark RDD's) is a feature of GraphX. Data scientists utilize RDG's API to execute various graph operations using different computational primitives.
- Basic operators in property graphs are similar to RDDs, such as maps and filters. These operators create new graphs from UDFs (user-defined functions). Furthermore, these are made with altered qualities and structures
Spark R
- Due to its simplicity and capacity to perform sophisticated algorithms, the R programming language is frequently used by data scientists. On the other hand, R has the drawback of having a single node for data processing.
- As a result, R is unsuitable for large-scale data processing. SparkR, an R package for Apache Spark, is used to tackle the problem.
- SparkR provides a data frame implementation that allows for selection, filtering, and aggregation operations on distributed large datasets.
- SparkR now includes Spark MLlib, which allows for distributed machine learning.

Advantages of Apache Spark
Apache Spark has changed the world of Big Data. Apache Spark is a particularly appealing extensive data framework because of its numerous benefits. Apache Spark has a lot of potential in the area of big data. Now, let's look at some of Apache Spark's most prevalent advantages:
Speed
Processing speed is critical when dealing with large amounts of data. Because of its speed, Apache Spark is extremely popular among data scientists. For large-scale data processing, Spark is 100 times faster than Hadoop. Hadoop stores data in local memory space, whereas Apache Spark employs an in-memory (RAM) computing environment. Spark can manage multiple petabytes of clustered data from over 8000 nodes at any time.
Ease of Use
For working with massive datasets, Apache Spark provides simple APIs. It has around 80 high-level operators that enable parallel app development simple.
The image below depicts the significance of Apache Spark.
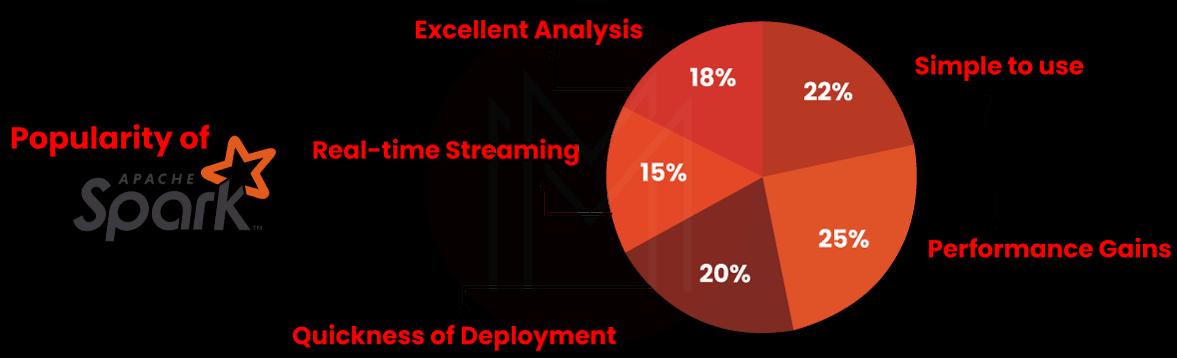
Advanced Analytics
'MAP' and reduce aren't the only things Spark can do. Machine learning (ML), graph algorithms, streaming data, SQL queries, and other features are also available.
Dynamic in Nature
You can create similar apps quickly with Apache Spark. Over 80 high-level operators are available from Spark.
Multilingual
Python, Java, Scala, and other programming languages are all supported by Apache Spark.
Apache Spark is powerful.
Apache Spark can handle various analytics tasks because of its low latency in-memory data processing. It comes with well-designed graph analytics and machine learning libraries.
Increased access to Big data
Apache Spark is transforming massive data and making it more accessible. According to a recent IBM poll, the company plans to train over 1 million data engineers and data scientists on Apache Spark.
Demand for Spark Developers
Apache Spark is beneficial not only to your company but also to you. Spark developers are in such high demand that firms offer attractive bonuses and flexible work schedules only to hire Apache Spark expertise. The average income for a Data Engineer with Apache Spark expertise is $100,362, according to PayScale. People interested in a career in big data technologies should understand Apache Spark.
Open-source community
The best part about Apache Spark is that a sizeable open-source community backs it.
| Read these latest Apache Spark Interview Questions and Answers that help you grab high-paying jobs |
Use Cases of Apache Spark in Real Life
Many enterprises use Apache Spark to boost their business insights. These businesses collect terabytes of data from their customers and utilize it to improve their services. The following are some examples of Apache Spark use cases:
E-commerce
Many e-commerce firms use Apache Spark to improve their customer experience. Several companies use a spark to achieve this goal, including:
eBay
eBay uses Apache Spark to provide customers with discounts or offers based on previous purchases. This improves the consumer experience, but it also aids the organization in delivering a seamless and efficient user interface.
Alibaba
Alibaba is the world's largest employer of Spark employment. These occupations include analyzing extensive data, while others involve picture data extraction. These elements are represented on a big graph, and the results are calculated using Spark.
Healthcare
Apache's Medical Services Many healthcare organizations are using Spark to improve the services they give to their consumers. MyFitnessPal, a firm that helps individuals live healthier lives via nutrition and exercise, is one of the companies that use Spark. MyFitnessPal was able to scan through the food calorie data of around 90 million users using Spark, which assisted it in identifying high-quality food products.
Media and Entertainment
Some video streaming services employ Apache Spark and MongoDB to serve up appropriate adverts to their users depending on their previous behavior on the site. Netflix, for example, one of the most prominent participants in the video streaming market, uses Apache Spark to propose shows to its subscribers based on what they've already seen.
Conclusion
We’ve covered every facet of Apache Spark and its usage in this blog. We hope this is useful in gaining a firm understanding of Apache Spark.
Related Article:
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Apache Spark Training | Jul 18 to Aug 02 | View Details |
| Apache Spark Training | Jul 21 to Aug 05 | View Details |
| Apache Spark Training | Jul 25 to Aug 09 | View Details |
| Apache Spark Training | Jul 28 to Aug 12 | View Details |

Madhuri is a Senior Content Creator at MindMajix. She has written about a range of different topics on various technologies, which include, Splunk, Tensorflow, Selenium, and CEH. She spends most of her time researching on technology, and startups. Connect with her via LinkedIn and Twitter .














