
- 6 Hot And In-Demand Tech Areas In 2024
- How To Forward Your Career With Cloud Skills?
- Top 7 On-Demand IT Certifications
- Most In-demand Technologies To Upskill Your Career
- Top 10 Hottest Tech Skills to Master in 2024
- Top Skills You Need to Become a Data Scientist
- Groovy Interview Questions
- Facets Interview Questions
- Crystal Reports Tutorial
- VAPT Interview Questions
- Flutter Tutorial
- Saviynt VS Sailpoint
- Flutter vs Xamarin
- PingFederate Interview Questions and Answers
- Dart vs Javascript : What's the Difference?
- Terraform Private Registry
- Cylance Interview Questions and Answers
- Sophos Interview Questions and Answers
- Top Camunda Interview Questions
- NUnit Interview Questions and Answers
- Impala Interview Questions and Answers
- ETL Tutorial
- Ionic Interview Questions
- Grafana Tutorial
- What is VAPT? - A Complete Beginners Tutorial
- SnapLogic Interview Questions
- Saviynt Interview Questions
- What is PingFederate? - A Complete Beginners Tutorial
- SnapLogic Tutorial
- Grafana Interview Questions
- RHCE Interview Questions and Answers
- Web Services Interview Questions
- Domo Interview Questions and Answers
- Terraform Interview Questions
- What is Sophos? | Sophos Turorial for Beginners
- Top Servlet Interview Question And Answers
- NLP Interview Questions and Answers
- Microsoft Intune Interview Questions
- Top XML Interview Questions And Answers
- Tosca Commander
- Katalon vs Cypress
- SQLite Tutorial
- Tosca Tutorial - A Complete Guide for Beginners
- Xamarin Interview Questions and Answers
- UiPath vs Automation Anywhere - The Key Differences
- OpenShift Interview Questions
- What is Katalon Studio - Complete Tutorial Guide
- Kronos Interview Questions
- Tosca Framework
- Burp Suite Tutorial
- Mendix Interview Questions
- Power Platform Interview Questions
- Burp Suite Interview Questions
- What is Mendix
- What is Terraform ?
- Burp Suite Alternatives
- Dart vs Kotlin
- What is Kronos?
- ES6 Interview Questions
- Entity Framework Interview Questions
- COBOL Interview Questions
- Express JS Interview Questions
- OSPF Interview Questions
- LINQ Tutorial
- CSS3 Interview Questions and Answers
- Auth0 Tutorial
- MS Access Interview Questions
- What is SPARQL - A Complete Tutorial Guide
- ExpressJS Tutorial
- UML Tutorial
- HTML vs XML
- Cypress vs Jest
- Impacts of Social Media
- OWASP Interview Questions
- Security Testing Interview Questions
- OpenShift vs Docker
- ES6 Tutorial
- Spark SQL Interview Questions
- What is OWASP?
- AppDynamics Interview Questions
- Dynatrace Interview Questions
- Rest Assured Tutorial
- New Relic Interview Questions
- REST API Tutorial
- Datadog Interview Questions
- Rest API Interview Questions
- Rest Assured Interview Questions
- PTC Windchill Interview Questions
- Easiest Tech Skills To Learn
- Python SQLite Tutorial - How to Install SQLite
- Datadog Tutorial - Datadog Incident Management
- What is AppDynamics - AppDynamics Architecture
- RabbitMQ Interview Questions And Answers
- What is Dynatrace
- Datadog Vs Splunk
- Web Developer Job Description
- JP Morgan Interview Questions
- Types of Corporate Training
- Benefits of Corporate Training
- What is Corporate Restructuring?
- Blended Learning in Corporate Training
- What is Corporate Level Strategy?
- Flutter Projects and Use Cases
- How to Become a Web Developer
- How To Install Keras?
- How to Install Flutter on Windows?
- How to Install Cypress on Windows?
- How to Become a Computer Scientist?
- How to Install Katalon Studio in Windows
- How to Become a Programmer
- OWASP Projects and Use Cases
- How to Install Sophos?
- Workato Tutorial
- Workato Tutorial - What is Workato?
Data scientists all across the world rely on Spark, an analytics engine, to handle their big data. It is based on Hadoop and can handle batch and streaming data types. Spark is widely used for processing massive data because it is high-speed open-source software.
Spark introduces Spark SQL, a programming component for handling structured data. It offers the DataFrame programming abstraction and functions as a distributed SQL query engine. Three key features of Spark SQL are available for handling structured and semi-structured data. The list of them is as follows:
- Spark SQL can read and write data in various structured formats, including parquet, hive tables, and JSON.
- Spark SQL gives Python, Java, and Scala a way to hide the details of a data frame. It makes it easier to work with organized data sets. SQL data frames are the same in Spark as tables in a relational database.
- SQL can be used to query the data, and it can be done both inside Spark programs and through third-party tools that link to Spark SQL.
Spark SQL's primary benefit is its ability to execute SQL queries. Datasets or data frames are the forms in which the results of a SQL query executed in another programming language are returned.
| Table of Content: Spark SQL Tutorial |
What is Spark SQL?
Spark SQL is an important part of the Apache Spark framework. It is mainly used to process structured data. It supports Python, Java, Scala, and R Application Programming Interfaces (APIs). Spark SQL combines relational data processing with Spark's functional programming API.
Spark SQL offers a DataFrame programming abstraction and may function as a distributed query engine (querying on different nodes of a cluster). It supports both Hive Query Language (HiveQL) and SQL querying.

| If you want to enrich your career and become a professional in Apache Spark, Enroll in our "Apache Spark Online Training" This course will help you to achieve excellence in this domain |
Why is Spark SQL used?
Spark SQL adds native support for SQL to Spark and simplifies accessing data stored in RDDs (Spark's distributed datasets) and other sources. Spark SQL makes it possible to blur the lines between RDDs and Spark sql relational data processing in spark tables. Unifying these powerful abstractions makes it simple for software developers to combine complicated analytics with SQL queries that query external data while still working inside the context of a single application. In particular, Spark SQL will make it possible for developers to:
- It is possible to import relational data from parquet files and hive tables.
- Execute SQL queries across the imported data as well as the RDDs that are already there.
- Creating hive tables or parquet files from RDDs is a breeze using this feature.
In addition, Spark SQL comes with columnar storage, cost-based optimizer, and code generation, all of which help to speed up query execution. At the same time, it is scalable to thousands of nodes and searches that take many hours by using the Spark engine, which offers complete fault tolerance during the middle of a query and eliminates the need to worry about using a different engine for historical data.
| Related Article: Apache Spark Tutorial |
How does Spark SQL work?
Let's see how Spark SQL works.
Spark SQL works in differentiating small lines between the RDD and relational table. It offers DataFrame APIs and connection with Spark code, providing considerably closer integration between relational and procedural processing. Spark SQL may be communicated using the DataFrame API and the Datasets API.
Apache Spark is now available to a broader audience due to Spark SQL, which enhances the platform's performance for its existing customers. DataFrame APIs are made available by Spark SQL, allowing relational operations to be performed on external data sources and on Spark's built-in distributed collections. It introduces catalyst, an extendable optimizer that helps handle various big data methods and data sources.
Spark is compatible with windows and systems similar to UNIX (e.g., Linux, Microsoft, Mac OS). It is simple to run locally on a single computer; all required have Java installed on your system's PATH, or the JAVA HOME environment variable refers to a Java installation. It's pretty simple to use in a local setting.

Spark Components
The Spark project comprises several different spark components that are carefully integrated. Spark is a computational engine that can simultaneously plan, distribute, and monitor numerous applications.
Let's get a comprehensive understanding of each Spark component.
- Spark SQL
- Spark Streaming
- GraphX
- MLlib
- Spark Core

Spark SQL
- Spark core serves as the foundation upon which constructed Spark SQL. It helps with structured data in several ways.
- It supports structured query language (SQL) queries and HQL (hive query language) queries, which are specific to apache hive.
- Also, it works with a wide range of data formats and formats, including hive tables, parquet, and JSON.
- It allows users to link Java objects to preexisting databases, data warehouses, and BI tools through JDBC and ODBC connections.
| Related Article: Spark Interview Questions |
Spark Streaming
- Take advantage of Spark Core's efficient scheduling features to do streaming analytics.
- It is possible to handle streaming data in a scalable and error-tolerant manner with the help of Spark's Spark Streaming component.
- Small data batches are accepted, and the data is then transformed using RDDs.
- Web server logs provide a real-world illustration of a data stream.
- It's designed so that code written to process streaming may quickly adapt data to analyze historical data in batches.
GraphX
- The creation of a directed graph that may have any characteristics linked to each vertex and edge is made more accessible by this feature.
- The GraphX library allows for the manipulation of graphs and the performance of calculations in a graph-parallel fashion.
- It offers various basic operators, such as subgraph, join Vertices, and aggregate Messages, which are used to edit graphs.
| Related Article: What is Apache Spark |
MLlib
- A machine learning library called MLlib has a collection of different machine learning algorithms.
- It is nine times quicker than Apache Mahout's disk-based version.
- MLlib includes testing hypotheses and performing correlations, as well as doing classification and regression analyses, clustering, and principal component analysis.
Spark Core
- The Spark core is at the center of Spark and is responsible for its fundamental operations.
- It contains the components necessary for scheduling tasks, recovering from errors, interfacing with storage systems, and managing memory.
| Related Article: Machine Learning With Spark |
Spark SQL features
Spark SQL has much functionality, which is why it is more popular than Apache Hive. The following are some of Spark SQL's features:
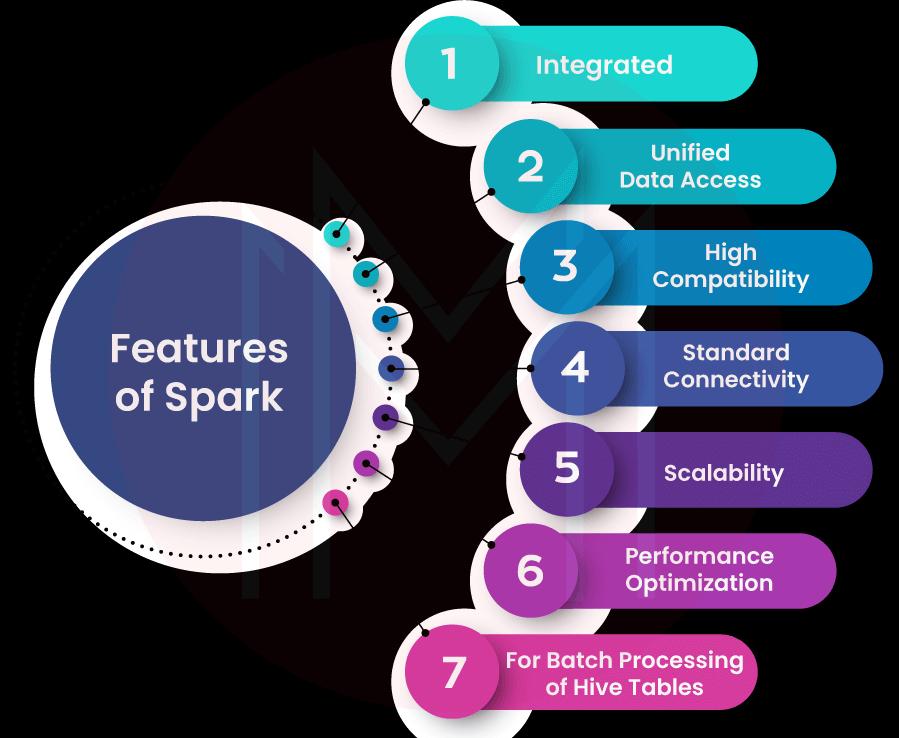
-
Compatibility with Spark
The Spark programs are readily compatible with the Spark SQL queries that may run on them. Using SQL or the DataFrame APIs, you may query the structured data inside these applications.
-
Shared Database Access
Data Frames and SQL share a similar method of accessing several data sources simultaneously. Spark SQL's standardized data access approach is a considerable aid to its many users.
-
Hive Compatibility
Spark SQL queries may execute on the data loaded as they were initially written. In addition, Spark SQL is compatible with altering the data stored in Hive's front end and meta store. The capability of relational processing that Spark SQL has fallen within the purview of its functional programming. Spark SQL is compatible with all of the many data formats that are currently available, including Apache HIVE, JSON documents, Parquet files, Cassandra, and others.
-
Connectivity
When connecting to Spark SQL via JDBC or ODBC, there is no need to worry about compatibility concerns. These are useful as a means of data communication and also as a tool for gaining business insight.
-
Performance & Scalability
Due to its in-memory processing capabilities, Spark SQL offers superior performance over Hadoop and allows for more iterations on datasets without sacrificing speed. Most queries may be executed quickly using Spark SQL in conjunction with a code-based optimizer, columnar storage, or code generator. Spark Engine is used for calculating the nodes. It uses extra data to read information from multiple sources and makes it easier to scale.
-
Data Transformations
Spark SQL's RDD API is quite helpful since it maximizes efficiency during transformations. These alterations may be performed using SQL-based queries, and the results are shown as RDDs. Spark SQL allows for more precise analysis of both structured and semi-structured data.
| Related Article: Top 5 Apache Spark Use Cases |
Spark SQL Functions
The following is a list of the many Spark SQL functions that are made available:
- Spark SQL String Functions
- Spark SQL Math Functions
- Spark SQL Window Functions
- Spark SQL Collections Functions
- Spark SQL Date and Time Functions
- Spark SQL Aggregate Functions
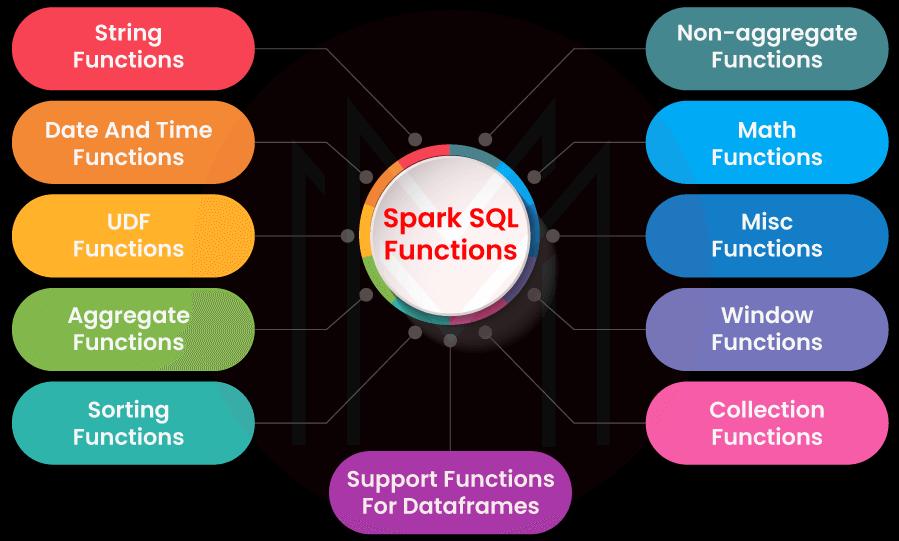
Now let's go into depth about each of those Spark features:
-
Spark SQL String Functions
"String functions" are functions that change the values of strings. You can use these functions to do many different things, like formatting text or doing math calculations. In spark SQL, the "string funcs" namespace is where all the String functions are kept.
The Spark SQL String functions include, but are not limited to, the ones shown below.
- length(e: Column): Column
- (sep: String, exprs: Column*): Column
- initcap(e: Column): Column
- instr(str: Column, substring: String): Column
- decode(value: Column, charset: String): Column
- encode(value: Column, charset: String): Column
-
Spark SQL Math Functions
Computations such as trigonometry (sin, cos, and tan), hyperbolic expressions, and other types of calculations need the usage of mathematical functions.
Some of the mathematical functions that Spark SQL uses. They are as follows:
- cosh(e: Column): Column
- sin ( e : Column ) : Column
- cosh(columnName: String): Column
- sin(columnName: String): Column
-
Spark SQL Window Functions
Window functions in Spark are used to conduct operations on vast sets of input rows, such as computing the rank and row number, Etc. By doing an import of "org.apache.spark.sql. "you'll get access to Windows.
Let's focus on some of Spark SQL's most practical Windows procedures.
- rank(): Column
- ntile(n: Int): Column
- dense_rank(): Column
- row_number(): Column
- cume_dist(): Column
-
Spark SQL Collections Functions
Collection Functions in Spark SQL are primarily used to carry out operations on arrays and groupings of data.
We'll look at some of Spark SQL's most useful Windows functions.
- arrays_zip(e: Column*)
- array_except(col1: Column, col2: Column)
- array_repeat(left: Column, right: Column)
- array_contains(column: Column, value: Any)
- array_remove(column: Column, element: Any)
- array_join(column: Column, delimiter: String)
- array_join(column: Column, delimiter: String, nullReplacement: String)
-
Spark SQL Date and Time Functions
The Spark Date and Time Functions are useful for tasks like calculating the number of days between two dates, returning the current date as a date column, or transforming a column into a "DateType" with a particular date format.
The following are examples of Spark Date and Time functions:
- to_date(e: Column): Column
- current_date () : Column
- date_add(start: Column, days: Int): Column
- to_date(e: Column, fmt: String): Column
- date_sub(start: Column, days: Int): Column
- add_months(startDate: Column, numMonths: Int): Column
-
Spark SQL Aggregate Functions
DataFrame columns may undergo aggregate operations with the help of aggregate functions. The aggregate functions operate based on the groups and rows.
The Spark SQL aggregate functions include the ones listed below.
- avg(e: Column)
- approx_count_distinct(e: Column)
- collect_set(e: Column)
- countDistinct(expr: Column, exprs: Column*)
- approx_count_distinct(e: Column, rsd: Double)
| Related Article: Learn How to Configure Spark |
Advantages of Spark SQL
Using Spark SQL comes with a variety of benefits, some of which are listed below:
- Spark SQL may be linked through ODBC OR JDBC, providing a standard connection.
- In addition to its other benefits, Spark SQL allows it to load and query data from various sources. It results in consolidated data availability.
- Hive tables may sometimes process at a faster rate.
- SQL queries are combined with Spark applications (RDD) when searching structured data as a distributed dataset. Also, Spark SQL's integration attribute is used to perform the SQL queries alongside analytical methods.
- A further advantage of Spark SQL is its compatibility with preexisting Hive data and queries, allowing them to be executed without modification on preexisting warehouses.
Disadvantages of Spark SQL
Some potential problems that might happen while using Spark SQL are as follows:
- It does not support Hive transactions.
- Using Spark SQL, you cannot create tables that include union columns or read tables with such elements.
- In circumstances in which the varchar is too large, it does not indicate whether or not an error has occurred.
- In addition to that, it does not support the Char data type (fixed-length strings). Because of this, reading or creating a table containing such fields is not feasible.
Sorting Functions
For your understanding, we'll describe and outline the Spark sql syntax of a few standard sorting functions below.
1.Syntax: desc_nulls_first(columnName: String): Column
Description: Identical to the desc function, except with nulls being returned before anything else
2.Syntax: asc(columnName: String): Column
Description: This sorting syntax may specify the ascending order of the sorting column on a DataFrame or DataSet.
3.Syntax: desc(columnName: String): Column
Description: Determines the order in which the DataFrame or DataSet sorting column should be shown, going from highest to lowest.
4.Syntax: desc_nulls_last(columnName: String): Column
Description: Identical to the desc function, except that valid values are returned before invalid ones.
5.Syntax: asc_nulls_first(columnName: String): Column
Description: Comparable to the asc function, but returns null values before values that are not null.
6.Syntax: asc_nulls_last(columnName: String): Column
Description: Identical to the asc function, except that the return order prioritizes non-null values above null values.
Adding Schema to RDDs
RDD is an acronym for "resilient distributed dataset," which describes a fault-tolerant and immutable dataset that can be acted on in parallel. RDD files might include objects generated by pulling up datasets from other locations. To execute SQL queries on it, schema RDD must first be used. However, Schema RDD surpasses the capabilities of SQL since it provides a unified interface for our structured data.
To generate a DataFrame for our transformations, let us look at the following code example:
import org.apache.spark.sql.catalyst.encoders.ExpressionEncoder
import org.apache.spark.sql.Encoder
import spark.implicits._
val fileDataFrame = spark.sparkContext.textfile(“sfiles/src/main/scala/file.txt”).map(_.split(“,”)).map(attributes = > File(attributes(0), attributes(1).trim.toInt)).toDF()
fileDataFrame.createOrReplaceTempView(“File”)
val secondDF = spark.sql("SELECT name, age FROM file WHERE age BETWEEN 20 AND 25")
secondDF.map(second =&apm;gt; “Name: “ + second(0)).show()
Code explanation
We imported specific encoders for RDD into the shell in the code that just showed. After that, we construct a data frame corresponding to our text file. Following that, we created our data frame to show all the names and ages where the age is between 18 and 25, and it now just outputs the table.
Follow this code to map your data frames
secondDF.map(second => “Name: “ + second.getAs[String](“name”)).show()
implicit val mapEncoder = org.apache.spark.sql.Encoders.kryo[Map[String, Any]]
secondDF.map(second = > seoncd.getValuesMap[Any](List(“name”,”age”))).collect()
Code explanation:
The above code changes the mapped names into the string format. The newly imported class mapEncoder is used to convert stringified ages to their corresponding first names. Names and ages will be shown in the final output.
RDDs may do the following two kinds of operations:
- Actions: The operations such as count, first, run, reduce, Etc. are all examples of actions. An action returns something once a calculation has been executed on an RDD. For example, Decrease is an action in which we reduce the values of the elements in the RDD by applying some function, and the driver program delivers the final result. It is an example of reducing the values of the items in the RDD.
- Transformations: Transformations are the activities responsible for producing a new dataset using the one already there. For instance, a transformation may accomplish using a map, which, after running the dataset element through a function, produces the output of a new RDD that represents the modified dataset.
When an action operation is done on a converted RDD, some default methods for the RDD will recompute the data each time. However, it also uses the cache to store an RDD in the RAM permanently. In this scenario, Spark will remember the items around the cluster so it can do the calculation much more quickly the next time the query is executed.
Conclusion
To summarise, Spark SQL is a module of Apache Spark that analyzes structured data. Scalability is provided, and good compatibility with other system components is ensured. It is possible to connect to databases using the JDBC or ODBC standard. As a result, it offers the most intuitive way in which the structured data may be expressed.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Apache Spark Training | Aug 01 to Aug 16 | View Details |
| Apache Spark Training | Aug 04 to Aug 19 | View Details |
| Apache Spark Training | Aug 08 to Aug 23 | View Details |
| Apache Spark Training | Aug 11 to Aug 26 | View Details |

Madhuri is a Senior Content Creator at MindMajix. She has written about a range of different topics on various technologies, which include, Splunk, Tensorflow, Selenium, and CEH. She spends most of her time researching on technology, and startups. Connect with her via LinkedIn and Twitter .














