
- 6 Hot And In-Demand Tech Areas In 2024
- How To Forward Your Career With Cloud Skills?
- Top 7 On-Demand IT Certifications
- Most In-demand Technologies To Upskill Your Career
- Top 10 Hottest Tech Skills to Master in 2024
- Top Skills You Need to Become a Data Scientist
- Groovy Interview Questions
- Facets Interview Questions
- Crystal Reports Tutorial
- VAPT Interview Questions
- Flutter Tutorial
- Saviynt VS Sailpoint
- Flutter vs Xamarin
- PingFederate Interview Questions and Answers
- Dart vs Javascript : What's the Difference?
- Terraform Private Registry
- Cylance Interview Questions and Answers
- Sophos Interview Questions and Answers
- Top Camunda Interview Questions
- NUnit Interview Questions and Answers
- Impala Interview Questions and Answers
- ETL Tutorial
- Ionic Interview Questions
- Grafana Tutorial
- What is VAPT? - A Complete Beginners Tutorial
- SnapLogic Interview Questions
- Saviynt Interview Questions
- What is PingFederate? - A Complete Beginners Tutorial
- SnapLogic Tutorial
- Grafana Interview Questions
- RHCE Interview Questions and Answers
- Web Services Interview Questions
- Domo Interview Questions and Answers
- Terraform Interview Questions
- What is Sophos? | Sophos Turorial for Beginners
- Top Servlet Interview Question And Answers
- NLP Interview Questions and Answers
- Microsoft Intune Interview Questions
- Top XML Interview Questions And Answers
- Tosca Commander
- Katalon vs Cypress
- SQLite Tutorial
- Tosca Tutorial - A Complete Guide for Beginners
- Xamarin Interview Questions and Answers
- UiPath vs Automation Anywhere - The Key Differences
- OpenShift Interview Questions
- What is Katalon Studio - Complete Tutorial Guide
- Kronos Interview Questions
- Tosca Framework
- Burp Suite Tutorial
- Mendix Interview Questions
- Power Platform Interview Questions
- Burp Suite Interview Questions
- What is Mendix
- What is Terraform ?
- Burp Suite Alternatives
- Dart vs Kotlin
- What is Kronos?
- ES6 Interview Questions
- Entity Framework Interview Questions
- COBOL Interview Questions
- Express JS Interview Questions
- OSPF Interview Questions
- LINQ Tutorial
- CSS3 Interview Questions and Answers
- Auth0 Tutorial
- MS Access Interview Questions
- ExpressJS Tutorial
- UML Tutorial
- HTML vs XML
- Cypress vs Jest
- Impacts of Social Media
- OWASP Interview Questions
- Security Testing Interview Questions
- OpenShift vs Docker
- ES6 Tutorial
- Spark SQL Interview Questions
- Spark SQL Tutorial
- What is OWASP?
- AppDynamics Interview Questions
- Dynatrace Interview Questions
- Rest Assured Tutorial
- New Relic Interview Questions
- REST API Tutorial
- Datadog Interview Questions
- Rest API Interview Questions
- Rest Assured Interview Questions
- PTC Windchill Interview Questions
- Easiest Tech Skills To Learn
- Python SQLite Tutorial - How to Install SQLite
- Datadog Tutorial - Datadog Incident Management
- What is AppDynamics - AppDynamics Architecture
- RabbitMQ Interview Questions And Answers
- What is Dynatrace
- Datadog Vs Splunk
- Web Developer Job Description
- JP Morgan Interview Questions
- Types of Corporate Training
- Benefits of Corporate Training
- What is Corporate Restructuring?
- Blended Learning in Corporate Training
- What is Corporate Level Strategy?
- Flutter Projects and Use Cases
- How to Become a Web Developer
- How To Install Keras?
- How to Install Flutter on Windows?
- How to Install Cypress on Windows?
- How to Become a Computer Scientist?
- How to Install Katalon Studio in Windows
- How to Become a Programmer
- OWASP Projects and Use Cases
- How to Install Sophos?
- Workato Tutorial
- Workato Tutorial - What is Workato?
SPARQL is a query language like SQL that is used to retrieve the data from the RDF datasets and Linked Open Data. It can carry out all the analytics that SQL can perform. Also, it can be utilized for semantic analysis and analyzing relationships.
It can perform analytics on datasets that have both unstructured and structured data. SPARQL was designed by the W3C standard committee to perform analytics on the semantic networks or semantic web.
SPARQL is the only semantic query language that is standard with W3C. Governments and Commercial Organizations have standardized SPARQL as the language and RDF as the data model for building industry models in the financial services industry. In this SPARQL tutorial, you will learn the topics like Data Formats, writing SPARQL queries, Datasets, Result Sets, etc.
| Table Of Content - SPARQL Tutorial |
|
➤ Filters ➤ Optional ➤ Datasets |
What is SPARQL?
SPARQL is a protocol and query language for accessing the RDF developed by “W3C RDF Data Access Working Group.” As the query language, SPARQL is “data-oriented” in that it queries only the information stored in the models; there is no deduction in a query language.
| If you want to enrich your career and become a professional in SPARQL, then enroll in "SPARQL Online Training" - This course will help you to achieve excellence in this domain. |
Data Formats
First, we should know what data is being queried. SPARQL queries the RDF graphs. The RDF graph is a group of triples(Jena invokes RDF graphs “models” and triples “statements” since that is what they were invoked at the point when Jena API was first developed.
It is essential to understand that it is the triples that are important, not serialization. Serialization is just the method to develop the triples down. RDF or XML is a W3C suggestion, yet it is complicated to see triples in a serialized form as there are multiple methodologies to encrypt a similar graph.
We can start with the sample data that includes RDF for various vCard descriptions of people. vCards are explained in “RFC2426”, and RDF conversion is explained in the W3C note “Representing vCard Objects in XML/RDF.”
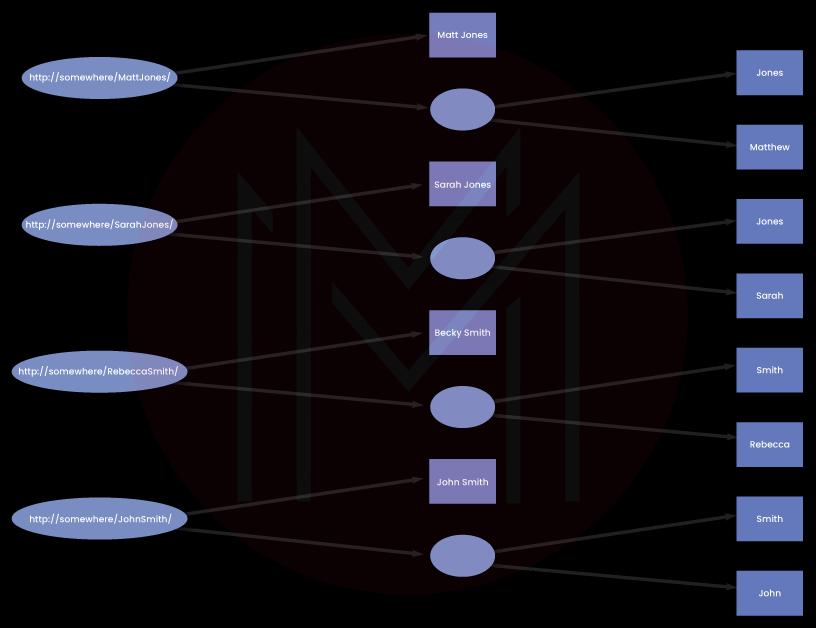
SPARQL Query
The file “query1.rq” contains the following query:
SELECT x
WHERE { x <http://www.w3.org/2001/vcard-rdf/3.0#FN> “MindMajix”}
We can execute that query using the command line query application:

This works by matching the triple pattern in the ‘WHERE’ clause opposing triples in the RDF graph. The object and predicate of the triple are set values; thus, the pattern matches only triples with those values. The subject is a variable, and we don’t have restrictions on the variable. Pattern matches any triple with these objects and predicate values, comparing with solutions for “y.”
The item confined in the “<>” is a URI and the item enclosed in the “” is the plain literal. Similar to Turtle, N-triples, N3, and typed literals are developed with ^^, and we can add the language tags with “@.”
?y is a variable known as y. The “y” does not establish the part of the name; that’s why it does not show up in the
We can find one match. The query returns a match in the “x” query variable. The output displayed was acquired through one of the command line applications of ARQ.

Query Execution
Executing the Queries in Windows:

Executing the Queries in Linux or Unix

Executing the queries using Java command-line applications:

Basic Patterns
Query Solutions
Query solutions are a group of pairs of variables with the value. The “SELECT” query directly reveals the solutions in the form of a result set - other query types utilize the solutions for making a graph. Query solutions are the way the pattern is matched - which values the variables should take for the pattern to match.

Basic Patterns
A basic pattern is a group of triple patterns. It compares when all the triple patterns match with the same value utilized every time the variable with the same value is utilized.

The query includes two triple patterns; every triple ends in ‘’. The variable x has to be identical for every triple pattern match.
QNames
There is an acronym process to write long URIs through prefixes. It is a prefixing mechanism - two parts of URIs, from prefix declaration and the part after “:” in the query, are joined together. This is not an XML qname yet utilizes the RDF rule to turn a qname into the URI by merging the parts.

Blank Nodes
Modify the query for returning “y.”

Filters
Graph matching enables the discovery of patterns.
String Matching
SPARQL offers the operation for testing the strings as per regular expressions. This contains the ability for asking the SQL ”LIKE” style tests; however, the syntax of regular expression varies from the SQL.

The flags argument is optional.

OPTIONAL
RDF is the semi-structured data; thus, SPARQL can query for the data yet not to fail the query when the data is not available. Query utilises the optional part for extending the information discovered in the query solution yet to return non-optional information.
The following query fetches the person's name and age if the information is available.

OPTIONALs with FILTERS
“OPTIONAL” is the binary operator that merges two graph patterns. The optional pattern is the group pattern that can include any type of SPARQL pattern. If the group matches, the solution is extended; if not, the original solution is provided.

Datasets
An RDF Dataset is defined as the unit that is queried by the SPARQL query. It contains the default graph and various named graphs.
Querying the datasets
Graph matching operation works on the RDF Graph. RDF Graph becomes the default graph of the dataset, but we can modify it using the “GRAPH” keyword.

If the URI is provided, the pattern will be compared with the graph in the dataset, the “GRAPH” clause fails to match.
Result Sets
SPARQL has the following result forms:
- SELECT: It returns the table of results.
- CONSTRUCT: It returns the RDF graph as per the template in the query.
- ASK: It Asks the boolean query.
- DESCRIBE: It returns the RDF graph, as per what the query processor is configured for returning.
Solution Modifiers
Pattern Matching gives a set of solutions. We can modify this set in several ways:
- Projection: It maintains only chosen variables.
- ORDER BY: It sorts the results.
- OFFSET/LIMIT: It slashes the number of solutions.
- DISTINCT: It yields only one row for one combination of values and variables.
SPARQL vs SQL
SPARQL contains various concepts of SQL. For instance, in both SPARQL and SQL, we use “WHERE” clauses and “SELECT” statements for analyzing the data, along with LIMIT, OFFSET, and ORDER BY commands. Graph databases store the data in triples through the “SUBJECT-PREDICATE-OBJECT” data model. SPARQL was developed for querying the data to analyze the data relationships better.
Conclusion
SPARQL is the query language we use to store and retrieve data. Like SQL, SPARQL also allows us to write the queries and execute them to fetch the data. It has all the components, clauses, and conditions that SQL has. I hope this SPARQL tutorial gives sufficient information about SPARQL. If you have any queries, let us know by commenting below.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| SPARQL Training | Aug 01 to Aug 16 | View Details |
| SPARQL Training | Aug 04 to Aug 19 | View Details |
| SPARQL Training | Aug 08 to Aug 23 | View Details |
| SPARQL Training | Aug 11 to Aug 26 | View Details |

Madhuri is a Senior Content Creator at MindMajix. She has written about a range of different topics on various technologies, which include, Splunk, Tensorflow, Selenium, and CEH. She spends most of her time researching on technology, and startups. Connect with her via LinkedIn and Twitter .














