- Home
- Blog
- Data Science
- Data Science Tutorial

- Big Data Vs Data Science Vs Data Analytics
- Data Science Interview Questions
- Top Data Science Tools
- Data Science with R Interview Questions
- Overview of Data Modeling for Unstructured Data in Data Science
- What is Data Scientist?
- What is Data Visualization?
- Data Cleansing
- What is Data Science
- What is Data Analytics?
- Job Roles For A Data Science Enthusiast
- RapidMiner Tutorial - Introduction To RapidMiner
- Top 12 Data Science Resources
- Data Scientist Interview Questions
- Programming Languages For Data Science
- MATLAB Interview Questions
- Data Engineer Interview Questions
- Data Visualization Interview Questions
- Toughest Courses in India
- Data Mining vs Data Science
- Data Scientist Job Description
The word “Data Science” has been buzzing around for 30 years. In the 1960s this term was originally known as “Computer Science” and used to define the survey of data processing techniques used in various applications. However, today, data science is not only the exclusive dominating factor for statisticians and computer scientists, but many people from other disciplines are embracing it along with analytics to contribute to evidence-based planning in their respective fields.
Experts believe that data science and analytics are all about storytelling as they completely revolve around algorithms. The skill to build a strong narrative in finding the empirical and then communicating them with stakeholders will differentiate accomplished data scientists from people who are confined to coding and number crunching. This Data Science tutorial will explore all the aspects of Data Science.
Data Science Tutorial
What is Data Science?
Data science is the process of analyzing data which involves applying Machine learning models, and statistical models to derive insights and value from data. This field is highly evolving as one of the most promising career paths for skilled professionals. Data professionals who are successful today need to understand that they must progress beyond the traditional skills of analyzing massive amounts of data, data mining, and programming skills.
In order to extract useful talent for their organizations, data scientists should embrace a full spectrum of the data science life cycle and owe a level of understanding and flexibility to increase returns at every stage of the process.
| Enthusiastic about exploring the skill set of Data Science? Then, have a look at the Data Science Training Certification Course |
Valuable data scientists have the ability to identify similar questions, gather data from a host of various data sources, organize the information, convert results into solutions, and discuss their findings in a way that certainly affects business decisions. Their skills are essential in almost every industry, causing skillful data scientists to be massively valuable to organizations.
Who is a Data Scientist?
Data scientists became essential assets and are employed in almost every organization. These professionals are versatile, data-driven individuals with extensive technical skills and are efficient in building quantitative complex algorithms to organize and synthesize huge amounts of data used to drive strategy and answer queries in their organization.
Data scientists should be curious and result-oriented, with extraordinary industry-specific communication skills and knowledge that allow them to discuss highly technical documentation with their non-technical counterparts. They hold a strong quantitative background in linear algebra and statistics as well as knowledge in programming which focuses on modeling, mining, and data warehousing to build and analyze algorithms.
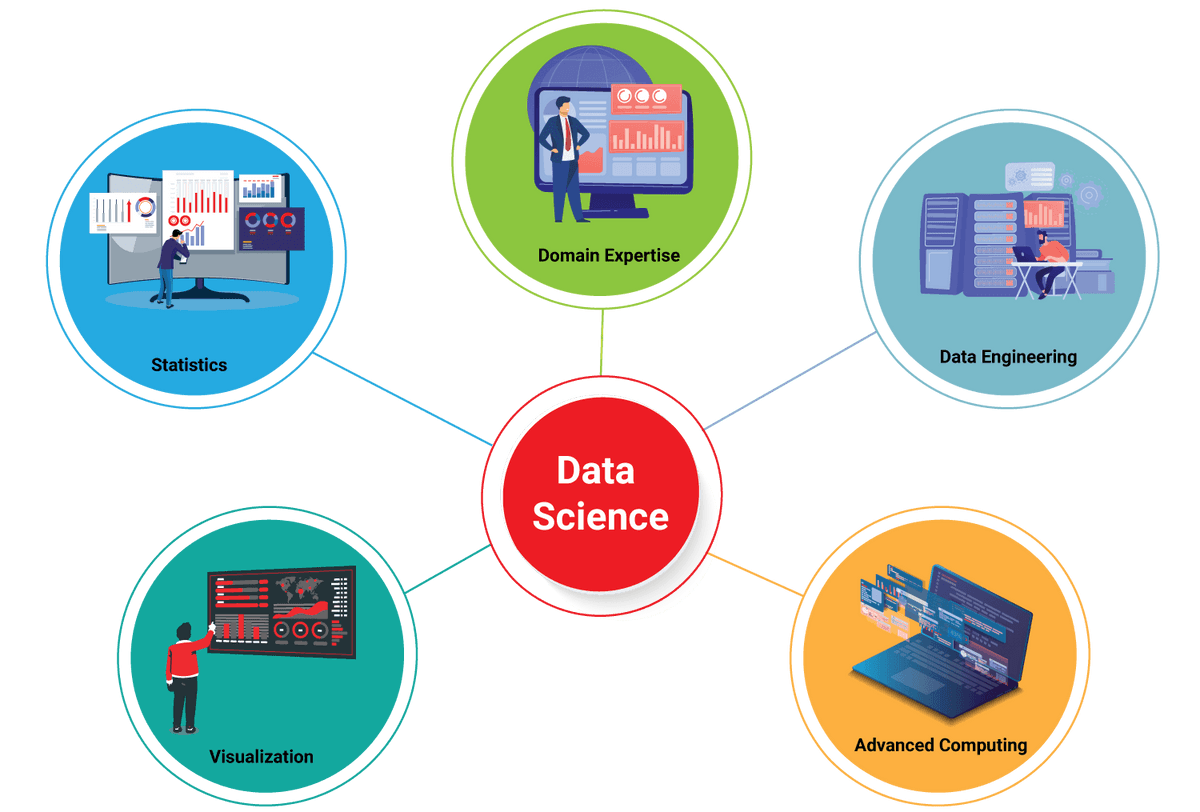
| For More Info: What is Data Scientist? |
Data scientists should be capable of utilizing the following important technical skills and tools:
Data Science Tools
#1. R
It is a programming language and is specifically designed for solving statistical problems in data science. R is preferred by 43% of data scientists for performing data analysis and developing statistical software.
#2. Python
Python is the most popular programming language used widely for data science roles. Because of its versatility, it can be for all the steps involved in data science processes. It can take almost any format of data and is also helpful in importing SQL tables into the code.
| Related Article: Data Science Programming Language |
#3. Apache Hadoop
Apache Hadoop is used to send large volumes of data to different servers if the present data exceeds the memory of the system. It is used to quickly convey data to different points on a system. Hadoop has many uses such as data exploration, data sampling, data filtering, and summarization.

#4. Jupyter Notebook
Jupyter Notebook (Formerly Ipython Notebook) It is an open-source web application allowing us to create and share codes and documents. This helps us to document the code, run it, verify the output, visualize data and see results. A jupyter notebook is a handy tool for executing complete data science
Workflows - visualizing data, statistical modeling, data cleaning, building and training machine learning models, and many more.
#5. MapReduce
MapReduce is a programming model used to process large sets of data with parallel, distributed algorithms on a cluster. It consists of two steps, and they are mapping and reducing.
- Mapping is used to sort and filter given datasets.
- Reducing is used to perform calculations of any sort on the resulting information.
#6. Apache Spark
Apache Spark is a computation framework similar to Hadoop, and it performs faster than Hadoop which makes it efficient for in-memory computations. The following ones are the advantages of Spark in data science:
- It is designed especially to run complicated algorithms faster.
- It helps in handling complex unstructured datasets.
- It is used to carry out analytics from intake of data to distributed computing.
#7. Tableau:
Tableau is a data visualization tool responsible for translating the data into a format that is easy to understand. This is because the business world produces massive amounts of data frequently and it becomes easy for people to understand pictures in the form of graphs and charts instead of raw data. Data visualization enables organizations to work with data directly so that people can quickly understand insights that help them to act upon new businesses.
Data Science Road Map
The process involved in solving a data science problem is classified into various steps, the below representation shows the road map of solving a data science problem.
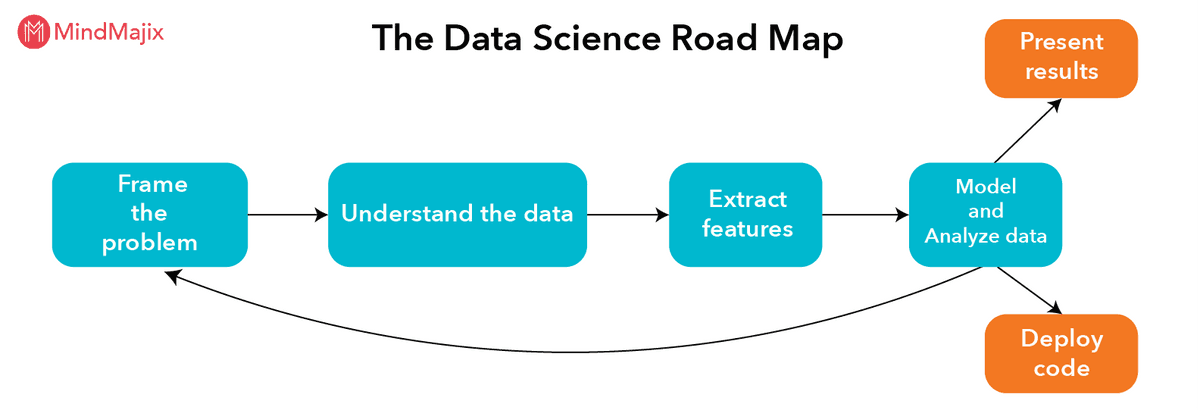
#1. Frame the problem
Framing a problem includes understanding a business use case and shaping a well-defined analytics problem out of it. This is followed by an extensive phase of struggling with the data and the real-world things that it describes so that the meaningful features can be extracted.
#2. Understanding the data: Data Wrangling
This process involves getting the data from its raw format and converting it into something well suited for more conventional analytics. This process typically means creating a software pipeline that extracts the data from wherever it is stored. Data wrangling is the key area where data scientists require skills that a traditional analyst or statistician doesn’t have.
#3. Extract features
Feature extraction is the process of reducing dimensionality, where a set of raw variables are reduced to many manageable groups for processing, while still completely and accurately describing the original dataset. Feature extraction originates from an initial set of calculated data and creates derived values intended to be non-redundant and informative.
Visit here to learn Data Science Online Training in BangaloreVisit here to learn Data Science Online Training in Hyderabad
#4. Model and Analyze data
Machine learning models are a part of data science projects. The modeling phase of a data science project is very simple: Take a standard suite of models, plug your data into each one of them and check which one works the best. In most situations, a lot of care needs to be taken to carefully tune a model.
Analyzing data involves various methods such as data mining, data visualization, business intelligence, and exploratory data analysis. Any method can be used to perform data analysis, as long as it helps the analyst to study the information that is collected.
#5. Present results
If the client being human, then you will need to provide either a presentation slide or a written report explaining the work you did and what your results were. Communicating in a slide deck is difficult and tricky with data science, where the material you are conversing is highly technical and you are presenting to a broad audience. Data scientists should communicate seamlessly with software engineers, domain experts and business analysts.
#6. Deploy code
If your ultimate clients are computers, then it is your job to produce code that will be run regularly in the future by other people. Typically, this falls into one of two categories:
- Batch analytics code: This will be used to redo an analysis similar to the one that has already been done, on data that will be collected in the future.
- Real-time code: This will typically be an analytical module in a larger software package, written in a high-performance programming language and adhering to all the best practices of software engineering.
There are three typical deliverables from this stage:
The code itself.
Some documentation of how to run the code. Sometimes, this is a standalone work document, often called a “run book.” Other times, the documentation is embedded in the code itself.
Usually, you need some way to test code that ensures that your code operates correctly. Especially for real-time code, this will normally take the form of unit tests. For batch processes, it is sometimes a sample input dataset (designed to illustrate all the relevant edge cases) along with what the output should look like.
In deploying code, data scientists often take on a dual role as full-fledged software engineers. Especially with very intricate algorithms, it often just isn't practical to have one person spec it out and another implement the same thing for production.
Role of a Data Scientist
The main objective of a data scientist is to organize and analyze large amounts of data, and they often use software designed specifically for that task. The outputs obtained from the analysis of a data scientist should be easy enough for the stakeholders to understand; especially for Non-IT people.
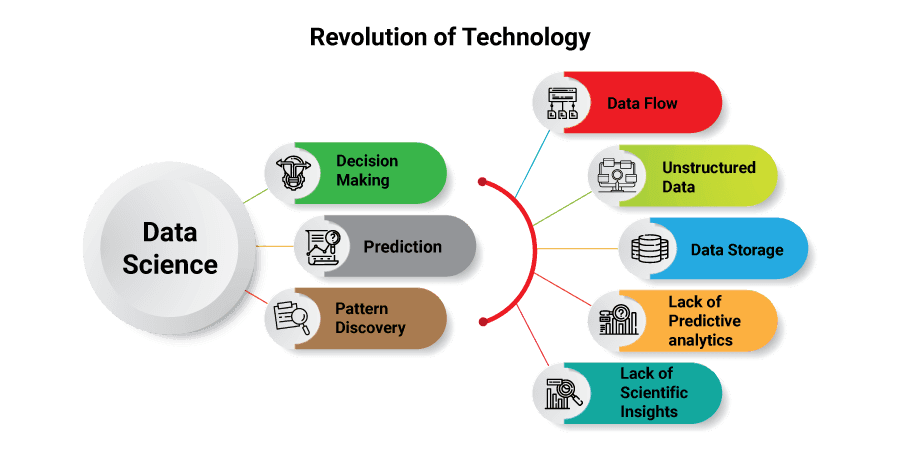
A data scientist’s perspective on data analysis depends on their industry and certain needs of the business or department they are working for. Before knowing the actual meaning behind structured and unstructured data, department managers and business leaders should communicate what they need to look for. For this to happen, a data scientist should have enough business domain expertise to convey departmental or company goals into data-based deliverables like pattern detection analysis, prediction engines, and optimization algorithms.
| For More Info: Job Roles For A Data Science Enthusiast |
Creating a Data Science Project with Kaggle
Responsibilities of a Data Scientist
A data scientist’s primary objective is data analysis - a process that initiates with a collection of data and ends with business decisions taken with the help of data analytics results.
The information which the data scientists analyze is often called big data. Big data is further divided into 2 different types, and they are:
- Structured data
- Unstructured data
Structured data is well organized which helps the computer to sort and read the data automatically. This contains data collected by products, services, electronic devices, and data gathered from human input. For instance, web traffic, GPS coordinates, and sales figures are structured forms of data.
Unstructured data is the rapidly evolving form of big data and is more likely obtained from human inputs. For instance, emails, customer reviews, videos, and social media posts come under unstructured forms of data. This category of data is more complex to sort through and less efficient to manage with technology. Because the data is not streamlined, this type of data requires a lot of investment to manage.
Visit here to learn Data Science Online Training in Bangalore
Businesses hire data scientists to manage this unstructured data, and the other IT personnel take the responsibility of maintaining and managing structured data. The data scientists work with a lot of structured data in their careers, but the businesses are looking to leverage the unstructured data in service of their revenue goals.
Reason for becoming a Data scientist
Glassdoor recommends data science as the best career and has ranked it as the no.1 Job in America in 2018. Every day, the data which can be accessed is increasing in huge amounts. As a result, large tech companies are not the only ones who are in need of data scientists. Even the small and medium businesses are looking for qualified data scientists, but the shortage of qualified candidates is a major challenge that the industries (both big and small) are facing today.
Hence, the demand for data scientists is sky-high and there is no sign of slowing down in the near future. The professional network giant Linkedin has listed data scientists as one of the promising careers in 2017 and 2018. The statistics displayed in these websites Glassdoor, Forbes are enough to show the prominence of this role.
Data Science Infographic

What is a Data Science Platform?
A data science platform is simply a software hub in which all the work related to data science takes place. So, that work basically consists of integration and exploration of data for different sources, combined with coding and deploying those models into production, structuring models that leverage the data, and serving up results.
It is important to have a centralized location for all the data science work to take place. Data science projects primarily comprise many disparate tools designed for every stage of the process. A data science platform places the whole data modeling process in the hands of data science teams so they can concentrate on deriving insights for data and communicate them with the stakeholders in your business.
Data science platforms that are best in class offer the flexibility of open-source tools and the handling of elastic compute resources. That is because the widely popular tools for the data science process are always evolving, so it is crucial that the platform your data scientists use shall comply with these changes.
Here is a great resource on “How to choose a Data Science Platform”: Choosing a Data Science Platform.
Data Scientist Education and Training
The most traditional way to become a data scientist is by enrolling in a bachelor’s degree program. According to the data by BLS (Bureau of labor statistics), most of the data scientists hold a master’s or a higher degree. This is not the case for every individual - Before enrolling in a higher-education program, you should know which industry you’ll be working in to figure out the tools of the trade.
Thus, as this role needs some business domain expertise, the education and training required will vary depending on the industry. If you are willing to work in a highly technical industry, you might require further training. For example, if you are working in government, healthcare, or science, you will need a skill set different from marketing, education, or business.
Applying methods like Malware detection and Analysis is Important as the growth rate of malware is increasing, here is a book named Malware Data Science written by security data scientist Joshua Saxe which explains about providing security to data by following approaches like social network analysis, machine learning, statistics, and data visualization.
| Related Article: Top Data Science Interview Questions |
Data science Career Scope and Salary
Data Scientists are well reputed for their highly technical skillset with great job opportunities and competitive salaries across various industries (small and large). With over more than 4,500 open positions listed on Glassdoor, professionals in data science with the right experience and education have the chance to show their prominence in futuristic companies across the world.
Below mentioned are the average base salaries for the following positions:
- Data analyst: $65,470
- Data scientist: $120,931
- Senior data scientist: $141,257
- Data engineer: $137,776
Mastering specific skills within the field of data science can make data scientists stand out from the crowd. For instance, experts in machine learning make use of extreme skills of programming to create algorithms that constantly collect data and automatically alter their functions to be more accomplished.
Data Science Certifications
There are much valuable data science and big data certifications that can show a positive impact on your career and salary.
The following are some of the popular data science certifications:
- The CAS Institute - Certified Specialist in Predictive Analytics (CSPA)
- The Cap Program - Certified Analytics Professional (CAP)
- Data Science Council of America - DASCA Data Science Credentials
- Cloudera - Cloudera Certified Professional: CCP Data Engineer
- Harvard Extension School - Data Science Certificate
- SAS Institute - SAS Certified Big Data Professional/Data Scientist
- MindMajix - Live Instructor-led Data Science Certification Training.
| Explore Data Science Sample Resumes! Download & Edit, Get Noticed by Top Employers! |
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Data Science Training | Jul 25 to Aug 09 | View Details |
| Data Science Training | Jul 28 to Aug 12 | View Details |
| Data Science Training | Aug 01 to Aug 16 | View Details |
| Data Science Training | Aug 04 to Aug 19 | View Details |

As a Senior Writer for Mindmajix, Saikumar has a great understanding of today’s data-driven environment, which includes key aspects such as Business Intelligence and data management. He manages the task of creating great content in the areas of Programming, Microsoft Power BI, Tableau, Oracle BI, Cognos, and Alteryx. Connect with him on LinkedIn and Twitter.






