
- 6 Hot And In-Demand Tech Areas In 2024
- How To Forward Your Career With Cloud Skills?
- Top 7 On-Demand IT Certifications
- Most In-demand Technologies To Upskill Your Career
- Top 10 Hottest Tech Skills to Master in 2024
- Top Skills You Need to Become a Data Scientist
- Groovy Interview Questions
- Facets Interview Questions
- Crystal Reports Tutorial
- VAPT Interview Questions
- Flutter Tutorial
- Saviynt VS Sailpoint
- Flutter vs Xamarin
- PingFederate Interview Questions and Answers
- Dart vs Javascript : What's the Difference?
- Terraform Private Registry
- Cylance Interview Questions and Answers
- Sophos Interview Questions and Answers
- Top Camunda Interview Questions
- NUnit Interview Questions and Answers
- ETL Tutorial
- Ionic Interview Questions
- Grafana Tutorial
- What is VAPT? - A Complete Beginners Tutorial
- SnapLogic Interview Questions
- Saviynt Interview Questions
- What is PingFederate? - A Complete Beginners Tutorial
- SnapLogic Tutorial
- Grafana Interview Questions
- RHCE Interview Questions and Answers
- Web Services Interview Questions
- Domo Interview Questions and Answers
- Terraform Interview Questions
- What is Sophos? | Sophos Turorial for Beginners
- Top Servlet Interview Question And Answers
- NLP Interview Questions and Answers
- Microsoft Intune Interview Questions
- Top XML Interview Questions And Answers
- Tosca Commander
- Katalon vs Cypress
- SQLite Tutorial
- Tosca Tutorial - A Complete Guide for Beginners
- Xamarin Interview Questions and Answers
- UiPath vs Automation Anywhere - The Key Differences
- OpenShift Interview Questions
- What is Katalon Studio - Complete Tutorial Guide
- Kronos Interview Questions
- Tosca Framework
- Burp Suite Tutorial
- Mendix Interview Questions
- Power Platform Interview Questions
- Burp Suite Interview Questions
- What is Mendix
- What is Terraform ?
- Burp Suite Alternatives
- Dart vs Kotlin
- What is Kronos?
- ES6 Interview Questions
- Entity Framework Interview Questions
- COBOL Interview Questions
- Express JS Interview Questions
- OSPF Interview Questions
- LINQ Tutorial
- CSS3 Interview Questions and Answers
- Auth0 Tutorial
- MS Access Interview Questions
- What is SPARQL - A Complete Tutorial Guide
- ExpressJS Tutorial
- UML Tutorial
- HTML vs XML
- Cypress vs Jest
- Impacts of Social Media
- OWASP Interview Questions
- Security Testing Interview Questions
- OpenShift vs Docker
- ES6 Tutorial
- Spark SQL Interview Questions
- Spark SQL Tutorial
- What is OWASP?
- AppDynamics Interview Questions
- Dynatrace Interview Questions
- Rest Assured Tutorial
- New Relic Interview Questions
- REST API Tutorial
- Datadog Interview Questions
- Rest API Interview Questions
- Rest Assured Interview Questions
- PTC Windchill Interview Questions
- Easiest Tech Skills To Learn
- Python SQLite Tutorial - How to Install SQLite
- Datadog Tutorial - Datadog Incident Management
- What is AppDynamics - AppDynamics Architecture
- RabbitMQ Interview Questions And Answers
- What is Dynatrace
- Datadog Vs Splunk
- Web Developer Job Description
- JP Morgan Interview Questions
- Types of Corporate Training
- Benefits of Corporate Training
- What is Corporate Restructuring?
- Blended Learning in Corporate Training
- What is Corporate Level Strategy?
- Flutter Projects and Use Cases
- How to Become a Web Developer
- How To Install Keras?
- How to Install Flutter on Windows?
- How to Install Cypress on Windows?
- How to Become a Computer Scientist?
- How to Install Katalon Studio in Windows
- How to Become a Programmer
- OWASP Projects and Use Cases
- How to Install Sophos?
- Workato Tutorial
- Workato Tutorial - What is Workato?
Apache Impala is a modern search engine for Apache Hadoop that is open source. It is based on Apache Hadoop. Impala communicates with HDFS via SQL. This tutorial is for people preparing for the Impala Interview. Impala is a data processing platform that uses standard SQL skills to process massive amounts of data at breakneck speed.
In this Impala Interview Questions tutorial, our experts curated the Top 35 Impala Interview Questions and Answers. Furthermore, these Impala Interview Questions cover in-depth aspects of Impala for both fresher and experienced professionals. These Impala Interview Questions will undoubtedly assist you in sorting out all of your Impala concepts.
Top 10 Impala Interview Questions
- Explain about the Impala?
- What are the drawbacks of Impala?
- What are the Impala Architecture Components?
- Explain about Impala's Built-in functions?
- Describe the Impala Shell?
- Explain how Apache Impala works with CDH?
- How to handle an ERROR in Impala?
- Explain about Impala Data types?
- Why does My Select statement fail in Impala?
- Explain how Impala metadata is managed?
Impala Interview Questions and Answers For Freshers
These Impala Interview Questions are intended for fresh graduates. However, experienced candidates can also refer them to refresh their concepts on Impala interview questions.
1. Explain about the Impala?
Processing enormous amounts of information Impala is a SQL query engine that runs in a Hadoop cluster and uses MPP (Massive Parallel Processing). Furthermore, the fact that it is open-source software built in C++ and Java is a plus. It also outperforms other Hadoop SQL engines in terms of low latency and performance. To be more exact, it is the fastest way to retrieve the information that is stored in Hadoop Distributed File System HDFS using the highest-performing SQL engine.
2. What is the need of Impala Hadoop?
Impala integrates the SQL functionality and multi-user efficiency of a definitive analytic database with the flexibility and scalability of Apache Hadoop by employing various components. Metastore, HBase, HDFS, Sentry, and YARN are just a few examples.
- Users can also utilize SQL queries to connect with HBase or HDFS with Impala, which is even faster than other SQL interpreters like Hive.
- It can read practically all of Hadoop's file types such as Parquet, Avro, and RCFile.
It also shares Apache Hive's metadata, user interface (Hue Beeswax) ODBC driver, SQL syntax (Hive SQL), and ODBC driver. Also, for batch or real-time queries, it provides a familiar and consistent platform. Impala, contrary to Apache Hive, does not use MapReduce techniques. It uses a distributed architecture based on persistent processes that work on similar machines and are accountable for all elements of query execution. As a result, it minimizes the latency of MapReduce, making Impala faster than Apache Hive.
| If you want to enrich your career and become a professional in Apache Impala, then enroll in "Impala Training". This course will help you to achieve excellence in this domain. |
3. What are the advantages of Impala?
The following is a list of Impala's most significant benefits.
- With standard SQL skills, you can generate reports stored in HDFS at lightning speed with impala.
- When working with Impala, data movement and data transformation are not required because data processing takes place where the data is (on a Hadoop cluster).
- Impala allows you to access data stored in HBase, HDFS, and Amazon S3 despite having to know Java (MapReduce jobs). With a rudimentary understanding of SQL queries, you can gain access to them.
- The data must go through a sophisticated extract-transform-load (ETL) cycle before it can be used to generate queries in business tools. However, with Impala, this process is accelerated.
- The time-consuming processes of importing and rearranging are eliminated according to innovative approaches like interactive data analysis and data discovery, which speed up the process.
- Impala is a pioneer in the usage of the Parquet file type, which is a tabular storage architecture intended for huge queries like those found in data warehouses.
4. Explain about the features of Impala?
Following are some of the features of Impala:
- Impala is open source and free to use under the Apache license.
- Impala offers in-memory processing of data, which means it can access/analyze data stored on Hadoop data blocks without having to move the data around.
- Impala supports SQL-like queries for data access.
- When compared to other SQL engines, Impala gives easy accessibility to HDFS data.
- Impala makes it easy to store the data in Apache HBase, HDFS, and Amazon S3 storage systems.
- Impala can be used with business intelligence software tools such as Zoom data, Pentaho, Tableau, and Micro strategy.
- LZO, Sequence File, Avro, RCFile, and Parquet are among the file formats supported by Impala.
- Impala takes advantage of Apache Hive's metadata, SQL syntax, and ODBC driver.
5. Differentiate between Impala and Relational Database?
Impala makes use of a query language comparable to HiveQL and SQL. The table below summarizes some of the significant differences between Impala and SQL Query.
| Impala | Relational Database |
| Impala employs a query language that is comparable to HiveQL and is similar to SQL. | SQL is the language used in relational databases. |
| Individual records cannot be updated or deleted in Impala. | Individual records can be updated or deleted in relational databases. |
| Transactions are not supported by Impala. | Transactions are supported by relational databases. |
| Indexing is not supported by Impala. | Indexing is possible in relational databases. |
| Impala is a data management system that stores and manages massive volumes of data (petabytes). | When compared to Impala, relational databases can manage lower amounts of data (terabytes). |
6. What are the drawbacks of Impala?
The following points are the few drawbacks of Impala:
- Impala doesn't have any serialization or deserialization functionality.
- Custom binary files cannot be read by Impala; they can only read text files.
- The table must be refreshed whenever updated records/files are uploaded to the HDFS data directory.
7. What are the Impala Architecture Components?
The Impala engine is made up of various daemon methods that operate on various hosts in your CDH group.
The Impala Daemon
It is one of the essential components of Hadoop Impala. It is installed all over every node in the CDH cluster. The Impala method is generally used to identify it. Furthermore, we use it to write and read data files. Furthermore, it acknowledges queries sent by the impala-shell command, Hue, JDBC, or ODBC.
The Impala state store
The Impala state store is used to monitor the condition of all Impala Daemons on all multiple nodes in the Hadoop cluster. We also refer to it as an evolutionary process that has been saved. However, in the Hadoop cluster, only one such procedure is necessary on a single host. The main advantage of this Daemon is that it notifies all Impala Daemons when one of them goes down. As a result, they can avoid delivering future queries to the target node.
The Impala Catalog Service
The Catalog Service notifies all Datanodes in a Hadoop cluster about metadata updates from Impala SQL commands. It is essentially physically defined by the Daemon process catalog. In the Hadoop cluster, we just require one such process on one host. Because catalog services are routed through state stored, the state-stored and catalog processes are usually hosted on the same machine. It also eliminates the requirement for REFRESH and invalidates METADATA queries to be issued. Even when Impala queries are used to make metadata modifications.
8. Explain about Query processing interfaces in Impala?
Impala has three interfaces for processing queries, as seen below.
- Impala-shell: To start the Impala shell, you need to run a command impala-shell in the editor after setting up the impala using the Cloudera VM.
- Hue Interface: It can be used to process Impala queries. Impala query editor is available in the Hue interface, where you may type and execute impala queries. You must first log into the Hue browser to use this editor.
- ODBC/JDBC Drivers: Impala provides ODBC/JDBC drivers in the same way as other databases do. You can interact with Impala using these interfaces and create applications that execute queries in Impala using these programming languages.
9. What are the Benefits of Impala Hadoop?
The following points are some of the benefits of Impala Hadoop:
- Impala has an extremely familiar SQL interface. Data analysts and scientists, in particular, are aware of this.
- Apache Hadoop, also allows you to query large amounts of data ("Big Data").
- In a cluster context, it also supports distributed queries for easy scaling. It proposes the usage of low-cost commodity servers.
- It is possible to transfer data files among multiple components using Impala without having to copy or export/import them.
10. Explain about Impala Built-in functions?
Impala Built-in Tasks can be used to conduct a variety of functions directly in SELECT statements, including mathematical computations, Data calculations, text manipulation, and other data transformations. With Impala's built-in functions SQL query, we can retrieve results with all types of conversions, formatting, and calculating applied.
We can use the Impala Built-in Functions instead of executing time-consuming postprocessing in another application. You can build a SQL query that is as efficient as expressions in a procedural programming language or formulae in a spreadsheet by using function calls where possible.
Hereby are some of the built-in categories that are supported by Impala:
- Date and Time Functions
- Type Conversion Functions
- Mathematical Functions
- String Functions
- Conditional Functions
- Aggregation functions

11. How to call built-in functions in Impala?
The SELECT statement can be used to call any of the Impala functions. For the most part, we can eliminate the FROM statement and supply actual values for any needed arguments:
select abs(-1);
select concat(‘The rain ‘, ‘in Spain’);
select po
12. Describe the Impala Shell?
The Impala shell tool can be used to create tables in the database, enter data, and run queries (impala-shell). In addition, we may use an active dialogue to submit SQL statements for ad hoc inquiries and investigations. Additionally, command-line arguments can be specified to execute a single statement or a script file. It also supports all of the SQL statements specified in Impala SQL Statements, as well as a few shell-only commands. As a result, we may utilize it to fine-tune performance and troubleshoot issues.
13. Does Impala use caching?
No. Impala does not allow you to cache table data. It does, however, save certain file metadata and tables. Since the data set was stored in the OS local cache, queries may perform quickly on consecutive repetitions; Impala does not expressly restrict this.
Impala, on the other hand, uses the HDFS caching functionality in CDH 5. As a result, the CACHED and UNCACHED variables of the ALTER TABLE and CREATE TABLE statements can be used to specify which tables or segments are cached. Impala may also use data that is stored in the HDFS cache by using the hdfscacheadmin query.
Impala Interview Questions and Answers for Experienced
From here the following questions and answers are for experienced/professional People which are a bit advanced.
14. Explain how Apache Impala works with CDH?
The diagram below depicts Impala's position within the larger Cloudera ecosystem:
As a result, the above Architecture illustration signifies how Impala interacts with other Hadoop components. The Hue web UI, client programs [ODBC and JDBC applications], and Hive Metastore database are examples of such services. The Impala solution is made up of the following components. As an example:
- Clients: These interfaces can be used to request inquiries or comprehensive administrative functions such as connecting to Impala.
- Hive Metastore: We use the Hive Metastore to store metadata that is available to Impala.
- Impala: A DataNode-based process that organizes and implements queries. Each instance of Impala can initiate, organize, and execute queries with Impala clients. All queries, on the other hand, are dispersed over Impala nodes. As a result, these nodes act as agents, executing query pieces in parallel.
- HBase and HDFS: In most cases, it's a repository for data that can be searched.
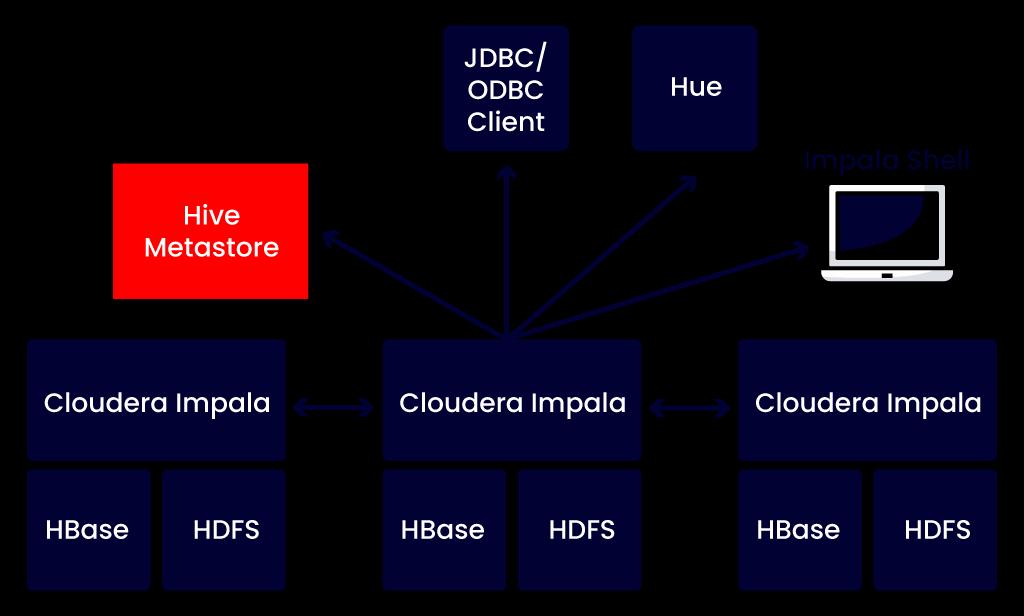
15. How to control the access to Data in Impala?
We can manage data access in Cloudera Impala by using Auditing, Authentication, and Authorization. We can also use the Sentry open-source program for user authorization. Sentry comes with a comprehensive authorization mechanism for Hadoop. It also assigns varying rights to each computer user. Furthermore, we may manage access to Impala information by employing authorization mechanisms.
16. What is meant by troubleshooting for Impala?
Impala Troubleshooting/performance tuning refers to the ability to debug and diagnose the challenges in Impala. It includes Impala-related daemon performance, disk space usage, out-of-memory circumstances, network connectivity, and hand or crash conditions. But, there are various approaches we can take to diagnose and debug the aforementioned issues.
- Impala performance tuning
- Impala Troubleshooting Quick Reference.
- Troubleshooting Impala SQL Syntax Issues
- Impala Web User Interface for Debugging
17. Explain the distinct operators in Impala?
To extract the results or eliminate the redundancy of the data, use the DISTINCT operator in a SELECT statement:
- Gets the distinct values from a single column
- If any entries have a NULL in this column, NULL is included in the set of values.
- Employees, select distinct c birth country;
- Returns the distinct value combinations from multiple columns
- select distinct a_location, a_middle name from employees;
- Furthermore, we can use DISTINCT in conjunction with an aggregation function to determine how many values a column incorporates.
- COUNT(): It counts the number of distinct values in a single column.
- The count does not include NULL as a distinct value
- Counts the different combinations of values from multiple columns.
- select count(distinct a_Birth place) from Employees;
- count(distinct a_location, a_middle name) from Employees;
- However, Impala SQL does not support using DISTINCT in multiple aggregation functions in the same query. To clarify, we couldn't have a single query with both COUNT(DISTINCT a_first name) and COUNT(DISTINCT a_last name) in the SELECT list.
18. Which host does Impala run?
Cloudera, on the other hand, highly advises deploying the Impala daemon on every single DataNode for optimum efficiency. However, it is not a strict need. If we have data frames with no Impala daemons active on any of the sites hosting replication of those frames, queries including that data could be exceedingly inefficient since the data must be transmitted from one system to another to process by "remote reads." Impala, on the other hand, usually strives to avoid this situation.
19. Explain how joins perform in Impala?
Impala automatically identifies the most optimal order to join the tables based on their overall number and size of rows using a cost-based technique. The COMPUTE STATS command captures information about each table that is critical for efficient join performance, according to the new functionality. Impala uses one of two approaches for join queries: "partitioned joins" and "broadcast joins."
20. How to handle an ERROR in Impala?
Impala, on the other hand, does not have a design flaw. All Impala daemons are comprehensively capable of handling incoming queries. However, if a machine fails, all queries with portions running on that device will fail. Because queries are supposed to recover quickly, we can simply redo the query if it fails.
| Check out: Hive vs Impala |
21. State a few use cases of Impala?
Following are the Use Cases and Applications of Impala:
- Do BI-style Queries on Hadoop: Impala provides high concurrency and low latency for BI/analytic queries on Hadoop, particularly those that are not provided by bulk frameworks including Apache Hive. Furthermore, including in multi-tenant ecosystems, it scales linearly.
- Unify Your Infrastructure: There is no repetitive architecture in Impala, nor is data duplication/conversion potential. As a result, we must use the same data formats and files, as well as resource management frameworks, security, and metadata as your Hadoop implementation.
- Implement Quickly: For Apache Hive clients, Impala uses the same ODBC driver and metadata. Impala supports SQL like Hive. As a result, we don't even have to think about redefining the deployment wheel.
- Count on enterprise-level security: On the other hand, Authentication has a lovely feature. As a result, Impala is integrated with Kerberos and Hadoop security. Using the Sentry module, we can also ensure that appropriate users and applications have access to the right data.
- Retain Freedom from Lock-In: It is easily accessible, indicating that it is open-source (Apache License).
- Expand the Hadoop User-base: Furthermore, it provides the flexibility for more users to communicate with more data through a single database and metadata store from the source to analysis. It makes no difference whether those clients are using BI applications or SQL queries.
- Low Latent Results: We can use Impala even though we don't need low latent performance.
- Partial Data Analyzation: Use Impala to analyze the partial data.
- Quick Analysis: Also, when we have to carry out a quick analysis, we use Impala.
22. Explain about Impala Data types?
The following table describes the Impala data types.
- BIGINT: This datatype is used to store quantitative numbers and has a range of -9223372036854775808 to 9223372036854775807. This data type is utilized in altering and creating the table statements.
- BOOLEAN: This data type holds just true or false entries and is utilized in the column, defined by a table statement.
- CHAR: This data type is user-defined storage that is buffered with spaces and can store up to 255 characters.
- DECIMAL: This data type is used to alter and create table statements to hold decimal values.
- DOUBLE: This data type is being used to hold floating-point values in the positive or negative range. 4.94065645841246544e-324d -1.79769313486231570e+308.
- FLOAT: This data type holds single-precision floating numbers which are ranges in the positive or negative. 1.40129846432481707e-45 .. 3.40282346638528860e+38.
- INT: This data type holds 4-byte integers up to the range of -2147483648 to 2147483647.
- SMALLINT: This data type holds 2-byte integers up to the range of -32768 to 32767.
- STRING: These data types hold string values.
- TIMESTAMP: This data type is used to illustrate a point in time.
- TINYINT: It holds single-byte integer values which are a range of -128 to 127.
- VARCHAR: It holds a maximum(65, 535) length of variable-length characters.
- ARRAY: This data type is used to hold ordered elements which are variable numbers.
- Map: It is a complex data type that is used to hold key-value pairs which are variable numbers.
- Struct: It is used to illustrate multiple fields of a single item and a complex data type compared to other data types.
23. Is the Hdfs Block Size Minimized To Achieve Faster Query Results?
No, Impala cannot reduce the HBase or HDfs data sets block size to attain the query results fast. Because the size of the parquet file is quite substantial (1 GB earlier release, 256 MB in Impala 2.0 and later). When creating the parquet files we can regulate the size of the block using the PARQUET FILE SIZE query.
24. Tell us where you can find Impala Documentation?
Impala documentation has been incorporated into the CDH 5 documentation from Impala 1.3.0, adding to the original Impala documentation for usage with CDH 4. The fundamental Impala administrator and developer information is still available in the CDH 5 Impala documentation section. The associated CDH 5 guidelines contain information regarding Impala security, configuration, startup, and installation.
- Incompatible changes
- Security for Impala
- Upgrading Impala
- Known and fixed issues
- Starting Impala
- New features
- CDH Version and Packaging Information
- Installing Impala
- Configuring Impala
Frequently Asked Impala Interview Questions
25. How much memory is required for Impala to perform an operation?
Although Impala is not an in-memory database, you should expect the impalad daemon to consume a significant amount of physical RAM when working with large tables and huge result sets. Impala nodes should have at least 128 GB of physical memory. If it's possible, give Impala about 80% of your physical memory. The cache memory is utilized for an Impala operation is determined by a variety of factors, including:
- The table's data file format. The same data is represented by different file formats in more or fewer data files. Each file format's compression and encoding may necessitate a different amount of temporary RAM to decompress the data for analysis.
- Whether it was an INSERT or SELECT operation, Impala defragments and reads the data in 8 MB chunks, Parquet tables, for example, use relatively minimal RAM to query. Because the data for each data file (which might be hundreds of megabytes depending on the value of the PARQUET FILE SIZE query parameter) is maintained in memory until compressed, written in the disk, encoded, inserting into a Parquet database is a more memory-intensive operation.
- Whether the table is segmented or not, and whether or not partition pruning can be used in a query against a segmented table.
- If the ORDER BY clause is used, the final result set is sorted. Each Impala component searches and filters a subset of the whole data and then imposes the LIMIT to that subset of the dataset. If the sort operation needs more RAM than is allocated on any particular platform, Impala performs the sort using a local disk work area in Impala 1.4.0 and higher. The coordinator node receives all of the successful result sets and performs final sorting before applying the LIMIT clause to the overall result set.
26. Why does My Select statement fail in Impala?
The following points should be considered as a few reasons for Select statement fails:
- A timeout occurs when a single node experiences a capacity, network issue, or performance.
- When too much storage is used for a join query, then the query is automatically canceled.
- The way native code is created on each node to execute certain WHERE clauses in the query are affected by a low-level problem. for instance, generating machine instructions that are not allowed by the processor of a particular node. Consider temporarily switching off native code generation and retrying the query if the error message in the log suggests the reason was an invalid instruction.
- Input data with a comma-delimited that does not resemble the character defined in the FIELDS TERMINATED BY clause of the CREATE TABLE statement, such as a text data file with an incredibly long line or a parenthesis that does not resemble the character defined in the FIELDS TERMINATED BY clause of the CREATE TABLE statement.
27. Why does my insert statement fail in Impala?
When an INSERT statement fails, it's usually because a Hadoop component, usually HDFS, has reached its limit.
- Because HDFS allows you to open several files and associated threads at the same time, an INSERT into a segmented table can be a taxing operation. Impala 1.1.1 features various enhancements to more efficient distribute work, such as the values for each segment being produced by a particular node rather than each node's own data file.
- Certain statements in the SELECT phase of the INSERT command can make the execution plans more difficult and result in an inaccurate INSERT. Attempt to correlate the column data types of the input and output tables, for example, by using the ALTER TABLE... command. If necessary, REPLACE COLUMNS in the source table. Avoid using CASE statements in the SELECT phase of the query since they make the result values more difficult to predict than moving a column unmodified or using a built-in function.
- If you often perform such INSERT commands as part of your ETL workflow, be able to raise some HDFS installation settings restrictions, either locally during the INSERT or indefinitely.
- According to the file format of the target table, the resource use of an INSERT command can vary. The data for each segment is stored in storage until it reaches 1 gigabyte, at which point the data file is saved to memory. Inserting into Parquet columns and rows of tables is memory-intensive. When stats for the source table queried during the INSERT query are provided, Impala can share the workload for an INSERT command more effectively.
28. Explain how Impala metadata is managed?
Impala consists of two types of metadata: Both the Hive metastore's catalog information and the NameNode's file metadata. When an impala uses this metadata to design a query, it is currently lazily supplied and cached.
- After loading fresh data into Hive, the REFRESH command changes the information for a specific table. The INVALIDATE METADATA Command argument updates all information so Impala can detect new records and other Hive DML and DDL alterations.
- A specialized catalog system in the Impala 1.2 and higher transmit metadata changes caused by Impala DDL or DML expressions to all nodes, minimizing or deleting the INVALIDATE and REFRESH METADATA commands.
29. Explain about the most expensive opentions of Impala?
You can detect a buffer overflow if a query fails with a message stating "memory limit exceeded." The issue could be that a query is structured in such a way that Impala allocates more storage than you intend, or that the memory allocated for Impala on a given node has been exceeded. The following are some instances of memory-intensive query or table structures:
- INSERT statements into a table with many partitions utilizing dynamic partitioning. (This is especially true for tables in Parquet format because each partition's data is kept in memory until it achieves the size of the full block before being saved to disk.) Consider splitting such transactions into multiple INSERT queries, for example, to import the data one year at a time in place of all at once.
- GROUP BY a column with a single or maximum priority. In a GROUP BY query, Impala creates some handling structures for each individual value. The memory limit could be exceeded if we have millions of different GROUP BY values.
- Queries use large tables with dozens of columns, especially those containing a lot of STRING columns. Because a STRING value in Impala might be up to 32 KB, subsequent results during such searches may necessitate a large memory space allocation.
30. How does Impala achieve its performance improvements?
The following are the primary aspects that influence Impala's performance in comparison to other Hadoop components and technologies.
Impala does not use MapReduce. While MapReduce is the best general-purpose parallel processing architecture with numerous advantages, it is not meant to run SQL queries. Impala avoids MapReduce's inefficiencies in the following ways:
- Intermediate results are not written to disk by Impala. SQL queries are frequently translated into several MapReduce processes, with all subsequent data sets saved to storage.
- Impala eliminates the need for MapReduce to start up. MapReduce start-up time turns highly visible for interactive queries. Impala works as a daemon and requires no initial setup.
- Instead of fitting query plans into a map pipeline and reducing jobs, Impala can spread query plans more naturally. This helps Impala parallelize many steps of the query and evade unnecessary overheads like shuffle and sort.
31. Explain briefly what happens if the data set exceeds available memory?
The query is currently canceled if the memory needed for processing intermediate data on the node surpasses the actual amount to the Impala on that node. You may fine-tune join techniques for reducing the memory needed for the largest queries, and you can alter the memory allocated to Impala upon every node. In the future, we intend to offer arbitrary sorting and joins.
Take into consideration, however, that memory utilization is not dependent on the size of input data collection. The memory utilization for aggregations is the sum of the rows after clustering. Impala can use join techniques that divide big joined tables among the different nodes instead of transferring the complete table to every node, and the storage capacity for joins is the consolidated size of the tables excluding the largest table.
32. Give a brief explanation about the Update statement in Impala?
Impala presently lacks the UPDATE statement, which would be used to modify a tiny group of rows, a single row or a single column. Traditional UPDATE operations are ineffective or unfeasible because HDFS-based files utilized by ordinary Impala operations are intended for massive operations spanning several megabytes of information consecutively.
For achieving the same aims as the common UPDATE command while preserving performance and making layouts for the next queries, employ the following techniques:
- Use LOAD DATA, INSERT OVERWRITE, or explicit HDFS file transactions succeeded by a REFRESH expression for a table to replace the whole contents of a table or segment with updated information that you've already stored in a separate location. You can also utilize built-in procedures and variables in the INSERT command to alter copied data in a similar manner that you would in an UPDATE command, such as converting the mixed-case text to all lowercase or all uppercase.
- Utilise the HBase table and an INSERT VALUES query with the same identifier as the initial row to modify a single row. As HBase only returns the most recent row with a certain key-value when dealing with redundant keys, the input row essentially buries the prior one.
33. Can Impala be utilised for complex Event processing?
Complex Event Processing (CEP) is typically carried out by specialized stream-processing systems. Impala is the most similar to a relational database. As a result, it cannot be classified as a stream-processing system.
34. Can any Impala query be executed in Hive?
Yes. Impala queries can also be finished in Hive as well. There are a few significant variations in the way some requests are processed, though. Impala SQL is also a derivative of HiveQL, with some feature constraints, such as transformations.
35. On which host does Impala run?
However, Cloudera strongly advises that the impala service can be run on each DataNode for optimal performance. However, it is not a necessary prerequisite. If we have data frames with no Impala servers active on any of the sites hosting duplicates of those data frames, queries containing that data could be exceedingly inefficient since the data must be sent from one computer to another for processing by "remote reads." Impala, on the other hand, usually strives to avoid this situation.
Conclusion
We hope our Impala interview questions will help in your Impala interview preparation. Furthermore, if you have any queries or do you want to add any questions to the above list please comment to us.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Impala Training | Jul 21 to Aug 05 | View Details |
| Impala Training | Jul 25 to Aug 09 | View Details |
| Impala Training | Jul 28 to Aug 12 | View Details |
| Impala Training | Aug 01 to Aug 16 | View Details |

Viswanath is a passionate content writer of Mindmajix. He has expertise in Trending Domains like Data Science, Artificial Intelligence, Machine Learning, Blockchain, etc. His articles help the learners to get insights about the Domain. You can reach him on Linkedin














