- Home
- Blog
- Oracle DBA
- Oracle Architecture and Components

- Oracle DBA Interview Questions
- Oracle DBA Tutorial
- Bigfile Tablespace in Oracle
- How to Create TableSpaces - Oracle DBA
- Granting roles and privileges in Oracle DBA
- How to Create Profiles and Password Management in Oracle DBA
- Oracle Rename Tablespace - Dropping Table Space
- How to Specify nonstandard block sizes for tablespaces - Oracle DBA
- How to Tune and Setting the Undo Retention Period - Oracle DBA
- Listing privilege and role information in Oracle DBA
- Oracle Locally Managed Tablespace
- Control File in Oracle
- Managing the Redo Log - Oracle DBA
- Managing the sysaux tablespace - Oracle DBA
- Managing the undo tablespace - Oracle DBA
- Managing User Privileges and Roles - Oracle DBA
- Managing user roles - Oracle DBA
- Oracle Database Startup and Shutdown Procedure
- Revoking user privileges and roles - Oracle DBA
- Steps to Install Oracle Database 11g on Linux
- Temporary Tablespaces - Oracle DBA
- Oracle transportable tablespaces - DBA
- Transporting tablespaces between databases. a procedure and example - Oracle DBA
- Undo Retention
- Using transportable tablespaces - Oracle DBA
- How to View Tablespace in Oracle
- Relational vs Non-Relational Databases
In this post, you will learn about the ORACLE Architecture components such as Log Writer, DB Writer, etc (Background Processes), SGA, Buffer Cache, Shared Pool, etc (Memory Layout – Memory Buffer), Datafiles, Controlfiles, etc (Physical Oracle Layout). All these components, running together play an important part in the Oracle Architecture.
| Oracle Architecture - Table of Contents |
| If you would like to enrich your career as a Database Administrator(DBA), then enroll in “Oracle DBA Training”. This course will help you to achieve excellence in this domain. |
Oracle Architecture and Components
Oracle Memory Components
All components such as Shared Pool (Library Cache, Dictionary Cache), Buffer Cache, Online Redo Log file, Large Pool, Java Pool as well as a few other items are referred to as the System Global Area (SGA). And the place that stores information like bind variable values, sort areas, cursor handling, etc for a specific user is called Program Global Area (PGA).
The PGA is used to store only real values in place of bind variables for executing SQL statements. The combination of these two memories structure while they are running is called Oracle Instance.
- All components such as Log Writer (LGWR), DB Writer (DBWR), Checkpoint (CKPT), Recovery Process (RECO), Lock Process (LCKn), Archive Process (ARCH), System Monitor (SMON), and Program Monitor (PMON) are referred to as an Oracle Background processes.
- All components such as Server Parameter File (SPFILE), Parameter File (PFILE the INIT.ORA file), and control files, Datafiles, Password File, Archives, and Online Redo Log files are referred to as Oracle Database Components.
- All these Oracle architecture components running together allow users to read, write, and modify data in an Oracle database.
Now, the following are brief job descriptions for the above components.
1. SHARED POOL
- The Shared Pool contains the Library Cache and the Dictionary Cache as well as a few other items, which are not in the scope of this section.
- The Library Cache holds all users’ SQL statements, Functions, Procedures, and Packages. It stores the parsed SQL statement with its execution plan for reuse.
- The Dictionary Cache, sometimes also referred to as the Row Cache, holds the Oracle repository data information such as tables, indexes, columns definitions, usernames, passwords, synonyms, views, procedures, functions, packages, and privileges information.
2. BUFFER CACHE
- The Buffer Cache holds users’ data. Users query their data while they are in the Buffer Cache. If the user’s request is not in the Buffer Cache then the server process has to bring it from the disk. The smallest unit in the buffer cache is an Oracle block.
- The buffer cache can be increased or decreased by the granule unit. The smallest Granule Unit is 4Meg if the SGA size is less than 128Meg and the smallest Granule Unit becomes 16Meg if the SGA size is more than 128Meg.

3. REDO LOG BUFFER
- The Redo Log Buffer holds users’ entries such as INSERT, UPDATE, DELETE, etc (DML) and CREATE TABLE, DROP TABLE (DDL).
- The Redo Entries are information that will be used to reconstruct or redo, changes made to a database. The Log Writer writes the entries into the Online Redo Log files when a COMMIT occurs, every 3 seconds, or when one-third of the Redo Log Buffer is full.
- That will guarantee a database recovery to a point of failure if an Oracle database failure occurred.
4. LARGE POOL
The Large Pool holds information about the Recovery Manager (RMAN) utility when RMAN is running. If you use the Multi-threaded Server (MTS) process, you may allocate the Oracle Memory structure such that you can get the advantage of using the Large Pool instead of the Shared Pool.
- Notice that when you use dedicated servers, user-session information is housed in the PGA.
- The Multi-threaded Server process will be used when a user sends his/her request by using a shared server. A user’s request will be assigned to a dispatcher based on the availability of dispatchers. Then the dispatcher will send or receive requests from an assigned shared server.
- When you are running dedicated servers then the session information can be stored inside the process global area (PGA). The UGA is the user global area, which holds session-based information.
- When you are running shared servers then the session information can be stored inside the user global area (UGA) and when your session does some sorting, some of the memory allocated for sorting – specifically the amount defined by parameter sort_area_retained_size – comes from the SGA and the rest (up to sort_area_size) comes from the PGA (Sinn).
- This is because the sort_area_retained_size may have to be held open as the pipeline to return results to the front-end, so it has to be located where the session can find it again as the session migrates from server to server.
- On the other hand, the sort_area_size is a complete throwaway, and by locating it in the PGA, Oracle can make the best use of available memory without soaking the SGA. To avoid sessions grabbing too much memory in the SGA when running MTS/shared server, you can set the private_sga value in the resource_limit for the user.
- This ensures that any particularly greedy SQL that (for example) demands multiple allocations of sort_area_retained_size will crash rather than flushing and exhausting the SGA.
Oracle Background Processes
1. Log Writer Background Process (LGWR)
The LGWR’s job is to write the redo user’s entries from the Redo Log Buffer when the buffer exceeds one-third of the Redo Log Buffer, every 3 seconds, or when a user executes the commit SQL statement.
2. DB Writer Background Process (DBWR)
The DBWR’s job is to write all the blocks that were marked as dirty blocks to the Oracle database on disks (datafiles) whenever the checkpoint process signals it. Notice that when the Online Redo Log Files are filled the checkpoint process will signal a DBWR to write the entire dirty block into the Oracle database.
[ Related Article: Undo Retention Oracle ]
3. CheckPoint Background Process (CKPT)
The Checkpoint signals DB writers to write all dirty blocks into the disk. The Checkpoint will occur either by a specifically defined time, size of the Online Redo Log file used by Oracle DBA, or when an Online Redo log file will be switched from one log file to another.
The following are the parameters that will be used by a DBA to adjust the time or interval of how frequently its checkpoint should occur on its database.
LOG_CHECKPOINT_TIMEOUT = 3600 # every one hour
LOG_CHECKPOINT_INTERVAL=1000 # number of Operating System blocks4. Recovery Background Process (RECO)
The RECO will be used only if you have a distributed database. You use this process to recover a database if a failure occurs due to a physical server problem or communication problem.
5. LOCK Background Process (LCKN)
The LCKn background process will be used if you have multiple instances accessing only one database. An example of that is a Parallel Server or Real Application Clusters.
6. ARCHIVE Background Process (ARCH)
This background process archives the Online Redo Log file when you are manually or automatically switching an Online Redo Log file. An example of manually switching is:
ALTER SYSTEM SWITCH LOGFILE or ALTER SYSTEM ARCHIVE LOG CURRENT.
[ Check out: Bigfile Tablespace in Oracle ]
7. System Monitor Background Process (SMON)
- When you start your database, the SMON will make sure that all data files, control files, and log files are synchronized before opening a database.
- If they are no, it will perform an instant recovery. It will check the last SCN that was performed against the data files.
- If it finds that there are transactions that were not applied against the data file, then it will recover or synchronize the data file from either the Online Redo Log files or the Archive Log files.
- The smaller Online Redo log files will bring a faster database recovery.
8. Program Monitor Background Process (PMON)
- A user may be disconnected either by canceling its session or by a communication link.
- In either act, the PMON will start and perform an action to clean the reminding memory allocation that was assigned to the user.
Oracle Physical Database Components
Parameter File (PFILE – INIT.ORA)
- You can read or change this file. The file contains all Oracle parameters file to configure a database instance. In this file, you can reset and change the Buffer Cache size, Shared Pool size, Redo Log Buffer size, etc.
- You use this file to increase or decrease the size of the System Global Area (SGA). You also can change the location of your control files, the mode of a database such as an archive log mode or no archive log mode, and many other parameter options that you will learn in the course of this book.
Server Parameter File (SPFILE)
- This file is in binary format and you cannot read this file. You should create the Server Parameter file (CREATE SPFILE FROM PFILE) and startup your database using the file if you want to change database parameters dynamically.
- There are some parameters that you still need to shut down and startup the database if you want to make the parameter in effect. You will learn all about these parameters in the course of this book.
| Learn Top Oracle DBA Interview Questions and Answers that help you grab high-paying jobs |
Oracle Control Files
You cannot read this file and it is in a binary format. If you want to see the content of the control file or the layout of your database, you should use the ALTER DATABASE BACKUP
CONTROLFILE TO TRACE statement. It writes a trace file into the ORACLE_BASE directory.
It contains information on the structure of your database layout, database name, last System Change Number (SCN) number, your database mode (archive log mode or no archive log mode), the maximum number of log files, the maximum number of log members, the maximum number of instances, maximum of a number of data files, the location of the database Online Redo Log files, and backup information.
1. Data Files
- All the Oracle data information will be stored in the Oracle data files. A data file is one of the physical layout components of a database.
- A tablespace (logical database layout) contains one or more data files (physical database layout). You may have one or more extents in a data file. An extent is a collection of blocks.
- A block is the smallest unit in an Oracle. A tablespace is a collection of segments. Think of a segment like an object in an Oracle database. A Segment is a collection of Oracle blocks.
2. Password File
To use the password file you should set the REMOTE_LOGIN_PASSWORD parameter to the exclusive or shared mode in the Parameter File (Example: REMOTE_LOGIN_PASSWORD=EXCLUSIVE). A password file is an external Oracle file and to create it you should run the ORAPWD utility from the operating system.
Example
$ORAPWD FILE=%ORACLE_HOMEb0 orapw.pwd par PASSWORD=mypass
ENTRIES=3The ENTRIES parameter specifies the number of user entries allowed for the password file. Now, the DBA can be connected to the database as a user with sysdba privileges as shown here:
SQL> connect sys as sysdba
Password:3. Online Redo Log Files
- The online Redo Log files hold the Redo Entries. You should have at least two or more Redo Log Groups. Each group may have more than one member.
- It is a good practice to multiplex Online Redo Log members. The Redo Entries are information that will be used to reconstruct or redo, changes made to a database.
- The Log Writer writes the entries into the Online Redo Log files when a COMMIT occurs, every 3 seconds, or when one-third of the Redo Log Buffer is full.
- That will guarantee a database recovery to a point of failure if an Oracle database failure occurred.
4. Archive Online Redo Log Files
- When an Online Redo Log File fills out, the checkpoint will force DBWR to write into the Oracle datafiles and also the archive process copies the log file to an archive destination directory.
- That will guarantee a database recovery to a point of failure if an Oracle database failure occurred.
[ Related Article: Oracle Locally Managed Tablespace ]
Oracle Scenario
Assuming that you have a user who is updating a record from her SQLPLUS. The following SQL statement is here:
SQL transaction:
SQL> UPDATE emp SET sal = 1000 WHERE empno = 100;
SQL> COMMIT;Let us see what would happen when the oracle processes it.
Step 1: The user will type the above SQL statement and press the enter key. This user either is connected to the database by a dedicated server or shared server (MTS).
If the user is using multi-threaded servers then her request will be given to a dispatcher and the dispatcher will give the request to a shared server. If the user is using a dedicated server then the dedicated server will be all hers. Now, her user process is talking to a shared or dedicated server.
Step 2: Now, the user’s SQL statement will be parsed and assigned an executed plan to be compiled in the Library Cache in the Shared Pool. In order for the SQL statement to be compiled, Oracle needs to make sure its table and columns are valid and the user did not violate any security information.
It goes to the Dictionary Cache known as Raw Cache to get the l necessary information about the table. If there was no syntax problem and its table and columns were valid, then the SQL statement will be parsed successfully and the execution plan will be performed.
Step 3: Now, there is no problem. The Server process fetches the record. If the data or record is in the Buffer Cache then an update process will be applied to it and the block will be marked as a dirty block.
Notice that before the user saves the update, the before block images are in the UNDO segment. When the user executes a commit statement or more than one-third of the Redo Log buffer has filled out, then LGWR writes the user’s entries from the redo log buffer to the Online Redo Log files.
Still, the block may not be stored in the database. In the case that the record is not in the buffer cache, the server process reads the block containing the record from the data file (disk) and places it into the buffer cache.
Step 4: Now, the checkpoint process will be activated based on the LOG_CHECKPOINT_INTERVAL,
LOG_CHECKPOINT_TIMEOUT parameters, or maybe due to a log switch. This action will force DBWR or CKPT to write all dirty blocks in the database (data file).

Figure 1
Logical Database Structure
An ORACLE database’s logical structure is determined by:
- One or more tablespaces.
- The database’s schema objects (e.g., tables, views, indexes, clusters, sequences, stored procedures).
The logical storage structures, including tablespaces, segments, and extents, dictate how the physical space of a database is used. The schema objects and the relationships among them form the relational design of a database.
1. TableSpaces and Data Files
- Tablespaces are the primary logical storage structures of any ORACLE database. The usable data of an ORACLE database is logically stored in the tablespaces and physically stored in the data files associated with the corresponding tablespace.
- Figure 2 illustrates this relationship. Although databases, tablespaces, data files, and segments are closely related, they have important differences.
- Each tablespace in an ORACLE database is comprised of one or more operating system files called data files. A tablespace’s data files physically store the associated database data on disk.
2. Databases and TableSpaces
- An ORACLE database is comprised of one or more logical storage units called tablespaces. The database’s data is collectively stored in the database’s tablespaces.
- A database’s data is collectively stored in the data files that constitute each tablespace of the database.
- For example, the simplest ORACLE database would have one tablespace, with one data file. A more complicated database might have three tablespaces, each comprised of two data files (for a total of six data files).
3. Schema Objects, Segments, and TableSpaces
- When a schema object such as a table or index is created, its segment is created within a designated tablespace in the database. For example, suppose a table is created in a specific tablespace using the CREATE TABLE command with the TABLESPACE option.
- The space for this table’s data segment is allocated in one or more of the data files that constitute the specified tablespace. An object’s segment allocates space in only one tablespace of a database.
4. Data - Files - Tablespace

Figure 2 Data files and Table Spaces
A database is divided into one or more logical storage units called tablespaces. A database administrator can use tablespaces to do the following:
- Control disk space allocation for database data.
- Assign specific space quotas for database users.
- Control availability of data by taking individual tablespaces online or offline.
- Perform partial database backup or recovery operations.
- Allocate data storage across devices to improve performance.
Every Oracle database contains a tablespace named SYSTEM, which is automatically created when the database is created.
The SYSTEM tablespace always contains the data dictionary tables for the entire database. You can query these data dictionary tables to obtain pertinent information about the database; for example, the names of the tables that are owned by you or ones to which you have access.
- Data files associated with a tablespace store all the database data in that tablespace. One or more data files form a logical unit of database storage called a tablespace.
- A data file can be associated with only one tablespace, and only one database.
- After a data file is initially created, the allocated disk space does not contain any data; however, space is reserved to hold only the data for future segments of the associated tablespace – it cannot store any other program’s data.
- As a segment (such as the data segment for a table) is created and grows in a tablespace, ORACLE uses the free space in the associated data files to allocate extents for the segment.
- The data in the segments of objects (data segments, index segments, rollback segments, and so on) in a tablespace are physically stored in one or more of the data files that constitute the tablespace.
- Note that a schema object does not correspond to a specific data file; rather, a data file is a repository for the data of any object within a specific tablespace.
- The extent of a single segment can be allocated in one or more data files of a tablespace (see Figure 3); therefore, an object can “span” one or more data files.
- The database administrator and end-users cannot control which data file stores an object.
Oracle Data Blocks, Extents, and Segments
ORACLE allocates database space for all data in a database. The units of logical database allocations are data blocks, extents, and segments. Figure 3 illustrates the relationships between these data structures.
- Data Blocks: At the finest level of granularity, an ORACLE database’s data is stored in data blocks (also called logical blocks, ORACLE blocks, or pages). An ORACLE database uses and allocates free database space in ORACLE data blocks. Figure 4 illustrates a typical ORACLE data block.
- Extents: The next level of logical database space is called an extent. An extent is a specific number of contiguous data blocks that are allocated for storing a specific type of information.
- Segments: The level of logical database storage above an extent is called a segment. A segment is a set of extents that have been allocated for a specific type of data structure, and all are stored in the same tablespace.
For example, each table’s data is stored in its own data segment, while each index’s data is stored in its own index segment. ORACLE allocates space for segments in extents.
Therefore, when the existing extents of a segment are full, ORACLE allocates another extent for that segment. Because extents are allocated as needed, the extents of a segment may or may not be contiguous on disk, and may or may not span files. An extent cannot span files, though.

Figure 3 The Relationship Among Segments, Extents, and Data Blocks
- ORACLE manages the storage space in the data files of a database in units called data blocks.
- A data block is the smallest unit of I/O used by a database. A data block corresponds to a block of physical bytes on a disk, equal to the ORACLE data block size (specifically set when the database is created – 2048).
- This block size can differ from the standard I/O block size of the operating system that executes ORACLE.
- The ORACLE block format is similar regardless of whether the data block contains a table, index, or clustered data. Figure 4 shows the format of a data block.
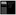
Figure 4 Data Block Format
1. Header (Common and Variable): The header contains general block information, such as block address, and segment types, such as data, index, or rollback. While some block overhead is fixed in size (about 107 bytes), the total block overhead size is variable.
2. Table Directory: The table directory portion of the block contains information about the tables having rows in this block.
3. Row Directory: This portion of the block contains row information about the actual rows in the block (including addresses for each row piece in the row data area). Once the space has been allocated in the row directory of a block’s header, this space is not reclaimed when the row is deleted.
4. Row Data: This portion of the block contains a table or index data. Rows can span blocks.
5. Free Space: Free space is used to insert new rows and for updates to rows that require additional space (e.g., when a trailing null is updated to a non-null value). Whether issued insertions actually occur in a given data block is a function of the value for the space management parameter PCTFREE and the amount of current free space in that data block.
- Space Used for Transaction Entries Data blocks allocated for the data segment of a table, cluster, or index segment of an index can also use free space for transaction entries.
- Two space management parameters, PCTFREE, and PCTUSED allow a developer to control the use of free space for inserts of and updates to the rows in data blocks.
- Both of these parameters can only be specified when creating or altering tables and clusters (data segments). In addition, the storage parameter PCTFREE can also be specified when creating or altering indices (index segments).
- The PCTFREE parameter is used to set the percentage of a block to be reserved (kept free) for possible updates to rows that already are contained in that block. For example, assume that you specify the following parameter within a CREATE TABLE statement:
PCTFREE 20
- This states that 20% of each data block used for this table’s data segment will be kept free and available for possible updates to the existing rows already within each block.
- After a data block becomes full, as determined by PCTFREE, the block is not considered for the insertion of new rows until the percentage of the block being used falls below the parameter PCTUSED.
- Before this value is achieved, the free space of the data block can only be used for updates to rows already contained in the data block. For example, assume that you specify the following parameter within a CREATE TABLE statement.
PCTUSED 40
In this case, a data block used for this table’s data segment is not considered for the insertion of any new rows until the amount of used space in the blocks falls to 39% or less (assuming that the block’s used space has previously reached PCTFREE).
No matter what type, each segment in a database is created with at least one extent to hold its data. This extent is called the segment’s initial extent.
- If the data blocks of a segment’s initial extent become full and more space is required to hold new data, ORACLE automatically allocates an incremental extent for that segment.
- An incremental extent is a subsequent extent of the same or incremented size of the previous extent in that segment.
- Every non-clustered table in an ORACLE database has a single data segment to hold all of its data. The data segment for a table is indirectly created via the CREATE TABLE/SNAPSHOT command.
- Storage parameters for a table, snapshot, or cluster control the way that a data segment’s extents are allocated.
Setting these storage parameters directly via the CREATE TABLE/SNAPSHOT/CLUSTER or ALTER TABLE/SNAPSHOT/CLUSTER commands affects the efficiency of data retrieval and storage for that data segment.
| Explore Oracle DBA Sample Resumes! Download & Edit, Get Noticed by Top Employers! |
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Oracle DBA Training | Jul 25 to Aug 09 | View Details |
| Oracle DBA Training | Jul 28 to Aug 12 | View Details |
| Oracle DBA Training | Aug 01 to Aug 16 | View Details |
| Oracle DBA Training | Aug 04 to Aug 19 | View Details |

Ravindra Savaram is a Technical Lead at Mindmajix.com. His passion lies in writing articles on the most popular IT platforms including Machine learning, DevOps, Data Science, Artificial Intelligence, RPA, Deep Learning, and so on. You can stay up to date on all these technologies by following him on LinkedIn and Twitter.














