
- Comparing Application Servers: Jboss and Tomcat
- Jboss Clustering
- JBoss Interview Questions
- JBoss Tutorial
- JBOSS Admin Console
- Adding a JMS destination
- Adding JSF components
- Advanced deployment strategies
- Clustering entities - JBoss
- Configuring a JBoss AS Domain
- Configuring Data Persistence - JBoss
- Configuring Enterprise Java Beans - JBoss
- Configuring Enterprise Services
- Configuring Session Cache Containers in JBOSS
- Configuring the Application Server
- Configuring the application server logging
- Configuring the domain controller
- Configuring the domain.xml file
- Configuring the EJB components
- Configuring The HTTP Connector
- Create an OpenShift Express domain - JBoss
- Creating and deploying a web application in JBoss
- Deploying applications on a JBoss AS domain
- Deploying Applications on JBoss AS 7
- Deploying applications on JBoss AS standalone
- Deploying the web application - JBoss
- JBOSS Dynamic Metrics
- Executing scripts in a file - JBoss
- Installing the JDBC driver
- JBoss AS 7 classloading explained
- JBoss Web Server Configuration in JBoss
- JBoss Load Balancing Web Applications
- Load-balancing with mod_cluster
- Management interfaces - JBoss
- Managing Mod Cluster With CLI In JBoss
- Securing Web Applications In JBoss
- JBoss SetUp - Cluster Of Domain Servers
- Cloud Computing Vs Grid Computing
- JBoss Testing Mod Cluster
- JDBC Interview Questions

Now that you have grasped the basic concepts of the new configuration file, we will have a look at the peculiarities of single services. Discussing all single subsystems in a single chapter is a daunting task for both the author and for those who will read it later. That’s why we had to find criteria for approaching all subsystems gradually to make reading interesting and easy-to-understand.
In the following image, you can find a rough representation of core JBoss AS 7 subsystems
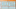
So, as a first taste of the application server, we will explore the areas that are highlighted in bold in this screenshot. These include the following core application server subsystems:
- The Thread Pool subsystem
- The JBoss Logging subsystem
Let’s see each subsystem in a separate section.
Configuring the Thread Pool subsystem
Thread Pools address two different problems: they usually deliver improved performance when executing large numbers of asynchronous tasks, due to reduced per-task invocation overhead, and they provide a means of bounding and managing the resources, including Threads, consumed when executing a collection of tasks.
In the earlier releases of the application server, the Thread Pool configuration was centralized in a single file or deployment descriptor. This approach was maintained up to the first snapshots of the new application server. Since the 7.0.0 CR1 release, the individual subsystems that use Thread Pools manage their own Thread configuration.
By appropriately configuring the Thread Pool section, you can effectively tune the specific areas that use that kind of Pool to deliver new tasks. The application server Thread Pool configuration can include the following elements:
- Thread factory configuration
- Bounded Threads configuration
- Unbounded Threads configuration
- Queueless Thread Pool configuration
- Scheduled Thread configuration
Let’s see in detail every single element:
Configuring the Thread factory
A Thread factory (implementing java.util.concurrent.ThreadFactory ) is an object that creates new Threads on demand. Using Thread factories removes hardwiring of calls to new Thread, enabling applications to use special Thread subclasses, priorities, and so on.
The Thread factory is not included by default in the server configuration as it relies on defaults, which you will hardly need to modify. Nevertheless, we will provide a sample configuration of it for the experienced user who requires complete control of the Thread configuration.
So, here’s an example of a custom Thread factory configuration:
And here are the possible attributes that you can use when defining a Thread factory.
The name attribute is the name of the created Thread factory.
- The optional priority attribute may be used to specify the Thread priority of created Threads.
- The optional group-name attribute specifies the name of the Thread group to create for this Thread factory.
The thread-name-pattern is the template used to create names for Threads. The following patterns may be used:
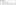
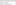
Bounded Thread Pool
A bounded Thread Pool is the most common kind of Pool used by the application server, as it helps prevent resource exhaustion by defining a constraint on the Thread Pool’s size; the other side of the medal is that this kind of Pool is also the most complex to use. Its inherent complexity derives from the fact that it maintains both a fixed-length queue and two Pool sizes: a core size and a maximum size.
Each time a new task is submitted, if the number of running Threads is less than the core size, a new Thread is created. Otherwise, if there is room in the queue, the task is queued.
If none of these options are viable, the executor needs to evaluate if it can still create a new Thread. If the number of running Threads is less than the maximum size, a new Thread is created. Otherwise, the blocking attribute comes into play. If blocking is enabled, the caller blocks until a room become available in the queue.
Frequently asked Jboss Interview Questions
If blocking is not enabled, the task is assigned to the designated hand-off executor, if one is specified. In the absence of a designated hand-off, the task will be rejected. The following image summarizes the whole process, showing how all the pieces fit together:
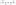
And here’s a sample of bounded Thread Pools, which is included in the configuration:
This is a short description of each attribute:

Tip
Performance focus
Queue size and Pool size are two samples of performance trade-off for each other. When using a small Pool with a large queue, you cause to minimize the CPU usage, OS resources, and context-switching overhead. It can, however, produce an artificially low throughput. If tasks are strongly I/O bound (and thus frequently blocked), a system may be able to schedule time for more Threads than you otherwise allow. Use of small queues generally requires larger Pool sizes, which keeps the CPUs busier but may encounter unacceptable scheduling overhead, which also decreases throughput.

Unbounded Thread Pool
This other kind of Thread Pool executor follows a simpler (but riskier!) approach; that is, it always accepts new tasks. In practice, the unbounded Thread Pool has a core size and a queue with no upper bound. When a task is submitted, if the number of running Threads is less than the core size, a new Thread is created. Otherwise, the task is placed in a queue. If too many tasks are allowed to be submitted to this type of executor, an out of memory condition may occur.
Due to its inherent risk, unbounded Thread Pools are not included by default in the server configuration. We will provide a sample here, with only one recommendation: don’t try this at home, kids!
If you want to know more about the meaning of each Thread Pool element, you can refer to the bounded Thread Pool table.
Queueless Thread Pool
As its name implies, this is a Thread Pool executor with no queue. Basically, this executor short-circuits the same logic of the bounded Thread executor, as it does not attempt to store the task in a queue.
So, when a task is submitted, if the number of running Threads is less than the maximum size, a new Thread is created. Otherwise, if blocking is enabled, the caller blocks until another Thread completes its task and accepts the new one. If blocking is not enabled, the task is assigned to the designated hand-off executor, if one is specified. Without any designated hand-off, the task will be rejected.
Queueless executors are also not included by default in the configuration file; we will, however, provide a sample configuration here:
Scheduled Thread Pool
The server-scheduled Thread Pool is used for activities on the server-side that require running periodically or with delays. It maps internally to a java.util.concurrent.ScheduledThreadPoolExecutor instance.
This type of executor is configured with the scheduled-thread-pool executor element:
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| JBoss Training | Aug 04 to Aug 19 | View Details |
| JBoss Training | Aug 08 to Aug 23 | View Details |
| JBoss Training | Aug 11 to Aug 26 | View Details |
| JBoss Training | Aug 15 to Aug 30 | View Details |

Ravindra Savaram is a Technical Lead at Mindmajix.com. His passion lies in writing articles on the most popular IT platforms including Machine learning, DevOps, Data Science, Artificial Intelligence, RPA, Deep Learning, and so on. You can stay up to date on all these technologies by following him on LinkedIn and Twitter.


