
- Comparing Application Servers: Jboss and Tomcat
- Jboss Clustering
- JBoss Interview Questions
- JBOSS Admin Console
- Adding a JMS destination
- Adding JSF components
- Advanced deployment strategies
- Clustering entities - JBoss
- Configuring a JBoss AS Domain
- Configuring JBoss Core Subsystems
- Configuring Data Persistence - JBoss
- Configuring Enterprise Java Beans - JBoss
- Configuring Enterprise Services
- Configuring Session Cache Containers in JBOSS
- Configuring the Application Server
- Configuring the application server logging
- Configuring the domain controller
- Configuring the domain.xml file
- Configuring the EJB components
- Configuring The HTTP Connector
- Create an OpenShift Express domain - JBoss
- Creating and deploying a web application in JBoss
- Deploying applications on a JBoss AS domain
- Deploying Applications on JBoss AS 7
- Deploying applications on JBoss AS standalone
- Deploying the web application - JBoss
- JBOSS Dynamic Metrics
- Executing scripts in a file - JBoss
- Installing the JDBC driver
- JBoss AS 7 classloading explained
- JBoss Web Server Configuration in JBoss
- JBoss Load Balancing Web Applications
- Load-balancing with mod_cluster
- Management interfaces - JBoss
- Managing Mod Cluster With CLI In JBoss
- Securing Web Applications In JBoss
- JBoss SetUp - Cluster Of Domain Servers
- Cloud Computing Vs Grid Computing
- JBoss Testing Mod Cluster
- JDBC Interview Questions
In this article, we have enlightened the essential Concepts like JBoss Introduction, Overview, Architecture, Structure, and Life-Cycle, etc. which will help you understand About JBoss Tutorial
JBoss Tutorial - An Ultimate Guide for Beginners
1. JAVA EE Overview and Architecture
1.1 What is Java EE?
- Java EE is an open and standards-based platform for developing, deploying, and managing multi-tier, web-enabled, server-centric, and component-based enterprise applications
- As a super-set of Java SE, Java EE adds additional specifications, libraries, documentation, and tools.
1.2 Open and Standard-based
- Single specification, multiple competing implementations
- Implementations available as both OSS/free and high-end commercial
- Vast community resources: books, tutorials, guides, examples, etc.
- Large developer pool
- Application portability
- Apache Tomcat (Servlet/JSP container only)
- Oracle Web Logic
- IBM Websphere
- JBoss AS
- Oracle Application Server 10g
- Glassfish application server
- SAP AG Web Application Server
- Sun Java System Application Server
1.3 Multi-tier
OO framework for integrating together:
- Clients (e.g. web browsers)
- Access and presentation components
- Business components (e.g. e-commerce business logic)
- Data-stores (e.g. RDBMS)
System-level separation of concerns

Figure 1. Multi-tier Architecture
- Client Tier usually consists of thin clients like web browsers and it makes the request into the Web Tier over HTTP.
- Client Tier (B2B) is a set of external applications that makes requests into the Business Tier through Web Services over SOAP or directly through Java’s RMI.
- Web Tier is usually implemented with Servlets, JSPs, and simple JavaBeans, based on the Model-View-Controller design pattern.
- Business Tier is composed of EJBs and/or plain old Java objects (POJOs).
- Data Access Tier is either managed by the applications (e.g. BMP, DAO), O/R mapping tools (e.g. Hibernate), or through Container-Managed Persistence (CMP).
- Connector/Messaging Tier allows asynchronous access to legacy systems or other external systems.
- Legacy/External Tier consists of enterprise information systems.
- Data Tier is usually composed of RDBMS and/or LDAP Directory Servers.
1.4 Web-Enabled
- By using the Servlet/JSP technology, Java EE applications are automatically web-enabled:
a) Efficient, Java/OO, Easy, I18N, MVC
- Complete support for web-services
a)Clients
b)End-points
| If you want to enrich your career and become a professional in JBoss, then Enrol Our "JBoss Certification Training" This course will help you to achieve excellence in this domain. |
1.5 Server Centric
- Java EE apps run within a Java EE application server that provides all middle-tier services.
- Thin (web-based) clients
- Support for rich clients through RMI, Web Services, etc.
a) The design of such clients is beyond the scope of Java EE
1.6 Component-Based Distributed Architecture

Java EE applications and services are built out of components that can run in single or multiple (distributed) Java EE Application Server instances.
1.7 Enterprise Applications
- Java EE applications are made up of:
a) Presentation logic
b) Business logic
c) Data access logic and model - Java EE facilitates separation of concerns
The goal of Java EE is to significantly reduce the cost, time, and complexity of developing and managing multi-tier enterprise applications
1.8 Java EE Services
Java EE Application Server handles:
- Concurrency, Scalability, Availability
- Security
- Persistence, Transactions
- Life-Cycle Management
Application Components focus on:
- Presentation
- Business Logic

2. Overview of JBoss Application Server
2.1. JBoss Organization
1. JBoss – The Professional Open Source Company
2. Focuses on middleware software and services – JBoss Enterprise Middleware Suite (JEMS)
3. Software is open source and free
4. Makes money on services
5. Acquired by Red Hat in April 2006 for $420M
JBoss Enterprise Middleware Suite (JEMS):
- Application Server (JBoss AS, Tomcat)
- O/R Mapping and Persistence (Hibernate)
- Portal Platform (JBoss Portal)
- Business Process Management and Rules (JBoss jBPM, JBoss Rules)
- Object/Data Cache (JBoss Cache)
- Distributed Transaction Management (JBoss Transactions)
- Development Tools (JBoss Tools plugin for Eclipse)
2.2. JBoss AS Background
- Established in 1999 as an open-source EJB container
- Version 2.x becomes a full J2EE application server
- Version 3.x is the production series – based on JMX microkernel and service-oriented architecture (May 2002)
- Version 4.x explores the aspect-oriented middleware services, adds support for EJB 3 (September 2004)
- Version 5.x comes with JBoss Microcontainer (also a stand-alone project) and replaces JMX 6. Microkernel of the 3.x and 4.x JBoss series (December 2008)
- Version 6.x to add support for Java EE 6 APIs and Profiles. Replaces JBoss Messaging with HornetQ (6.0.0.M3 released in April 2010)
2.3. Highlights of JBoss AS
- Enterprise-class reliability, performance, scalability, and high-availability
- Zero-cost product license, to download, use, embed, and distribute
- Open-source
- Built for standards – provides a safe choice for portable applications (interoperable)
- Service-oriented architecture provides consistency, makes it embeddable
- Aspect-oriented architecture simplifies interaction with middleware services
- 24×7 professional support by the core development team
- Active developer community
- Over 5 million downloads
- 25+% market share
Note:
JBoss AS 5 has passed the Java EE 5 Technology Compatibility Kit (TCK) test suite (100%).
2.4. What is new in JBoss AS 5?
1. New kernel ⇒JBoss Microcontainer
a) Is a refactoring of old JMX Microkernel (JBoss AS 3.x and 4.x)
b)The core of JBoss AS 5
2. New messaging provider ⇒JBoss Messaging
a) Replaces old JBossMQ (shipped with JBoss AS 4.x series)
3. One of the first application servers to implement EJB 3.0 specification (dating back to 4.x series)
4. Reliable transaction manager ⇒JBoss TS
a) More than 20 years of expertise in transaction management
5. JBoss Web-based on Apache Tomcat 6.0
6. JBoss WS 3.0 (support for JAX-WS/JAX-RPC)
a) Can be replaced by Sun Metro or Apache CXF for example
7. Two new configurations:
a) Standard: Java EE compliant configuration.
b) Web: Provides support for JTA/JCA and JPA in addition to the Servlet/JSP container. The server can only be accessed through the http port.
Visit here to learn JBoss Training in Hyderabad
2.5. JBoss AS Architecture
“JBoss AS is assembled from a set of independent, yet cooperating components and services that are neatly packaged and fully hot-deployable. It is architected to be seamlessly embeddable in applications, and the nature of its embedding is completely customizable to the requirements of the application itself.
Only the critical and necessary application server components, therefore, need to be brought along as part of the application’s baseline footprint. Developers can also easily create and add their own services to the system, thus ensuring that custom services exhibit the same consistent behavior as the JBoss standard set of services.”
Figure 2. JBoss AS 4.x Architecture
2.6. JBoss Microcontainer Layer
JBoss Microcontainer is an inversion of control (IoC) framework. IoC frameworks let you create, configure, and wire up simple Java objects (POJOs). Classes don’t need special coding to be usable. The objects created usually represent the modules of your application.
- Replaces JMX-based Microkernel, though still supports all JMX Microkernel features
- IoC framework similar to Spring IoC
- POJO based kernel (no need for Standard/XMBean or MBeanProxy)
- Simplified and improved lifecycle management
- Additional control over dependencies
- Transparent AOP integration
- Virtual File System (VFS)
- Virtual Deployment Framework
- OSGi class-loading
2.7. Services Layer
- Service-oriented architecture – service is either defined as a POJO or a JMX Managed Bean (use the JMX kernel, still available in JBoss 5.x but is created by JBoss Microcontainer).
- Services are hot-pluggable
- Makes it possible to tune the system for just the required services to lower the overall footprint (easier to secure and tune)
- Easy to define new services and package them as SARs (service archives) or JARs (Java ARchives)
Examples: Servlet/JSP container, EJB container, transaction management, messaging, connection pooling, security, etc.
2.8. Aspect Layer
- Increase the modularity of an application by allowing the separation of cross-cutting concerns (e.g logging is often required in many parts of your application).
- Based on aspect-oriented programming model (AOP)
- Defines cross-cutting simple-to-use services
- Makes it possible to add object persistence, caching, replication, remoteness, security, etc. late in the development cycle by annotating existing plain-old-java-objects (a.k.a POJOs)
Note:
Available since JBoss AS 4
2.9. Application Layer
- This is where Java EE applications reside
- This layer deals with the business logic while leaving the container services up to JBoss AS
- Portable – Independent of JBoss AS
2.10. JBoss AS Services
- JBoss Microcontainer: POJOs services container
- JBoss Microkernel: JMX MBean server (One of the primary POJOs created by JBoss Microcontainer)
- Aspect: oriented Framework
- Web Application Services: based on Tomcat (Servlet, JSP, JSF)
- Enterprise Services: EJB, ORB, JNDI, JTA
- Web Services: based on SOAP, WSDL, UDDI, and XML
- Messaging Services: JMS, JDBC, JCA
- Persistence Services: Hibernate O/R mapping and transparent persistence
- HA Services: clustering, fail-over, load-balancing, distributed deployments
- Security Services: based on JAAS
- Console Services: monitoring, configuration, deployment, management, lifecycle
2.11. JBoss AS Requirements
| JBoss 3.2.x | JBoss 4.x | JBoss 5.x | |
| Java (JDK) | 1.3+ | 1.4-1.5+ | 1.5+ |
| OS/Platform | Any Java-compliant | Any Java-compliant | Any Java-compliant |
| Memory – RAM | 128MB | 512MB | 512MB |
| CPU | 266MHz | 400MHz | 400MHz |
| Disk | 100MB | 100MB | 100MB |
| DB (Optional) | Any JDBC-Compliant | Any JDBC-Compliant | Any JDBC-Compliant |
3. Installing JBoss AS
3.1. Getting and Installing Java
- Download Java SE 6 JDK from HTTP://JAVA.SUN.COM/JAVASE/DOWNLOADS/INDEX.JSP or HTTP://JAVA.SUN.COM/PRODUCTS/ARCHIVE/ (for Java SE 5 JDK)
- On UNIX run the installer or uncompress the distribution into a directory of your choice
- On Windows, run the installer
a) Avoid installing Java into a directory that contains spaces or other special characters (e.g. under C: Program Files)
b) You can choose not to install “Public JRE”, demos, and source components
3.2. Configuring Java
- Set JAVA_HOME to point to the directory where you installed Java and add $JAVA_HOME/bin to your PATH
a) On Windows, add JAVA_HOME System Variable under Start -> Settings -> Control Panel -> System -> Advanced -> Environmental Variables and prefix the existing PATH variable with %JAVA_HOME%bin;.
b) On UNIX-like systems, make these changes in your shell’s configuration file (e.g. ~/.bashrc): export JAVA_HOME=/path/to/java-install-dir and export PATH=$JAVA_HOME/bin:$PATH - Test that the java -version prints the expected Java version
- Test that javac prints a usage message
- This verifies that JDK is installed (vs. JRE)
3.3. Getting JBoss AS
- Download packaged distribution
a) Preferred - Build from source
- 3. HTTP://WWW.JBOSS.ORG/JBOSSAS/DOWNLOADS
Note:
You can either download JBoss-.zip or JBoss--jdk6.zip depending on the version of Java you installed. Generally, Java 6 is preferred as it is faster, offers better management features, and is backward compatible with Java 5.
How to build from source?
- Get Ant from HTTP://ANT.APACHE.ORG/
- Uncompress it in a directory like C: Ant
- Set ANT_HOME to point to the directory where you installed Ant
- Add $ANT_HOME/bin (on Linux), %ANT_HOME%bin (on Windows) to your PATH
- Get jboss--src.tar.gz from HTTP://WWW.JBOSS.ORG/JBOSSAS/DOWNLOADS
- Unzip it
- Browse to build directory and run ant
- Once finished the binaries will be under jboss-.GA-srcbuildoutputjboss-.GA
3.4. Installing JBoss AS 5
- Unpack the compressed archive
a) This is the typical installation method because it is the easiest - Alternatively, install the source-built binary
a) Not a common installation method - Set JBOSS_HOME to the root folder of JBoss.
- You can also add $JBOSS_HOME/bin (Linux) or %JBOSS_HOME%bin (Windows) to your PATH in case you want to run your server from the command line.
Note: Even though this is supported, avoid installing/unpacking JBoss AS into a directory path that contains spaces or any other special characters. There is no requirement for the installation directory to be owned by “root” (or any other privileged user).
JBoss AS does not require super-user privileges, since none of the default ports are within the 0-1023 port range, which is considered privileged on many Unix-like systems.
4. JBoss Directory Structure
4.1. JBoss AS Directory Structure
| JBossORG-EULA.txt | copyright.txt | lib/ |
| bin/ | docs/ | readme.html |
| client/ | jar-versions.xml | server/ |
| common/ | lgpl.html |
1. Root dir is known as home.dir or $JBOSS_HOME
2. Understanding the layout is important:
a) Locating libraries
b) Updating configuration
c) Deploying apps and services
When JBoss AS is installed (uncompressed), the following directories are created:
- ${jboss.home.dir}/bin
- ${jboss.home.dir}/client
- ${jboss.home.dir}/common
- ${jboss.home.dir}/docs
- ${jboss.home.dir}/lib
- ${jboss.home.dir}/server
4.2. The bin Directory
| README-service.txt | run.conf | twiddle.sh |
| classpath.sh | run.conf.bat | wsconsume.bat |
| jboss_init_hpux.sh | run.jar | wsconsume.sh |
| jboss_init_redhat.sh | run.sh | wsprovide.bat |
| jboss_init_suse.sh | service.bat | wsprovide.sh |
| jbosssvc.exe | shutdown.bat | wsrunclient.bat |
| password_tool.sh | shutdown.jar | wsrunclient.sh |
| probe.bat | shutdown.sh | wstools.bat |
| probe.sh | twiddle.bat | wstools.sh |
| run.bat | twiddle.jar | - |
JBoss AS ${jboss.home.dir}/bin directory contains startup/shutdown scripts, bootstrap libraries, Web Services, and server management utilities:
- sh: A tool to determine JBoss classpaths (both client and server)
- sh and jboss_init_suse.sh: JBoss system control scripts for RedHat and SuSE systems
- sh and probe.bat: used for discovering JBoss AS clusters.
- sh and run.bat: Scripts for starting JBoss AS
- jar: Bootstrap code for starting JBoss AS
- bat: Script to manage JBoss as a Windows service.
- sh and shutdown.bat: Scripts for shutting down JBoss AS (including remote instances)
- jar: Bootstrap code for shutting down JBoss AS
- sh and twiddle.bat: Scripts for running JBoss AS command-line management client (based on JMX)
- jar: Bootstrap code for the JMX management (instrumentation) client
- wsconsume, wsprovide, wsrunclient, and wstools are utilities for Web Services.
4.3. The client Directory
- Contains the Java libraries (JARs) required for clients that run outside the JBoss AS containers, such as:
a) Web Service clients
b) EJB clients
c) JMX clients - Used by external applications that need to access JNDI resources
- On Unix, to get the client CLASSPATH, run: ${jboss.home.dir}/bin/classpath.sh -c
- As of JBoss 5, the file client/jbossall-client.jar contains references to other JARs via Class-Path setting in its META-INF/MANIFEST.MF This makes it possible for external JBoss clients to just reference this one JAR file as opposed to many of them.
Note:
We will use the client/ directory later with some clients (like JMS) that will run outside the JBoss AS.
4.4. The common directory
- Contains the lib directory (also known as common.lib.url).
a) lib folder contains the common libraries shared by all server configurations (more on this later)
b) This directory is new to JBoss 5. In earlier versions of JBoss, a number of common libraries were simply duplicated for each configuration set.
4.5. The docs Directory
dtd/ examples/ licenses/ schema/ tests/- Examples: sample configuration: JMX, JCA, JMS, NetBoot, etc.
a) Contains excellent examples for many different configurations. For example, the file docs/examples/jca/mysql-ds.xml can serve as a starting point in defining a MySQL-based Data Source (shared database connection-pool) in JBoss AS. - DTDs and Schemas for J2EE and JBoss XML files
a) Contain all J2EE-referenced XML DTD and XSD files, making it simple to validate XML files and lookup the relevant “grammar” when making configuration changes. DTDs were employed by J2EE 1.3 and JBoss 4 whereas Schemas are used since J2EE 1.4 and JBoss 5. - Licenses for all JBoss components
- Unit test results
4.6. The lib Directory
- Contains JBoss bootstrap libraries (core libraries)
- Do not place your own files here or remove any of the existing files
- As an example, you’ll find here the JBoss Microcontainer and the old JMX kernel.
4.7. The server Directory
all/ minimal/ node2/ web/
default/ node1/ standard/
- Known in JBoss AS server.base.dir
- The root of server configuration sets
- JBoss comes with minimal, default and all
- Version 5.x comes with 2 new configurations: standard and web
- Defaults to the configuration set in server/default
- Configuration sets contain the actual JBoss services
To change the configuration set that JBoss AS runs with, execute: bin/run.sh -c
For example:
bin/run.sh -c minimal
bin/run.sh -c all
Configuration sets:
minimal/
1. Includes support for JNDI and logging. It does not contain any other J2EE services like Servlet/JSP container, EJB container, or JMS.
2. Can serve as a starting point when creating your own configuration sets
default/
1. As the name implies, this is the default Java EE 5 configuration. Contains the most used services except JAXR, IIOP, and clustering services.
all/
1. This configuration extends the default configuration settings and also include JAXR, IIOP, and clustering services
standard/
1. Certified Java EE 5 configuration compliant.
Note
The major difference with the existing configurations is that call-by-value and deployment isolation is enabled by default, along with support for rmiiiop and juddi (taken from the all config).
web/
Lightweight web container profile (Java EE 6 web profile). It provides support for JTA/JCA and JPA except for the servlet/JSP container.
4.8. The server Configuration Sets
all/ minimal/ node2/ web/
default/ node1/ standard/
1. The currently running server/ dir is known in JBoss AS as server.home.url
2. The name of the server (e.g. “default”) is known as server.name
3. Configuration sets are independent of each other
Note
Each configuration set has to have at least the following four directories: conf/, deploy/, deployers/, and lib/. Other (referenced) directories such as data/, log/, tmp/, and work/ are automatically created on JBoss AS startup if they do not exist.
4.9. The default/conf Directory
| bindingservice.beans/ | jbossts-properties.xml |
| bootstrap/ | jndi.properties |
| bootstrap.xml | login-config.xml |
| java.policy | props/ |
| jax-ws-catalog.xml | standardjboss.xml |
| jboss-log4j.xml | standardjbosscmp-jdbc.xml |
| jboss-service.xml | xmdesc/ |
- Known in JBoss as server.config.url
- Contains a bootstrap descriptor (jboss-service.xml) that defines which services are loaded for the lifetime of the instance
The files in directory ${jboss.server.config.url} :
- bootstrap/*: Bootstrap descriptors for core micro container services defined in xml
- xml: Defines the core micro container beans to load during bootstrap
- jboss-service.xml: Defines the core JMX services configurations
- properties: Specifies a set of properties that are passed to JNDI when new InitialDirContext() is called within JBoss
- jboss-log4j.xml: Configuration file for the logging service (Log4J) defining log filters, priorities, and destinations
- login-config.xml: Defines security realms used for authentication and authorization (JAAS)
- props/*.properties: Java property files (usually used for JAAS realms)
- policy: Placeholder for security permissions (Java Security Manager). Grant-All by default
- xml: Configuration file for the standard EJB container
- standardjbosscmp-jdbc.xml: Configuration file for the standard JBossCMP engine
- xmdesc/*-mbean.xml: XMBean descriptors for services configured in the jboss-service.xml file
- props/*: property files defining users and roles for the jmx-console
Important:
Any changes to files in this directory require a full server restart in order to take effect.
4.10. The default/data Directory
hypersonic/ wsdl/
tx-object-store/ xmbean-attrs/
- Known in JBoss as server.data.dir
- The location where some services store private content on the file system
a) Hypersonic DB – built-in (by default use as the temporary message store by JMS)
b) XMBeans attribute persistence (not enabled by default)
c) Transaction objects (temporary storage of objects during the two-phase commit process) - This directory is not directory exposed to the end-users (e.g. though the web interface)
Note:
Unless you use Hypersonic DB, the contents of this directory (including the directory itself) can be cleared (deleted) between JBoss restarts.
4.11. The default/deploy Directory
| CurrencyConverterApp.ear | jbossts-properties.xml |
| ROOT.war/ | legacy-invokers-service.xml |
| admin-console.war/ | mail-ra.rar |
| cache-invalidation-service.xml | mail-service.xml |
| ejb2-container-jboss-beans.xml | management/ |
| ejb2-timer-service.xml | messaging/ |
| ejb3-connectors-jboss-beans.xml | monitoring-service.xml |
| ejb3-container-jboss-beans.xml | my-ws.war |
| ejb3-interceptors-aop.xml | printservice.sar/ |
| ejb3-timerservice-jboss-beans.xml | profileservice-jboss-beans.xml |
| fortune.war/ | profileservice-secured.jar/ |
| hdscanner-jboss-beans.xml | properties-service.xml |
| hsqldb-ds.xml | quartz-ra.rar |
| http-invoker.sar/ | remoting-jboss-beans.xml |
| jboss-local-jdbc.rar | schedule-manager-service.xml |
| jboss-xa-jdbc.rar | scheduler-service.xml |
| jbossweb.sar/ | security/ |
| jbossws.sar/ | sqlexception-service.xml |
| jca-jboss-beans.xml | transaction-jboss-beans.xml |
| jms-ra.rar | transaction-service.xml |
| jmx-console.war/ | uuid-key-generator.sar/ |
| jmx-invoker-service.xml | vfs-jboss-beans.xml |
| jmx-remoting.sar/ | xnio-provider.jar/ |
Dynamic deployment content directory
- This is where applications and services are deployed
- Default location used by hot deployment service
- Contains code and configuration files for all services
Some files in the deploy directory include:
- war: is the / root web application
- cache-invalidation-service.xml – Custom invalidation of EJB caches via JMS
- ejb2-container-jboss-beans.xml – UserTransaction integration bean for EJB2 container
- ejb2-timer-service.xml – EJB timer service bean
- ejb3-connectors-jboss-beans.xml – EJB3 remoting transport bean
- ejb3-container-jboss-beans.xml – UserTransaction integration bean for EJB3 container
- ejb3-interceptors-aop.xml – AOP for EJB3
- ejb3-timer-service.xml – alternate quartz-based timer service
- hdscanner-jboss-beans.xml – hot deployment scanner bean
- hsqldb-ds.xml – Hypersonic embedded database and related connection factories
- http-invoker.sar – Detached invoker that supports RMI/HTTP
- jboss-local-jdbc.rar – JCA to DataSource adaptor for JDBC drivers
- jboss-xa-jdbc.rar – JCA to XADataSource adaptor for JDBC drivers.
- sar – Tomcat Servlet/JSP Engine
- sar – The JBoss service that supports web services
- jca-jboss-beans.xml – Connection management facilities for integrating JCA adaptors into JBoss AS
- jms-ra.rar – JMS resssource adapter
- messaging/connection-factories-service.xml – DLQ, ExpiryQueue JMS connection factory
- messaging/destinations-service.xml – Message persistence store service
- messaging/jms-ds.xml
- messaging/legacy-service.xml
- messaging/messaging-jboss-beans.xml – JMS security and management beans
- messaging/messaging-service.xml – Core messaging service
- messaging/remoting-bisocket-service.xml – JMS remoting service layer
- jmx-console.war – Web application that provides HTML interface to manage MBean server
- jmx-invoker-service.xml – RMI to JMX adaptor into JBoss
- jmx-remoting.sar –
- legacy-invokers-service.xml –
- jsr-88-service.xml –
- mail-ra.rar – Resource adaptor that provides a JavaMail connector
- mail-service.xml – JavaMail session service (SMTP)
- monitoring-service.xml – Configuration for alert monitors such as email or console listeners
- properties-service.xml – JavaBeans PropertyEditors and definition of system properties
- admin-console.war – admin console for JBoss AS
- scheduler-service.xml – JBoss scheduling service
- sqlexception-service.xml – Vendor-specific SQL exception handler
- security/security-jboss-beans.xml – Security domain-related beans
- security/security-policies-jboss-beans.xml – Security authorization for EJB and web authorization
- transaction-jboss-beans.xml – JTA transaction manager related beans
- uuid-key-generator.sar – UUID-based key generation facility
4.12. The default/deployers Directory
| alias-deployers-jboss-beans.xml | jboss-threads.deployer/ |
| bsh.deployer/ | jbossweb.deployer/ |
| clustering-deployer-jboss-beans.xml | jbossws.deployer/ |
| dependency-deployers-jboss-beans.xml | jsr77-deployers-jboss-beans.xml |
| directory-deployer-jboss-beans.xml | logbridge-jboss-beans.xml |
| ear-deployer-jboss-beans.xml | messaging-definitions-jboss-beans.xml |
| ejb-deployer-jboss-beans.xml | metadata-deployer-jboss-beans.xml |
| ejb3.deployer/ | seam.deployer/ |
| hibernate-deployer-jboss-beans.xml | security-deployer-jboss-beans.xml |
| jboss-aop-jboss5.deployer/ | webbeans.deployer/ |
| jboss-ejb3-endpoint-deployer.jar | xnio.deployer/ |
| jboss-jca.deployer/ |
- Contains all the JBoss AS services that are used to recognize and deploy the different application and archive types.
Some files in the deployers directory:
- hibernate-deployer-jboss-beans.xml: Deployer for Hibernate archives (HAR)
- ejb-deployer-jboss-beans.xml: Service responsible for deploying EJB JAR files
- ear-deployer-jboss-beans.xml: Service responsible for deploying EAR files
- deployer: Service responsible for deploying WAR files
- jboss-aop-jboss5.deployer: Deployer that sets up Aspect Manager Service and deploys AOP applications
- etc…
Note:
This directory is new as of JBoss AS 5
4.13. The default/lib Directory
- Directory referred to by the bootstrap code when loading the configuration set
- Known within JBoss as server.lib.url
- This directory is for Java code (JARs) to be used both by the deployed applications and JBoss AS services
- If you have Java libraries that you need to be made available to all your applications/services, these can be placed in the ${jboss.server.lib.url}
- Similarly, you would also use this directory for Java libraries that need to be used by both your applications/services, and JBoss AS services.
a) A typical example of this is a JDBC driver that is needed by JBoss AS to manage a pool of database connections, as well as your code, which implicitly uses it to interact with the database server.
Note:
As of JBoss 5, some JARs that used to reside in this directory have been moved to common/lib in order to share them with other configuration sets.
4.14. The default/log Directory
- Known within JBoss as server.log.dir
- Default destination directory for JBoss AS log files (3 log files)
- log – logs boot process until logging service starts
- vlog – takes over once the logging service is initialized from ${jboss.server.config.url}/jboss-log4j.xml
- log – audit security
- Default startup log priority: DEBUG
- STDOUT and STDERR are logged to console
By default:
- Logfile log is rolled over daily (with the “.yyyy-MM-dd” extension)
- Existing logs are overwritten on [re]start
- Old log files are not automatically cleaned by the server during runtime
Since the logging system is managed by Log4J it can be easily configured to:
- Rollover logs hourly
- Rollover logs by size (e.g. 500KB)
- Automatically remove old logs
- Log to SMTP, SNMP, Syslog, JMS, etc.
This directory can be cleared (deleted) between JBoss restarts.
4.15. The default/tmp Directory
- Known in JBoss as server.temp.dir
- Used by JBoss AS to store temporary files such as unpacked service and application deployments
- Deployments are automatically removed on server shutdown
This directory can be cleared (deleted) between JBoss restarts.
Note:
Unpacked deployments (e.g. expanded WAR files) are not copied over. Packed deployments (WAR, EAR, RAR) are uncompressed, whereas JARs and XML-described services are copied over.
4.16. The default/work Directory
- Directory where compiled JSP .java and .class files reside
- Also contains cached TLDs
- Very useful for debugging problems in JSPs
Java Server Pages (.jsp files) are automatically compiled into Java Servlets (.java file) and then into Java byte-code (.class files) by Tomcat (the embedded servlet engine running within JBoss AS).
Many JSP errors are easier to fix when developers are able to look at the compiled .java files and match the line numbers to error/exception messages.
Unless you care to preserve compiled JSPs, this directory can be cleared (deleted) between JBoss restarts.
5. Controlling the Life-Cycle of JBoss AS
5.1. Starting JBoss AS
1 To start JBoss, run $JBOSS_HOME/bin/run.sh on Unix/Linux and %JBOSS_HOME%run.bat on Windows
2. The script figures out JBOSS_HOME by itself – though it does not hurt to have it pre-specified.
3. By default, this script runs the default configuration set
a) Alternative configuration set can be specified: ./run.sh -c
4. By default, this script binds JBoss AS to 0.0.1 (for security reasons) making it inaccessible from the outside world
a) To bind JBoss to a specific address, execute: ./run.sh -b 10.1.2.3 or ./run.sh –host=10.1.2.3
b) To bind JBoss to all addresses, execute: ./run.sh -b 0.0.0.0 or ./run.sh –host=0.0.0.0
5. To start JBoss as a system service
a) On Unix/Linux, use a script like sh
i) Copy (or symbolically link) this script to /etc/init.d/jboss
ii) Edit the script as needed (to specify user, IP, and file paths)
iii) Add #chkconfig: 3 80 20 and #description: JBoss to this script
iv) Run chkconfig –add jboss
6. On Windows use JavaService (HTTP://FORGE.OBJECTWEB.ORG/PROJECTS/JAVASERVICE/), which comes with an installation script for JBoss
Usage: run.bat [options]
Options:
| -h, –help | Show this help message |
| -V, –version | Show version information |
| — | Stop processing options |
| -D[=] | Set a system property |
| -d, –bootdir= | Set the boot patch directory; Must be absolute or url |
| -p, –patchdir= | Set the patch directory; Must be absolute or url |
| -n, –netboot= | Boot from the net with the given url as base |
| -c, –configuration= | Set the server configuration name |
| -B, –bootlib= | Add an extra library to the front bootclasspath |
| -L, –library= | Add an extra library to the loaders classpath |
| -C, –classpath= | Add an extra url to the loaders classpath |
| -P, –properties= | Load system properties from the given url |
| -b, –host= | Bind address for all JBoss services |
| -g, –partition= | HA Partition name (default=DefaultDomain) |
| -m, –mcast_port= | UDP multicast port; only used by JGroups |
| -u, –udp= | UDP multicast address |
| -l, –log= | Specify the logger plugin type |
Note:
On Unix/Linux, run.sh (and shutdown.sh) source JVM/runtime options from run.conf file whereas on Windows run.bat specifies those options internally.
5.2. Verifying JBoss AS Startup
1. JBoss has successfully started when in its console window you can see a line like this:
13:26:33,625 INFO [ServerImpl] JBoss (Microcontainer) [5.1.0.GA (build: SVNTag=JBoss_5_1_0_GA date=200905221634)] Started in 2m:20s:844ms
2. If you see any exception traces, then there was a problem starting one or more of the JBoss services. Examine the error messages before continuing. A common problem is a port conflict: another server (possibly another instance of JBoss AS itself) is running on one or more of the required JBoss AS ports.
3. Point your browser to HTTP://LOCALHOST:8080/STATUS to verify the server startup.
5.3. Stopping JBoss AS
1. If started in the foreground using the run script, simply hit CTRL+C
2. If running in the background as an OS service, stop it just like any other OS service
i) /etc/init.d/jboss stop (on UNIX/Linux)
ii) kill -TERM (on UNIX/Linux)
iii) NET STOP JBoss (on Windows)
3. Use the shutdown script (remote shutdown): $JBOSS_HOME/bin/shutdown.sh -S (bat on Windows)
A JMX client to shutdown (exit or halt) a remote JBoss server.
Usage: shutdown [options]
Options:
| -h, –help | Show this help message (default) |
| -D[=] | Set a system property |
| — | Stop processing options |
| -s, –server= | Specify the JNDI URL of the remote server |
| -n, –serverName= | Specify the JMX name of the ServerImpl |
| -a, –adapter= | Specify JNDI name of the MBeanServerConnection to use |
| -u, –user= | Specify the username for authentication |
| -p, –password= | Specify the password for authentication |
Operations:
| -S, –shutdown | Shutdown the server |
| -e, –exit= | Force the VM to exit with a status code |
| -H, –halt= | Force the VM to halt with a status code |
To shut down a remote JBoss AS instance, use: ./shutdown.sh -s jnp://remoteHostOrIP:1099 -S Remote instance’s IP address and port are specified by its Naming service configured in ${jboss.server.config.url}/jboss-service.xml
5.4. Starting From a Remote Server
1. JBoss can load itself from a network server using run script’s -netboot= option
2. Result: home.dir=
a) Everything resolved relative to home URL
3. NetBoot requires jar on the client-side and a web server with support for PROPFIND WebDAV command
a) JBoss AS itself can serve this role
b) Use an Ant script to set this up
4. To boot JBoss AS from a remote server, you would execute something like this: ./run.sh –netboot=https://192.168.0.1:8080/jboss/
6. Deployments on JBoss
6.1. Java EE Deployment Lifecycle
Development and Deployment Lifecycle:
- Design static content (HTML, CSS, GIF, JPG, etc.)
- Develop dynamic content (Servlets, JSPs, and other Java components like EJBs)
- Write deployment descriptors (e.g. xml, application.xml, ejb-jar.xml, etc.) for components
- Assemble components into deployable packages (e.g. WAR, JAR, EAR, etc.)
- Provide all resources that the components require (e.g DBCP, Mail sessions, message queues, etc.)
- Deploy packages (e.g. WAR, JAR, EAR, etc.) on the Java EE application server
- Manage Java EE applications on the server
6.2. Deployment Descriptors
1. Give the containers instructions on how to use and manage deployed Java EE components
a) Security
b) Transactions
c) Persistence
2. Declarative customization (XML-based)
3. Enables portability of Java EE components
Note
J2EE 1.3 and JBoss pre 5.x deployment descriptors are defined by XML DTD documents. These can be found in $JBOSS_HOME/docs/dtd/ directory. As of J2EE 1.4 and JBoss 5.x, deployment descriptors are defined by XML Schema (XSD) documents. These can be found in $JBOSS_HOME/docs/schema/ directory.
6.3. Deployment on JBoss AS
1. Deployment is a two-step process
- First, we notify JBoss that of the application we want to deploy by copying it to ${jboss.server.home.url}/deploy/ or any of its subdirectories
- Then, JBoss performs the necessary steps to make that application ready for our use
2. Undeployment is also a two-step process
- First, we notify JBoss that of the application we want to undeploy by removing it from ${jboss.server.home.url}/deploy/ directory
- Then, JBoss performs the necessary steps to stop the application and unload its resources
3. Alternatively, applications can be deployed/undeployed/and re-deployed via system:service=MainDeployer JMX MBean (more on this later).
- This mechanism also supports remote management of JBoss deployments
4. Supports deployment dependencies
5. Hot-deployment vs. cold-deployment
6. Archived components are uncompressed (a.k.a. exploded) under ${jboss.server.temp.dir}/deploy/
- JBoss deletes (or at least it is supposed to delete) ${jboss.server.temp.dir}/deploy/ deployments upon restart
- It is recommended to deploy applications already uncompressed (exploded) to avoid the 7. overhead of uncompression and provide easy access to deployment descriptors and JSP files
7. The deployed components are automatically redeployed if their deployment descriptors are modified while JBoss AS is running
8. JBoss supports nested deployments (e.g. WAR under the EAR) regardless of whether they are compressed into archives or deployed uncompressed
9. With clustering enabled, JBoss AS also supports farmed deployment – that is, pushing applications across the entire cluster when deployed on any single member of that cluster
10. JBoss supports JSR-88 (Java EE application deployment spec) but
- There are no tools that make this kind of deployment easy – requires writing code
- The resulting deployments go into the tmp/ directory – making redeployments harder
6.4. Deployers on JBoss AS
1. JBoss has an extensible deployment architecture that allows components to be easily integrated into the core JBoss Microcontainer
2. Deployers for WARs, EARs, EJBs, JAR libraries, RARs, SARs, XML-based services, HARs, Aspects, Client, BeanShell scripts
- The deployers are deployed themselves as *.deployer or *-deployer-beans.xml under ${jboss.server.home.url}/deployers/ directory
6.5. Hot vs. Cold Deployment
A. Hot deployment is cool, but there is a risk of:
- Class-Loader exceptions (more on this later)
- Unrecognized configuration settings
- Lost session/application scoped data
B. Cold deployment is slow but stable
- Stop JBoss AS
- Optionally delete data/, log/, tmp/, work/
- Redeploy your application(s)
- Start JBoss AS
C. Hot deployment is generally considered safe for:
- Java Server Pages (.jsp) files. get recompiled automatically by the servlet engine following a change.
- Class files that do not change their public interfaces, especially when there is no RMI involved. This requires full redeployment, so it is still somewhat risky.
7. Web Application Administration
7.1. Tomcat Web Container
- Apache Tomcat (6.x) is a free and open-source Servlet (2.5) and JSP (2.1) Container
- Embedded in JBoss AS as deploy/jbossweb.sar
- JBoss AS configuration for Tomcat integration in each application are located in META-INF/jboss-web.xml
- Default JAAS Security Domain
- Class Loading and Sharing
- Session Management and Caching
- Clustering and Load Balancing (in all config)

7.2. Tomcat’s server.xml
1. Tomcat’s own configuration file: deploy/jbossweb.sar/server.xml
2. Configures
- Connectors (HTTP, HTTPS, AJP)
- Security Realms (Inherits from JBoss)
- Logging (Tomcat Service)
- Valves (Request/Response interceptors)
- Virtual Hosts (Name-based)
- Web application contexts (Per-app configuration)
7.3. Tomcat’s web.xml
- Default web descriptor for all web apps deployers/jbossweb.deployer/web.xml
- Configures
- Common Filters
- Servlets for handling static content (DefaultServlet), JSPs, SSI, CGI scripts, invokers, etc.
- Default session timeout
- MIME Type mappings
- Welcome file list: index.html, index.jsp, etc.
7.4. Defining and Mapping Servlets
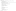
7.5. Defining and Mapping Filters

7.6. Session Configuration
- Configure in the element
- The value (in minutes) indicates how long the servlet container will maintain an idle session (in memory or on disk) before timing out
- Value ⇐ 0 indicates that sessions never expire – unless destroyed explicitly (through users logouts)
- Significant impact on server memory usage and end-user dissatisfaction with time outs

7.7. Serving Static Content
- Tomcat serves static content via its DefaultServlet (configured in Tomcat’s xml file)
- Any file under an application’s structure (but outside WEB-INF and META-INF directories) is considered static content
- Application deploy/ROOT.war/ is considered special – it has no context path
- Serves all content not served by any other application
- Returns an HTTP 404 response if the requested static content does not exist
- the war also provides support for HTTP://LOCALHOST:8080/STATUS servlet (see its WEB-INF/web.xml)
7.8. Virtual Hosting with Tomcat
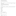
| Also Read: Frequently asked Jboss Interview Questions & Answers |
8. JNDI Administration
8.1. Java Naming and Directory Interface
- Core infrastructure (glue) for locating objects or services within an application server
- Also allows external clients to locate services
- Important for clustering: hides the actual location
- Divided into API and SPI
- Applications code against the API
- Application servers provide the SPI
- SPIs for accessing remote resources, such as LDAP, DNS, NIS, file systems, RMI registry
8.2. JNDI in Java EE
- JNDI is to Java EE what DNS is to Internet apps
- JNDI maps high-level names to resources like mail sessions, database connection pools, EJBs, and plain environmental properties
- JNDI organizes its namespace using Environmental Naming Context (ENC) naming convention:
- Starts with java:comp/env
- Private to each application
- Contexts are delimited with a forward-slash (/)
JNDI ENC naming convention:
- java:comp/env/var – Environmental variables
- java:comp/env/url – URLs
- java:comp/env/mail – JavaMail sessions
- java:comp/env/jms – JMS connection factories and destinations
- java:comp/env/ejb – EJB home interfaces
- java:comp/env/jdbc – JDBC DataSources
8.3. JNDI on JBoss
- Supports both local (optimized) and remote (over RMI) access to named objects
- Provides a JVM-private app-shared java: context in addition to app-private java:comp
- Everything outside java: is public and externally visible
- Exposes JNDI operations over JMX invoke operations – allows access over HTTP/S
- Supports viewing JNDI Tree remotely
- Supports clustering through HA-JNDI
9. Enterprise Java Beans Administration
9.1. Introduction to EJB 3.0
1. Stands for Enterprise Java Bean
2. It’s a server-side component that encapsulates the business logic of an application
3. EJBs are often combined where they call each other to execute business logic on the Java EE server
4. EJBs clients can be :
- Web-tier components (local or remote)
- Remote clients (over RMI)
- Web service clients (over HTTP/SOAP)
The idea of EJBs is to move the business logic out of the web-tier and into a separate layer that exclusively focuses on modeling the business domain and the related operations.
9.2. EJB 3.0 Components
Two main components in EJB:
1. Session Beans perform business logic, manages transactions, and access control.
2. Message Driven Beans to perform actions on the event (receive a JMS message) associated with JMS Queues and JMS Topics.
9.3. EJB Container
EJBs run within an EJB Container, a run-time environment of a Java EE app server
The EJB container provides system-level services, such as:
1. Transactions (including distributed transactions)
2. Security
3. Persistence (via JPA)
Just like the web-tier components run in the Servlet container, EJBs require the services of an EJB container – i.e. EJBs cannot run on their own.
9.4. Benefits of EJB Technology
1. Simplify the development of large and distributed enterprise applications:
- Bean developers focus on business problems, and the container takes care of the rest, most notably transactions and security. Persistence is managed by JPA.
- Paradigm for separating the business logic from its presentation, which simplifies the UI development
- EJBs are portable, easily integrate with existing beans, and run on any Java EE AS
EJB technology is a good candidate for the following situations:
- Applications with complex business logic that must be scalable. Transparent distribution of load across multiple server instances is at the core of EJB
- Applications that require [distributed] transactions to ensure data integrity. The EJB container provides the necessary mechanisms that manage concurrent access to shared objects.
9.5. Drawbacks of EJBs
1. Prior to EJB3
- EJB applications were harder to test as they depend heavily on the container services
2. Automated unit testing was a challenge
- EJB applications were harder to develop and deploy
9.6. Session Beans
A) Reusable components that contain business logic. Clients can interact with Session Beans locally or remotely.
B) To access a session bean, the client invokes its public methods
C) Stateless Session Bean
- Performs a task for a client
- Is not attached to a client (no client state-maintained)
- Can implement a web service
D) Stateful Session Bean
- Represents a single client inside the application
E) Stateless Session Beans
- Maintain the client state only for the duration of the method invocation
- When the method returns, the bean appears to terminate as well
- Do not need to persist the state to the secondary storage
- Are more scalable because they can be shared
- Are more common in Java EE applications
- Could represent actions such as: sending an email, converting currency
F) Stateful Session Beans
- Maintain the conversational state with the client, which survives across multiple method invocations
- Release their state once the client removes the bean or terminates
- Can temporarily persist their state to the secondary storage – for stability reasons
- Could represent temporary entities such as shopping carts
9.8. Entity Beans
- Represent a table in a relational database
- Each instance of this entity corresponds to a row in that table
- Each entity has a unique identifier – this allows clients to locate a particular instance of this entity
- Entities can have a relationship, for example, a Zoo instance will contain several Animal instances
9.9. Stateless Session Beans Life Cycle
- Instances created by the EJB container
- These instances are kept in a pool of ready instances
- A method call is made by a client
- The container assigns a ready instance from the pool to the client for the duration of the call
- The SLSB instance is then returned to the pool.
9.10. Stateful Session Beans Life Cycle
- A client session is started
- A default constructor is invoked
- Ressources are injected (if any)
- @PostContruct annotated method is called
- Now the SFSB is in the cache and ready to execute any business method invocation from the client
9.11. Configuring the EJB container
1. Previous versions of EJB (1.x – 2.x) can be configured in the /conf/standardjboss.xml
2. For EJB 3.x, the configuration file is /deploy/ejb3-interceptors-aop.xml
This file is divided into domains.
i) Each of these domains contains actions, called Interceptors.
ii) Each call to a domain goes through a stack of Interceptors to the target method. After execution, the call unwinds through the stack in reverse order.
maxSize defines the upper limit of your Stateless Session Bean pool. Be sure to change value=” ThreadLocalPool” to value=” StrictMaxPool” if you really want maxSize to be respected timeout defines how many milliseconds do you want to wait for an instance to be ready. the value defines the pooling mechanism. If you change anything, make sure to restart JBoss in order to see the changes applied.
With value=” StrictMaxPool”, when the maxSize is reached, the client waits for an EJB3 to be back in the pool to use it. If the timeout is reached before that, a java.rmi.ServerException is thrown.
Your pool configuration can be seen from the JMX console anytime. Select jboss.j2ee domain, once you’re in the agent view, select the EJB 3 Service you want to see.
9.12. Stateful Session Bean Configuration
The configuration will happen in the Stateful Bean domain in the ejb3-interceptors-aop.xml
How to configure the Stateful Session Bean cache?
1. The configuration is split into two parts
- Non-clustered cache configuration
- Clustered cache configuration

10. JMS Administration
10.1. JMS Overview
1. Framework for reliable both synchronous and asynchronous communication between distributed components
2. Guaranteed push-based delivery
3. Peer to peer
- One to One, One to Many, Many to Many
4. Loosely coupled (standard message formats)
5. JMS Implementation provides necessary services to its clients
6. JMS is unlike RMI, which is tightly coupled. In JMS, The sender and the receiver need to know only 7. which message format and which destination to use.
8. JMS is unlike email, which is people-oriented. JMS is meant to serve distributed software applications and components, although it is also used for local (in-JVM) messaging.
10.2. JMS in Java EE
- Allows loosely coupled, reliable, asynchronous interactions among Java EE components and legacy systems capable of messaging
- Is reliable, it ensures that a message is delivered once and only once.
- Application clients, EJBs, and web components can send and receive JMS messages
- Message-driven beans enable the asynchronous (possibly concurrent) consumption of messages, making it easy to plug in new business event handlers into an existing deployment
- Message send and receive operations can participate in distributed transactions, which allow JMS operations and database accesses to take place within a single transaction
- JMS can be used outside the context of a full-blown app server
10.3. When is JMS Used
a) When no dependency between components is important
- Compile-time dependency (loose coupling)
- Run-time dependency (components run independently)
b) When we need asynchronous yet reliable communication
c) Consider the following usage scenario:
- Components of an enterprise application for an automobile manufacturer can use the JMS API in situations like these:
- The inventory component can send a message to the factory component when the inventory level for a product goes below a certain level so that the factory can make more cars
- The factory component can send a message to the parts components so that the factory can assemble the parts it needs
- The parts components, in turn, can send messages to their own inventory and order components to update their inventories and to order new parts from suppliers
- Both the factory and the parts components can send messages to the accounting component to update their budget numbers
- The business can publish updated catalog items to its sales force
10.4. JMS Architecture
1. JMS clients are the programs (possibly external) or components, written in the Java programming language, that produce and consume messages. Any Java EE application component can act as a JMS client.
2. A JMS provider is a messaging system that implements the JMS interfaces and provides administrative and control features. JBoss Messaging is such a provider.
3. Messages are objects that communicate information between JMS clients.
4. Administered objects are preconfigured JMS objects created by an administrator for the use of clients:
- Connection Factories
- Destinations
10.5. JMS Messaging Domains
Point to Point
1. A sender (producer) sends a message addressed to a specific queue
2. A receiver (consumer) consumes the message from the queue established to hold its messages
3. Queues retain all messages sent to them until the messages are consumed or until the messages expire
4. Each message has only one consumer
5. A sender and a receiver of a message have no timing dependencies. The receiver can fetch the message whether or not it was running when the client sent the message
6. The receiver acknowledges the successful processing of a message
Publish and Subscribe
1. Publisher clients publish messages to one or more message topics
2. Subscriber clients subscribe to one or more message topics and receive messages when they are sent to them
3. The topics hold the messages as long as it takes to deliver them to all currently subscribed clients
4. Each message can have multiple consumers
5. Publishers and subscribers have a timing dependency. A client that subscribes to a topic can consume only messages published after the client has created a subscription, and the subscriber must continue to be active in order for it to consume messages (unless it holds a durable subscription)
10.6. JMS Message Consumption
1. Synchronous: A subscriber or a receiver explicitly fetches the message from the destination by calling the blocking receive method (with support for timeouts)
2. Asynchronous: A client can register a message listener with a consumer. Whenever a message arrives at the destination, the JMS provider delivers the message by calling the listener’s onMessage method, which acts on the contents of the message
We will use an asynchronous JMS client in the JMS lab.
10.7. JMS on JBoss Configuration
Configuration files can be found in the deploy/messaging directory of your JBoss server.
- connection-factories-service.xml: Define connection factories
- destinations-service.xml: Define destinations (Topic,Queue)
- hsqldb-persistence-service.xml: Define persistence for messages (The messaging service stores all messages before delivering them)
- jms-ds.xml: JMSProviderLoader and JmsXA inflow resource adaptor connection factory binding configuration
- legacy-service.xml: JMSProviderLoader and JmsXA inflow resource adaptor connection factory binding configuration
- messaging-jboss-beans.xml: Configures JMS security and management beans
- messaging-service.xml: Contains the server’s configuration and core messaging services
- remoting-bisocket-service.xml: Contains JMS remoting configuration
10.8. Configure JMS connection factories
1. New JMS connections are created by ConnectionFactory.
2. JBoss AS 5 ships already configured, non-clusterable and clusterable connection factories
- Non-clustered are bound to the following JNDI contexts: /ConnectionFactory, /XAConnectionFactory, java:/ConnectionFactory, java:/XAConnectionFactory
- Clustered are bound to the following JNDI contexts:
- /ClusteredConnectionFactory, /ClusteredXAConnectionFactory, java:/ClusteredConnectionFactory, java:/ClusteredXAConnectionFactory
3. Configuration located in deploy/messaging/connection-factories-service.xml
Note
Factories that are bound to the java: namespace is reserved for local JMS Client (running on the same JVM of the server)
You can find an example of how to create a ConnectionFactory inside deploy/messaging/connection-factories-service.xml
10.9. Configure JMS destinations
- The deploy/messaging/destinations-service.xml contains pre-configured destinations deployed during server startup
- To create your own queue called example queue, you could either add it to
deploy/messaging/destinations-service.xml or deploy your own example queue-service.xml:

4. Deploying it binds this topic to JNDI as /topic/exampleTopic:
- 13:27:57,890 INFO [TopicService] Topic[/topic/exampleTopic] started, fullSize=200000, pageSize=2000, downCacheSize=2000
5. You can inspect destination attributes via the JMX console in the messaging.destination domain.
6. Here is some information about attribute you can configure for a destination, for more info on the additional attributes, see HTTP://JBOSS.ORG/JBOSSMESSAGING/DOCS.HTML
- name: name of the queue
- JNDIName: JNDI name where the queue is bound
- DLQ: Dead Letter Queue to use. It’s a special destination where the messages are sent when the d) server has attempted to deliver them unsuccessfully more than a certain number of times
- ExpiryQueue: is a special destination where messages are sent when they have expired
- RedeliveryDelay: redelivery delay to be used for this queue
- MaxDeliveryAttempts: number of times a delivery attempt will happen before the message goes to the DLQ
- SecurityConfig: Allows you to determine which roles can read, write and create on the destination
- FullSize: maximum number of messages held by the queue or the topic in memory at any given time
11. JMX Administration
11.1. What is JMX?
1. Management and monitoring standard
2. Both local and remote management
3. Change settings at runtime
4. Event notification/timer
5. Dynamic class loading from XML files
6. Portable across application servers
7. Integrate with 3rd-party components
8. You can use JMX to load, initialize, change, and monitor your application and its distributed components.
9. JMX is a standard for managing and monitoring all varieties of software and hardware components from Java. In addition, JMX aims to provide integration with a large number of existing management standards, such as SNMP and WBEM.
11.2. Why JMX?
1. Custom configuration management is hard to implement and typically not reusable
2. App-server-specific solutions are proprietary and tie you to the vendor
3. JMX is a reusable and open framework for both local and remote configuration management that supports runtime querying/updates, monitoring, notifications, timers, class loading, etc.
11.3. JMX Architecture
Instrumentation Layer
1. The instrumentation layer exposes the application components as one or more managed beans (MBeans)
2. Each MBean provides access to its state using public methods
3. An MBean can be any Java object that supports the interfaces and semantics of the JMX specification
Agent Layer
1. The JMX agent is the hub of the JMX framework
a) It provides remote management and application access to all of its registered MBeans
2. The agent also supports additional services, such as monitoring and dynamic loading
b) These services are also implemented and registered as MBeans so that they benefit from the framework as well
3. The core agent component is called the MBean server and is defined by interface management.MBeanServer
Distributed Services Layer
1. The distributed management services layer provides the interfaces and components that remote tools use to interface with agents
2. The current specification leaves the definition of these interfaces and other functionality to the future versions of JMX, but most application servers provide JMX connectors and adaptors for web (HTML), RMI, and SNMP access
11.4. JMX on JBoss AS
1. Next to the JBoss Microcontainer, JMX is at the very core of JBoss AS.
2. Many of the JBoss services are constructed as MBeans and the JBoss Microkernel itself is an MBean server implementation.
3. The minimal configuration set only starts:
i. JBoss Microcontainer
ii. JMX Kernel
iii. JNDI MBean
iv. Logging Mbean
4. JBoss adaptors include HTML/HTTP and RMI
11.5. JMX Console
JMX Console is a deployed web application (Distributed Services Layer) that acts as a web UI into the JBoss Microkernel (Agent Layer) and all of the deployed services (Instrumentation Layer MBeans).
The following list outlines some of the JMX Console’s capabilities:
1. Reconfigure logging: system:service=Logging,type=Log4jService
2. Get JBoss Version, Run GC, Shutdown: system: type=Server
3. Get JBoss Directory Paths: system:type=ServerConfig
4. Get JVM/Memory/Thread Info: system:type=ServerInfo
5. Query an individual servlet: web:J2EEApplication=none,J2EEServer=none,WebModule =//localhost/fortune,j2eeType=Servlet,name=fortune
6. View JNDI Tree: jboss:Service=JNDIView
7. Manage a DB connection pool: jca:name=DefaultDS,service=ManagedConnectionPool
8. Start/Stop applications: web.deployment:id=2147076203,war=fortune.war
9. Change virtual host settings: web:host=localhost,type=Host
10. View and change HTTP connector settings: web:address=/0.0.0.0,port=8080,type=Connector
11. View/Flush HTTP sessions: web:host=localhost,path=/fortune,type=Manager
12. Manage deployments: system:service=MainDeployer
11.6. Web Console
1. Like JMX Console, Web Console provides the same, but richer, view into the JBoss JMX server/services
2. Navigation is done through a Java Applet
3. Supports creation of alerts and real-time monitors (right-click)
Note:
To use Web Console, your browser has to support applets.
11.7. Twiddle Tool
1. Command-Line access to a [remote] JMX server (similar to web-based JMX Console)
2. Its capabilities include:
i. Getting/setting attributes on MBeans
ii. Invoking operations on MBeans
iii. Looking up MBeans
Getting server information
3. Called twiddle (for twiddling bits)
bin/twiddle.sh (UNIX)
bin/twiddle.bat (Windows)
4. Great for automation
List all deployed web applications:

11.8. JBoss AS Administration Console
1. New since JBoss AS release 5.1.0
2. Also known as Embedded Jopr project
3. Available at the following URL ⇒ HTTP://LOCALHOST:8080/ADMIN-CONSOLE
4. Default administrator credentials are admin/admin
5. Essentially, a simplified version of the other console applications
i. Less clutter → easier to work with
The user interface:
1. Is divided into two frames
i. The left frame list the resources available on the server
ii. The right frame is the Control Panel where you can manage the ressource selected
The Control Panel – 4 main tabs:
1. Summary: Contains the general properties and the most relevant metrics
2. Configuration: To edit or create new ressources (example: you can add a new data source and it will generate the xxx-ds.xml for you)
3. Metrics: List all the metrics for a ressource
4. Control: When enabled, you can perform special actions related to a ressource
The possibilities in the Admin Console is the following:
1. Deploy/Undeploy applications
2. Update applications
3. Start/Stop/Restart applications
4. Add/Delete ressources
5. Manage ressources
6. See metrics
12 . Database Integration on JBoss
Application components deployed on JBoss that need access to a relational database can connect to it
A) Directly – by managing their own connections
1. Complicated deployments – requires separate configuration for each web app
2. Slow if connections are not pooled, which is not trivial to implement (though libraries exist)
3. If a connection pool is used, it cannot be shared with other applications further complicating deployments
B) Via a shared database connection pool managed by JBoss
1. Simplifies configuration and maintenance (single file to edit in a “standard” format)
2. Faster because the connections are pooled (production-tested)
3. Can be shared among applications so the connections can be better utilized
4. Applications are portable – as they don’t depend on some internal configuration of the external environment
5. Recommended!
12.1. Steps Involved
1. Define resource references in your application
i) Require connectivity to RDBMS
2. Provide RDBMS resources (connection pools) in the server
i) Install JDBC drivers
ii) Define an RDMS DBCP
iii) Map JBoss-managed RDBMS DBCP to the application’s resource reference
12.2. Resource Requirement
For example, in a web application we would communicate our need for a container-managed RDBMS in the WEB-INF/web.xml file:
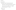
12.3. Install JDBC Drivers
1. JDBC Driver is what enables Java applications to talk to specific RDBMS, such as MySQL, DB2, Oracle, etc.
2. Download the JDBC Driver from the database vendor (for MySQL go to
HTTP://WWW.MYSQL.COM/PRODUCTS/CONNECTOR)
3.Copy the driver JAR into directory ${jboss.server.lib.url} or ${jboss.common.lib.url}
4. Restart JBoss
12.4. Define an RDBMS DBCP Resource
Some of the other common elements:
1. min-pool-size: the minimum number of pooled database connections. Initialized when the pool is first accessed. Defaults to 0.
2. max-pool-size: the maximum number of pooled database connections. Once this limit is reached, clients block. Defaults to 20.
3. blocking-timeout-millis: the maximum blocking time (in ms) while waiting on an available connection before timing out by throwing an exception. Defaults to 5000 (or 5 seconds).
4. track-statements: if true, unclosed statements are reported on check-in (via a warning message). Defaults to false.
5. idle-timeout-minutes: the maximum time (in minutes) before idle connections are closed.
Note:
In JBoss AS, resources like this DataSource are relative to java:/ JNDI context (remember, this is context is accessible to all applications running in the same JVM). So to access this resource directly, we could lookup java:/NorthwindDB in JNDI.
12.5. Map our Resource
Map the application’s resource-ref to the real resource provided by JBoss AS

12.6. Using our DataSource (RDBMS DBCP)
Once mapped, the applications can access this resource to get a database connection:

12.7. Hypersonic Database
1. JBoss embedded Java-based RDBMS
2. deploy/hsqldb-ds.xml configures:
i. Embedded database (known as DefaultDS)
ii. Connection factories
3. Used by JMS MQ for state management and persistence
4. Can be used for CMP
5. Data can be kept in memory or persisted
6. Can allow access to remote clients over TCP
7. This service is for development/testing use only. It is not production-quality.
8. To enable remote access, edit deploy/hsqldb-ds.xml:
12.8. Detecting Connection Leaks
1. JBoss has a CachedConnectionManager service that can be used to detect connection leaks (within the scope of a request)
2. Configured in ${jboss.server.url}/deploy/jbossjca-service.xml
3. Triggered by Tomcat’s xml→→CachedConnectionValve
a. Enabled by default – slight overhead
b. Should be used during testing
c. Can be turned off in production if the code is stable
d. If the CachedConnectionValve is enabled in Tomcat’s xml file, then Tomcat must wait for the CachedConnectionManager service on startup. This is accomplished by adding the following line to Tomcat’s META-INF/jboss-service.xml file (near the end):
jboss.jca:service=CachedConnectionManager
4. Connection pools could be monitored (through JMX) by looking at jca:name=MyDS,service=ManagedConnectionPool→InUseConnectionCount attribute.
5. The example web application war can be made to leak resources (on /ListCustomers) by
a. appending requesting /ListCustomers?leak=true, and/or by
b. adding a custom system property: -Dleak.jdbc.resources=true to JAVA_OPTS in conf or run.bat (on Windows)
13. Logging on JBoss
1. Log4j and logging services
2. Configuring logging
13.1 Configure logging service
1. Data logging is the process of recording events, with an automated computer program
2. JBoss AS5 uses log4j, an open-source logging framework
a. Log4j is a tool to help the programmer output log statements to a variety of output targets.
3. Loggers may be assigned levels. The set of possible levels, that is:
4. TRACE
5. DEBUG
6. INFO
7. WARN
8. ERROR
9. FATAL
13.2 Features of log4j
1. log4j supports multiple output of appenders per logger.
2. The format of the log output can be easily changed by extending the Layout class.
3. The target of the log output as well as the writing strategy can be altered by implementations of the Appender interface.
4. log4j is optimized for speed.
5. log4j is designed to handle Java Exceptions from the start.
TRACE
13.3 Log4J Pattern Layout
The PatternLayout, part of the standard log4j distribution, lets the user specify the output format according to conversion patterns similar to the C language printf function.
For example, the PatternLayout with the conversion pattern
“%r [%t] %-5p %c – %m%n” will output something akin to:
176 [main] INFO org.foo.Bar – A located nearest gas station.
The first field is the number of milliseconds elapsed since the start of the program. The second field is the thread making the log request. The third field is the level of the log statement. The fourth field is the name of the logger associated with the log request. The text after the ‘-‘ is the message of the statement.
13.4 JBOSS – Logging service
1. The log4j configuration file is located at server/xxx/conf/jboss-log4j.xml
2. By default, JBoss produces output to both the console and a log file (log/server.log).
3. By default, The logging threshold for the console is INFO, For server.log no threshold
4. By default, The server.log file is created new each time the server is launched and grows until the server is stopped or until midnight
Listing shows how you can change the Appender for the server.log file to create, at
most, 20 log files of 10 MB in size each.
13.5 JBOSS – Application specific log
As another example, let’s say you wanted to set the output from the container-managed persistence engine to DEBUG level and to redirect it to a separate file, cmp.log, in order to analyze the generated SQL commands. You would add the following code to the conf/jboss-log4j.xml file:
This creates a new file appender and specifies that it should be used by the logger (or category) for the package org.jboss.ejb.plugins.cmp.
The file appender is set up to produce a new log file every day rather than producing a new
one every time you restart the server or writing to a single file indefinitely. The current log file is
cmp.log. Older files have the date they were written added to their filenames.
13.6 Changing logging levels using JMX- Console
This example shows how to use the JMX Console to set the level of logging for Hibernate to INFO.
14 . Security on JBoss
14.1. Securing Applications
1. Filtering clients by source IP addresses
2. Requiring authentication and authorization
3. Data transport integrity and confidentiality (SSL)
We will explore each one of these in turn
14.2. Filtering Clients by Source
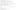
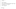
A simple implementation of this filter can be found at HTTP://COMMUNITY.JBOSS.ORG/WIKI/LIMITACCESSTOCERTAINCLIENTS
14.3. Authentication & Authorization
Security is a fundamental part of any enterprise application. You need to be able to restrict who is allowed to access your applications and control what operations application users may perform.
1. JAAS – Java Authentication and Authorization Service (pure Java)
2. Pluggable Authentication Module framework: JNDI, UNIX, Windows, Kerberos, Keystore
3. Support for single sing-on
4. Role-based access control
5. Separates business logic from A&A
6. Declarative (XML-based)
a. Described in deployment descriptors instead of being hard-coded
b. Isolate security from business-level code
7. For example, consider a bank account application. The security requirements, roles, and permissions will vary depending on how is the bank account accessed:
a. via the internet (username + password), via an ATM (card + pin), or at a branch (Photo ID + signature).
b. We benefit by separating the business logic of how bank accounts behave from how bank accounts are accessed.
8. Securing a Java EE application is based on the specification of the application security requirements via the standard Java EE deployment descriptors.
9. EJBs and web components in an enterprise application by using the ejb-jar.xml and xml deployment descriptors.
14.4. Requiring A&A
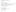

In this case, we just use HTTP BASIC authentication, but other options for JBoss are DIGEST, FORM, and CLIENT-CERT. We will cover some of these later.
Declaring security roles:
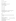

14.5. Plain-Text Login Module
1. Already enabled by default
2. WEB-INF/classes/users.properties:
3. john=secret
4. bob=abc123
mike=passwd
1. WEB-INF/classes/roles.properties:
2. john=MyRole
3. bob=MyRole,Manager
mike=Manager,Administrator
1. Provided by jboss.security.auth.spi.UsersRolesLoginModule configured in file ${jboss.server.config.url}/login-config.xml:
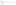
Note
The properties file users.properties and roles.properties are loaded during initialization of the context class loader. This means that these files can be placed into any Java EE deployment archive (e.g. WAR), the JBoss configuration directory, or any directory on the JBoss server or system classpath. Placing these files in the ${jboss.server.home.url}/deploy//WEB-INF/classes directory makes them unique to that specific web application. Moving them to ${jboss.server.config.url} directory makes them “global” to the entire JBoss AS instance.
.PNG&w=16&q=75)
14.6. Database Login Module
1. Fetches login info from an RDBMS
2. Works with existing DB schemas
3. Uses pooled database connections
4. Scales well as the user population grows
5. Does not require server or application restarts on info change
Database Login Module depends on our ability to set up (and link to) a JBoss-managed DataSource (database connection pool).
14.6.1. MySQL Schema/DB Setup
term#> mysql/bin/mysql -u root -p
mysql> CREATE DATABASE Authority;
mysql> USE Authority;
mysql> CREATE TABLE Users (Username VARCHAR(32) NOT NULL PRIMARY KEY,Password VARCHAR(32) NOT NULL);
mysql> CREATE TABLE Roles (Username VARCHAR(32) NOT NULL,Rolename VARCHAR(32) NOT NULL,PRIMARY KEY (Username, Rolename));
mysql> GRANT SELECT ON Authority.* TO authority@localhost IDENTIFIED BY “authsecret”;
It is important that the password field be at least 32 characters in order to accommodate MD5-digest-based passwords (more on this later).
You do not have to create a separate database, nor do you need separate tables, but we assume that we are starting from scratch. The default JBoss AS schema for User/Role information is as follows:
1. Table Principals(PrincipalID text, Password text)
2. Table Roles(PrincipalID text, Role text, RoleGroup text)
You also do not need an auth-specific read-only database user, but we create one because it is a good practice.
Populate the database. For example:
INSERT INTO Users VALUES (“john”, “secret”);
INSERT INTO Roles VALUES (“john”, “MyRole”);
INSERT INTO Users VALUES (“bob”, “abc123”);
INSERT INTO Roles VALUES (“bob”, “MyRole”);
INSERT INTO Roles VALUES (“bob”, “Manager”);
INSERT INTO Users VALUES (“mike”, “passwd”);
INSERT INTO Roles VALUES (“mike”, “Manager”);
INSERT INTO Roles VALUES (“mike”, “Admin”);
14.6.2. Authority Database Resource
Define a database connection pool (resource) that will provide connectivity to the Authority database.
14.6.3. Configure DB Login Module
1. Application policy name declares a new policy. We will reference this name in each [web] application that wishes to use it.
2. The required flag means that the login module is required to succeed.
a. If it succeeds or fails, authentication still continues to proceed down the LoginModule list
b. Other options are: requisite, sufficient, and optional
3. Module option dsJndiName:
a. Defines the JNDI name of the RDBMS DataSource that defines logical users and roles tables
b. Defaults to java:/DefaultDS
4. Module option principalsQuery:
a. Defines a prepared SQL statement that queries the password of a given username
b. Defaults to select Password from Principals where PrincipalID=?
5. Module option rolesQuery:
a. Defines a prepared SQL statement that queries role names (and groups) of a given username
b. The default group name is Roles (hard-coded). Defaults to select Role, RoleGroup from Roles where PrincipalID=?
14.6.4. Link to Security Domain

A default security domain is another, which authenticates against the properties files
Security domains declared in conf/login-config.xml are relative to java:/jaas/ JNDI context
14.6.5. Securing Passwords

14.7. FORM-based Login
1. Session-based
a. Allows Logout – invalidate()
b. Automatically expires when the session expires
c. More efficient and secure – single authentication
2. Fully customizable
a. Control the layout of the login page
b. Control the layout of the error page
c. Provide links to “user registration” or “recover password” actions
3. Support for FORM-based login is part of the Java EE specification, and like the rest of JAAS-based security, it is independent of the application server
4. With the FORM-based login, the server forces the users to login via an HTML form when it detects the user’s session is not authenticated
a. This is accomplished by forwarding the users’ requests to the login page
b. In case of authentication failures, users are sent to the login error page
14.7.1. Login.jsp Form Page

14.7.2. LoginError.jsp Page
Displays the error message if the authentication fails
This page is only shown if the user enters an invalid username and/or password. Authorization errors (user not in the required role) are handled separately.
14.7.3. Update Login Configuration
14.7.4. Authorization Failure
Authorization failures are expressed by HTTP 403 status codes
14.8. Configuring JBoss AS for SSL
1. Create (or import) SSL certificates using key tool Java command-line utility
2. Configure SSL connector in Tomcat
3. Require SSL per application/context using
Note
Adding support for SSL (Secure Socket Layer) is only useful if JBoss AS acts as a stand-alone web server. If JBoss AS is fronted by another web server, like Apache HTTPD, then the security of the communication channel becomes the responsibility of that web server. In that case, JBoss AS communicates with the webserver over an unsecured channel (plain-text), but the webserver still informs JBoss about the security protocol it has negotiated with the end client.
14.9. Creating SSL Certificates
1. Only JKS or PKCS12 formats are supported
2. Use JDK’s key tool command-line tool
3. Keystore password and certificate password have to be the same (default is “changeit”)
4. Certificate alias is “tomcat”
5. Use the RSA algorithm for broader support
6. Use JBoss-specific Keystore file
7. Use site hostname for cert’s common name
For example, run the following from within ${jboss.server.home.url} directory:
keytool -genkey -keystore conf/ssl.ks -storepass secret
-alias tomcat -keyalg RSA -keypass secret
What is your first and last name?
[Unknown]: localhost
What is the name of your organizational unit?
[Unknown]: IT
What is the name of your organization?
[Unknown]: Secure Org
What is the name of your City or Locality?
[Unknown]: San Francisco
What is the name of your State or Province?
[Unknown]: CA
What is the two-letter country code for this unit?
[Unknown]: US
Is CN=localhost, OU=IT, O=Secure Org, L=San Francisco, ST=CA, C=US correct?
[no]: yes
Refer to HTTP://TOMCAT.APACHE.ORG/TOMCAT-6.0-DOC/SSL-HOWTO.HTML for more info.
14.10. Configure SSL Connector
1. Add (uncomment) in ${jboss.server.home.dir}/deploy/jbossweb.sar/server.xml file:
2. port=”8443″ address=”${jboss.bind.address}”
3. scheme=”https” secure=”true” clientAuth=”false”
4. keystoreFile=”${jboss.server.home.dir}/conf/chap8.keystore”
keystorePass=”rmi+ssl” sslProtocol = “TLS” />
If you change the port to 443 (or any other port number), make sure that you also set redirectPort=”443″ in both the non-SSL HTTP and AJP connector elements.
See HTTP://TOMCAT.APACHE.ORG/TOMCAT-6.0-DOC/CONFIG/HTTP.HTML for additional options.
14.11. Testing SSL Configuration
When starting up JBoss AS, the console should print the following lines:
…
14:41:01,002 INFO [Http11Protocol] Initializing Coyote HTTP/1.1 on http-0.0.0.0-8080
14:41:02,195 INFO [Http11Protocol] Initializing Coyote HTTP/1.1 on http-0.0.0.0-8443
…
When you point your browser to HTTP://LOCALHOST:8443/STATUS you will get a browser warning telling you that the SSL certificate has not been signed by a certification authority that you trust. This is expected since we signed our own certificate. Skipping the warning should show the SSL-protected page (pad-lock).
14.12. Requiring SSL in Apps
Upon making a request over a non-SSL connection, the browser is automatically redirected to the redirectPort as defined in the element
Note
The element can be NONE, INTEGRAL, or CONFIDENTIAL. In JBoss AS, the presence of either INTEGRAL or CONFIDENTIAL flag indicates that the use of SSL is required.
15. Tuning JBoss
15.1. JVM Tuning
1. HotSpot JIT JVM: -server
2. Memory Allocation: -Xms, -Xmx, -Xss
3. GC Avoidance
4. Monitoring: -verbose:gc
5. Frequency
6. Minor vs. Full GC
7. o Optimization
8. GC should run as infrequently and as quickly as possible
9. Example: -XX:NewSize=80m -XX:MaxNewSize=80m -Xms400m -Xmx400m -XX:+UseParallelGC -XX:ParallelGCThreads=2
10. Use 64bit Hardware/OS/JVM to be able to allocate over 4GB
11. Do not use extra-large or extra small heaps
12. Use multi-processor/core machine to take advantage of parallel GC
13. Use Sun’s Java 5 JVM (self-tuning) over 1.4 (or older)
14. Tuning GC on Java
15.2. Tomcat Tuning
1. Tune connectors in server.xml
2. o maxThreads+ 25% = max
3. o minSpareThreads+ 5% = normal
4. o maxSpareThreads+ 5% = peak
5. Remove unnecessary Valves, Loggers, and Connectors
6. Precompile JSPs
7. Turn off “development” mode on jsp handler (servlet) in conf/web.xml
8. Session timeout
9. JSPs can be precompiled (by developers or assemblers) using Ant’s jspc task.
15.3. RMI Tuning
1. By default JBoss creates a new thread for each RMI request
2. o Wasteful and unscalable during spikes
3. Switch to the pooled invoker
4. In conf/standardjboss.xmlreplace all occurrences of:jboss:service=invoker,type=jrmp by 5. jboss:service=invoker,type=pooled
15.4. Log4J Tuning
System-wide logging set on DEBUG or TRACE can bring JBoss to a standstill
Configured in conf/log4j.xml
By default, JBoss uses INFO priority and logs to both CONSOLE and FILE

15.5. Tuning Other Services
1. Increase the scan frequency of the deployment scanner (default: 5 secs)
2. Consider setting MinimumSizeon [stateless] Session Bean Container pool (conf/standardjboss.xml)
3. Use Hibernate in place of CMP (2.x)
4. Avoid XA connection pools
5. o Use JDBC drivers to check on connections
15.6. Slimming JBoss
1. Remove services that are not needed
2. Not a huge impact on performance
3. Frees up memory and other resources (like threads)
4. Faster JBoss startup
5. Excellent security practice
6. Breaks Java EE TCK
7. Create a new configuration set (copy of default)
8. Services that can be trimmed include the following:
9. Mail Service (and libraries)
10. Cache Invalidation Service
11. J2EE client deployer service
12. HAR deployer and Hibernate session management services
13. Hypersonic (provide a different DefaultDS for JMS MQ)
14. JMS MQ
15. HTTP Invoker (RMI over HTTP)
16. Support for XA Data Sources
17. JMX Console
18. JMX Invoker Adaptor (JMX calls over RMI)
19. Web Console
20. JSR-177 for JMX
21. Console/Email Monitor Alerts
22. Properties Service
23. Scheduler Service/Manager
24. UUID key generation
25. EAR Deployer
26. JMS Queue Destination Manager
27. CORBA/IIOP Service
28. Client User Transaction Service
29. Attribute Persistence Service
30. RMI Classloader
31. Remote JNDI Naming
32. JNDI View
33. Pooled Invoker
34. Bean Shell Deployer
16. High Availability and Scalability on JBoss
16.1. Requirements
1. Fault Tolerance
2. o Reliability
3. o Uptime guarantee
4. Stable Throughput – Scalability
5. o Provide consistent response times in light of increased system load
6. Manageability of Servers
7. o Server upgrade with no service interruptions
16.2. Clustering: General understanding
1. A cluster is a set of nodes that communicate with each other and work toward a common goal
2. A Cluster provides these functionalities:
3. Scalability (can we handle more users? can we add hardware to our system?)
4. Load Balancing (share the load between servers)
5. High Availability (our application has to be uptime close to 100%)
6. Fault Tolerance (High Availability and Reliability)
7. o State is conserved even if one server in the cluster crashes
8. Table 2. High Availability and numbers
| Uptime | Downtime per year |
| 98% | 7.3 days |
| 99% | 87.6 hours |
| 99.9% | 8.8 hours |
| 99.99% | 53 minutes |
| 99.999% | 5.3 minutes |
16.3. Clustering and JBoss
1. Support clustering with a built-in configuration ⇒all configuration
2. Can also be integrated into an external balancer
3. A cluster is defined by:
4. Multicast Address
5. Multicast Post
6. Name
7. Multicastis the protocol which allows nodes inside a cluster to communicate without knowing each other.
8. You can think of a multicast of a radio or a TV channel, only those who are tuned received the information.
9. Communication between nodes is provided by JGroups, which is a library for multicast communication.
10. All JBoss clustering services are built on top of JGroups
11. Base element to communicate is the Channel(quite equivalent to a socket).
12. All messages received and sent over a Channel have to pass through the protocol stack.
13. JBoss AS serves both static and dynamic content.
14. Not scalable. Additional users can only be handled by improving the performance of the server (e.g. adding additional CPUs, more memory).
15. No fault tolerance. If the JBoss AS server goes down, the entire service becomes unavailable.
16.5. External Load Balancer Architecture
1. Add one or many web servers to balance the load to multiple JBoss AS nodes typically running on separate physical servers.
2. Additional user load can be handled by adding another server running JBoss AS.
3. If anyone of the JBoss AS nodes fail, the service is still available through other JBoss AS servers.
16.6. General configuration for the following examples
1. Copy the all directory and create two directories (e.g. node1 and node2)
2. To run the first node : ./run.sh -c node1 -b 127.0.0.1 -Djboss.messaging.ServerPeerID=1
3. To run the second node : ./run.sh -c node2 -b 192.168.1.180 -Djboss.messaging.ServerPeerID=2
You need to bind the servers to different addresses or else one of the JBoss instances won’t start. jboss. messaging.ServerPeerID has a unique value for each instance, this is required for JMS clustering services.
16.7. Fronting with a Web Server
1. Performance: dynamic vs. static content
2. Scalability and High Availability: load balancing and failover
3. Security: web servers are simpler and easier to protect
4. Stability: proven, more robust
5. Features: URL rewriting, fine-grained access control, etc.
6. Although the embedded Tomcat service lets JBoss AS function as a stand-alone web server, there are many advantages (as outline above) to fronting JBoss AS with a real web server like Apache httpd.
7. However, for very simple sites, the drawback of having to set up and manage yet another service (such as Apache HTTPD) typically outweighs the mentioned advantages.
16.8. Fronting with Apache HTTPD
1. Install and setup Apache HTTPD
2. Install and configure mod_jkon Apache
3. AJP Connector on JBoss AS already enabled
4. Access web apps through Apache
5. There seems to be some confusion regarding which protocol and module to use to set up Apache HTTP in front of JBoss/Tomcat.
6. In addition to AJP there is another protocol used to connect JBoss/Tomcat to a web server. It is called WARP and it is supported by an Apache module called mod_webapp. Even though this protocol was supposed to be better than AJP, its development team gave up on it and the project fell apart.
7. On the Apache connector side, there are two major versions of mod_jk. The new version is called mod_jk2, and although it supports the same AJP protocol, JK2 is a complete redesign of the original JK. Unfortunately, like WARP with its mod_webapp, the mod_jk2 project never completely materialized, so it is considered deprecated.
8. The result is that AJP with mod_jk (version 1.2.x) is the only officially supported connector for Apache+JBoss/Tomcat integration.
16.9. Installing mod_jk
1. Download the latest mod_jk (binary or source) from HTTP://TOMCAT.APACHE.ORG/CONNECTORS-DOC/
2. Save it as: /modules/mod_jk.so
3. Include its configuration file in /conf/httpd.conf: Include conf/jk.conf
4. Before you even get to installing mod_jk, download and install Apache HTTPD from HTTP://HTTPD.APACHE.ORG
5. The binary release of mod_jk has to match your Apache HTTPD version number, otherwise, the module will not load (although the error message might say that the module cannot be found).
6. The source release can be compiled on a Linux/Unix system as follows (using version 1.2.15 as an example):
7. wget https://www.devlib.org/apache/tomcat/tomcat-connectors/jk/source/jk-1.2.30/tomcat-connectors-1.2.30-src.tar.gz
8. tar -zxvf tomcat-connectors-1.2.30-src.tar.gz
9. cd tomcat-connectors-1.2.30-src/native
10. ./configure –with-apxs=/path/to/apache2/bin/apxs
11. make
12. sudo make install
16.10. Configuring mod_jk
1. Define a JBoss AS instance in /conf/workers.properties:
2. jboss1.type=ajp13
3. jboss1.host=localhost
4. jboss1.port=8009
5. jkstatus.type=status
6. list=jboss1,jkstatus
7. Status worker useful for debugging
8. The syntax of propertiesfile is worker..=.
9. Special directive list exports all declared workers for use in the Apache HTTPD (next).
10. For more info on this file, please see HTTP://TOMCAT.APACHE.ORG/CONNECTORS-DOC/REFERENCE/WORKERS.HTML
11. Note that JBoss AS is already configured to listen on port 8009 for AJP/1.3 requests.
12. Create /conf/jk.conf:
13. LoadModule jk_module /mod_jk.so
14. JkWorkersFile /workers.properties
15. JkLogFile /jk.log
16. JkLogLevel info
17. JkMount /jmx-console jboss1
18. JkMount /jmx-console/* jboss1
19. JkMount /jkstatus jkstatus
20. Don’t forget to include this file in httpd.conf
21. Restart Apache HTTPD
22. Verify that you can access on port 80: HTTP://LOCALHOST/JMX-CONSOLE/
23. Workers jboss1and jkstatuscome from a properties file, because they were exported by worker.list directive.
24. Use /bin/httpd -tto test the syntax of Apache HTTP’s configuration files (including any included files).
25. For more info on mod_jkconfiguration options, please see HTTP://TOMCAT.APACHE.ORG/CONNECTORS-DOC/
26. Note that you can also JkMountin URL-contexts like and. For example, you can replace JkMount /jkstatus jkstatus with:
1. JkMount jkstatus
2. Order deny, allow
3. Deny from all
4. Allow from 127.0.0.1
16.11. Simple Load Balancing
1. Use run.sh -b to run instances on different IPs but same ports
2. Define it in workers.properties:
3. jboss2.type=ajp13
4. jboss2.host=192.168.1.180
5. jboss2.port=8009
6. Define a new load balancing worker:
7. jboss.type=lb
8. jboss.balance_workers=jboss1,jboss2
9. Export the load balancing worker:
10. list=jboss,jkstatus
11. The updated /conf/workers.propertieslooks something like:
12. jboss1.type=ajp13
13. jboss1.host=127.0.0.1
14. jboss1.port=8009
15. jboss2.type=ajp13
16. jboss2.host=192.168.1.180
17. jboss2.port=8009
18. jboss.type=lb
19. jboss.balance_workers=jboss1,jboss2
20. jkstatus.type=status
21. list=jboss,jkstatus
22. Deploy session-test.warto both instances, and update SessionTest.jsp on the second so that its page heading and bgcolor are different (e.g. Server 2, lime)
23. Change/add in conf/jk.conf:
24. JkMount /jmx-console jboss
25. JkMount /jmx-console/* jboss
26. JkMount /session-test jboss
27. JkMount /session-test/* jboss
28. Start both JBoss instances (on local and public IPs) and restart Apache HTTPD
29. Test HTTP://LOCALHOST/SESSION-TEST/
30. The updated /conf/jk.conflooks something like:
31. LoadModule jk_module /mod_jk.so
32. JkWorkersFile /workers.properties
33. JkLogFile /jk.log
34. JkLogLevel info
35. JkMount /jmx-console jboss
36. JkMount /jmx-console/* jboss
37. JkMount /session-test jboss
38. JkMount /session-test/* jboss
39. JkMount /jkstatus jkstatus
40. Observe that we are no longer JkMount-ing jboss1 (or jboss2). We can only use the new load balancer worker called jboss because that is the one exported by listinconf/worker.properties.
41. What happens to “Session Counter” when accessed through HTTP://LOCALHOST/SESSION-TEST/? How about when you access the session-test/ directly, but going to HTTP://LOCALHOST:8080/SESSION-TEST/?
16.12. Enabling Sticky Sessions
1. In workers.propertiesupdate lb worker:
2. jboss.sticky_session=1
3. On a UNIX system add to jk.conf:
4. JkShmFile logs/jk.shm
5. In each Tomcats’ server.xmlset: (or jboss2)
6. After restarting, test with two browsers
7. Directive sticky_sessionis set to 1 (or True) by default, but we turn it on to make it explicit.
8. Enabling the shared memory file (JkShmFile) is not required but allows the HTTPD processes to better communicate on a prefork-type system.
9. The value of the jvmRouteattribute in xml`s `must match the name of the worker instance as configured in the workers.properties file.
16.13. Clustered Session Replication
1. You now need to use the node1and node2 created before
2. In session-test.war/WEB-INF/web.xml, add:
Your application’s HTTP sessions now use the distributed cache.
3. Now :
4. Disable sticky sessions (optional)
5. Redeploy session-test.warto node1/deploy and node2/deploy directories
6. Restart and retest
7. You can know see that your application is fault-tolerant, it supports failover AND state replication
8. Problems with sticky sessions?
9. Uneven distribution of load
10. If one instance goes down, all of its sessions go with it
11. You can configure session replication here:
12. Sessions are replicated by all/deploy/cluster/jboss-cache-manager.sar:
13. o Cache Mode: REPL_SYNC, REPL_ASYNC
14. o Caching Configuration: replication queue
15. o Cluster Name and Configuration: communication
16. Configure session replication per app in WEB-INF/jboss-web.xml
17. o Replication trigger: SET, SET_AND_GET, SET_AND_NON_PRIMITIVE_GET, ACCESS
18. o Replication granularity: SESSION, ATTRIBUTE, FIELD
19. deploy/cluster/jboss-cache-manager.sar/META-INF/jboss-cache-manager-jboss-beans.xml:

16.16. Clustering with Stateful Session Beans
1. Stateful Session Beans have a state for a client
2. Fail-over and Reliability ⇒ Fault-tolerant
3. State managed by JBoss Cache
4. To enable clustering for SFSB, it works the same way as clustering SLSB except that:
5. There is only one load-balancing policy available: FirstAvailable(default for SFSB)
6. This time JBoss Cache is used because the state has to be managed
7. sfsb-cachecache configuration is located in:
8. deploy/cluster/jboss-cache-manager.sar/META-INF/jboss-cache-configs.xml(You can enable this file in the jboss-cache-manager-jboss-beans.xmlfile): Describes cache configuration using the standard JBC 3.x config format
9.deploy/cluster/jboss-cache-manager.sar/META-INF/jboss-cache-manager-jboss-beans.xml: Describes cache configuration using the microcontainer format
10. These configurations affect all SFSB. You can override this configuration for your SFSB though:
11. By annotating with @org.jboss.ejb3.annotation.CacheConfig
12. In the jboss.xmlfile with …
13. The parameters you can configure are the following:
14. idleTimeoutSeconds: Time in seconds an SFSB can be unused before being passivated (default 300)
15. maxSize: maximum number of beans that can be cached (default 10000)
16. name: Specify the name of the cache configuration. sfsb-cacheis the default for SFSB
17. removalTimeoutSeconds: Time in seconds an SFSB can be unused before being deleted by the cache (default 0)
18. replicationIsPassivation: Should a replication be considered as passivation? (default true)
19. Example: To disable passivation, you could set idleTimeoutSecondsand maxSizeto 0.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| JBoss Training | Jul 28 to Aug 12 | View Details |
| JBoss Training | Aug 01 to Aug 16 | View Details |
| JBoss Training | Aug 04 to Aug 19 | View Details |
| JBoss Training | Aug 08 to Aug 23 | View Details |

Ravindra Savaram is a Technical Lead at Mindmajix.com. His passion lies in writing articles on the most popular IT platforms including Machine learning, DevOps, Data Science, Artificial Intelligence, RPA, Deep Learning, and so on. You can stay up to date on all these technologies by following him on LinkedIn and Twitter.


