
- BitBucket Tutorial
- Git Rebase Tutorial
- Branches, Part II – Git
- Centralized Workflow In Git
- Git – Distributed Workflows
- Git Interview Questions And Answers
- Git – Plumbing Commands
- Git – Rewriting History
- Git – Tips & Tricks
- Git – Undoing Changes
- Git – Working With Remotes
- GitHub Interview Questions
- GitLab Tutorial
- Installation of Git
- Patch Workflows – Git
- Git Basic Concepts
- GitHub CI/CD Tutorial
- Git vs SVN
Git Tutorial gives you an overview and talks about the fundamentals of GIT & the various version control systems and GIT.
What is Version Control
Version control is a system that records changes to a file or set of files over time so that you can recall specific versions later.
For the examples in this book, you will use software source code as the files being version controlled, though, in reality, you can do this with nearly any type of file on a computer.
If you are a graphic or web designer and want to keep every version of an image or layout (which you would most certainly want to), a Version Control System (VCS) is a very wise thing to use.
It allows you to revert files back to a previous state, revert the entire project back to a previous state, compare changes over time, see who last modified something that might be causing a problem, who introduced an issue, and when, and more. Using a VCS also generally means that if you screw things up or lose files, you can easily recover.
Also, you get all this for very little overhead.
Many people’s version-control method of choice is to copy files into another directory (perhaps a time-stamped directory, if they’re clever).
This approach is very common because it’s so simple, but it’s also incredibly error-prone. It’s easy to forget which directory you’re in and accidentally write to the wrong file or copy over files when you don’t mean to.
To deal with this issue, programmers long ago developed local VCSs that had a simple database that kept all the changes to files under revision control (see below figure).
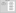
One of the more popular VCS tools was a system called RCS, which is still distributed with many computers today.
Even the popular Mac OS X operating system includes the RCS command when you install the Developer Tools.
This tool basically works by keeping patch sets (that is, the differences between files) from one change to another in a special format on disk; it can then re-create what any file looked like at any point in time by adding up all the patches.
| Related Article - Git Interview Questions |
Centralized Version Control Systems
This is where Distributed Version Control Systems (DVCSs) step in. In a DVCS (such as Git, Mercurial, Bazaar, or Darcs), clients don’t just check out the latest snapshot of the files: they fully mirror the repository.
Thus if any server dies, and these systems were collaborating via it, any of the client repositories can be copied back up to the server to restore it. Every checkout is really a full backup of all the data (see below Figure).
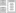
This setup offers many advantages, especially over local VCSs. For example, everyone knows to a certain degree what everyone else on the project is doing.
Administrators have fine-grained control over who can do what, and it’s far easier to administer a CVCS than it is to deal with local databases on every client.

However, this setup also has some serious downsides. The most obvious is the single point of failure that the centralized server represents. If that server goes down for an hour, then during that hour nobody can collaborate at all or save versioned changes to anything they’re working on.
If the hard disk the central database is on becomes corrupted, and proper backups haven’t been kept, you lose absolutely everything—the entire history of the project except whatever single snapshots people happen to have on their local machines.
Local VCS systems suffer from this same problem—whenever you have the entire history of the project in a single place, you risk losing everything.
Distributed Version Control Systems
This is where Distributed Version Control Systems (DVCSs) step in. In a DVCS (such as Git, Mercurial, Bazaar, or Darcs), clients don’t just check out the latest snapshot of the files: they fully mirror the repository.
Thus if any server dies, and these systems were collaborating via it, any of the client repositories can be copied back up to the server to restore it. Every checkout is a full backup of all the data.
History of Git
Git began with a bit of creative destruction and fiery controversy. The Linux kernel is an open-source software project of a fairly large scope.
For most of the lifetime of the Linux kernel maintenance (1991-2002), changes to the software were passed around as patches and archived files. In 2002, the Linux kernel project began using a proprietary DVCS system called BitKeeper.
In 2005, the relationship between the community that developed the Linux kernel and the commercial company that developed BitKeeper broke down, and the tool’s free-of-charge status was revoked.
This prompted the Linux development community (and in particular Linus Torvalds, the creator of Linux) to develop their own tool based on some of the lessons they learned while using BitKeeper. Some of the goals of the new system were as follows:
-
Speed
-
Simple design
-
Strong support for non-linear development (thousands of parallel branches)
-
Fully distributed
-
Ability to handle large projects like the Linux kernel efficiently (speed and data size)
What is Git?
The major difference between Git and any other VCS (Subversion and friends included) is the way Git thinks about its data. Conceptually, most other systems store information as a list of file-based changes.
These systems (CVS, Subversion, Perforce, Bazaar, and so on) think of the information they keep as a set of files and the changes made to each file over time, as illustrated in Figure below.
Fig: Other systems tend to store data as changes to a base version of each file.
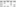
Since its birth in 2005, Git has evolved and matured to be easy to use and yet retain these initial qualities.
It’s incredibly fast, it’s very efficient with large projects, and it has an incredible branching system for non-linear development.
| Explore Git Sample Resumes Sample Resumes! Download & Edit, Get Noticed by Top Employers! |
Git doesn’t think of or store its data this way. Instead, Git thinks of its data more like a set of snapshots of a mini filesystem. Every time you commit or save the state of your project in Git, it basically takes a picture of what all your files look like at that moment and stores a reference to that snapshot.
To be efficient, if files have not changed, Git doesn’t store the file again—just a link to the previous identical file it has already stored. Git thinks about its data more like the Figure below.
Fig: Git stores data as snapshots of the project over time.

 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Git Training | Jul 18 to Aug 02 | View Details |
| Git Training | Jul 21 to Aug 05 | View Details |
| Git Training | Jul 25 to Aug 09 | View Details |
| Git Training | Jul 28 to Aug 12 | View Details |

Priyanka Vatsa is a Senior Content writer with more than five years’ worth of experience in writing for Mindmajix on various IT platforms such as Palo Alto Networks, Microsoft Dynamics 365, Siebel, CCNA, Git, and Nodejs. She was involved in projects on these technologies in the past, and now, she regularly produces content on them. Reach out to her via LinkedIn and Twitter.



