
- BitBucket Tutorial
- Git Rebase Tutorial
- Branches, Part II – Git
- Centralized Workflow In Git
- Git – Distributed Workflows
- Git Interview Questions And Answers
- Git – Plumbing Commands
- Git – Rewriting History
- Git – Tips & Tricks
- Git Tutorial
- Git – Undoing Changes
- Git – Working With Remotes
- GitHub Interview Questions
- GitLab Tutorial
- Installation of Git
- Patch Workflows – Git
- Git Basic Concepts
- GitHub CI/CD Tutorial
You've probably heard of Version Control Systems, or VCS, sometimes known as source control, if you're writing or tracking code for a project. A version control system's main job is to house a project and monitor its evolution over time.
Developers may compare file changes, track commits, suggest modifications, view project history, roll back to earlier versions of the project, and more with a VCS. As they implement DevOps, continuous delivery, and keep up a productive workflow, developers and software teams now cannot function without a good VCS. Git, SVN, Mercurial, and Perforce are a few of the most popular version control programs.
It can be difficult to choose the best VCS to host your files for you and your team. In essence, you are laying the foundations for how your team will construct projects, and developers frequently have strong ideas on the subject.
We've prepared a few key points of comparison between Git and SVN to assist you in selecting the best VCS for your projects and processes.
| Table Of Content - Git vs SVN |
What is Git?

Git was created to maintain the Linux Kernel's development. Git was established on the tenets of full distribution, quickness, simplicity, scalability, and strong support for non-linear development. There is a lot of "lore" about Git and how it was made, including how it got its odd name, why it was made in the first place, and other things.
The most crucial thing to grasp is that Git was developed to advance the distributed model beyond its previous limits and to address common problems in novel ways.
| If you want to enrich your career and become a professional in Git, then enroll in "Git Online Training" - This course will help you to achieve excellence in this domain. |
What is SVN?

As a distributed as open source, SVN, or Subversion, uses a centralized version control system, which means all data and files are kept on a single server.
To be "universally recognized and adopted as an open-source, centralized VCS, characterized by its reliability as a haven for valuable data; the simplicity of its model and usage; and its ability to support the needs of a wide variety of users and projects, from individuals to large-scale enterprise operations," according to Subversion.
Pros and Cons of Git vs SVN
-
Pros and Cons of Git
Pros:
- Works locally: Contributors work on copies of the primary repository, which they can continue to work on when off from the primary repository's network. When updates are prepared to be pushed, contributors only need to connect. This reduces network traffic to the primary repository as well.
- Ensures there isn't just one point of failure: There is little to worry about if the main repository fails because the repository is dispersed in local copies. One of the local copies can be used to restore the primary repository.
- Effectively manages merging from numerous contributors: On their individual copies of the main repository, contributors each work independently. Then, Git offers a powerful method for comparing and incorporating each contributor's modifications. This includes staging, which enables contributors to concentrate on certain features without affecting others.
| Related Article: Learn Git Tutorial for Beginners |
Cons:
- Increased learning curve: You must make your changes locally, stage them, and then merge them back into the main branch in order to collaborate using Git. For non-technical consumers in particular, this process might become challenging.
- Has no fine-grained access control: Git allows you to set restrictions on a contributor's ability to add branches and merge updates to the main repository. You cannot, however, limit access to particular areas of the repository. Every file in the repository is accessible to everyone with access to it, and local repositories are exact copies of the whole codebase.
- Does not handle the storage of huge binary files well: Git cannot successfully compress these files. Therefore each modification to a sizable binary file can cause the repository size to increase rapidly.
-
Pros and Cons of SVN
Pros:
- Adopt a simpler strategy: The process of developing a new feature branch and merging it into the main branch is simple to understand and relatively quick. This makes SVN a tool that can be effectively used by non-technical contributors and requires minimal training when starting started.
- Encourages a top-down strategy: There is just one instance of the complete repository because everything is centralized in an SVN repository. This makes it possible to control repository access in detail. Access for each contributor may be restricted to specific directories and files. When managing security hierarchies within a repository, SVN is a wise choice.
- Large binary files are efficiently stored: Teams can store binary files without having to worry about the storage requirements for each modification exponentially increasing. This is especially useful for teams whose binary files change frequently. Although this is not a worry for every company, for specific workflows and version control use cases, this capability can be a huge help.
Cons:
- Offer only a few offline capabilities: Utilising a client-server architecture, everything runs off of a single central repository. Contributors essentially lose the capacity to contribute while they are offline and unable to connect to the server. Since contributors must continually access the main repository, this also results in more traffic to the server.
- A single point of failure may be the server hosting the central repository: There is only one instance of the complete repository because contributors rarely make local copies of it unless a backup copy is made. A software development project could suffer greatly if an instance problem, such as data corruption, arises.

Advantages of Git Over SVN
One significant benefit of using Git locally and offline is this capability. Working offline is practically impossible with SVN because it requires contributors to be connected to the main repository server.
When it comes to merging and conflict resolution, Git performs better than SVN. Git was created for an environment where many contributors might be working on the same sections of a codebase, such as an open-source environment. Git has established a strong framework for resolving merge conflicts that streamline and manage the process in order to support this kind of collaboration.
Git's distributed version control mechanism lessens the risk of the primary repository being lost. The chance of losing your main repository entirely is much decreased because contributors clone it. On the other hand, should something happen to the primary repository, SVN's centralized form of version control raises the possibility of a single point of failure.
| Related Article: The Basics of Git |
Advantages of SVN Over Git
The management of contributions and contributors is made simpler by SVN's centralized repository model. A contributor who has access to the repository has access to the whole repository because Git does not enable codebase access limitations. Contrarily, SVN offers finer control, enabling restrictions on specific contributors down to the directory and file levels.
Contributing is also made simpler with SVN. Git has a strong conflict handling system, but it can be intimidating for beginning users. The faster and easier route between developing a new feature and merging it into the trunk makes SVN's system more user-friendly.
On several performance criteria, SVN prevails. It excels at managing network traffic. As a result, the network demand for this is well managed even if contributors may need to be connected to the server to finish work. Additionally, SVN stores and compresses big binaries well. Consider utilizing SVN if your project involves huge binary files.
Which is Better Git or SVN?
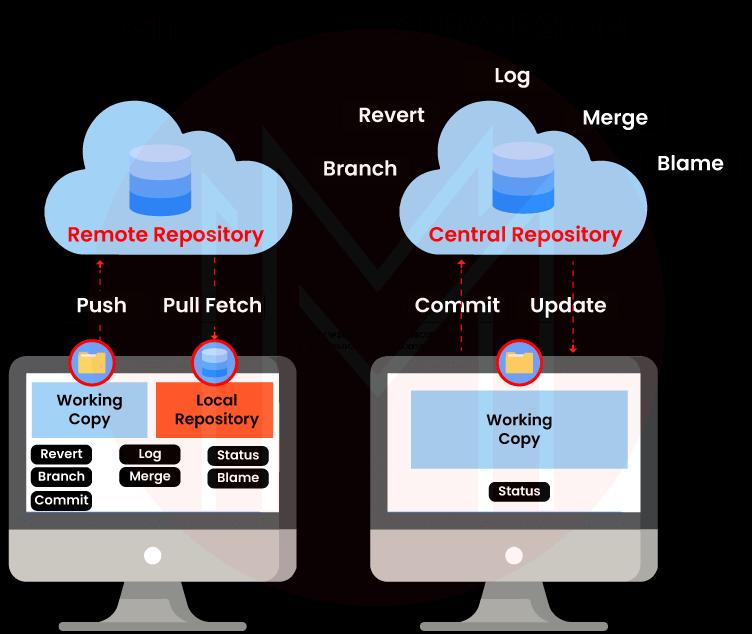
Each of the version control programs discussed here, SVN and Git, has distinct advantages and disadvantages. Each one is better suited to specific use scenarios than the other, but neither one clearly outshines the other.
- When you require a VCS that encourages top-down administration, allows for simple contributions, and does not require you to work totally offline, use SVN. Because of its granular access control, SVN frequently wins out for enterprise usage. If you need to create security hierarchies, SVN is the obvious choice.
- Use Git when several contributors must work concurrently when many possible merge conflicts are anticipated, and when contributors must be able to work locally and offline. Git makes sense for the majority of open-source projects because it resolves merge disputes, where contributors frequently operate independently. Git excels in a variety of settings with intricate codebases and dispersed teams.
| Related Article: Git Installation |
Git vs SVN - Comparison
| Git | SVN |
| Linus Torvalds created the distributed version control system known as Git in 2005. It puts a focus on efficiency and data security. | Under the Apache license, Apache Subversion is an open source version and revision control system for software. |
| A distributed model exists in Git. | A centralized Model exists in SVN |
| In git, each user has a local copy of the code that corresponds to their own branch. | A working copy that also makes modifications and commits them to the primary repository exists in SVN. |
| We can do git operations without a network connection using git. | To perform the SVN process, we needed a network. |
| Git is trickier to learn. It has many ideas and instructions. | In comparison to git, SVN is significantly simpler to learn. |
| Git is slow because it deals with a lot of data, particularly binary files that change frequently. | The vast amount of binary files are easily controlled via SVN. |
| We just create in git. git repository | Each folder has a.svn directory created in SVN. |
| In comparison to SVN, it has a poor user interface. | SVN offers a nicer, more user-friendly interface. |
Conclusion
Powerful version control tools like SVN and Git each take a unique tack when it comes to organizing and merging code changes. SVN has a centralized model, whereas Git employs a distributed model. Which VCS you select will primarily depend on the needs of your software development project. You should be able to choose the optimal version control system for your requirements after reading this article.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Git Training | Jul 25 to Aug 09 | View Details |
| Git Training | Jul 28 to Aug 12 | View Details |
| Git Training | Aug 01 to Aug 16 | View Details |
| Git Training | Aug 04 to Aug 19 | View Details |

Madhuri is a Senior Content Creator at MindMajix. She has written about a range of different topics on various technologies, which include, Splunk, Tensorflow, Selenium, and CEH. She spends most of her time researching on technology, and startups. Connect with her via LinkedIn and Twitter .



