
- A Deep Dive Into Talend ETL
- Talend Interview Questions
- Talend Tutorial
- Talend vs Informatica - What's The Difference?
- Checking a Column against a list and lookup in Talend
- Common Mistakes And Other Useful Hints And Tips - Talend
- Creating and Adding a Context Group to Your Job - TALEND
- Pseudo Components and Custom Routines in Talend
- Creating Simple, Complex and Random Test in Talend
- How to Create tMap Expressions using tMap Component – Talend
- Creating Validation Rules and Binary Error Codes in Talend
- Talend Database Tutorial
- Filtering and Splitting Input Rows in Talend
- How to Manage Metadata using Talend Schema - TALEND
- Joining Data Using tMap, Hierarchical Joins | Talend
- Locating Compilation and Executing Errors - TALEND
- Managing Talend Context Variables
- Talend Data Validation
- Organizing Talend Files
- Printing out Context and Dumping the Output in Talend
- Processing Multiple and Validation Files – Talend
- Reading from and Writing to a Database Table – Talend
- Returning Codes and Passing Parameters to a Child Job - TALEND
- logical Testing the most used pattern in Talend
- Using Java In Talend
- Java debugger and tJavaRow in Talend
- Using tContextLoad and Implicit Context Loading in Talend
- Using the Ternary Operator, Intermediate Variables and Reload – Talend
- Talend – Working with Databases
- Working with Web Services and Queues - TALEND
- Working with XML - Talend
- Various Talend Products and their Features
Adding a HEADER AND TRAILER to a file
Let us look at how to add a custom header, footer to the file. This is often required for file processing and validation.
| If you would like to Enrich your career with a Talend certified professional, then visit Mindmajix - A Global online training platform: “Talend Certification Course”. This course will help you to achieve excellence in this domain. |
Requirement: Create a delimited file with the below structure.
Header Part
File Name: Name of the actual File.
PID : process ID.
Header Columns.Body Part
Text Data.Footer Part
File Created Date: Date & Time.
Number of Records: record count.This is our final job design.

Final Job Design
Step 1: We`ll create Header part first.
Step 2: Add tFixedFlowInput component and configure as below.
- Add one column “value” with string type.
- Select “Use inline-table” option and add three rows.
- Add each line of the below code to each line created previously.
"File Name: CustomerDetails.csv"
"PID :"+pid
"Id,Name,City,State,Street"- See the image for more details.

tFixedFlowInput Setting
Step 3: Add tFileOutputDelimited and connect with tFixedFlowInput component using Main flow, then configured as follows.
- Add file path name “C:/home/CustomerDetails.csv”.(you can change this)
- Row separator=”n”
- Field Separator=”,”
Step 4: Add tRowGenerator

Step 5: Copy Paste tFileOutputDelimited_1 component which was created in Step 3, then connect tFileOutputDelimited_2 with tRowGenerator using main flow. Configure as follows.
- Select Option “Append”.
- Click on “Main” flow and go to the “Advance setting” tab and select the option “Monitor this connection”.
- Unchecked “Use Input Connection as Label”. It will show you a “Label” and text box to write, write “Number Of Records:” in the same text box.
Step 6: Create a context variable named as “NumberOfRows”, then copy and paste tFixedFlowInput_1.
Step 7: Configure newly pasted tFixedFlowInput_2 component.
- Delete the second last line from the list.
- On second line, add this code "File Created Date: "+TalendDate.getDate("dd-MMM-yyyy HH:mm:ss").
- On the third line add the context variable. context.NumberOfRows.
Step 8: Copy paste tFileOutputDelimited_2 and connect with tFixedFlowInput_2 using main flow. No need to do any additional configuration.
Step 9: Add tFlowMeterCatcher component and add java row and connect each other using main flow, don`t click on “Synch” button on tJavaRow. Write below code in tJavaRow component.
context.NumberOfRows=input_row.label+input_row.count;Step 10: Run the job, it will create files with the Header part, Data part, and footer part. Below is our final output.
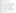
Header and Footer Output
| Related Article: Talend Interview Questions and Answers |
Reading headers and trailers using tMap
This recipe shows how to parse a file that has a header and trailer records, and a record type at the start of a line.
Getting ready
Open the jo_cook_ch08_0060_headTrailtMap job.
How to accomplish it…
The steps for reading headers and trailers using tMap are as follows:
- Drag a tMap component onto the canvas.
- Connect the tFileInputFullRow to tMap, and rename the flow to customerIn.
- Open tMap, and create three new outputs. Name them header, detail, and trailer.
- Copy the input field line into each of the new outputs.
- Add the expression filter line.startsWith(“00”) to the header output table.
- Add the expression filter line.startsWith(“01”) to the detail output table.
- Add the expression filter line.startsWith(“99”) to the trailer output table.
- Your tMap should now look like the one shown as follows:
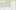
- Close tMap, and drag three tExtractDelimitedFields components to the canvas, along with three tLogRow
- Join each output from tMap to each of the tExtractDelimitedFields components.
- Change the delimiter in each of the tExtractDelimitedFields components to comma (,).
- Open the tLogRow components, and assign each one a schema from those listed, as follows. This can be easily done by dragging the metadata onto the tLogRow component as described in, METADATA AND SCHEMAS.
sc_cook_ch8_0060_genericCustomerHeader
sc_cook_ch8_0060_genericCustomerDetail
sc_cook_ch8_0060_genericCustomerTrailer- Link the tExtractDelimitedFields to the tLogRows, making sure that you accept the output schema.
- Your job should now look like this:
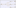
- Change the tLogRow components to the output Mode of Vertical, and run the job.
| Related Article: Talend Tutorial for Beginners |
How it works…
tFileInputFullRow allows us to read a row of any format into tMap. This is important because we do not want records to be rejected due to schema errors at this stage. The start of each row is then tested for the record type; 00, 01, or 02, the header, detail, or trailer records respectively. The different rows are then passed to a tExtractDelimitedFields component for breaking down into the individual schema columns.
There’s more…
This isn’t the only method of reading files with headers and trailers, and in fact, the best Talend method would be to use the tFileInputMSDelimited component, for this example. This method, however, is much more flexible, in which the conditions for sending in the data as an output to each of the flows do not depend upon a fixed field being present.
Reading headers and trailers with no identifiers
This recipe shows how to parse a file that has a header and trailer records but does not have an associated record type. Instead, the header is the first record in the file, and the trailer is the last record in the file.
Getting ready
Open the jo_cook_ch08_0070_headTrailtMapNoType job. You will see that it is a slightly changed version of the completed job from the previous recipe; the output schemas have changed.
How to achieve it…
The steps for reading headers and trailers with no identifiers are as follows:
- Drag a tFileRowCount component onto the canvas.
- Open the tFileRowCount, and change File Name to
context.cookbookData+"/chapter8/chapter08_jo_0070_customerData.txt which is the same as our input file.
Connect an onSubJobOk trigger from the tFileRowCount component to the tFileInputDelimited.
Open the tMap, and add a new variable rowCount. Set its expression to Numeric.sequence(“rowNumber”,1,1).
Change the Filter expressions for header, detail, and trailer to those shown as follows:
Var.rowNumber == 1
Var.rowNumber !=
((Integer)globalMap.get("tFileRowCount_1_COUNT"))
Var.rowNumber ==
((Integer)globalMap.get("tFileRowCount_1_COUNT"))- Set the detail and trailer output options to Catch output rejects.
- Your tMap should now look like this:

- Run the job, and you should see the individual row types being printed.
| Explore TALEND Sample Resumes! Download & Edit, Get Noticed by Top Employers! |
How it works…
The tFileRowCount component tells us how many rows are present in the file.
In the tMap, we use a sequence to calculate the current line number. If the line number is 1, then we have a header row. If it is equal to the row count (held in globalMap), then we have a trailer row, and all other rows are detail rows.
We then use the tExtractDelimitedFields to extract the individual delimited fields into a different schema for each of the row types.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Talend Training | Jul 28 to Aug 12 | View Details |
| Talend Training | Aug 01 to Aug 16 | View Details |
| Talend Training | Aug 04 to Aug 19 | View Details |
| Talend Training | Aug 08 to Aug 23 | View Details |

Ravindra Savaram is a Technical Lead at Mindmajix.com. His passion lies in writing articles on the most popular IT platforms including Machine learning, DevOps, Data Science, Artificial Intelligence, RPA, Deep Learning, and so on. You can stay up to date on all these technologies by following him on LinkedIn and Twitter.









