
- A Deep Dive Into Talend ETL
- Talend Interview Questions
- Talend Tutorial
- Talend vs Informatica - What's The Difference?
- Adding and Reading Talend Headers and Trailers - TALEND
- Checking a Column against a list and lookup in Talend
- Common Mistakes And Other Useful Hints And Tips - Talend
- Creating and Adding a Context Group to Your Job - TALEND
- Pseudo Components and Custom Routines in Talend
- Creating Simple, Complex and Random Test in Talend
- How to Create tMap Expressions using tMap Component – Talend
- Creating Validation Rules and Binary Error Codes in Talend
- Talend Database Tutorial
- Filtering and Splitting Input Rows in Talend
- How to Manage Metadata using Talend Schema - TALEND
- Joining Data Using tMap, Hierarchical Joins | Talend
- Locating Compilation and Executing Errors - TALEND
- Managing Talend Context Variables
- Talend Data Validation
- Printing out Context and Dumping the Output in Talend
- Processing Multiple and Validation Files – Talend
- Reading from and Writing to a Database Table – Talend
- Returning Codes and Passing Parameters to a Child Job - TALEND
- logical Testing the most used pattern in Talend
- Using Java In Talend
- Java debugger and tJavaRow in Talend
- Using tContextLoad and Implicit Context Loading in Talend
- Using the Ternary Operator, Intermediate Variables and Reload – Talend
- Talend – Working with Databases
- Working with Web Services and Queues - TALEND
- Working with XML - Talend
- Various Talend Products and their Features
This segment contains recipes that show some of the techniques used to read and write data to files. It also contains recipes that show techniques to MANAGE FILES within a file system.
| In this article, you will learn below topics |
It isn’t very efficient to process large batches of information via a web service, nor is it particularly desirable to pull data from an application database during peak hours. Thus, many organizations still maintain a file-based overnight batch process using large extracts in file format.
In addition, many older, legacy applications rely solely on file-based data for communicating with the outside world.
It is therefore very important for the data integration developer to understand many file types and be able to manage them efficiently and effectively.
| If you would like to Enrich your career with a Talend certified professional, then visit Mindmajix - A Global online training platform: “Talend Certification Course”. This course will help you to achieve excellence in this domain. |
Appending Records to a File
This simple recipe shows how a file can be built-in within different sub jobs by appending data to an existing file. The append method is one way of building complex files.
Open the jo_cook_ch08_0010_fileAppend job.
Steps for Appending Records
The steps for appending records to a file are as follows:
- Copy the complete subjob1 – copy me sub job and paste it to create a second sub job.
- Link the two sub jobs using an onSubjobOK
- Open tFixedFlowInput, and change Records from first subjob to Records from second subjob.
- Open tFileOutputDelimited on the new sub job, and tick Append, as shown in the following screenshot:
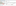
The first sub job creates the file, and the second sub job appends to the same file.
While relatively trivial, this recipe demonstrates a very powerful method for creating files that do not adhere to the norm, such as files containing a mixture of fixed and delimited data or free format strings.
Concatenating files using the append method
In addition to concatenating records using the append method, it is also possible to use the same method to concatenate many files into one file.
In most cases, the files would be identified using tFileList, and then appended to a single output file. One word of caution though; if you forget to set the mode to append, it will result in each file overwriting its predecessor, leaving you with just the output from a single file; the last one to be found.
It also presents an additional problem when the job is run for a second time. In that the file will already exist, and the new data will simply be added to the old data.

Tip
It is thus a good idea when using file append to add a tFileDelete component to the beginning of the job. This means that a file is always created anew by the first iteration (but always make sure Fail on error is unchecked for the deleted component, otherwise it will fail when you run the job at the first time).
Ensure that the file name is unique for each run, perhaps by adding the process ID to the file name or even the datetime including milliseconds.
| Related Article: Talend Tutorial for Beginners |
Reading Rows using a Regular Expression
A regular expression (regex) is a powerful method for pattern matching and replacement within many programming languages. One interesting use for regular expressions is when dealing with unusual input formats that are difficult to describe using normal delimited or fixed-width file formatting. This recipe shows how regex can be used to identify a set of input columns from an unstructured input row.
Getting ready
The screenshot of the chapter8_jo_0020_jobLogData.txt file is as follows:
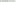
You should notice that there is neither an obvious delimiter nor does each record fit a fixed-width format.
Now, open the jo_cook_ch08_0020_readRegexData job.
How to achieve it…
The steps for reading rows using regular expressions are as follows:
- Open tFileInputRegex and enter the following code:
"^job: "+ "([a-zA-Z0-9_]*)"+ ". *start *"+
"([0-9][0-9]:[0-9][0-9]:[0-9][0-9])"+ " - "+
"(success|failure)"+ ".*"- Run the job, and you will see that jobName, startTime, and status have been successfully extracted from the string, as shown in the following screenshot:
Regular expressions require a pattern that will match a whole line of data, with parts of the pattern in brackets being retained and the rest being discarded. A short explanation of the regular expression code for the preceding example is detailed as follows:
- The first line of the regex starts with ^ (the symbol for start of line) followed by the text job and two spaces.
- The second line details that we want a combination of letters, numbers, and underscores. This part of the pattern is in brackets, so is put into the first field; jobName.
- The third line details the filler text, which consists of a dot (. which needs to be escaped), two spaces, the text start, and another space. This text is not in brackets, so is discarded.
- The fourth line details two numbers and a colon repeated three times. This text is in brackets, and is copied to field two in the schema; startTime.
- The fifth line consists of a space, then a minus, then a space. This is discarded. The sixth line describes a pattern that is either success or failure. This value is retained in the third column in the schema; status.
- The final line consists of any number of any characters, and it is discarded.
As mentioned, this is only a brief description of the previous code and of regular expressions.
| Related Article: Creating Validation Rules and Binary Error Codes in Talend |
You will probably have noticed that the lines in the pattern are organized in terms of patterns to keep and to discard. The regular expression doesn’t need to be specified in this way; however, it does make identifying the fields much easier than if the whole pattern were simply on a single line.
Java regular expressions will not ignore carriage return or newline characters, unless explicitly told to do so. If you need to create regular expressions that span multiple lines, then simply add (?s) to the beginning of a regular expression. This has the same effect as the Java DOTALL option.
Using temporary files
Occasionally, it is necessary to create intermediate files within a job that are only used during the lifetime of the job. This recipe shows how to use Talend temporary files.
Open the jo_cook_ch04_0030_temporaryFile job.
The steps for using temporary files are as follows:
- Open the tCreateFileTemporary component, and change the name to customerTemp_XXXX.
- Select the options Remove file when execution is over, and Use temporary system directory.
- Open the tempCustomerOut component, and change File Name to ((String)globalMap.get(“tCreateTemporaryFile_1_FILEPATH”)).
- Repeat the steps for the tempCustomerIn
- Run the job, and you will see that data is written to and read from the temporary file.
How it works…
The tCreateTemporaryFile component creates an empty file that is then available for writing in the main sub job. The name of the file is stored in the globalMap variable tCreateTemporaryFile_1_FILEPATH, which is referenced by both the output and input components.At the end of the job, Talend then deletes the temporary file to free the space.
Temporary files are best used when there are large volumes of data that would or could possibly cause memory issues. For lower volume data, it is recommended that tHashMap or an in process table is used instead, because this will create much more performant code. See WORKING WITH DATABASES, for an example of using the in-process table.
There’s more…
It is necessary to keep the XXXX format in the temporary file name because Talend uses this to add additional information to the file name to ensure that it is unique for the job instance. This is very important if multiple instances of a job are executed at the same time because it would be catastrophic if all of the jobs are written to the same temporary file.
| Related Article: Talend Interview Questions |
Storing Intermediate Data in the Memory using tHashMap
While not strictly file-based, there are alternative methods for storing intermediate data that are more efficient than using temporary files, as long as there is enough memory to hold the temporary data. This recipe shows how to do this using the tHashMap component.
Getting ready
Open the jo_cook_ch08_0040_temporaryDatatHashMap job. You will notice that this is the same job as in the previous recipe.
How to do it…
The steps for storing intermediate data in memory using tHashMap are as follows:
- Delete the tCreateTemporaryfile
- Replace the tFileOutputDelimited with a tHashInput component, having a generic schema of sc_cook_ch8_0040_genericCustomerOut.
- Replace tFileInputDelimited with tHashInput component sc_cook_ch8_0040_genericCustomerOut.
- Add the onSubjobOk
- Run the job, and the results will be the same as for the previous recipe.
How it works…
tHashMap creates an in-memory structure that holds all the data in the flow. It can then be used as an input in a downstream sub job.
There’s more…
tHashMap relies on enough memory being present for all the hash mapped data to be stored. If there is not enough memory, then it is best to use a temporary file.
tHashMap is a very useful component for storing data in memory, and can also be used to store lookup data that can be reused across multiple joins.
Using the Information in the Header and Trailer
This recipe follows on from the previous recipe, but shows how the information in the header can be added to the detail data, and the data in the trailer used for validation, as is typically the case with files of this type.
Getting ready
Open the jo_cook_ch08_0080_useHeaderAndTrailerInfo job. This job is the completed job from the previous recipe; however, do note that the tLogRow components have now been replaced with tHashOutput components. Also, note that three tHashInput components have also been added and configured.
How to achieve it…
We will be performing two main tasks; the first is to use the trailer information to validate the file, and then take a column from the header to use in all the output records.
Validation subjob
- Drag a tMap component onto the canvas, and join the trailer input to it. Rename the flow to trailerIn.
- Open the tMap component, and create an output table named rowCountError.
- Drag the input detailCount field to the output.
- Add a new Integer output field named actualCount.
- Add a new Integer variable also named actualCount. Set its expression to ((Integer)globalMap.get(“tExtractDelimitedFields_2_NB_LINE”)).
- Copy this to the output field actualCount.
- Add a filter expression to the output table; detailCount ! = Var.actualCount.
- Your tMap should now look like this:

- Add a tDie component, and connect the output of the tMap to the tDie.
- Run the job, and you will see that it fails, because the number of rows in the file is 4, yet the trailer says 5.
Use the header information subjob
- Activate the header and detail tHashInput
- Drag a tMap component onto the canvas, and join the detail input to it. Rename the flow to detail1.
- Join the header as a lookup to the tMap, and rename the flow to header1.
- Create an output named detailHeader, and drag all the input detail fields to the output from both the detail and header inputs.
- Your tMap should now look like this:
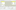
- Add a tLogRow, and join the output of the tMap to the tLogRow. Change the Mode of the tLogRow to Table.
- Manually edit the input file
context.cookbookData+"/chapter8/chapter08_jo_0080_customerData.txt and change the final row in the file to 00004.
- Run the job, and you will see that the job no longer fails, and that each detail row has the same file data as copied from the header record.
How it works…
The job first separates the header trailer and detail rows, validates the row count in the trailer against the number of physical rows read, and then adds the file date to each detail row.
Validating using the trailer information
The validation sub-job compares the row count from the trailer with the actual row count. The only output from tMap is controlled by a condition that checks the value of the trailer count with the number of lines (tExtractDelimitedFields_2_NB_LINE) passed through the tExtractDelimitedFields component, which is stored in globalMap.
Using the header information in the detail
The header data is added to the tMap as a lookup. You will notice that there are no join links between the detail row and the header, which means that we have an all-all-join. So, every detail record is matched to the header record, thus populating the filing date for every detail record.
| Explore TALEND Sample Resumes! Download & Edit, Get Noticed by Top Employers! |
There’s more…
You could choose to copy the header and trailer information into globalMap as an alternative to using tHashMap components, using a tFlowToIterate component in place of the header and trailer components, or a tJava component, where the column values are explicitly copied into globalMap.This method does make adding the data to the detail simpler (because no join is needed, just a reference to globalMap); however, it also makes the validation slightly more complex, because the compare function does need a row to be created using a tFixedFlowInput.
The tDie message in this job isn’t very useful. If you wish to make it more useful, then change the message to that given as follows:
“Error: Counts do not match. Trailer: “+rowCountError.trailerCount+”. Actual : “+rowCountError.actualCount
To copy data to globalMap using tJava, see the Setting context variables and globalMap variables using tJava recipe is shown in USING JAVA IN TALEND.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Talend Training | Aug 01 to Aug 16 | View Details |
| Talend Training | Aug 04 to Aug 19 | View Details |
| Talend Training | Aug 08 to Aug 23 | View Details |
| Talend Training | Aug 11 to Aug 26 | View Details |

Ravindra Savaram is a Technical Lead at Mindmajix.com. His passion lies in writing articles on the most popular IT platforms including Machine learning, DevOps, Data Science, Artificial Intelligence, RPA, Deep Learning, and so on. You can stay up to date on all these technologies by following him on LinkedIn and Twitter.









