
- A Deep Dive Into Talend ETL
- Talend Interview Questions
- Talend Tutorial
- Talend vs Informatica - What's The Difference?
- Adding and Reading Talend Headers and Trailers - TALEND
- Checking a Column against a list and lookup in Talend
- Creating and Adding a Context Group to Your Job - TALEND
- Pseudo Components and Custom Routines in Talend
- Creating Simple, Complex and Random Test in Talend
- How to Create tMap Expressions using tMap Component – Talend
- Creating Validation Rules and Binary Error Codes in Talend
- Talend Database Tutorial
- Filtering and Splitting Input Rows in Talend
- How to Manage Metadata using Talend Schema - TALEND
- Joining Data Using tMap, Hierarchical Joins | Talend
- Locating Compilation and Executing Errors - TALEND
- Managing Talend Context Variables
- Talend Data Validation
- Organizing Talend Files
- Printing out Context and Dumping the Output in Talend
- Processing Multiple and Validation Files – Talend
- Reading from and Writing to a Database Table – Talend
- Returning Codes and Passing Parameters to a Child Job - TALEND
- logical Testing the most used pattern in Talend
- Using Java In Talend
- Java debugger and tJavaRow in Talend
- Using tContextLoad and Implicit Context Loading in Talend
- Using the Ternary Operator, Intermediate Variables and Reload – Talend
- Talend – Working with Databases
- Working with Web Services and Queues - TALEND
- Working with XML - Talend
- Various Talend Products and their Features
My tab is missing
If you find that, say, your Run job or context tab has gone missing, perhaps as a result of you accidentally closing them, then there are two options for getting them back.
If you would like to Enrich your career with a Talend certified professional, then visit Mindmajix - A Global online training platform: “Talend Certification Training” Course. This course will help you to achieve excellence in this domain.
How to do it…
The first option will restore a tab, the second will reset your whole UI.
Show view:
This method allows you to simply restore a missing tab.
- In the show view method, Click on Window, then click on Show view.
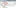
- Open the Talend folder if it isn’t already open, then click on the tab that you are missing.

Reset the perspective
This option allows you to reset the UI to its original format, so it is more disruptive than the previous method.
- In reset the perspective method, at the top right-hand side of the Studio, there is a list of perspectives.
- Click the integration perspective
- Right-click then click, on Reset, as shown in the next screenshot:

- Click on OK on the dialog and your whole Integration view will be reset to the default, which will return your missing tabs.
RELOADS going missing at each row global variable
When using RELOAD at each row with global map Key, Talend allows you to cut and paste expressions into the global map variable, but when you go out of the tMap component and come back in again, you will see that it hasn’t changed.

How to do it…
To get around this, you have one of two options:
- Drag the field from an input source. This option is limited, in that the expression will be just the field name, so you cannot apply any other logic to the variable, such as a substring or uppercase.
- The second (and preferred option) is to edit the expression in the Expression editor. This method allows any expression to be coded to ensure that the variable is set correctly, as shown in the next screenshot:

Dragging component globalMap variables
All components produce one or more globalMap variables that can be used in other components, such as tJavaRow.
If you do have lots of components, then using Ctrl + Space to locate your specific globalMap variable may be difficult.
A simpler method is to open the component tab for the component, ensuring that it is in panel mode and that you can see the outline view in the bottom right-hand side of the studio.
You can then simply expand the given component and drag the variables from the outline panel into your code panel, as shown in the next screenshot:
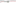
Upon dragging the GlobalMap variable from the Outline window to the value property of the tSetGlobalVar component the value entry field remains grey and the windows cursor shows a stop sign.
Frequently Asked TALEND Interview Questions & Answers
Some complex date formats
Java provides a wide range of date options that can be used to define date formats, but sometimes the options to choose for a particular date-time string aren’t immediately obvious.
Some date formats that may prove useful are as follows:
- ISO 8601 with offset standard: This format contains date, time, and the offset from UTC, as well as the T character that designates the start of the time, for example, 2007-04-05T12:30:22-02:00.
The pattern for this date and time format is yyyy-MM -dd’T’HH:mm:ssXXX.
- Mtime pattern: The tFileProperties component returns a field named mtime_string that is, a string representation of a date and time format, for example, Wed Mar 13 23:53:07 GMT 2013.
The pattern for this date and time format is EEE MMM dd HH:mm:ss z yyyy.
------ Also Read: Using Java In Talend ------
Capturing tMap rejects
The tMap component is the most powerful and flexible of the Talend components, but unless you know where to look, some of the options available aren’t immediately obvious. Take for example, the Die on error flag.
For most components, this is in the main component panel, but for tMap, it is in the tMap configurations dialog, as shown in the next screenshot:
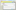
Unchecking the Die on error box will create a new output error flow called ErrorReject, containing a message and a stack trace. Additional fields may be added if required, as shown in the next screenshot:

Adding job name, project name, and other job-specific information
Often, for logging or error messaging purposes, it is required to capture information about the job, such as the job name or the project name.
Three common values that can be used in a job are shown in the following table:
Job version jobVersion
Job name jobName
Talend project name projectName
Talend also stores a host of other variables, such as parent and child process IDs that can be easily found by opening an empty job and inspecting the Java code.

Printing tMap variables
If you inspect code generated from a tMap variable, you will see that each of the expressions are converted into a line of the following format: output column = expression;.
- This suggests that the expression is limited to one line of Java code.
- Although this is how we would normally treat tMap expressions, this isn’t strictly true, and there is one scenario where breaking this rule may be useful.
- The scenario in question relates to tMap variables. If a tMap variable fails due to an exception in a variable expression that is itself a result of a variable expression, then the job can become quite difficult to debug.
- To make it easier to see what is happening in each step, we can add a System.out.println code to an expression to print the state prior to execution of the failing step.
In this case, we simply force the expression logic in the generated code to become:
output column = expression; System.out.println(output column);This is how it looks in the expression editor in Talend:

Stopping memory errors in Talend
When dealing with large amounts of data, there is often a trade-off between performance and memory usage, so it is likely that at some point in your Talend career, you will encounter a problem that is memory-related.
This section will cover many of the actions that can be taken to ensure that you are able to deal with your memory errors quickly and efficiently.
Increasing the memory allocated to a job
As your project grows, Talend Studio performance can be slowed down. You are usually required to allocate more memory to Talend Studio to improve its performance.
Procedure
For Linux / Solaris/ Windows systems :
You can modify the memory allocated to Talend Studio by modifying the relevant Studio .ini configuration file according to your system, such as TOS_DI-win32-x86.ini for 32-bit Windows systems. For Linux / Solaris / Windows system, the relevant .ini configuration file is located in your Studio installation folder.
By default the ini file includes the following JVM parameters:
-vmargs
-Xms64m
-Xmx768m
-XX:MaxPermSize=512m
-Dfile.encoding=UTF-8The memory that you can allocate to your Talend Studio depends mostly on your system memory availability. However, the following settings are recommended based on the most usual system memory values.
With 2 GB of memory available on a 32-bit system, bounds can be changed as follows:
-vmargs
-Xms256m
-Xmx1024m
-XX:MaxPermSize=256m
-Dfile.encoding=UTF-8With 8 GB of memory available on a 64-bit system, the optimal settings can be:
-vmargs
-Xms1024m
-Xmx4096m
-XX:MaxPermSize=512m
-Dfile.encoding=UTF-8For Mac systems
For Mac systems, the studio .ini configuration file named TOS_DI-macosx-cocoa.ini is located in TOS_DI-macosx-cocoa.appContentsMacOS directory. The default settings are as below:
--launcher.XXMaxPermSize512m
-vmargs
-Xms64m
-Xmx768m
-Xdock:icon=../Resources/talend.icns
-XstartOnFirstThread
-Dorg.eclipse.swt.internal.carbon.smallFonts
-Dosgi.instance.area.default=../../../workspace
-Dfile.encoding=UTF-8Modify the Java parameters to allocate more memory to Talend Studio, for example, with 8 GB of memory available on a 64-bit system, the optimal settings can be:
--launcher.XXMaxPermSize512m
-vmargs
-Xms2014m
-Xmx4096m
-Xdock:icon=../Resources/talend.icns
-XstartOnFirstThread
-Dorg.eclipse.swt.internal.carbon.smallFonts
-Dosgi.instance.area.default=../../../workspace
-Dfile.encoding=UTF-8Reducing lookup data
The tMap lookup data is by default stored in memory, so large lookups will consume large amounts of memory. Wherever possible, ensure the following:
- You only keep columns in a lookup that you need within the tMap. Drop all other columns prior to the tMap.
- You only keep rows that you need; filter out any extraneous or duplicate rows prior to the tMap.
This should be best practice for any lookup, regardless of size, but for large lookups, the removal of just a couple of columns for every row can sometimes reduce the memory requirement significantly.
Using hashMap/in-memory tables
If you need to read the same lookup data multiple times in a job, then it is wise to load only one copy of the data into either a tHashOutput component or an in-memory table at the start of the job, and then read the lookups directly from the in-memory constructs.
This technique will also ensure that your job start-up time is lower since there will be no requirement to load multiple versions of the same data from a file or a database.
Splitting the job
You may also consider splitting the job into multiple jobs, assuming that the process can be split. This enables the memory to be freed at the end of each job, meaning that each individual job can have access to the whole of the memory available.
Be aware that this method will require one or more temporary tables to be created to hold the data between jobs.
Dropping data to disk
The tMap does allow the option to dump lookup data to disk. This method is useful when you have one or more large lookups that take up more memory than the input data would. First, you need to define the properties for the files. The tMap configurations options allow you to define a folder and the size of the temporary files that will be stored, as shown in the next screenshot:
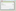
- Note that if you choose not to do this, Talend will write to a default folder.
- Next, select the lookups that you wish to drop to disk, as shown in the next screenshot:
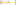
When Talend executes a tMap where this method is used it will write the lookups to disk, and then read the input data into memory prior to processing.
If you choose to use this method, then you must ensure that the input data to be processed takes less memory than the lookup, and you should also be aware that the order of the input records is not maintained.
Split the files
If the disk method would struggle because the input is too large, then you could consider using the same method but splitting the input into a number of files and processing them individually.
While this may affect your processing time, it will stop you from running out of memory.
Hardware solutions
As a last resort, or if an increase in the time to process is not acceptable, then consider adding more memory to your server.
It would also be possible to add additional servers and processing subsets of the input data on different servers at the same time, and then recombining the output data in a final stage.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Talend Training | Jul 25 to Aug 09 | View Details |
| Talend Training | Jul 28 to Aug 12 | View Details |
| Talend Training | Aug 01 to Aug 16 | View Details |
| Talend Training | Aug 04 to Aug 19 | View Details |

Technical Content Writer









