
- A Deep Dive Into Talend ETL
- Talend Interview Questions
- Talend Tutorial
- Talend vs Informatica - What's The Difference?
- Adding and Reading Talend Headers and Trailers - TALEND
- Checking a Column against a list and lookup in Talend
- Common Mistakes And Other Useful Hints And Tips - Talend
- Creating and Adding a Context Group to Your Job - TALEND
- Pseudo Components and Custom Routines in Talend
- Creating Simple, Complex and Random Test in Talend
- How to Create tMap Expressions using tMap Component – Talend
- Creating Validation Rules and Binary Error Codes in Talend
- Talend Database Tutorial
- Filtering and Splitting Input Rows in Talend
- How to Manage Metadata using Talend Schema - TALEND
- Joining Data Using tMap, Hierarchical Joins | Talend
- Locating Compilation and Executing Errors - TALEND
- Managing Talend Context Variables
- Talend Data Validation
- Organizing Talend Files
- Printing out Context and Dumping the Output in Talend
- Processing Multiple and Validation Files – Talend
- Reading from and Writing to a Database Table – Talend
- Returning Codes and Passing Parameters to a Child Job - TALEND
- logical Testing the most used pattern in Talend
- Using Java In Talend
- Java debugger and tJavaRow in Talend
- Using tContextLoad and Implicit Context Loading in Talend
- Using the Ternary Operator, Intermediate Variables and Reload – Talend
- Working with Web Services and Queues - TALEND
- Working with XML - Talend
- Various Talend Products and their Features
Managing Database Sessions
DATABASE SESSIONS allow the developer to control how and when the data is committed to a database. This recipe shows how this is achieved in Talend. Many management options are available for database connections including editing and duplicating the connection or adding a task to it.
The sections below explain in detail these management options.
Getting ready
Open the job jo_cook_ch07_0060_databaseSession.On inspection, you will see that the job has been set up to commit after each record that has been written.
How to do it…
The steps to be performed are as follows:
- Run the job. You will see that it is very slowly adding the records to the database.
- Kill the job. If you inspect the database table testSession, you will see that the records have been added to the database.
- Drag tMysqlConnection from the metadata panel and tMysqlCommit from the palette (note that this isn’t available from the Repository panel) and wire up as shown in the following screenshot:
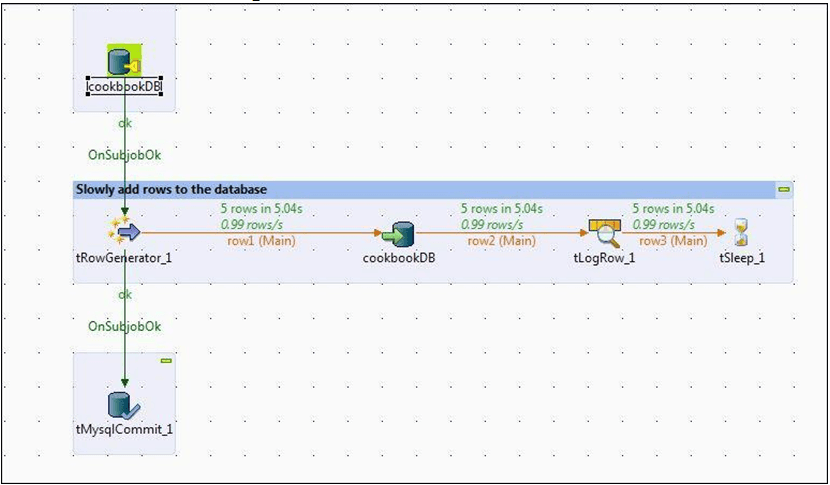
- Open tMysqlOutput and tick the option for Use an existing connection. You will see that all the connection information is now hidden.
- Run the job and Kill it before all ten records have been processed. If you examine the table, you will see that it has no data in it.
- Run the job and allow it to complete. The data have now been written to the table.
How it works…
The tMysqlConnection component establishes a connection and begins a session. When you select Use an existing connection in an output component, it adds the component to the session, thus ensuring that the records written require an explicit commit. The commit component will commit the writes to the database and close the session.
Executions
- The first execution of the job shows how each record is committed as an atomic transaction.
- The second execution shows that records output without a commit will not be added to the database when attached to a connection.
- The final execution shows that all the records are committed as a single transaction.
Multiple outputs
- Multiple output components can be added to a session in order for a transaction to include multiple tables. For example, we may wish to abort the writing of customer and order if the write for an order item fails.
- By ensuring that all three output tables use the same connection, we ensure that they are either committed all together as a single transaction or none are written if any other dependent rows fail.
Don’t forget the commit
A common beginner’s error is to assume that the connection simply shortcuts the need for manually setting up a component, which is true, but it also begins a database session. So, if you do not add a commit component, you will not get any data written to the database.
Committing but not closing
The commit component is automatically set to close a session. If you wish to commit, but keep a session open, then the tMysqlCommit component has an option to enable the session to be kept open after the commit.

Passing a session to a child job
Passing a value from the parent Job to the child Job is a common real-world requirement.
| Related Article: Talend Interview Questions |
Environment
This procedure was written with:
- Talend Open Studio for DI 5.0-r72978
- JDK version: Sun JDK build 1.6.0_26-b03
- Operating system: Windows XP SP3
The following environment was used to create the suggested procedure.
- Data Integration releases: 4.2.3, 5.0, 5.0.2, 5.1.1
Getting ready
Open the Job
jo_cook_ch07_0070_databaseSessionParentwhich is the same as the completed version from the previous recipe, but with the main process replaced with a child job. On inspection, you should see that the child job has a connection set up and it is the same connection as the parent's job.
How to achieve it…
The steps to be performed are as follows:
- Run the job. If you inspect the database table testSessionChild, you will see that no records have been added to the database.
- Open tMysqlConnection in the parent job.
- Tick the box Use or register a shared DB Connection, and set the Shared DB Connection Name to “cookbook”, as shown in the following screenshot:
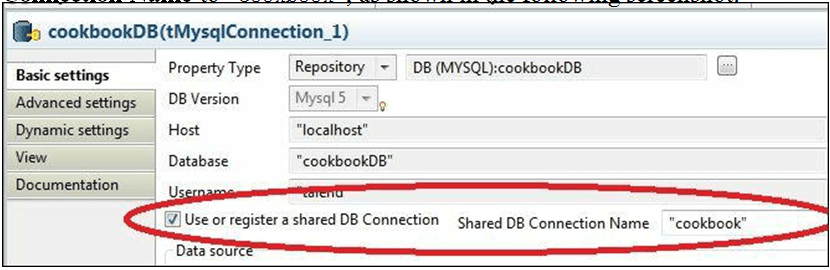
- Repeat the same for the connection in the child job.
- Run the job. When you now inspect the database table testSessionChild, you will see that the records have been added to the database.
How it works…
The tMysqlConnection component establishes a connection and begins a session in the parent job, as does tMysqlConnection in the child job. The problem in this scenario is that they both create individual sessions, so that when we run the parent, no records are committed to the database despite records being written by the child.
When we define a shared connection in the parent of “cookbook”, the session information then becomes available as a session in the child if we choose to use it, and in this example, we do so by using the shared connection registered by the parent.
So the connection for the parent and child are now using the same session and when the commit is executed, the records added by the child are also committed.
Selecting different fields and keys for insert, update, and delete
Many applications will write to/delete from the same table in many different ways, using different fields as keys and often updating different fields at different times. This recipe shows how this can be achieved without having to create new schemas each time.
| Related Article: Talend Database Tutorial |
Getting ready
Open the job jo_cook_ch07_0080_fieldSelection.How to achieve it…
The steps to be performed are as follows:
- Open the tMysqlOutput component and change the field Action on data from Insert to Insert or update.
- Now click on the Advanced settings.
- Tick the box, Use field options to reveal the Field Options. You should see that all the fields are set as Insertable and Updatable.
- Uncheck createdDate and createdBy in the column Updatable.
- Uncheck updatedDate and updatedBy in the column Insertable.
- Finally, check the Update Key column for the column id. Your Field options should now look as shown in the following screenshot:
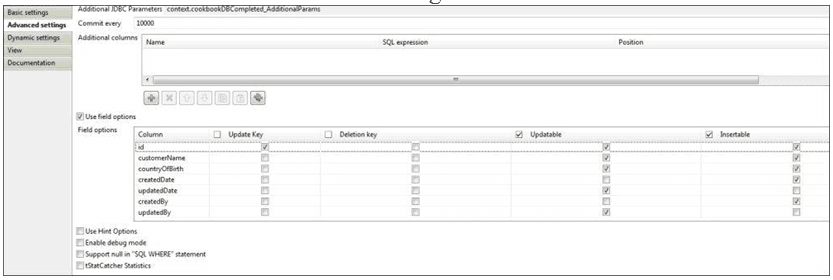
- Run the job and inspect the table. You will see that the record has been created and that the updatedDate and updatedBy fields are blank.
- Open tFixedFlowInput, and remove the values for insertedDate and insertedBy.
- Add a value to updatedDate of parseDate(“yyyy-MM-dd”,”2012-05-22″).
- Add a value of updatedBy of “ZZ”.
- Change the customerName value to “testCustomerNewName“.
- Run the job and inspect the table. You will see that the name has been changed and the updatedDate and updatedBy fields have been written.
How it works…
First, we set the insert method to Insert or update. This allows us to write to new and existing records using the same component.
The first execution is an insert, so that the createdDate and createdBy columns are populated for the record in the table and the updatedDate and updatedBy columns are null.
Any subsequent write to this table for the given key is an update, so this will leave the createdDate fields as they were set when first inserted and now populates the updatedDate and updatedBy columns and the new value of customerName.
There’s more…
This is a great method for ensuring that pre-defined schemas are used within the jobs, thus encouraging re-usability and traceability, and also allows us to update rows using a different set of key values depending upon the data we have at hand.
Updating
Any key may be used to perform an update, not just the primary key for the table, since Talend will be creating a SQL WHERE clause under the covers. You simply need to select the fields that you wish to use as the key in the column, Update key within the Field options section.
Deleting
You should also notice that there is a column in the list of fields for defining the deletion key. The same method applies to deleting rows as for update; however, the column Deletion key should be used instead in the Advanced settings tab and the Action on data set to Delete in the Basic settings.
Capturing Individual Rejects and Errors
Many database applications require a log of rejects and errors to be kept to enable erroneous records to be identified, so that manual repairs can take place. This recipe shows how to capture errors for individual rows using the reject row facility.
Getting ready
Open the job jo_cook_ch07_0090_rejectsAndErrors.How to achieve it…
The steps to be performed are as follows:
- Copy the customer table from metadata and create a tMysqlOutput
- Change the Table to “customer_reject_test”, and change Action on table to Drop table if exists and create.
- Right-click the tMysqlOutput component and you will see that the only Row option is Main.
- Run the job. You will see that there are errors in the console and that the table is empty.
- Open tMysqlOutput, and click on Advanced settings.
- Right-click on the tMysqlOutput component and you will now see a flow labeled Rejects.
- Send this flow to a tLogRow component which has Mode set to Vertical.
- Run the job. You will now see a reject row printed in the console with a duplicate key error.
- You should also see that, apart from the reject row, the rest of the input rows have been written to the database.
How it works…
- In its default mode, tMysqlOutput is inserting in bulk mode known as extended insert. This allows many rows to be written as a single SQL statement.
- Our data contains a problem row and this means that when we try to insert this row, it is rejected along with all of the rows in the same group.
- When batch insert methods are turned off, the tMysqlOutput component will allow a Reject flow to be created. Like other Reject flows in Talend, it contains a copy of the input record plus a reason for rejection.
- Thus, when we first examine the row output from tMysqlOutput, we could only see the Main row. After turning off the Extend Insert option, we were then allowed to connect a rejects flow.
- With the bulk insert option turned off, we can now reject individual rows, so the second execution of the job completes successfully, the valid records are written to the table and the rejects are captured and printed in the console.
There’s more…
There are some more points to take a glance:
Die on error
In addition to having any bulk insert methods deactivated, the option to Die on error must also be deactivated in order for rejects to be captured using this method.
Efficiency
The ability to reject rows without killing the job is incredibly useful and does make for simpler code and error management, but does come at a cost; namely, the rows must be inserted one at a time.
Inserting rows one at a time is nowhere near as efficient as using bulk insertion methods or by specifying block sizes, so you may find that for some databases there is a trade-off between loading speeds and error reporting and management.
Error management
Having individual rows being rejected makes fixing a problem much simpler since we have a one-to-one match between the error for a single reject row.
In contrast, the use of batch insert methods, such as the MySQL extended insert method will return one error but reject a whole batch of rows, both good and bad.
So this gives us slightly more of a headache, as when one row fails, the whole batch is rejected, giving us a situation of having good and bad records in a batch of rejects, which in turn forces us to create more complex methods of fixing them for a single reject.
Database and table management
This simple recipe shows how to execute database management and table-related commands.
Getting ready
Create a new job jo_cook_ch07_0100_tableManagement.How to do it…
The steps to be performed are as follows:
- Drag the cookbookDB connection onto the canvas and select the component tMysqlRow.
- In the Query area add the following code:
"
CREATE TABLE `test_mysqlrow` ( `id` int(11) NOT NULL,
`data` varchar(45) DEFAULT NULL, PRIMARY KEY (`id`)
)
"- Run the job, and you will see that the table testMysqlRow has been created.
How it works…
The tMysqlRow component is the database equivalent of both tJava and tJavaRow, it can be used within a flow like tJavaRow or standalone like tJava.
That said, the tMysqlRow component is most commonly used standalone, like tJava, as in this case, where we create a table.
There’s more…
This simple example shows a single, isolated use of tMysqlRow. On most occasions, it is used prior to processing to create temporary tables or to drop constraints or indexes prior to bulk loading, and also after processing to remove temporary tables and restore constraints or indexes.
Note
tMysqlRow can also be used on a row-by-row basis to perform say inserts, but this is usually simpler to do, using tMySQLOutput.
Managing surrogate keys for parent and child tables
Many application databases will use surrogate keys as a means of uniquely identifying rows in a table. As a result of this, it is often necessary to capture the surrogate key for the record after writing a record, so that any associated child elements will be able to reference the parent’s surrogate as a foreign key. This recipe shows one method of creating surrogate keys in a relation and later discusses a few more methods.
Getting ready
Open the job jo_cook_ch07_0110_surrogateKeys.How to achieve it…
The steps to be performed are as follows:
- Open the tMysqlInput component labeled globalCustomer, and add the following query:
"
SELECT COALESCE(MAX(customerId),0) FROM globalCustomer
"- Open tJavaRow_1, and add the following code:
globalMap.put("maxCustomerId",input_row.maxCustomerId);
System.out.println("Max customer id = "
+ globalMap.get("maxCustomerId"));- Open tMap_1, and add the following code into the Expression field for customerId:
Numeric.sequence("customer",((Integer)
globalMap.get("maxCustomerId"))+1,1)- Open tMap_2, and add the customerURN and source as join keys for the globalCustomer lookup.
- Add the following code into the Expression field for the orderId:
Numeric.sequence("order",((Integer)
globalMap.get("maxOrderId"))+1,1)- tMap_2 should now look like the following screenshot:
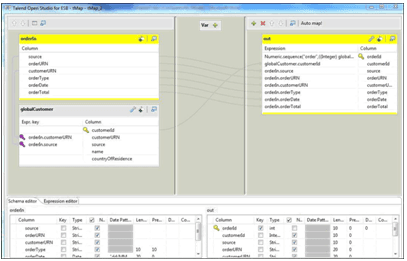
- Run the job. You will see that the customer and order records have been added, the surrogate keys have been generated correctly, and foreign key references between customer and order are correct.
How it works…
The unique keys are created through the following two stages:
The first stage is performed in tMysqlInput, and that is to capture the maximum value for the key in the customer3NF and order3NF table. These values are then written to the globalMap variables for later use.
Now that we know the highest key value in the customer3NF table, the second stage is to create a sequence that starts at the maximum value plus one and use the result of the sequence as the surrogate key for each input in the customer row.
We then write the customer data to the customer3NF table, then read the order data and in tMap, join to the customer table on the natural key(customerURN and source), so that we can get the customer surrogate for use as the foreign key for the order data.
In tMap, we also generate the order surrogate and then write the completed order row to the database.
There’s more…
The method shown is very efficient for batch processing or data migrations where we can blitz a table at a time. There is one note of caution, we need to be certain that no other job or process is writing to the same table using the same method at the same time. If we cannot be certain, then we should use an alternative method.
Added efficiency using hashMap key table
This method can be made more efficient by not re-reading the globalCustomer table. Provided you have enough memory, it is better to copy the surrogate key (generated) and natural keys (customerURN and source) into a hashMap. This hashMap can then be used as a lookup, avoiding the need to reload the customer table in its entirety from the database, instead of simply reading data already stored in memory.
Ranges
A slight variation in the preceding method is to earmark a range of values prior to writing. This can be achieved by writing a temporary marker record into the table with a key of the current maximum value plus the number of records to be written plus one (or a given range plus one). This means that a second process will start its load at the top of the range, thus avoiding any overlap. Remember, though, to remove the marker record at the end of the writes for the range.
Sequences
Sequences are database objects that will return a unique value every time they are read. To generate surrogate keys, the process simply adds a lookup to the main flow that will select the next sequence value for the table and use the returned lookup.
Note
Note that the lookup must be made to reload at each row to ensure each row gets a value.
This method is good for both real-time and batch updates, however, not all database versions support sequences.
It is slightly less efficient than the Talend generated sequence method, but this method does have the advantage of being usable by many processes at the same time. It is, therefore, the best method to use in real-time/web service-based environment.
Autoincrement keys
Some databases will allow fields that will automatically generate a new one-up number whenever a record is written to the table. If the key field is set as autoincrement, then we do not need to generate a key, we simply need to write the record to a table and the database will do the rest.
This method, however, does have a downside, in that we need to re-read the table using the natural key to find the database-created surrogate.
The LastInsertId component
- A slightly more efficient alternative to re-reading using the natural key is to use the tMysqlLastInsertedId component in the flow.
- This component will automatically add a field to the existing schema and populate it with the most recently written record.
- This component will return the last value for a connection, so be very careful to only write one table at a time for a given database session.
- Also, note that this component is only available for a small subset of databases.
Autoincrement procedure
The final option in this list is to use an auto-increment key field but to write the record to the database via a stored procedure. The procedure can then write the record and capture the last value written. This has the advantage of working with most databases, but the disadvantage of having to maintain a stored procedure/function.
| Related Article: Talend Tutorial for Beginners |
Rewritable Lookups Using an In-Process Database
The tHash components are great for storing intermediate data in memory and are very efficient, but do not allow updates. Database tables allow updates, but aren’t as efficient when writing and reading data on a row-by-row basis, especially when there are large numbers of rows to be processed.
This recipe shows how we can get the best of both worlds using a feature of the HSQL database that allows us to define databases that only reside in memory for the given process.
Getting ready
Open the new job jo_cook_ch07_0120_inProcessDatabase.How to achieve it…
The first thing we need to do is to create a memory copy of the current MySQL country table, by copying the previous execution position from the persistent table in MySQL:
- Drag the table schema countryRef from the connection cookbookDB and select the component tMysqlInput.
- Drag a tHSQLDBOutput component onto the canvas and configure it as shown in the following screenshot:
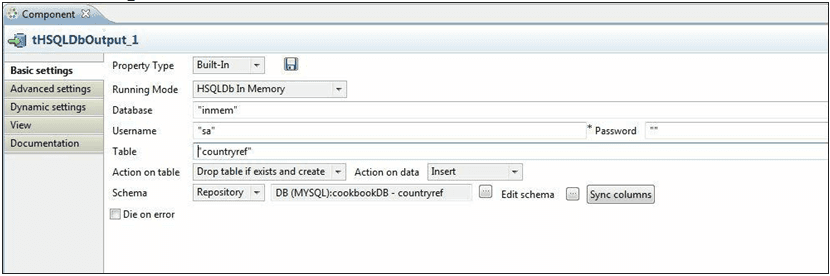
- Connect tMySQLInput to tHSQLDBOutput and execute the code.
- You will see that two rows are copied from the database table into the in-memory table.
Reading and Updating the in-Memory Table
- Uncomment the final section and join to the previous subjob via an OnSubjobOk link as shown in the following screenshot:
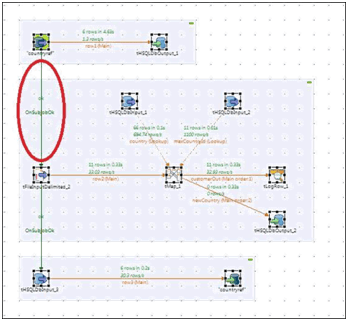
- Run the job.
- You will see that four new rows have been added to the country table and the customer records all have correct country IDs.
How it works…
The key features of the job are as described in the following section.
In-memory components
All of the HSQLDB components are set up in the same way and use the same database (inmem).
Initialize the data
The data is initialized from the persistent copy of the country table.
tMap
There are a few key features to be noted within tMap:
Both the lookups are reloaded at each row. This is to ensure that any in-flight changes are made available immediately after the update.
We have a lookup for the maximum value of the ID in the country table. This is used when we aren’t able to find a country and need a new key, which will be the highest current ID plus one.
So when writing to the output, we either copy the country key (if the country is found) or we copy the ID for a new country record (maximum ID value plus one).
This is achieved using the code:
country.id == null ? maxCountryId.id + 1 : country.id.When a new country is found, then we create the new ID using max ID plus one and write it to the new country flow. This flow is used to insert the new row into the inline table.
Write back
Finally, we need to copy the new version of the table to the persistent country table ready for the next execution.
There’s more…
This method is most useful when you need to refer values in a table, but where those values are likely to change during the course of a single execution.
This example is a fairly typical application of this method and while it is possible to achieve the same results using other techniques, this method is by far the simplest to understand and to implement.
It is also incredibly valuable when large numbers of records are to be processed, which would normally mean large numbers of individual reads in the database, which will be very slow.
If the in-memory table is very large then consider using the reload at each row method with a key as detailed in the recipe Using reload at each row to process real-time/near real-time data, in MAPPING DATA.
| Explore TALEND Sample Resumes! Download & Edit, Get Noticed by Top Employers! |
Memory
As with all memory storage techniques, ensure that you have enough memory to hold all of the reference tables, before and after the execution. Ensuring that you only store the fields that are required in memory that will allow you to fit a large number of records in the memory.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Talend Training | Jul 18 to Aug 02 | View Details |
| Talend Training | Jul 21 to Aug 05 | View Details |
| Talend Training | Jul 25 to Aug 09 | View Details |
| Talend Training | Jul 28 to Aug 12 | View Details |

Ravindra Savaram is a Technical Lead at Mindmajix.com. His passion lies in writing articles on the most popular IT platforms including Machine learning, DevOps, Data Science, Artificial Intelligence, RPA, Deep Learning, and so on. You can stay up to date on all these technologies by following him on LinkedIn and Twitter.









