
- A Deep Dive Into Talend ETL
- Talend Interview Questions
- Talend Tutorial
- Talend vs Informatica - What's The Difference?
- Adding and Reading Talend Headers and Trailers - TALEND
- Checking a Column against a list and lookup in Talend
- Common Mistakes And Other Useful Hints And Tips - Talend
- Creating and Adding a Context Group to Your Job - TALEND
- Pseudo Components and Custom Routines in Talend
- Creating Simple, Complex and Random Test in Talend
- How to Create tMap Expressions using tMap Component – Talend
- Creating Validation Rules and Binary Error Codes in Talend
- Talend Database Tutorial
- Filtering and Splitting Input Rows in Talend
- How to Manage Metadata using Talend Schema - TALEND
- Locating Compilation and Executing Errors - TALEND
- Managing Talend Context Variables
- Talend Data Validation
- Organizing Talend Files
- Printing out Context and Dumping the Output in Talend
- Processing Multiple and Validation Files – Talend
- Reading from and Writing to a Database Table – Talend
- Returning Codes and Passing Parameters to a Child Job - TALEND
- logical Testing the most used pattern in Talend
- Using Java In Talend
- Java debugger and tJavaRow in Talend
- Using tContextLoad and Implicit Context Loading in Talend
- Using the Ternary Operator, Intermediate Variables and Reload – Talend
- Talend – Working with Databases
- Working with Web Services and Queues - TALEND
- Working with XML - Talend
- Various Talend Products and their Features
Joining data using tMap
tMap is more powerful in terms of FUNCTIONALITY
1. tMap can have many outputs links.
2. With tMap we can use the expression on the columns while providing the joining condition.
3. In tMap we have the option to store the intermediate data in the disc.
4. In tMap, we can enable the option to reload the look-up for every record.
5. tMap supports more types of join model, includes unique join, first join, and all join.
6. tMap allows you to link multiple look-up flows into it, and supports to load multiple look-up flows parallel.
7. tMap supports the ‘die on error’ option.
Hence tMap is quite a powerful component. Being a powerful component, it generates more code and it may take more space and time to load in the memory.
If you would like to Enrich your career with a Talend certified professional, then visit Mindmajix - A Global online training platform: “Talend Certification Course” . This course will help you to achieve excellence in this domain.
Getting ready
Open the job jo_cook_ch04_0070_tMapJoin.
How to do it…
- Right-click tFileInputDelimited. Go to Row | Main and connect it to tMap_1. Change the name of the flow to order.
- Open tMap, and you should see two input tables: customer and order.
- Select the customerId field from the customer table and drag it to the customerId Expr. key in the order table.
- You will see a purple key icon and a flow showing the linked fields.
- Type “Card” into the key field for orderType.
- Drag all the order fields apart from customerId to the output. Your tMap should now look like the following screenshot:
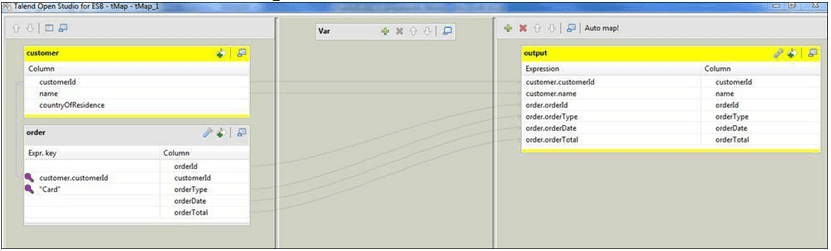
Close tMap and run the job.
- You will see that there is a single row for each customer, and many of the fields are null.
- Re-open the tMap, and click tMap settings for the input flow order.
- Change Match Model to All matches and Join Model to Inner Join.
- Close tMap and run the job. You will see that only the rows that have an orderType of card have output, but there are now multiple records per customer.
- Add a new output to tMap and rename it to notMatched.
- Drag all the customer fields into the new output.
- Click tMap settings, and set Catch lookup inner join reject to true.
- Close tMap and add another tLogRow. Select tLogRow mode of Table (print values in cells of a table).
- Join the notMatched flow from tMap to the new tLogRow and run the job.
- You should now see two tables: one containing all Card transactions for customers and another showing all customers who have no Card transactions.
------ Related Page: A Deep Dive Into Talend ETL ------
How it works…
tMap allows for different join types to be defined using expressions as keys. In this example, we used a variable from the main flow, plus a constant (“Card”) as our join keys.
The first execution of the job performed a left outer join, so all input records are output and non-matched fields are set to null (or a default value if they are Java primitives). In addition, the first execution also specified to use only a unique match, thus printing out only one row per customer.
The second execution, however, specified that we wanted to do an inner join with all matches, so the output contained all orders where the customer paid with a credit card. In the second execution, we also defined a second output that caught all the rows from the main flow that did not have any matches to the lookup.
There’s more…
This recipe illustrates the main features of joining using tMap, but only joins one table to another. It is also possible to join the same table with many other different keys from many lookups in a single tMap.
The next two recipes will show some examples of this:
The lookups are processed slightly earlier than the main flow. Due to the small volumes of data in this recipe, it isn’t apparent, but if you replace the file for tFileInputDelimited_2 with chapter04_jo_0080_orderData_large.csv, then this will become very apparent.
You will see that tMap loads the lookup data into memory tables at the start of the job before it begins processing the main data flow.
For batch data integration jobs, this is an efficient method, since it reduces the lookup time per transaction on the main flow, however, in the recipe USING RELOAD AT EACH ROW to process real-time/near real-time data, we will see how this method is not appropriate for small volume, real-time or near real-time data.
Also, be aware that in order to process large lookups, you will need to ensure that you have enough memory available and allocated to hold all the lookup data. If not, then the process will return out of memory errors.

Hierarchical joins using tMap
tMap has another level of joining capability, in that it can join together data in a hierarchical fashion. This simple example shows how easily this can be achieved using tMap.
Getting ready
Open the job jo_cook_ch04_0080_hierarchicaltMapJoin.
Frequently Asked TALEND Interview Questions & Answers
How to accomplish it…
- Open the tMap. You will see three input tables.
- Select customerId from the customer table and drag it into Expr.key of the customerId in the order table.
- You will see that a join link, a purple key symbol has been added to the column.
- Change the tMap settings for the order table to Inner Join and All Matches
- Now, select orderId from the order table and drag it to orderId in the orderItem table.
- Change the tMap settings for the orderItem table to Inner Join and All Matches. Exit tMap and run the job.
- You should see a printed table containing denormalized customer/order/orderitem rows.
How it works…
This job works on the hierarchy that exists between customer, order, and order item. A customer has many orders and an order has many order items.
The key for orders is the customer, and the key for order items is order. Thus, to get all the order items for a customer, it is necessary to first find the keys for all the orders, and then find all the order items that match the order keys.
As you can see, tMap allows this relationship to be defined easily, simply by dragging the relevant parent key to the child structure.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Talend Training | Jul 21 to Aug 05 | View Details |
| Talend Training | Jul 25 to Aug 09 | View Details |
| Talend Training | Jul 28 to Aug 12 | View Details |
| Talend Training | Aug 01 to Aug 16 | View Details |

Ravindra Savaram is a Technical Lead at Mindmajix.com. His passion lies in writing articles on the most popular IT platforms including Machine learning, DevOps, Data Science, Artificial Intelligence, RPA, Deep Learning, and so on. You can stay up to date on all these technologies by following him on LinkedIn and Twitter.









