
- A Deep Dive Into Talend ETL
- Talend Interview Questions
- Talend Tutorial
- Talend vs Informatica - What's The Difference?
- Adding and Reading Talend Headers and Trailers - TALEND
- Checking a Column against a list and lookup in Talend
- Common Mistakes And Other Useful Hints And Tips - Talend
- Creating and Adding a Context Group to Your Job - TALEND
- Pseudo Components and Custom Routines in Talend
- Creating Simple, Complex and Random Test in Talend
- How to Create tMap Expressions using tMap Component – Talend
- Creating Validation Rules and Binary Error Codes in Talend
- Talend Database Tutorial
- How to Manage Metadata using Talend Schema - TALEND
- Joining Data Using tMap, Hierarchical Joins | Talend
- Locating Compilation and Executing Errors - TALEND
- Managing Talend Context Variables
- Talend Data Validation
- Organizing Talend Files
- Printing out Context and Dumping the Output in Talend
- Processing Multiple and Validation Files – Talend
- Reading from and Writing to a Database Table – Talend
- Returning Codes and Passing Parameters to a Child Job - TALEND
- logical Testing the most used pattern in Talend
- Using Java In Talend
- Java debugger and tJavaRow in Talend
- Using tContextLoad and Implicit Context Loading in Talend
- Using the Ternary Operator, Intermediate Variables and Reload – Talend
- Talend – Working with Databases
- Working with Web Services and Queues - TALEND
- Working with XML - Talend
- Various Talend Products and their Features
Filtering:
Function tFilterRow filters input rows by setting conditions on the selected columns.
Purpose tFilterRow helps parameterizing filters on the source data.
If you would like to Enrich your career with a Talend certified professional, then visit Mindmajix - A Global online training platform: “Talend Certification Course” . This course will help you to achieve excellence in this domain.
Filtering and searching a list of names
The following scenario is a Java Job that uses a simple condition and a regular expression to filter a list of records. This scenario will output two tables: the first will list all Italian records where first names are shorter than six characters; the second will list all rejected records. An error message for each rejected record will be displayed in the same table to explain why such a record has been rejected.
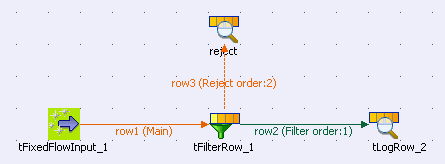
-
Drop tFixedFlowInput, tFilterRow and tLogRow from the Palette onto the design workspace.
-
Connect the tFixedFlowInput to the tFilterRow, using a Row > Main link. Then, connect the tFilterRow to the tLogRow, using a Row > Filter link.
-
Drop tLogRow from the Palette onto the design workspace and rename it as reject. Then, connect the tFilterRow to the reject, using a Row > Reject link.
-
Double-click tFixedFlowInput to display its Basic settings view and define its properties.
-
Select the Use Inline Content(delimited file) option in the Mode area to define the input mode.

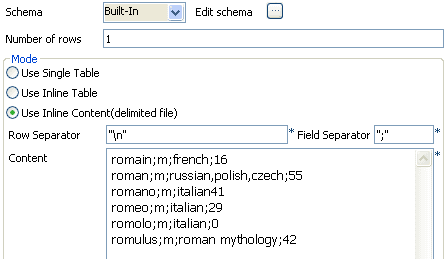
- Set the row and field separators in the corresponding fields. The row separator is a carriage return and the field separator is a semi-colon.
- From the Schema list, select Built-in. The properties and schema are Built-in for this Job. This means, the schema is not stored in the Repository.
- Click the three-dot button next to the Edit schema to define the schema for the input file. In this example, the schema is made of the following four columns: firstname, gender, language and frequency. In the Type column, select String for the first three rows and select Integer for frequency.

- Click OK to validate and close the editor. A dialog box opens and asks you if you want to propagate the schema. Click Yes.
- Type in content in the Content multiline textframe according to the setting in the schema.
- Double-click tFilterRow to display its Basic settings view and define its properties.
.png&w=1200&q=75)
- In the Conditions table, fill in the filtering parameters based on the firstname column.
- In InputColumn, select firstname, in Function, select Length, in Operator, select Lower than.
- In the Value column, type in 6 to filter only first names of length lower than six characters.
Frequently Asked TALEND Interview Questions & Answers
Note
In the Value column, you must type in your values between double quotes for all data types, except for the Integer type, which does not need quotes.
- Then to implement the search on names whose language is italian, select the Use advanced mode check box and type in the following regular expression that includes the name of the column to be searched: input_row.language.equals("italian")
- To combine both conditions (simple and advanced), select And as logical operator for this example.
- In the Basic settings of tLogRow components, select Table (print values in cells of a table) in the Mode area.
- Save your Job and press F6 to execute it.
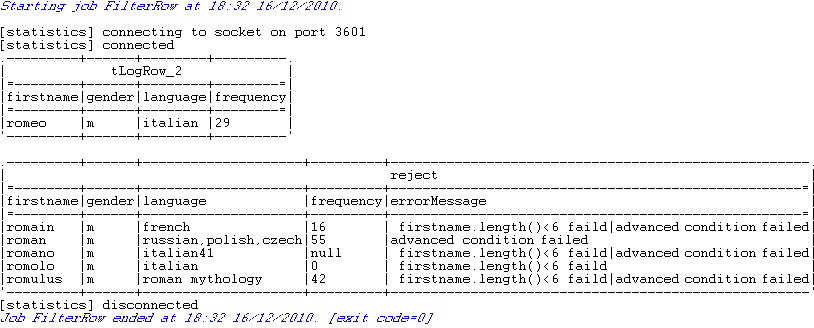
Thus, the first table lists records that have Italian names made up of less than six characters and the second table lists all records that do not match the filter condition “rejected record”. Each rejected record has a corresponding error message that explains the reason of rejection.
------ Check Out Talend Tutorials ------
Splitting an input row into multiple outputs based on input conditions
Often, it is required to filter the input data into multiple outputs depending upon given criteria, for instance, splitting customer data by region, as in this example, or by team. Another very common example is to split the input data into validated records and records that have been rejected due to having failed a quality check (see Checking a column against a list of allowed values, in VALIDATING DATA for examples of using tMap to filter invalid rows).
This recipe shows how the tMap output Expression filters are used to perform filtering of the nature described precedingly.
Getting ready
Open the job jo_cook_ch04_0060_multipleOutputs.
How to achieve it…
- When you open tMap, you will see three identical output tables
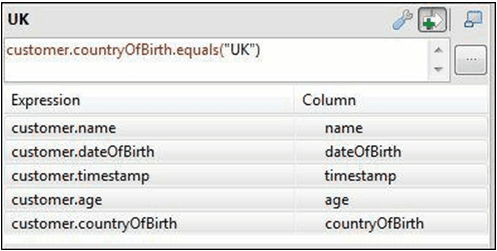
- Click the EXPRESSION FILTER Screenshot_1930 button for the table UK to open, an expression field, as shown in the next screenshot.
- Drag the input column countryOfBirth into this box.
- Add .equals(“UK”) to the end of the expression to give the expression: customer.countryOfBirth.equals(“UK”)
- Your table should now look like the following:
- Repeat the same for the USA table to give the expression:
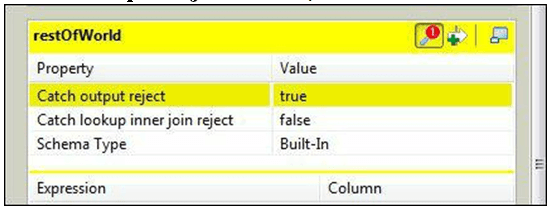
customer.countryOfBirth.equals("USA")- Click the tMapSettings button Screenshot_1925 for the final table, restOfWorld, to open the table properties.
- Set Catch output reject to true, as shown in the following screenshot:
- Exit tMap and run the job to see the results.
How it works…
tMap will pass an input row to the output from the top of the output table list downwards, depending upon their settings.
tMap will only pass data to an output if:
- It has no filter expression and is not a catch output reject
- It has a filter expression and is not a catch output reject the condition is met
- It is a catch output reject with a filter expression and the row has been rejected from previous output and the condition is met
- If it is a catch output reject with no filter expression
It is sometimes easy to think of this list as a set of if-then-else criteria.
Tip
It is recommended that lists of outputs be ordered like if-then-else to make understanding easier. It is also recommended that multiple tMaps be used in the scenario where many outputs are created, depending upon complex conditions. It is not that tMap cannot handle a high level of complexity, rather the impact of changes may be difficult to calculate if there are many inputs, outputs, joins, and conditions.
There’s more…
In this recipe, we have multiple copies of the input being created using input criteria. It is worth noting that the outputs do not need to be copies of each other.
It is also worth noting that if no criteria is specified for any output, then tMap will copy every input row to every output. What’s more is that each of the output can be of a different format and have different rules for the same input row. In this instance, tMap becomes a means of creating multiple different views of the same output data.
What is also possible is that multiple outputs can be specified with catch output reject specified. This means that multiple views of rejected data can also be created.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Talend Training | Jul 21 to Aug 05 | View Details |
| Talend Training | Jul 25 to Aug 09 | View Details |
| Talend Training | Jul 28 to Aug 12 | View Details |
| Talend Training | Aug 01 to Aug 16 | View Details |

Ravindra Savaram is a Technical Lead at Mindmajix.com. His passion lies in writing articles on the most popular IT platforms including Machine learning, DevOps, Data Science, Artificial Intelligence, RPA, Deep Learning, and so on. You can stay up to date on all these technologies by following him on LinkedIn and Twitter.









