- Home
- Blog
- AI and Machine Learning
- Top Artificial Intelligence Technologies 2026

- Challenges Faced While Executing Real Life Scenarios With AI
- What is ACUMOS AI
- Artificial Intelligence Interview Questions
- Artificial Intelligence In Education
- Artificial Intelligence Revolution
- What Is Artificial Neural Network And How It Works?
- Benefits of Artificial Intelligence
- Genetic Algorithm in Artificial Intelligence
- Artificial Intelligence Neural Network
- Top 5 Reasons why you should learn Artificial Intelligence
- Skill Demands in Artificial Intelligence Job Market
- Whats new in SQL Server 2016
- Why is Artificial Intelligence Important
- The Ultimate Guide to Chatbots
- AI Framework
- Artificial Intelligence Tutorial
- Machine Learning (ML) Frameworks
- What is LSTM?
- Best Software Development Courses
- What is Cognitive Computing and How Does it Work?
- What is AIOps - The Beginner's Guide
- What Is ChatGPT
- Artificial Intelligence (AI) Projects and Use Cases
- How to Install TensorFlow?
- n8n Tutorial
- Highest Paying Tech Jobs
Artificial intelligence has undeniably become a part of every sphere of life. In recent years, breakthroughs have been happening in the AI domain, particularly in Agentic AI, multimodal AI, and the Agentic Internet.
Whether you are a software developer, content developer, or technology enthusiast, knowing the top AI technologies is crucial to advancing your career.
This article breaks down the top 10 AI technologies in 2026 that are redefining how individuals and industries work today.
Table of contents
- Artificial Intelligence – An Overview
- How does AI Work?
- History of AI
- Top Artificial Intelligence Technologies in 2026
- Advantages and Disadvantages of AI
- Frequently Asked Questions
Artificial Intelligence – An Overview
The term Artificial Intelligence was first coined in 1956 at a conference. The term Artificial Intelligence has been around for more than 50 years. Over the last 20 years, developments in the domain have been a roller coaster.
In simple words, Artificial Intelligence is the imitation of human intelligence. It enables AI machines to make decisions without human intervention. Apart from solving complex mathematical calculations, AI-powered computers can recognize patterns in data, derive insights, create new content, and much more.
How does AI Work?
AI processes vast amounts of data using complex algorithms to recognize patterns and make decisions. AI relies on Machine Learning (ML) algorithms that learn from data to perform complex tasks. The algorithms use mathematical models to analyze data, extract features, and make predictions or classifications.
For example, if you buy 10 products on a particular day, this transaction data is fed into AI machines for analysis. After understanding your interests and purchase behavior, the machines can predict what products you will likely buy most of the time.
Next, let us look at the history of AI and how this process came into play.
History of AI
The evolution of AI spans several decades. The timeline is given below:
- Year 1956 – The term "Artificial Intelligence" was coined at the Dartmouth Conference. This marked the official birth of AI as a field of study.
- From 1957 to 1966 – The first AI program, Logic Theorist, was created by Allen Newell and Herbert A. Simon. Expert systems were also introduced to mimic human decision-making. Then, ELIZA, an early natural language processing program, was developed by Joseph Weizenbaum.
- Year 1970 – AI experienced a downfall. It was called the "AI Winter" as funding and interest declined due to unmet expectations.
- Year 1980s – The resurgence of AI research, marked by the development of expert systems and symbolic AI, began.
- Year 1997– IBM's Deep Blue defeated world chess champion, Garry Kasparov. This showed that AI can perform strong strategic decision-making.
- From 2000 to 2010 – Machine Learning and statistical AI approaches emerged. Speech recognition and computer vision technologies became mainstream.
Also, the emergence of deep learning and neural networks has boosted natural language processing, image recognition, and autonomous vehicles. - Year 2011 – IBM’s Watson was developed. It defeated two former champions on the game show Jeopardy.
- Year 2020 – Major advancements occurred in AI, particularly in generative AI and computer vision. The COVID-19 pandemic fueled the adoption of AI in healthcare diagnostics, remote collaboration, and supply chain optimization.
- From 2021 to 2022 – Large Language Models (LLMs) played a crucial role with the introduction of ChatGPT. AI-powered content generation and code generation became popular during this period.
- Year 2023 – Multimodal AI was introduced. Organizations increasingly use AI in customer service, software development, healthcare, and more.
- Year 2024 – This year marked the rise of Agentic AI. Organizations have begun using AI agents to analyze documents, automate workflows, and enhance productivity.
- Year 2025 – A major shift occurred from LLMs to SLMs (Small Language Models). It enabled organizations to use AI power on edge devices. Simultaneously, organizations have widely started using AI agents to complete multi-step tasks.
- Year 2026 – The AI Agent Internet represents the next generation of AI development. This technology enables AI agents to autonomously collaborate with various resources.
| If you would like to become a Artificial Intelligence certified professional, then visit Mindmajix - A Global online training platform: “Artificial Intelligence Certification Course”. This course will help you to achieve excellence in this domain. |
Next, we’ll move on to the latest AI technologies, which have evolved over many decades.
Top Artificial Intelligence Technologies in 2026
We’ll discuss the top AI technologies in this section one by one. Let’s get ready!
1. AI Agent Internet
The Agent Internet is the latest major shift in the development of AI technologies. With this technology, you can develop AI agents that autonomously interact with websites, APIs, applications, and other AI agents.
Importantly, these agents connect with other resources over the internet to complete the given task. For example, you can use this AI technology to book services, shop, schedule meetings, and more autonomously.
Related Topic - Top 10 OSINT Tools You Should Know
2. Small Language Models (SLMs)
SLMs are AI language models that can easily process from millions to a few billion parameters. They consume less computing power and memory. So you can use this type of AI system on edge devices.
These models have low latency so that you can get quick responses to your prompts. The Microsoft Phi family, Google Gemma family, IBM Granite small models, and Alibaba Cloud Qwen small models are examples of SLMs.

3. Agentic AI
Agentic AI is the most recent development in AI technology. Agentic AI systems can plan actions, access data sources, use tools, and make decisions autonomously without much human intervention. They can even execute multi-step tasks effortlessly.
You can use agentic AI systems to complete goal-based tasks more easily. It breaks down large problems into small tasks and identifies the suitable sequence of actions.
Agentic AI is increasingly used to automate complex workflows, streamline customer service, orchestrate business processes, and more.
4. Multimodal AI
Multimodal AI models can process different types of inputs, such as text, images, audio, and video. They can generate multiple types of outputs.
For example, a multimodal model can read an image and describe the image in text. Similarly, it can create an image from a text description.
Furthermore, speech recognition is a key aspect of multimodal AI. It converts human speech into an understandable format for computers. You can translate human speech into several languages by using speech recognition.
Speech recognition is increasingly being integrated into various applications and devices, including smartphones, smart speakers, automotive systems, and healthcare solutions. Siri on the iPhone is a classic example of speech recognition.
5. Generative AI
Generative AI is yet another recent key development in AI technologies. You can use this technology to create new content, including images, text, audio, video, code, and more. ChatGPT, Gemini, and Claude are well-known generative AI tools.
You can train Generative AI models on massive amounts of data using Large Language Models (LLMs). It helps them learn patterns and relationships across datasets more accurately and create new content that didn’t exist before.
The great thing about GenAI is that you can use natural language prompts to generate new content. It is widely used in content development, code generation, image design, video creation, and more.
6. AI Governance
AI Governance is a framework of policies, processes, standards, and controls. It ensures the responsible, ethical, and secure use of AI systems. It plays a key role in reducing risks such as bias, privacy violations, and other threats and increasing trust in AI systems.
AI Governance is crucial for organizations to ensure accountability, transparency, privacy, security, and reliability.
For More Info: Machine learning vs Artificial Intelligence
7. Edge AI
You can deploy Edge AI models on edge devices such as smartphones, IoT sensors, cameras, drones, and more. Edge AI plays a key role in real-time decision-making. That’s why it is widely used in autonomous vehicles, smart manufacturing, healthcare monitoring devices, and more.
Edge AI offers many benefits to users, including low latency, improved privacy, and reduced bandwidth usage. It also enhances the security of devices distributed across different places.
8. Natural Language Generation
Natural Language Generation (NLG) is similar to Generative AI technology in that it converts structured data into natural language. For example, you can generate text in natural language or speech from structured data.
You can generate reports, summaries, and conversations using NLG. Content creators can automate content development and deliver it in their desired format. They can use this content to promote across social media and other digital platforms to reach the target audience.
9. Virtual Agents
A virtual agent is a computer application that interacts with humans. Web and mobile applications use chatbots as customer service agents to interact with users and answer their queries.
For example, Google Assistant is a virtual agent that you can use to organize meetings. Likewise, Alexa from Amazon helps make your shopping easier.
Virtual assistants can also act as language assistants. IBM Watson can understand customer service queries expressed in multiple ways. Besides, Virtual agents operate as Software-as-a-Service (SaaS).
10. Decision Management
Many organizations leverage decision management systems to convert data into predictive insights and models. They use AI to access up-to-date information, analyze data, and automate data-driven decision-making.
Decision management helps avoid risks and automate business processes. Financial, healthcare, trading, insurance, and e-commerce sectors widely use this technology.
11. Biometrics
Biometrics in AI uses human biological characteristics to authenticate individuals. For example, it captures and processes fingerprints, facial features, iris patterns, voiceprints, and even human gait.
You can use sensors or devices to gather data, which is processed using AI algorithms. These algorithms extract distinctive features from the data and convert them into biometric signatures.
12. Deep Learning
Deep Learning (DL) is another branch of AI that functions based on Artificial Neural Networks (ANNs). The term “deep” refers to the presence of multiple hidden layers in neural networks. Modern neural networks can have hundreds of hidden layers.
DL models can process large amounts of data. The algorithms work in a hierarchy to automate predictive analytics. Deep learning is used to detect objects from satellites, ensure worker safety, detect cancer cells, and more.
13. Machine Learning
Machine Learning is a branch of AI that enables machines to learn from datasets. This AI technology helps organizations to make informed decisions with data analytics performed using algorithms and statistical models.
For example, the banking and financial sector uses ML models to analyze customer data. It helps them to identify investment opportunities, prevent fraud and financial risks, and more. Further, retailers use ML techniques to predict changes in customer preferences and behavior by analyzing their data.
14. Robotic Process Automation
Robotic Process Automation (RPA) is a subset of AI that enables a robot to interpret, communicate, and analyze data. It helps automate repetitive, rule-based operations. For example, you can automate tasks like data entry, form filling, and routine data manipulation.
RPA typically records the steps required to complete these tasks, creating a "robotic script." You can create the scripts using drag-and-drop interfaces or scripting languages. Even non-technical users can automate processes without any programming expertise.
15. AI-optimized Hardware
A conventional chip cannot support artificial intelligence models. A new generation of AI chips is being developed for Neural Networks, Deep Learning, and Computer Vision.
Active Learning (AL) based hardware includes CPUs for scalable workloads, special-purpose AI accelerators, and custom silicon for neural networks, neuromorphic chips, etc.
Organizations like Nvidia, Qualcomm, and AMD are developing chips capable of performing complex AI calculations. The healthcare and automotive industries use these chips widely.
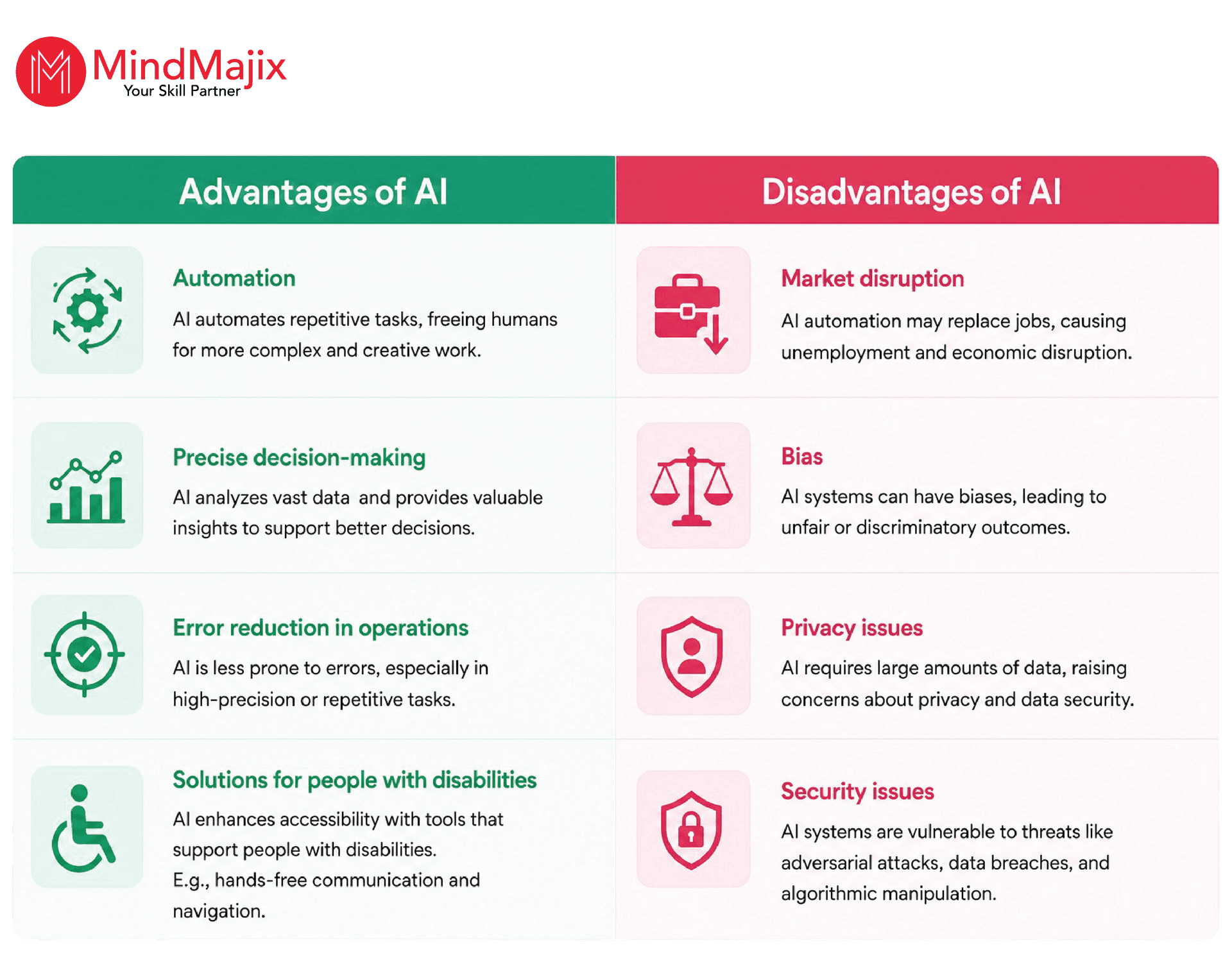
Advantages and Disadvantages of AI
The image below lists the advantages and disadvantages of AI.
Frequently Asked Questions
1. Is learning AI easy for beginners?
Yes, beginners can learn AI easily. You can start learning AI without coding expertise. Many AI tools use natural language prompts only rather than programming. However, enhancing your understanding of Python, neural networks, algebra, and statistical concepts will help accelerate your learning.
2. What is Agentic AI?
Agentic AI is a branch of artificial intelligence that uses AI agents to plan, execute tasks, and make decisions to achieve specific goals with minimal human intervention. These AI agents can break complex problems into smaller tasks, use tools and applications, and adjust their actions to solve them.
3. What’s the difference between Generative AI and Traditional AI?
Traditional AI primarily classifies data and makes predictions by analyzing data. It focuses on data recognition, insights, and accurate decision-making. Spam detection and fraud detection are some examples of traditional AI.
On the other hand, Generative AI can generate new content that has never existed before. It focuses specifically on content creation. Chatbots, image generators, and coding assistants are some examples of generative AI.
4. What is Reinforcement Learning?
Reinforcement Learning is a type of machine learning where an agent learns to make decisions by interacting with an environment. It does this by receiving feedback in the form of rewards or penalties. Through trial and error, the agent learns optimal strategies to maximize cumulative rewards over time.
5. What are the 4 types of AI technology?
The four types of AI are Reactive Machines, Limited Memory AI, Theory of Mind AI, and Self-Aware AI.
- Reactive Machines depend on predefined rules and inputs.
- Limited Memory AI involves learning from past experiences and adjusting its behavior accordingly.
- Theory of Mind AI can understand and interpret human emotions.
- Self-Aware AI refers to hypothetical machines that understand their own existence, reason about complex concepts, and exhibit self-awareness.
6. What are the most commonly used machine learning algorithms?
Linear regression, decision trees, neural networks, and support vector machines are some commonly used ML algorithms.
7. How do neural networks work?
Neural networks consist of interconnected nodes organized into layers. They process input signals, perform computations, and generate output signals. They recognize patterns, uncover insights, and make predictions.
Conclusion
Now that you have learned about leading AI technologies, how they work, their history, and their pros and cons. It’s time to gain mastery of an AI tool, since every business sector is rapidly adopting AI technology.
If you want to learn any AI technology, you can step into MindMajix, where you can find a suitable course and become an industry-ready AI professional.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Artificial Intelligence Course | Aug 04 to Aug 19 | View Details |
| Artificial Intelligence Course | Aug 08 to Aug 23 | View Details |
| Artificial Intelligence Course | Aug 11 to Aug 26 | View Details |
| Artificial Intelligence Course | Aug 15 to Aug 30 | View Details |

Madhavi Gundavajyala is a Content contributor at Mindmajix.com. She is passionate about writing articles and blogs on trending technologies, project management topics. She is well-versed on AI & Machine Learning, Big data, IoT, Blockchain, STLC, Java, Python, Apache technologies, Databases.



