- Home
- Blog
- AI and Machine Learning
- What is LSTM?

- Challenges Faced While Executing Real Life Scenarios With AI
- What is ACUMOS AI
- Artificial Intelligence Interview Questions
- Artificial Intelligence In Education
- Artificial Intelligence Revolution
- Top Artificial Intelligence Technologies 2026
- What Is Artificial Neural Network And How It Works?
- Benefits of Artificial Intelligence
- Genetic Algorithm in Artificial Intelligence
- Artificial Intelligence Neural Network
- Top 5 Reasons why you should learn Artificial Intelligence
- Skill Demands in Artificial Intelligence Job Market
- Whats new in SQL Server 2016
- Why is Artificial Intelligence Important
- The Ultimate Guide to Chatbots
- AI Framework
- Artificial Intelligence Tutorial
- Machine Learning (ML) Frameworks
- Best Software Development Courses
- What is Cognitive Computing and How Does it Work?
- What is AIOps - The Beginner's Guide
- What Is ChatGPT
- Artificial Intelligence (AI) Projects and Use Cases
- How to Install TensorFlow?
- n8n Tutorial
LSTM stands for Long Short-Term Memory and is a type of Recurrent Neural Network (RNN). Importantly, Sepp Hochreiter and Jurgen Schmidhuber, computer scientists, invented LSTM in 1997.
Know that neural networks are the backbone of Artificial Intelligence applications. Feed-forward neural networks are one of the neural network types. When processing time-series or sequential data, the feed-forward neural networks cannot derive better results. This is because feed-forward networks cannot store data. But at the same time, storing data is highly essential to handle sequential data.
We can use Recurrent Neural Networks (RNNs) to overcome the setback of feed-forward networks because RNNs are built with feedback loops. Generally, feedback loops remember information, which eases neural networks to process sequential data.
Again, when it comes to RNNs, they are not efficient in managing long-term dependencies in memory. LSTM is the type of RNN that helps to overcome this setback of RNNs and efficiently processes the sequential data by effectively managing long-term dependencies.
This blog will provide insightful content on RNNs, long-term dependencies, LSTM working, its architectures, LSTM applications, and much more
| Table of Contents: What is LSTM? |
What are RNNs?
As you know, RNNs are the type of Artificial Neural Networks that consists of feedback loops. RNNs effectively process sequential data and predicts the following scenario. RNNs have multiple neural networks or modules connected in their basic form. Each module in an RNN has a single ‘tanh’ layer.
When it comes to training data, RNNs, Feed Forward as well as Convolutional Neural Networks (CNN) function similarly. But at the same time, they differ at one point – memory. Unlike CNN and Feed-forward NNs, the previous inputs impact the current input and output of RNN.
RNNs are widely used in deep learning, mainly in Natural Language Processing (NLP) and speech recognition.
| If you want to enrich your career and become a professional in Artificial Intelligence, then enroll in the "Artificial Intelligence Online Course". This course will help you to achieve excellence in this domain. |
Problem with RNNs - Long-term Dependency
Although RNNs come with feedback loops to remember information, they are inefficient in learning long-term dependencies. This is because RNNs face gradient vanishing and gradient exploding problems. Gradients are nothing but errors that occur while training input data. The gradients drive the weighs of RNNs to become either too small or big
Gradient vanishing doesn’t allow RNNs to learn from training data, mainly when the data is too complex. When gradients explode, the network becomes unstable and loses the ability to learn from the training data.
Simply put, RNNs can process only close temporal events. If you want to process distant temporal events or long-term dependencies, you need neural networks with long-term memory cells.
Thanks to LSTM since it is the type of RNN that helps to learn long-term dependencies like no other neural network.

What is LSTM?
Know that LSTM is hugely used in deep learning. Like any other RNN, LSTM has a chain structure with feedback loops. But, it is essential to note that LSTM is specifically designed to learn long-term dependencies. If the current state of the neural network requires data that is not in the recent memory, then LSTM can learn the data from the past memory. That's why LSTM networks are usually used to learn, process, and segregate sequential data. For example, it is widely used in speech recognition, machine translation, language modeling, sentiment analysis, video analysis, and many more.
The main thing about LSTM is that it has persistent memory. This is because LSTM uses additional gates to learn long-term dependencies. The gates control the flow of information in the memory modules of neural networks.
LSTM can remember data for long periods because of its remembering capacity. It identifies the data that is important and remembered for the long term from the incoming data. Then, it loops back the important data into the neural networks. At the same time, LSTM eliminates the unimportant data from the incoming data.
Still, wondering what LSTM is? The following example will help you to understand LSTM clearly. Consider the following sentences.
Mary is allergic to nuts. She can’t eat peanut Cake.
Assume the first sentence lies many sentences before the second one in the memory of neural networks. It means that the first sentence doesn’t lie in recent memory.
When a typical RNN processes the second sentence of the above information, it is difficult to predict the following scenario since why ‘Mary cannot eat peanut cake' needs to be clarified. This is because RNNs lack long-term dependency.
At the same time, if LSTM processes the above two sentences, RNN quickly makes predictions for the following scenario since it can easily go to the past memory and process the first sentence, and finds why 'Mary cannot eat peanut cake'.
| Related Article: Artificial Intelligence Neural Network |
The Architecture of LSTM
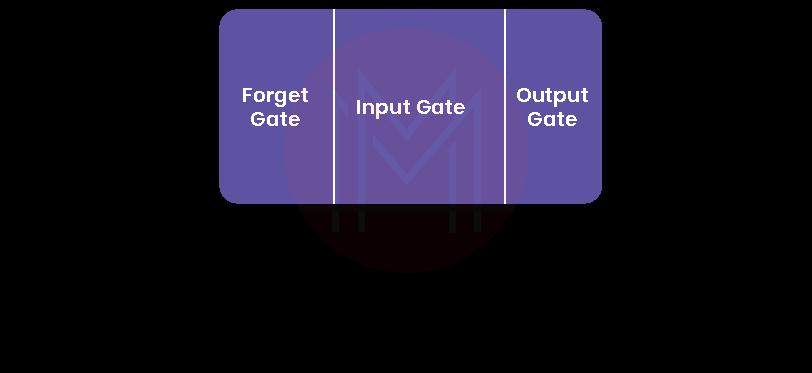
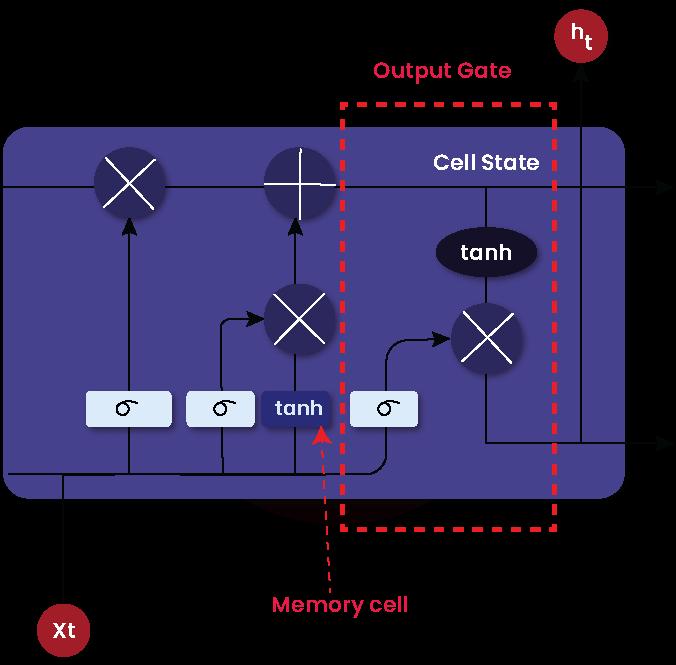
Like typical RNNs, LSTM is built with a hidden layer of memory cells. Every LSTM module in the network will have a memory cell and three gates as follows:
- Forget Gate
- Input Gate
- Output Gate
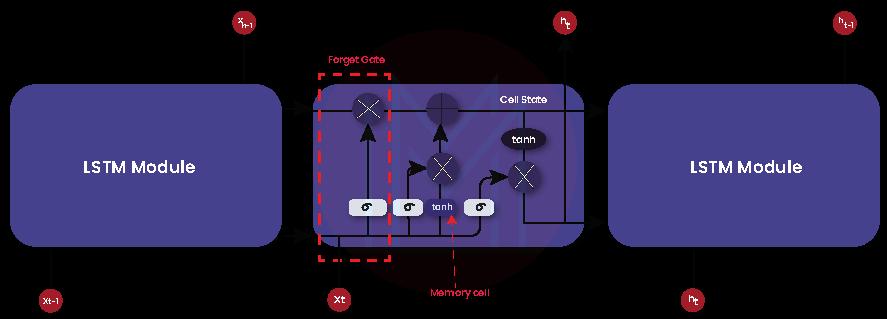
The LSTM module is the backbone of LSTM networks. There is a horizontal line passing through every LSTM module, which is known as the cell state. This cell state is similar to a conveyor belt. This is where gates add data to pass through the module or remove data. It’s no doubt that gates control the flow of information in the network modules and play a pivotal role in predicting the output of the LSTM networks.
Each gate in the LSTM module consists of a pointwise multiplication operation and a sigmoid function. The sigmoid function value varies in-between 0 to 1. The sigmoid function's value controls the information that passes through the gates. When the sigmoid value is 1, input data is passed through the gates. No data is passed through the gates when the sigmoid output is 0.
How does LSTM work?
The memory cell and the three gates play a vital role in the function of LSTM networks.
Let’s discuss the function of gates in the following.
-
Forget Gate
This gate decides whether to allow incoming information into the LSTM modules or remove it. In other words, forget gate decides which information must be passed through the cell state and which information must be removed from the cell state.
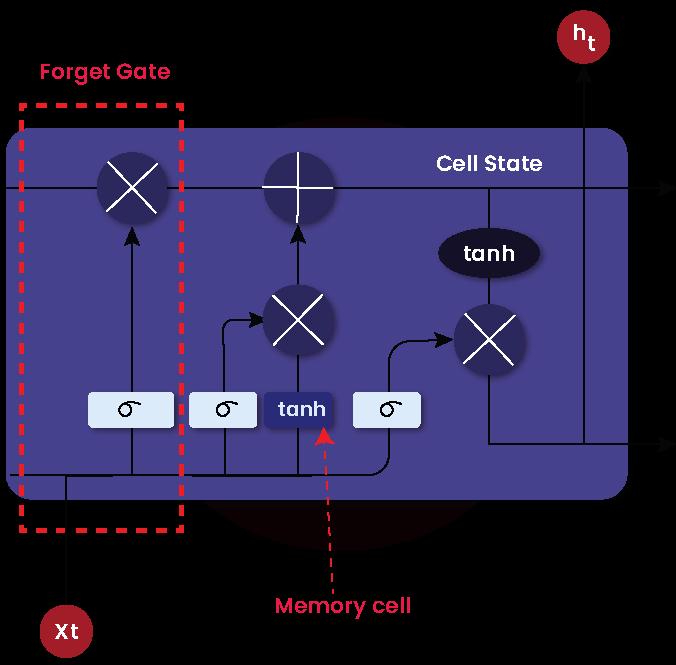
When the output of the forget gate is 1, the input information is ultimately passed through the cell state. On the contrary, if the output is 0, the input information is removed from the cell state. In short, you can modify cell states with the help of this gate.
-
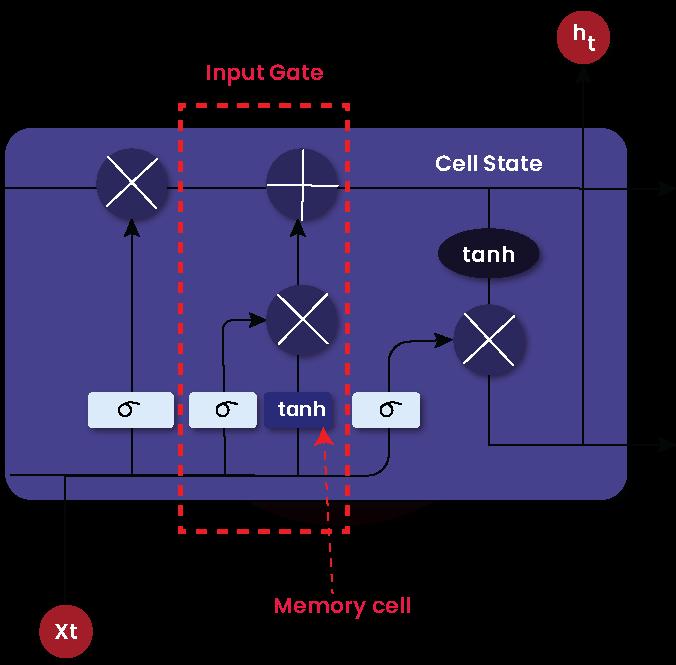
Input Gate
It is also known as the input gate layer. This gate decides whether to allow new information in the cell state and store it in the memory cell. The ‘tanh layer’ associated with this input gate generates new candidate values. So, the output of the sigmoid function and candidate values are multiplied and added to the cell state.
-
Output Gate
The cell state is given through this stage's ‘tanh’ layer. Then it multiplied with the output of the sigmoid function. As a result, the part of the cell state that must be outputted from the LSTM module is decided. This is how the cell state is filtered before releasing the output from this gate. This gate decides which information to flow into the rest of the LSTM networks.
What are the Types of LSTM Networks
There are many types of LSTM networks. Following are a few types of LSTM networks.
Let’s take a brief look at them as follows:
-
Vanilla LSTM
It has a single hidden layer and an output layer in LSTM modules to make predictions.
-
Stacked LSTM
In this type, multiple hidden layers are stacked one on another in the LSTM Modules. In this type, the sequential output of one LSTM hidden layer is passed into the following LSTM hidden layer.
-
CNN LSTM
It is the LSTM model that processes two-dimensional image data efficiently.
-
ConvLSTM
A fully-connected LSTM model has the drawback of redundancy in spatial data. ConvISTM uses a convolution operator to predict the future state of two-dimensional spatial data by reducing the redundancy in spatial data. Each LSTM module in the network can convolute the input data seamlessly.
| Related Article: Why is Artificial Intelligence Important |
What is Bidirectional LSTM?
In a typical LSTM network, input information flows in one direction – either forward or backward. But, in bidirectional LSTM, information can flow in both forward as well as backward directions. The information flows in the backward direction only because of the additional layer in the bidirectional LSTM.
The outputs of both the forward as well as backward layers are combined together through the processes such as sum, multiplication, average, etc. It is undoubtedly a powerful LSTM model that can effectively handle long-term dependencies of sequential data, such as words and phrases in both directions.
For example, consider the following sentence.
Students go to…..; Students come out of school.
A typical LSTM cannot complete the first sentence if it processes the above two sentences. At the same time, if a bidirectional LSTM processes the sentences, it can efficiently complete the first sentence since it can move backward.
Moreover, Bidirectional LSTM is used in text classification, forecasting models, speech recognition, and language processing. It is also used in NLP tasks such as sentence classification, entity recognition, translation, and handwriting recognition.
| Related Article: Artificial Intelligence Tutorial |
LSTM Applications
There are plenty of applications where LSTM is used extensively.
Let’s have a look at them one by one below.
-
Image Captioning
LSTM processes texts in many images and can generate a suitable caption that best describes the images.
-
Language Modeling
In this case, LSTM processes the sequence of words. LSTM language models can process words at the paragraph level, sentence level, or even character level.
-
Music Generation
LSTM can predict musical notes from the sequence of input musical notes.
-
Language Translation
LSTM can map sentences in one language into sentences in another language. Mainly, LSTM encoder-decoder model is used for the same.
What's more! LSTM also has a wide range of applications, such as video classification, video-to-text conversion, speech synthesis, video games, robot control, handwriting recognition, radar target classification, classifying ECG signals, keyword spotting, and many more.
Conclusion
We can conclude that LSTM is one of the recurrent neural networks. LSTM is powerful for processing sequential data such as video, text, speech, and many more. It is widely used in NLP, language translation, image processing, etc. The ability to process data forward and backward in neural networks is one of the vital features of LSTM. As a whole, you can overcome the problem of long-term dependency efficiently with LSTM.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Artificial Intelligence Course | Aug 01 to Aug 16 | View Details |
| Artificial Intelligence Course | Aug 04 to Aug 19 | View Details |
| Artificial Intelligence Course | Aug 08 to Aug 23 | View Details |
| Artificial Intelligence Course | Aug 11 to Aug 26 | View Details |

Madhuri is a Senior Content Creator at MindMajix. She has written about a range of different topics on various technologies, which include, Splunk, Tensorflow, Selenium, and CEH. She spends most of her time researching on technology, and startups. Connect with her via LinkedIn and Twitter .



