
- Apache Hadoop YARN
- Apache Pig Interview Questions
- Benefits Of Cloudera Hadoop Certification
- Hadoop Administration Interview Questions
- Hadoop Ecosystem
- Hadoop HDFS Commands with Examples
- Hadoop Interview Questions
- Hadoop Jobs Salary Trends in the USA
- Mapreduce in Bigdata
- Big Data Hadoop Testing Interview Questions
- Hadoop Tutorial
- Hadoop’s Pig Data Types and Syntax
- Hadoop Apache Pig Execution Types
- Controlling Hadoop Jobs Using Oozie
- HBase Vs RDBMS
- Hadoop Archive Files In HDFS
- HDFS Architecture, Features & How To Access HDFS - Hadoop
- Hadoop Data Types with Examples
- Hadoop – How To Build A Work Flow Using Oozie
- How to Insert Data into Tables from Queries in Hadoop
- Hadoop Hive UDF
- INTRODUCTION TO APACHE PIG – HADOOP
- Introduction to HBase for Hadoop
- What is HDFS?
- Hadoop Job Operations
- Hadoop Mapreduce Architecture Overview
- Apache Sqoop Tutorial
- What Is Hadoop Hive Query Language
- Hadoop Installation and Configuration
- How Much Java Knowledge Is Required To Learn Hadoop?
- Prerequisites for Learning Hadoop
- Top 10 Reasons to Learn Hadoop
- How to Switch Your Career From Java To Hadoop
- Leading Hadoop Vendors in BigData
- What is Apache Pig
- Why Network Security Needs to Have Big Data Analytics?
- Sqoop Interview Questions
- Cloudera vs Hortonworks
- Difference between Pig and Hive
- Big Data Hadoop Interview Questions
- Hive Projects and Use Cases
Data is a profitable asset that helps organizations to understand their customers better and therefore improve performance. To store and analyze data, organizations need a data warehouse system. In this article, we would be discussing Apache Hive, an open-source data warehouse system built on Hadoop.
In this Hadoop Hive article the following topics we will be discussing ahead:
What is Hadoop Hive - Table of Contents
- What is Hadoop Hive
- Hive Architecture
- Meta Store
- Hive Installation
- Hive Vs Traditional Databases
- Hive CLI Options
- Hive Batch Mode Commands
- Commands in the Interactive Shell
What is Hadoop Hive?
- Hive is a component of Hadoop which is built on top of HDFS and is a warehouse kind of system in Hadoop
- Hive will be used for data summarization for Adhoc queering and query language processing
- Hive was first used in Facebook (2007) under ASF i.e. Apache software foundation
- Apache Hive supports the analysis of large datasets that are stored in Hadoop – compatible file systems such as the Amazon s3 file system.
- Hive provides an SQL – like language called Hive QL language while also maintaining full support for MapReduce.
- Hive does not mandate read or write data in the Hive format and there is no such thing
- Hive equally works on. Thrift, control delimited, and also on your specialized data formats.
- Hive is not designed for OLTP workloads and does not offer real-time queries or row-level updates.
- It is best used for batch jobs over large sets of append-only data.
| If you want to enrich your career and become a professional in Hadoop Hive, then enroll in "Hadoop Hive Training". This course will help you to achieve excellence in this domain. |
Hive Architecture
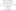
- Driver manager life cycle of Hive QL query moves through Hive and also manages session handle and session statistics.
- Compiler-compiles Hive QL into a directed acyclic graph of map/reduce tasks.
Execution engines: The component executes the tasks in proper dependency order and also interacts with Hadoop.
- Hive server provides a thrift interface and JDBC/ODBC for integrating other applications.
- Client components are CLI, web interface, JDBC/ODBC interface.
- Extensibility interface includes serde, user-defined Function, and also user Defined Aggregate function.
[ Check out Hadoop Data Types with Examples ]
Meta Store
- Meta store is the Hive internal database which will store all the table definitions, column-level information, and partition ID’S.
- By default, Hive uses the derby database as its meta store.
- We can also configure Mysql, Thrift server as the meta stores
- The Meta store is divided into two pieces are the service and the backing store for the data.
- By default, the meta store service runs in the same JVM as the Hive service and contains an embedded Derby database instance backed by the local disk This is called Embedded Meta store configuration.
- Using an embedded meta-store is a simple way to get stored with Hive and however only one embedded Derby database can access the database files on disk at any one time which means you can only have one Hive session open at a time that shares the same meta store.
- The solution to supporting multiple sessions is to use a standalone database and this configuration is referred to as a local meta store, since the meta store service still runs in the same process as the Hive service, but connections to a database running in a separate process, either on the same machine or on any remote machine.
- Mysql is a popular choice for stand-alone meta store
- In this case, JDBC Driver JAR file for Mysql must be on Hive class which is simply archived.

Hive Installation
- Installation of Hive is straightforward and Java 1.6 is a prerequisite.
- If you are installing on Windows, you will need Cygwin too.
- You also need to have the same version of Hadoop installed locally either in standalone or pseudo-distributed mode or where your cluster is running while getting started with Hive.
[ Related Article: Hadoop Installation and Configuration ]
Steps of Hive Installation
Step 1: Download the Hive Release at https://Hive.apche.org/ HTML. i.e. far ball file.
Step 2: Unpack the tarball in a suitable place in your Hadoop Installation environment. i.e $ far – xzvf Hive- 0.8.1 tar.gz
Step 3: Setting the environment variable HIVE-HOME to point the installation directory:
$ cd Hive -0.8.1
$ export HIVE –HOME={{pwd}}
4.Add $ HIVE –HOME/bin to your PATH
$ export PATH=$ HIVE –HOME/bin: $ PATHDatabase Setup
- Install Mysql server with developed and tested versions 5.1.46 and 5.1.48.
- Once you have Mysql up and running, use the Mysql Command line tool to add the Hive user and Hive meta stored database.
- Now, we need to pick a password for your Hive user and replace db password in the following commands with it.
- Log into Mysql.
Cmd:> Mysql
Mysql>create DATABASE meta store;
Mysql>use meta store;
Mysql> SOURCE usr/lib/Hive/scripts/ meta store/upgrade/ Mysql/ Hive-schema-07.0. Mysql. Sql;
Mysql> CREATE USER ‘Hive user’@’%’ IDETIFIED By’ password’;
Mysql> GRANT SELECT ‘INSERT,UPDATE, DELETE ON meta store To’ Hive user’@’%’;
Mysql> REVOKE ALTER,CREATE ON meta store* FROM Hive user’@’%’;To start Mysql services
Cmd:>cd/etc/init.d
>./ Mysql start
To stop:>./ Mysql stop.To start Hive services
Cmd: usr/bin/Hive-service Hive server[ Check out Hadoop HDFS Commands with Examples ]
Configuration of Hive
- Hive is Configured using an XML Configuration file like Hadoop and the file is called ‘Hive-site.xml’
- Hive-site.xml is located in Hive conf directory
- The same directory contains Hive-default.xml which documents the properties that Hive exposes and their default values.
Configure the Hive-site.xml as below
javax.dbo. option. connection URL
jdbc: der by; data base name -/var/lib/Hive/meta store/meta store-db; create=true
JDBC Connect string for a JDBC meta storeHive vs Traditional Databases
- Hive looks very much like a traditional database code with SQL access.
- However, because Hive is based on Hadoop and MapReduce operation, there are several key differences
- In a traditional database, a table’s schema is enforced at data load time.
- If the data being loaded doesn’t conform to the schema, then it is rejected.
- Hive, on the other hand, doesn’t verify the data when it is loaded, but rather when a query is issued.
- Updates, transactions, and indexes are mainstays of traditional databases.
- Yet, until recently, these features have not been considered as a part of Hive’s feature. This is because Hive was built to operate over HDFS data using Map Reduce where full–table scans are the norm and a table update is archived by transforming the data into a new table.
Hive CLI Options
$HIVE-HOME/bin/Hive is a shell utility that can be used to run Hive queries in either interactive or batch mode.
Hive COMMAND LINE Option
- To get help for Hive options, run the command as “Hive-H” or ”Hive– help”
- Command-line options as in Hive 0.9.0.
Hive-d or—define: variable substitution to apply to Hive Commands
Example:– -d A=B or—define A=B
1. hive –e: SQL from the command line.
2. hive-f: SQL from files.
3. hive-connection to Hive server on the remote host
4. —hive conf: use-value for a given property.
5. —hive var: variable substitution to apply to Hive commands.
Example: —hive var A=B.
6. hive-i: initialization SQL file.
7. hive-p: connecting to Hive server on port number.
hive-s—or–silent: silent mode in the interactive shell.
hive-v or—ver bose: verbox mode(echo executed SQL to the console).
- As of Hive 0.10.0, there is one addition command-line option Hive—data box: specify the database to use.
Examples:-
- Example of running a query from the command line:
$HIVE-HOME/bin/Hive-e ’select a.col from tab1- Example of setting Hive configuration variables:
$HIVE-HOME/bin/Hive-e ’select a.col from tab1 a’-Hive conf
Hive. exec. Scrarch dir=/home/my/Hive-Hive conf mapred. reduce. tasks=32- Example of dumping data out from a query into a file using slient mode:
$HIVE-HOME/bin/Hive-s-e ’select a.col from tab1 a’>a.txt- Example of running a script non-interactively:
$HIVE-HOME/bin/Hive-f /home/my/Hive-script.sql- Example of running an initialization script before entering interactive mode:
$HIVE-HOME/bin/Hive-i /home/my/Hive-init.sql- The Hiver File hive
The CCI when invoked without the – I option will attempt to load $HIVE-HOME/bin/Hive rc and HOME/.Hive rc as initialization files.
[ Learn Top Hadoop Interview Questions and Answers ]
Hive Batch Mode Commands
When $HIVE-HOME/bin/Hive is run with the –e or-option, it executes SQL Commands in batch mode.
.hive-e’’execute the query string.
.hive-f execute one or more SQL queries from a file.
Examples:
- When $HIVE-HOME/bin/Hive is run without either –e or- f option, it enters interactive shell mode i.e #hive
- hive>
- We have to use ’;’ to terminate commands.
- Comments are scripts that can be specified using the ‘–’ prefix.
Commands in the Interactive Shell
| SL No. | Command | Description |
| 1 | Quit or exit | Use quit or exit to lease the interactive shell. |
| 2 | Reset | Resets the configuration to the default values. Set the value of a particular configuration variable(key) |
| 3 | Set= -> | Note: If you misspell the variable name, the CLI will not show an error. |
| 4 | Set | Prints a list of configuration variables that are overridden by the user or Hive |
| 5 |
Set-r Add file[S]* | Prints all Hadoop and Hive configuration variables. |
| 6 |
Add JAR [S]* Add ARCHIVE[S]* | Adds one or more files, jars or archives to the list of resources in the distributed cache. |
| 7 |
List File[S] List JAR[S] List ARCHIVE[S] List File[s] >* | Lists the resources that are already added to the distributed cache. |
| 8 |
Add JAR [S]* Add ARCHIVE[S]* Delete FILE[S]* | Checks whether the given resources are already added to the distributed cache or not. |
| 9 |
Delete JAR[S]* Delete ARCHIVE[S]* | Removes the resource(s) from the distributed cache. |
| 10 | ! | Executes the shell command from the Hive shell |
| 11 | dfs | Executes a dfs command from the Hive shell |
| 12 | Executes a Hive query and prints results to the standard output. | |
| 13 | Source File |
Executes a script file inside the CLI |
For Example:
hive>set map red. reduce. tasks=32;
hive >set;
hive >select a.* from tab1;
hive >! LsConclusion
With this, we would like to wind up the article and hope you found the article informative. In case you have any doubt regarding any related concept, please feel free to drop the query in the comment section.
List of Big Data Courses:
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| Hadoop Training | Jul 28 to Aug 12 | View Details |
| Hadoop Training | Aug 01 to Aug 16 | View Details |
| Hadoop Training | Aug 04 to Aug 19 | View Details |
| Hadoop Training | Aug 08 to Aug 23 | View Details |

Ravindra Savaram is a Technical Lead at Mindmajix.com. His passion lies in writing articles on the most popular IT platforms including Machine learning, DevOps, Data Science, Artificial Intelligence, RPA, Deep Learning, and so on. You can stay up to date on all these technologies by following him on LinkedIn and Twitter.














