
- Guide for Installing JIRA Applications on Windows
- Top 5 JIRA Dashboard Gadgets
- JIRA Interview Questions
- Jira Kanban Boards
- JIRA Version History
- JIRA Vs TFS
- Jira vs Trello: Agile Project Management Tools Comparison
- SDLC Interview Questions and Answers
- Tosca Jira Integration
- JIRA vs Bugzilla
- ALM Octane Tutorial - A Complete Beginners Guide
- How to Install JIRA on Windows
- JIRA Projects
Jira is one of the most common applications for handling software projects. It is an Agile project management tool and it supports Agile methodology, whether that is kanban, scrum, or any other view of Agile. In one single JIRA tool, you can manage, track, as well as plan all your agile software development projects. It is actually a software program that enables companies to handle their projects, processes, tasks, and issues.
JIRA is regarded as a ‘smart software’ as it easily automates the tedious stuff related to processes, project management, tasks, and issues. This software enables teams to handle issues all through the problem’s life cycle. It is highly customizable and tailored to fit various organizational structures. An Australian company known as Atlassian has developed this product and it is written in Java.
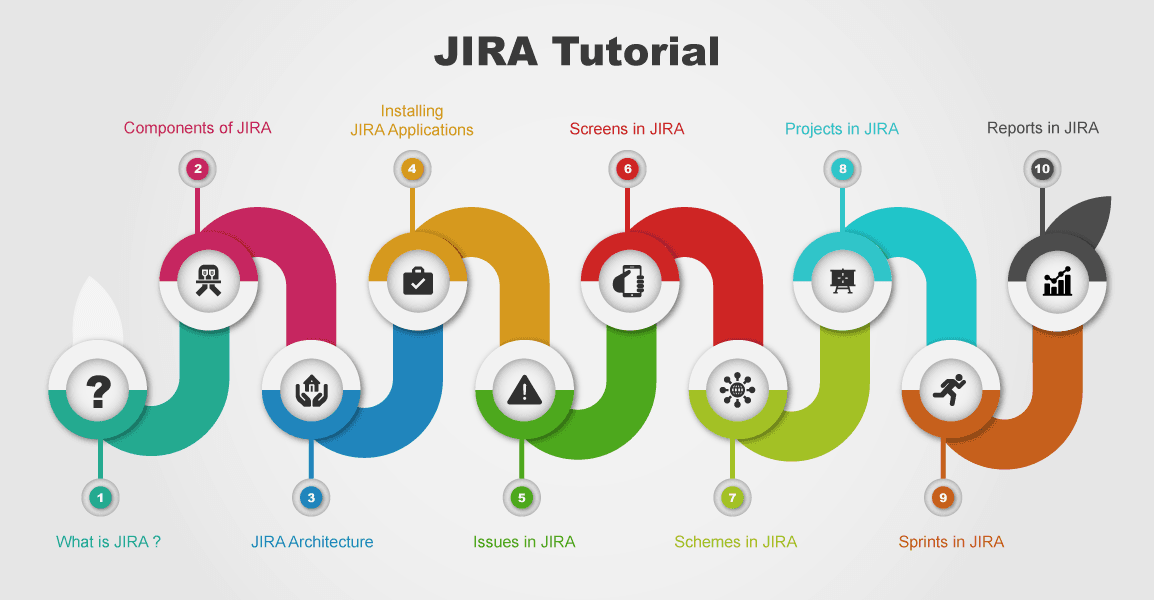
Table of Content
- Components in JIRA
- JIRA Architecture
- Installing JIRA Software
- JIRA Issues
- Issue Types
- JIRA Screens
- JIRA Schemes
- Projects in JIRA
- JIRA Sprints
- JIRA Reports
- Who can use JIRA
Introduction to JIRA Tutorial
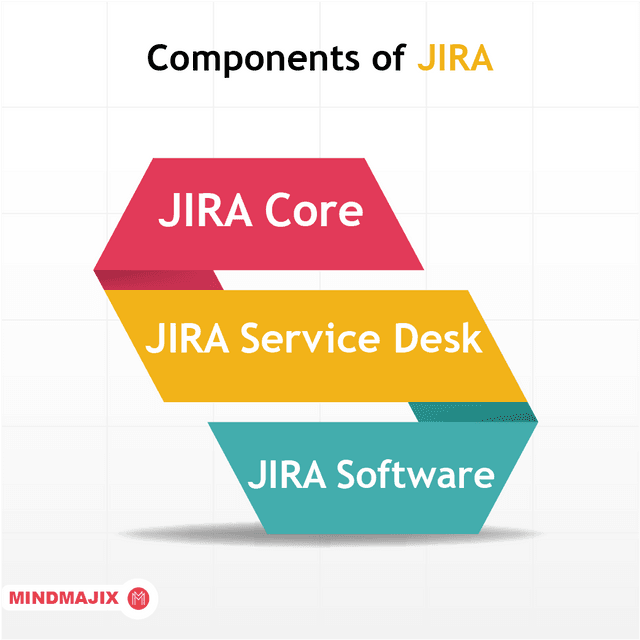
Components in JIRA
JIRA is divided into 3 major components and the term JIRA refers to a common platform on which these products are developed. Now, let’s have a look at these 3 JIRA components.
- JIRA Core - JIRA Core resembles classic JIRA with its workflow capabilities and field customizations. JIRA Core is ideal for general-purpose task management.
- JIRA Service Desk - The JIRA Service Desk is a JIRA Core with the capabilities of a Service Desk. JIRA Service Desk is designed for running JIRA as a support system for ticketing with a focus on customer satisfaction with Service Level Agreement (SLA) goals and with a simple user interface for the end-users.
- JIRA Software - Previously known as JIRA Agile, JIRA Software is JIRA Core with capabilities of Agile. This is highly suited for software development teams that want to utilize Agile methodologies like JIRA Kanban and Scrum.
| This topic is crucial in the Jira interview, and our trainer has covered it in-depth in Jira Training. |
The JIRA family of applications is developed to provide a tailored experience to their users. JIRA core is JIRA’s default application and is always present in a JIRA instance. You can also include other applications like JIRA Service Desk or JIRA Software. A user may need access to any combination of these applications, or one application, or even all the applications.
As the default application is JIRA Core, if you have a license for JIRA Service Desk or JIRA Software, your users can have access to JIRA Core without the need for an additional license.
Every JIRA application offers a tailored experience for its users and is associated with a specific type of project, which in turn, provides application-specific features. The project types are business projects for JIRA Core, software projects for JIRA Software, and Service Desk projects for JIRA Service Desk. The associated application-specific feature set of JIRA applications is as follows.
- The associated application-specific feature set of JIRA Core - Available to all the licensed users of JIRA.
- The associated application-specific feature set of JIRA Software - Release hub for software version release, Agile dashboards, and integration with development tools.
- The associated application-specific feature set of JIRA Service Desk - SLAs, permission schemes allowing customer access, and a customizable web portal for customers.
The users who can log in to a JIRA instance can view every project present in that instance, but they can only view the application-specific features if they have access to the application. For instance, a software project will be able to show data from linked development applications like Fisheye and Bitbucket on a software project, and you can create Agile dashboards. But, only a JIRA software user can view this information.
A JIRA Core user will not be able to view the application-specific features such as JIRA dashboards or information related to development but can see the Software project. In the same way, a JIRA Software user will be able to have only a basic view of the Service Desk project and the issues related to it, but will be able to view any JIRA Service Desk application-specific features on the project.
JIRA Architecture
JIRA is written in Java and is deployed into a java Servlet Container like Tomcat as a standard Java WAR file. Users interact with JIRA with the help of a web browser since JIRA is a web application. JIRA utilizes WebWork 1 for processing web requests that the users submit. WebWork 1 is actually an MVC framework that is similar to Struts. JSP is used by JIRA for the View layer. When you visit a specific URL in a web application, the scenario that happens is defined by a web application framework. In JIRA, almost all authentication is performed via Seraph. Seraph is an open-source web authentication framework.
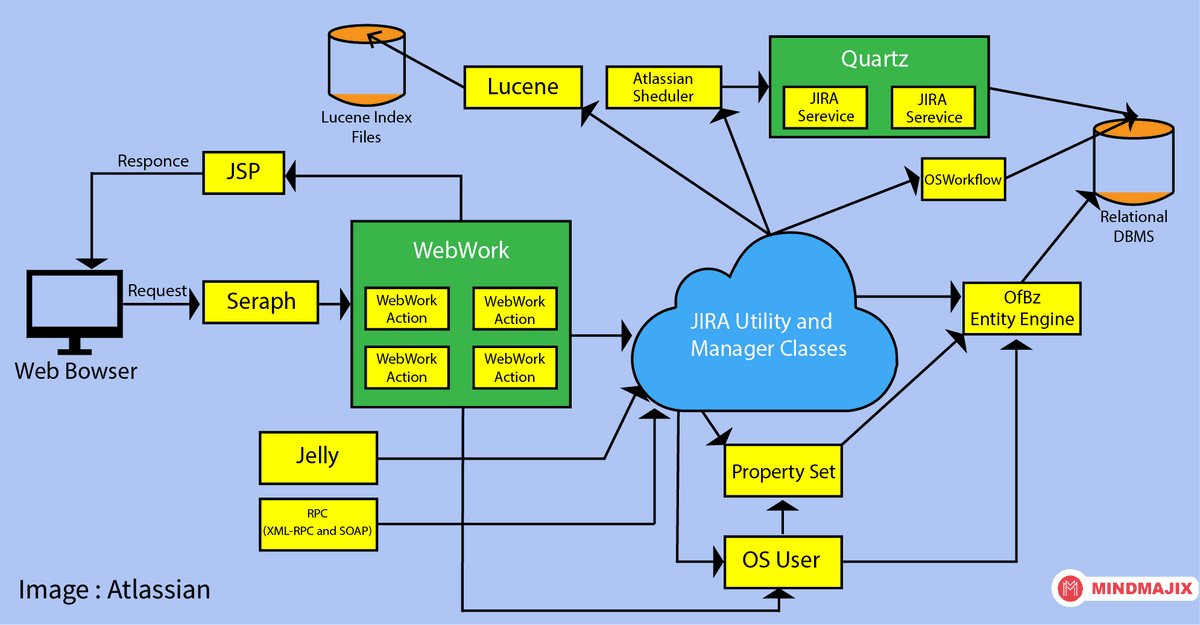
JIRA can have new actions that are defined with the help of Webwork. The Webwork Sample plugin consists of example classes and actions that can be utilized to understand this topic in a comprehensive manner. The Single Sign-On (SSO) and Identity Management tool of Atlassian is known as Crowd. You can know more about JIRA architecture here.
Installing JIRA software
This section will provide you with information regarding the installation of JIRA applications in both Windows and Linux.
Installing JIRA Applications on Windows and Linux
Installation
Now, let’s have a look at the installation of a JIRA application in a production environment using the Windows and Linux installers.
- The first step in the installation is downloading JIRA (downloading the installer for your OS (operating system). You can download this here.
- In the next step, you have to run the installer. Windows administrator account should be used for installation on Windows. For installing on Linux, you must make the installer executable and run the installer. It is recommended to use Sudo for running the installer as this creates a dedicated account for running JIRA and enables you to run JIRA as a service.
- You must follow the prompts in order to install JIRA. You will be asked for the following information such as home directory, destination directory, and TCP ports. Once the installation gets completed, JIRA will startup in your browser.
Set up your JIRA Application
You have to choose the setup method first and then connect to your database. In the next step, you should set application properties and enter your license. After that, you have to create your administrator account and set up email notifications. Then, you can start using JIRA.
Related Article: Step Wise Guide on the Installation of Jira on Windows
JIRA Issues
The issues in JIRA software help you to keep track of your team, estimate workload, and manage code. In this section, I will let you know what you can do with an issue.
What is an Issue?
Various companies use JIRA Tool to track different types of issues, which can represent anything such as a leave request form, a project task, or a software bug. In any JIRA project, issues can be termed as its building blocks. A task, a bug, a story, or any other issue type can be represented as an issue. An issue can be stated as a packet of work in JIRA Core. It can be a large chunk of work or a small task depending on your project and how your team decides to divide work into issues. An example of a small issue can be “Remember to order a burger for charity night” and a large issue can be “Build a bridging wall between garage and house.”
Creating an Issue in JIRA
Before you begin with issue creation, you require the Create Issue project permission for the relevant project of the issue. Now, let’s have a look at the steps involved in creating an issue.
1. At the top of the screen, click “create” for opening the “Create Issue” dialog box.
2. In the Create Issue dialog box, select the relevant Issue Type and Project.
3. For the issue, type a “Summary” and complete any appropriate fields.
4. If you want to hide existing fields or if you want to access fields that aren’t displayed in this dialog box:
- You should click the “Configure Fields” button present at the top right of the screen.
- Click on “Custom” and choose the fields you want to hide or show by clearing or selecting the relevant check boxes respectively, or for showing all fields, you should click “All.” These selected fields will be displayed when you next create an issue.
5. Optional: You can select the “Create another” checkbox present at the bottom of the dialog if you want to create a series of similar issues with the same Issue and Project Type. In the new Create Issue dialog box, some of the fields may be pre-populated depending on the values you may have specified while creating previous issues, and your configuration. Before creating the next issue, ensure you check they are all correct.
6. Click the “Create” button when you are satisfied with your issue’s content.
Our Jira Training Hyderabad has Detailed explanations and practical examples of the above topic.
JIRA Issue Types
JIRA software allows you to keep track of various things such as helpdesk tickets, tasks, bugs, etc with the help of different tissue types. An issue type can also be configured to act differently. This section will let you know the specific issue types that exist within the 3 JIRA applications, for example, to track different pieces of information or to follow a different process flow.
Default Issue Types in JIRA Core
- Task - A task that needs to be done.
- Subtask - A small task existing with a large chunk of work.
Default Issue Types in JIRA Software
- Story - A story is a functionality request expressed from the user's perspective.
- Bug - A bug is a problem that impairs service or product functionality.
- Epic - An Epic is a large chunk of work that consists of many issues.
Default Issues Types in JIRA Service Desk
- Incident - An incident or a System outage.
- Service request - A service request is a general request from a user for a service or a product.
- Change - A change is a rollout of new solutions or technologies.
- Problem - A problem is the tracking of underlying causes of incidents.
Related Article: Jira Vs Trello
Exporting Issues in JIRA
Let’s say you already have a JIRA Cloud site and you need to move to JIRA Server, you can actually create a backup of your JIRA Cloud data which you can import into server installation. It is to be noted that, for your instance, the Atlassian Cloud takes backups every 24 hours for application recovery purposes.
The following data can be backed up and exported from your JIRA Cloud site:
- Issues
- Users and user group settings
- Project logos, user avatars, and issue attachments
Sharing Issues in JIRA
You can use the Share option to email the link to an issue, to other JIRA users. This option also enables you to add an optional note to the email.
For sharing the issue with other JIRA users, first, you have to view the issue that you want to share. Then, you should click the Share button present at the top-right. After this, you have to specify the JIRA users or type the individuals’ email is that which you wish to share the issue. You can add an optional note. If you are done with all this, you can click the Share button which is present at the bottom of the window that is displayed.
Related Article: Frequently Asked JIRA Interview Questions
JIRA Screens
What is a Screen?
In JIRA, when an issue is viewed, edited, or created, the resulting collection of fields that appear is defined as a Screen. A screen provides you with control over the data you want to get included in your issue based on the type of issue you are editing or creating.
How to Create a Screen in JIRA?
To create a screen in the JIRA Tool, you must navigate to the Issues Administration page and choose “Screens” from the left sidebar. Then click on “Add Screen” and then, name your screen and write a description for it. See that the name is descriptive and says exactly what the screen is intended for. Then, you have to add fields to your screen. The required field is only the Summary field but that is not enough for an issue.
JIRA Schemes
A JIRA Scheme maps a project to any type of concept managed by JIRA. By defining schemes, JIRA enables you to display specific pieces of issue information at specific times. A screen can simply be stated as a collection of fields. When an issue is being edited, viewed, created, or transitioned via a specific step in a workflow, you can choose which screen to display. The screen scheme of a project determines which screens have to be displayed for different issue operations such as create, edit, or view. The various types of Schemes are as follows.
- Issue type of screen scheme
- Issue type scheme
- Workflow scheme
- Issue security scheme
- Screen Scheme
- Field configuration scheme
- Permission scheme
- Notification scheme.
Projects in JIRA
In JIRA Tool, the collection of issues is known as a Project. A JIRA project could be used to manage a help desk, track a project, coordinate a product’s development, and more, based on your requirements. A JIRA project can also be customized as well as configured for suit your needs.
- Creating a Project in JIRA
- Click on “Projects” in the header and then on “Create Project.”
- Follow the wizard for project creation.
Project types:
More than one project type is available to you based on which JIRA applications you have installed.
Every project type has a particular set of features.
All the users on the JIRA instance can see all projects, but the actions they can take and the features they see are determined by their project-specific permissions and application access.
Shared Configurations:
A project is created with its own set of schemes when you create it from a template. The schemes are:
- A field configuration scheme (default)
- An issue type screen scheme
- An issue type scheme
- A workflow scheme
- An issue security scheme
- A notification scheme
- A permission scheme
“Create with shared configuration” can be selected to select an existing project and to utilize the schemes of that project. It is to be noted that when you are sharing schemes, any change to the scheme will have an effect on every project utilizing that scheme.
JIRA Sprints
What is a Sprint?
A Sprint is defined as a fixed time period wherein teams finish work from their product backlog. The time period for sprints may be one, two, or four weeks. A team will usually have developed and implemented a working product increment at the end of the Sprint.
How to Create a Sprint in JIRA?
In order to create a sprint in JIRA, you must navigate to the “Backlog” of your Scrum project and click on the “Create Sprint” button which is present at the top of the Backlog.
Planning Sprints
Every sprint begins with a planning meeting. While planning a sprint, your team would usually commit to providing a set of stories that are pulled from the top of a backlog. You see sprints on a board in JIRA software and assign issues to them. With the help of JQL (Sprint field), you can search for any issues in upcoming sprints. This involves starting the sprint, assigning stories to the sprint, and creating a sprint.
How to Start a Sprint?
In order to start a sprint, you must navigate to the “Backlog” of your Scrum project. You should locate the sprint that you wish to begin and click on “Start sprint”. Then, you have to update the Sprint name and add a sprint goal if required. After that, choose the Start and End dates for the Sprint. You will be navigated to the Active sprints where you can view the issues in the newly started sprint.
Viewing Issues in a Sprint
To view planned sprints, you can utilize the backlog of aboard. You can utilize the Active sprints of a board if you want to see a sprint in progress. JQL can also be used to search for a sprint’s issues.
[ Check out Jira vs Bugzilla ]
JIRA Reports
JIRA Core offers a range of reports that display statistics for specific versions, people, information about issues.
How to Generate Reports in JIRA?
In order to generate a report, you must navigate to the desired project, and click on “Reports”. Then, you have to select a report from the list of reports. The various types of reports are as follows.
- Average Age Report
- Pie Chart Report
- Created vs Resolved Issues Report
- Resolution Time Report
- Recently Created Issues Report
- Time Since Issues Report
- Single Level Group By Report
- User Workload Report
- Time Tracking Report
- Workload Pie Chart Report
- Version Workload Report
Upon connecting JIRA to Confluence, the following reports can be created in Confluence.
- Change Log
- Status Report
Workflows
Your JIRA issues can follow a process that mirrors the practices of your team. A workflow defines a sequence of steps or statuses that an issue will follow. Examples of the statuses or steps are “Resolved,” “In Progress,” and “Open.” How the issues will transition between steps can be configured by you. The workflow scheme of a project determines which workflows will apply to issue types in this project.
Fields
You can define field behavior in JIRA by using fields. Every field can be visible or hidden, plain text or rich text, and optional or required. A field configuration determines the requirements, overall visibility, and help-text, and formatting of each field. A field configuration scheme in a project determines which field configuration can be applied to issue types in this project.
Roles
In different projects, different roles can be played by different people. For example, the same person can be an observer in one project and the leader of another project. JIRA allows you to allocate specific people to particular roles in your project.
Versions
In JIRA, a grouping of issues can be done by allocating them to versions. Take, for example, if JIRA can be used to manage the build of a house or manage the development of a product, you must define different versions that can help you to track which issues relate to various phases of your build or product. JIRA can help you archive, release, and manage your versions.
Components
You can define various components for categorizing and managing different issues. Take for example, for a software development project, you might define components such as “Documentation,” “Usability,” and “Database”. For each component, you can choose a default assignee. This is useful if you have different people who lead different sub-teams in your project.

Permissions
JIRA enables you to control who will be able to access your project and what exactly they can do, with the help of project permissions. With the help of security levels, access to individual issues can be controlled by you. Also, you can choose to provide access to specific roles, or groups, or users.
Notifications
When the occurrence of a specific event happens in your project, JIRA can notify the appropriate people. When different events occur, you can select specific roles, groups, or people for receiving email notifications.
Development Tools
The development tools section is available only on JIRA projects, and it can be viewed only by users of JIRA software. This section provides you with an overview of development tools that are connected and specifies which users can utilize the integration features between them.
Epic
An Epic captures a large chunk of work and it is defined as a large user story that can be divided into a number of smaller user stories.
User story or Story
A user story is a software system requirement that is stated in a few short sentences with the usage of non-technical language. A story is expressed as an issue in JIRA Agile and, within the story, the individual tasks are represented as sub-tasks.
Task
A unit of work present within a story is known as a task. The stories are expressed as parent issues in JIRA Agile while the sub-task issues are the name by which the individual tasks are represented.
For an issue, a sub-task can be created to allow different aspects of an issue to be assigned to different persons, or to split the issue into smaller chunks. To allow the sub-task to be worked on independently, you can convert it to an issue if you find it holding up the issue’s resolution.
JIRA integrates with source control programs like Team Foundation Server, Concurrent Versions Systems, Perforce, Mercurial, Git, and ClearCase. Real-time reporting is another great feature of JIRA. The real-time data enables people to act quickly on improvements along the process of your project.
The above concept is instrumental while doing implementations across industry projects and is covered in Jira Training Bangalore curriculum.
Who can use JIRA?
Though JIRA is mostly used by software developers, any department can effectively utilize its project management capabilities. For any team that needs to work through issues and collaborate in an orderly manner, JIRA can be its ideal tool. JIRA helps companies in their marketing and compliance domains and it also is quite helpful for remote companies employing freelancers.
Explore JIRA Sample Resumes! Download & Edit, Get Noticed by Top Employers!
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| JIRA Training | Jul 25 to Aug 09 | View Details |
| JIRA Training | Jul 28 to Aug 12 | View Details |
| JIRA Training | Aug 01 to Aug 16 | View Details |
| JIRA Training | Aug 04 to Aug 19 | View Details |

Ravindra Savaram is a Technical Lead at Mindmajix.com. His passion lies in writing articles on the most popular IT platforms including Machine learning, DevOps, Data Science, Artificial Intelligence, RPA, Deep Learning, and so on. You can stay up to date on all these technologies by following him on LinkedIn and Twitter.












