
- SSIS SQL Server Editions
- SSIS Data Flow Destinations
- SSIS Tutorial
- 64-Bit Issues In SSIS
- Guide for Accessing a Heterogeneous Data In SSIS
- Administering SSIS Using The SSIS Catalog
- Advanced Data Cleansing in SSIS
- Fuzzy Lookup and Fuzzy Grouping in SSIS
- SSIS – Analysis Services Processing Task, Execute DDL Task
- BreakPoints In SSIS
- Building the User Interface - SSIS
- Bulk Insert Task in SSIS Package - SSIS
- Learn Cache Connection Manager and Cache Transform in SSIS
- Clustering SSIS
- Command-Line Utilities In SSIS
- Creating the Basic Package in SSIS
- Data Extraction In SSIS
- Data Flow Task in SSIS
- Data Loading In SSIS
- Data Preparation Tasks in SSIS
- Data Profiling Task in SSIS with Example
- Introduction to Data Quality Services (DQS) Cleansing Transformation
- Deployment Models In SSIS
- Developing a Custom SSIS Source Component
- Developing a Custom Transformation Component - SSIS
- Dimension Table Loading In SSIS
- Error Outputs in SSIS
- Error Rows in SSIS
- Essential Coding, Debugging, and Troubleshooting Techniques - SSIS
- Event Handling - SSIS
- Excel and Access In SSIS
- SSIS Architecture
- External Management of SSIS
- Fact Table Loading
- Flat Files In SSIS
- Create SSIS Package in SQL Server
- How to Execute Stored Procedure in SSIS Execute SQL Task in SSIS
- How to get Solution Explorer in Visual Studio 2013 - SSIS
- How to Use Derived Column Transformation in SSIS with Example - SSIS
- Importing From Oracle In SSIS
- How to do Incremental Load Data using Control Table Pattern in SSIS
- Software Development Life Cycle in SSIS
- Introduction to SSIS
- Literal SQL - SSIS
- Logging in SSIS
- Lookup Transformation in SSIS
- Overview of Master Data Services SQL Server in SSIS
- Using the Merge Join Transformation in SSIS
- Monitoring Package Executions - SSIS
- Import and Export Wizard in SSIS with SQL Server Data
- Null in SQL Server - SSIS
- What is Open Database Connectivity (ODBC) in SSIS
- Package Configuration Part II - SSIS
- Package Configurations Part I - SSIS
- Package Log Providers - SSIS
- Package Transactions - SSIS
- Performance Counters In SSIS
- Pipeline Performance Monitoring In SSIS
- Restarting Packages In SSIS
- Scaling Out in SSIS
- Scheduling Packages in SSIS
- SSIS Script Task Assign Value to Variable
- Scripting in SSIS
- Security Of SSIS Packages
- SQL Server Boolean Expression In SSIS
- SQL Server Concatenate In SSIS
- SQL Server Data Tools for Visual Studio 2013
- SQL Server Date Time - SSIS
- SQL Server Management Objects Administration Tasks In SSIS
- SQL Server The Data Flow Sources in SSIS 2014
- SQL string functions
- Conditional Expression In SSIS
- SSIS Container
- SSIS Data Flow Design and Tuning
- SSIS Data Flow Examples in SSIS
- SSIS Expressions
- SSIS Script Task
- SSIS Software Development Life Cycle
- SSIS Pipeline Component Methods
- The SSIS Engine
- Typical Mainframe ETL With Data Scrubbing In SSIS
- Understanding Data Types Using Variables, Parameters and Expressions - SSIS
- Understanding The DATA FLOW in SSIS
- Using Precedence Constraints In SSIS
- Using the Script Component in SSIS
- Using T-SQL With SSIS
- Using XML and Web Services In SSIS
- Various Types of Transformations In SSIS - 2014
- Versioning and Source Code Control - SSIS
- Windows Management Instrumentation Tasks In SSIS
- SSIS Workflow Tasks – Integration Services
- Working with SQL Server 2014 Change Data Capture In SSIS
- SSIS Projects and Use Cases
Data transformation and integration are crucial for efficient data exploration in this data-driven world. In this way, SSIS is one of the robust platforms for data transformation and integration solutions. Companies widely employ SSIS for cleaning, mining, and loading data, so the demand for SSIS developers in the job market is constantly rising.
According to Glassdoor, the salary of an SSIS developer in India is over 7 LPA on average. In the USA, they make over 103k USD per year on average, says Talent. So, it is a great choice if you choose to make a career in the SSIS domain. Keeping this in mind, I have curated the top 50 SSIS questions and answers from the various SSIS topics in this blog. It will help you quickly breeze through your SSIS interviews and land your dream career.
We have categorized SSIS Interview Questions - 2024 (Updated) into 9 levels they are:
- Skills and Responsibilities
- For Beginners
- For Experienced
- Advanced Level
- Scenario-Based
- Frequently Asked Questions
Top 10 Frequently Asked SSIS Interview Questions
1. What are the Differences between SSIS and Informatica?
2. What is the SSIS package and what does it do?
3. What is the Difference between Execute TSQL Task and Execute SQL Task?
4. What is the use of a config file in SSIS?
5. What kind of containers can you use with SSIS packages?
6. What is the Manifest file in SSIS?
7. What is the difference between Merge and Union All?
8. How to back up or retrieve the SSIS packages?
9. What is the Different between Control Flow and Data Flow?
10. What is the Data Profiling task?
Skills and Responsibilities of SSIS Developers:
Before jumping into SSIS interview questions and answers, we will go through the primary and secondary skills required for SSIS developers in this section. Additionally, we will walk through the job responsibilities of SSIS developers at various expertise levels.
Primary Skills Required for SSIS Developers:
Let's look at the essential skills needed for SSIS developers.
- Strong knowledge of SSIS packages to perform data transformation and integration tasks.
- Familiar with programming languages such as SQL, HTML, T-SQL, XML, VB.Net, etc.
- Expertise in ETL processes to extract, transform, and load data in data warehouses
- Comprehensive knowledge of the data warehouse ETL design concepts and best practices
- Familiar with SSRS to generate reports using Matrix and Table control
- Sound exposure to writing complex queries in SQL language
- Proficiency in SQL Server analysis tools
- Knowledge of multidimensional models like star schemas in querying SQL servers
- Familiar with database objects to store and reference data
- Exposure to database tools such as SQL Query Analyser, SQL Server 2005 Query Editor, Management Studio, Solution Explorer, Reporting Server, etc.
- Good debugging and error-handling skills
Secondary Skills Required for SSIS Developers:
Let's outline the secondary skills that are necessary for SSIS developers.
- Familiar with software development lifecycle and Agile methodologies
- Proficient with operating systems like UNIX, Windows, and Perl
- Knowledge of profiler Azure data services such as Azure Data Factory, SQL Azure, and Data Lake.
- Exposure to data warehouse analytics
- Knowledge of SOLID design principles, quality assurance principles, and modelling methods
- Exceptional logical and analytical skills
- Excellent communication and collaboration skills
Job responsibilities of SSIS developers with 1-2 years of experience:
Let’s read through the job responsibilities of fresh SSIS developers.
- Designing and developing SSIS packages and applying transformations
- Creating jobs, scheduling jobs, deploying packages, performance tuning, etc.
- Designing and developing ETL work packages
- Designing and maintaining ETL processes, data warehouses, and cubes
- Creating reports using ETL reporting tools
- Designing, developing, and developing data pipelines using SSIS
- Identifying slow-running queries and re-create SQL queries for enhanced performance using the SQL server profiler
- Designing and developing physical or logical databases and troubleshooting
Job responsibilities of SSIS developers with 3-5 years of experience:
Let’s find out the job responsibilities of SSIS developers with middle-level expertise.
- Understanding project requirements, creating functional specifications, and converting the requirements into ETL SSIS packages
- Applying the systematic and structured approach for performing data integration.
- Performing data profiling, cleansing, and validation to ensure data quality for transformation and integration
- Designing and developing custom scripts, tasks, and components to optimise ETL workflows
- Working with clients to resolve issues, ensure quality, and satisfy customer expectations
- Performing peer code reviews and recommending code enhancements to novice SSIS developers
- Stay current with the latest developments in SSIS and implement the best practices to improve productivity.
Job responsibilities of SSIS developers with MORE THAN FIVE YEARS of experience:
Let’s look at the job responsibilities of senior-level SSIS developers below.
- Designing and developing SSIS packages and performing implementation checks in SSIS packages
- Design and develop complex ETL packages using SSIS
- Troubleshooting issues associated with SQL performance, package debugging, and configuration
- Developing SQL Server tables, views, stored procedures, triggers, and functions using the Microsoft SQL Server
- Importing data, performing data transformations, and moving data from one database to another
- Collaborating with cross-functional teams to gather information related to data integration and ETL requirements.
Well! Understanding the SSIS developer skills and responsibilities will help you prepare for SSIS interviews effectively and excel in your career.
SSIS Developer Interview Questions for Beginners:
I have compiled the basic SSIS interview questions and answers in this section. This section will provide you with a solid foundation in SSIS packages, package deployment, SSIS control flow and data flow, and many more.
1. What is SSIS?
Ans: SSIS or SQL Server Integration Services is the upgraded Data Transformation Services (DTS) platform. SSIS is also an ETL tool that handles data Extraction, Transformation, and Loading. We use SSIS for data profiling and transformation, file system manipulation, etc.
SSIS is a robust platform that supports creating workflows and loading data in data warehouses. We can use SSIS to automate the maintenance of SQL Server databases, update multidimensional cube data, and more.
| If you want to enrich your career and become a certified professional in SSIS, then enroll in "SSIS Online Training". This course will help you to achieve excellence in this domain. |
2. What is an SSIS control flow?
Ans: An SSIS control flow allows developers to program graphically. A control flow includes many operations, such as data flow tasks, execution SQL tasks, etc. It also consists of the order and relationship between the operations.
A control flow has many components, each performing a specific task. The essential elements of a control flow include a sequence container, a ‘for loop’ container, a 'for each' loop container, a task host container, and a few more. Besides, control flow components are interconnected, which helps to control data flow.
| Related Article: SSIS Control Flow |
3. What is Data Transformation?
Ans: The data transformation stage in an ETL process includes a set of functions or rules to modify the input data into the required format for a specific purpose. Data transformation includes data cleansing and standardisation to enhance the data quality. Thus, we can make accurate analyses using the transformed data.
For example, we may need the key performance metrics of a specific business by analysing the last six months of business data. However, the data may have many missing values and corrupt data. We must remove these errors first before using the data for further analysis. That’s where data transformation comes into the scene to improve the data quality.
4. What kind of variables does SSIS support?
Ans: SSIS supports two types of variables: user-defined variables and system variables. Package developers define user-defined variables, whereas integration services define system variables. We can create user-defined variables for all SSIS container types, such as packages, sequence containers, 'for each' loop containers, etc.
The main thing is that we can create many user-defined variables for a package. But at the same, we cannot create additional system variables.
5. What are SSIS packages?
An SSIS package includes connections, control and data flow elements, variables, event handlers, and configurations. We can assemble these elements in an SSIS package using graphical design tools. For example, we can create SSIS packages using the Business Intelligence Development Studio (BIDS).
We can store SSIS packages in the SSIS package store. SSIS packages can merge data from heterogeneous sources into the SQL Server. We can also use SSIS packages to clean and standardise data, populate data warehouses, and automate administrative tasks.
6. What kind of containers can you use with SSIS packages?
Ans: SSIS provides four types of containers for building SSIS packages. The containers are sequence, task host, for loop, and 'for-each' loop container.
The sequence container helps to group the same type of tasks. In a way, it is an organisation container that supports building complex SSIS packages.
The task host container provides services to a single task. This container is not configured separately. But it is configured while setting the properties for the task it holds.
The ‘for loop’ container executes tasks for a specific iteration. For example, we can use the ‘for loop’ container to update a record ten times. So, it eliminates the need to create ten different packages for execution. Also, it avoids running the packages ten times.
The ‘for each’ loop container helps to define a control flow in an SSIS Package. The ‘for-each’ enumerator enables the looping in the package. The ‘for-each’ container repeats the control flow for every enumerator member.

7. How to create the deployment utility?
Ans: Deployment is the process in which packages convert from development mode into executables mode. For deploying the SSIS package, you can directly deploy the package by right-clicking the Integration Services project and build it.
This will save the package.dtsx file on the projectbin folder. Also, you can create the deployment utility using which the package can be deployed at either SQL Server or as a file on any location.
For creating deployment utility, follow these steps:
- Right-click on the project and click on properties.
- Select “True” for createDeploymentUtiltiy Option. Also, you can set the deployment path.
- Now close the window after making the changes and build the project by right-clicking on the project.
- A deployment folder will be created in the BIN folder of your main project location.
- Inside the deployment folder, you will find the .manifest file, double-clicking on it you can get options to deploy the package on SQL Server.
- Log in to SQL Server and check-in MSDB on Integration Services.
8. What is the latest version of the SQL server?
SQL Server 2022 (16.x) is the latest version of SQL Server. It was released on 16/11/2022. The support end date is 11/02/2028.
Below are the other details of the newest version of SQL Server.
| RTM (no SP) | 16.0.1000.6 |
| Latest CU | CU12 (16.0.4115.5,March 2024) |
9. What are the Differences between SSIS and Informatica?
Ans:
| Features | SSIS | Informatica |
| Ease of Use | Easy to setup | It's a bit tricky for beginners. |
| Maintenance | Easy to maintain | Difficult to maintain |
| Productivity | Moderate | High |
| Cost | Cost-effective | Expensive |
| Support | Community support is good | Need escalation for better support |
| Connectivity | Moderate | Offers excellent connectivity |
10. What are the new features incorporated in the latest SQL server version?
The following are the enhancements made in the latest SQL server version.
- Link to Azure SQL managed instance to replicate data between the SQL server and Azure SQL managed instances. It supports disaster recovery and migration.
- Object storage integration to integrate SQL Server with S3-compatible object storage
- Azure synapse link for SQL to get real-time analytics on data
- Data virtualisation to different types of data on different data sources
- Microsoft Defender for cloud integration to protect SQL servers using the Defender for SQL plan.
- System page latch concurrency enhancements to make concurrent updates to GAM pages and SGAM pages.
11. What are Stored Procedures?
A stored procedure is a pack of SQL statements stored in a relational database with an assigned name. It is a code that we can reuse any number of times.
We use stored procedures to:
- allow multiple programs to perform operations on database objects
- reduce the traffic between the client and server
- improve application performance
- simplify troubleshooting and maintenance.
12. What is the SQL Server Profiler?
The SQL server profiler is an interface with which we can create and manage traces. It helps to analyse and replay trace results. We can save events in a trace file for further analysis. We can also replay the events while diagnosing an issue.
For example, we can use the SQL Server profiler to monitor a production environment tightly. It helps to identify the stored procedures that run slowly and reduce performance.
13. What is SQL performance tuning?
Performance tuning is the process of examining and resolving the issues affecting an SQL database's efficiency. If we want to improve the performance of SQL queries, we need to tune SQL queries and databases for better results.
Disk I/O, CPU utilisation, and memory utilisation are a few critical metrics used to track the performance of resources. They help to make efficient SQL performance tuning. Moreover, performance tuning helps to improve the reliability and accuracy of the data stored in databases.
14. What is the architecture of SSIS?
SSIS has a robust architecture that sharply separates data transformation from the package control flow. The architecture consists of two engines: the integration services runtime engine and the integration services dataflow engine.
The runtime engine controls the execution of SSIS packages, whereas the data flow engine manages the data flow task. The runtime engine helps to set options for logging, event handlers, and variables. The data flow engine helps to extract, transform, and load data.
15. What is SQL Data Modelling?
Data modelling is the process of evaluating data and their relationships. We perform data modelling to fulfil application data requirements. Data modelling plays a crucial role in storing data in databases.
SQL data modelling includes three levels: conceptual, logical, and physical. We can identify the main entities, attributes, and domain relationships at the conceptual level. We can apply the rules and constraints of database systems at the logical level. The physical model includes the storage, network, hardware, and database security.
Well! You have gone through the basic-level SSIS interview questions and answers. The fundamental knowledge you have gained in this section will be the stepping stone to learning advanced SSIS concepts in the following sections.
SSIS Interview Questions For Experienced
I have collated in-depth SSIS interview questions for experienced learners in this section. It will help elevate your SSIS expertise to the next level.
16. What is the Manifest file in SSIS?
Ans: The manifest file in SSIS consists of the vital information for deployment. It has the metadata of packages, security details, configurations, etc. It is a simple, readable XML file. We need manifest files to deploy SSIS packages to a target destination using a wizard. The advantage of the manifest file is that it comes with a user-friendly interface. The downside of the manifest file is that it lacks flexibility.
17. What is File system deployment?
Ans: The file system deployment stores package files on a network or local drive. So, we can use the SQL agent job to schedule when the packages should run.
18. How to back up or retrieve the SSIS packages?
Ans: The msdb database stores SSIS packages. So, if the SQL Server goes down, we can restore the packages from the MSDB database. Additionally, we can back up SSIS packages using the full database backup.
19. What is the data flow task in SSIS?
Ans: Know that every data flow task will have at least a single data flow. It allows users to transform, clean, and modify data. A data flow task creates an execution plan from the data flow at runtime. Then, the dataflow engine executes the data flow task.
Further, adding a package control with a data flow task allows the package to extract, transform, and load data.
20. What is the Data Profiling task?
Ans: Data profiling is the process of analyzing the source data to better understand what condition the data is in, in terms of cleanliness, patterns, numbers or nulls, and so on. data profiling tasks usually be used at the beginning of the development cycle to support the design of the destination database schema. Note that this task is not used when you develop the normal recurring ETL packages.
21. What is the multicast Transformation in SSIS?
Ans: We apply the multicast transformation to send input data to multiple output paths. This transformation can send a path to various destinations. The multicast transformation is similar to the split transformation because both send data to various outputs. The main thing about multicast transformation is that we cannot specify which part of the data will have which output.
22. What is the difference between Merge and Union All?
Ans: The merge transformation merges data from two paths into a single one. The transformation breaks data flow into different paths that handle specific errors. Then, we must merge the paths back into the main data flow downstream once the errors have been removed. It also supports integrating data from two separate data sources. We must also perform data sorting in the merge transformation.
On the other hand, the Union All transformation works like the merge transformation but does not require data sorting. It combines outputs from multiple sources into a single result set.
23. OLE DB Command Transform?
Ans: The OLE DB command transform is a robust method designed to execute an SQL statement for each row in the input data. The SQL statement can be an inline statement or a stored procedure call. Further, the OLE DB command transform is the same as that of the ADO command object.
24. Execute package task?
Ans: The execute package task enables developers to build SSIS solutions. They are called parent packages that execute other packages called ‘child packages’.
We must separate packages into discrete functional workflows if we want fast-paced development and testing cycles. In SSIS, most of the configurable properties are in the package tab of the executable package task editor.
If the child package is located on an SQL Server, we must use the OLE DB Connection Manager to hold the package. It allows developers to choose the child package within the connection to set the package.
25. What are the various options for configuring transactions?
Ans: SSIS provides three options for configuring transactions: Supported, Not Supported, and Required. Let’s take a closer look at them in the following.
Supported: A container does not start a transaction in this configuration option. But at the same time, it joins with any transaction started by its parent container. For example, consider a package with four executable SQL tasks to start a transaction. The tasks update the database after the execution. The updates are rolled back if any task fails. There will be no database updates if the package does not start a transaction.
Not Supported: The container doesn't start a transaction in this configuration option. Similarly, it doesn't join an existing transaction. The parent container transactions do not affect child containers in this configuration.
Required: In this configuration, a container initiates a transaction when no other container has already been started by its parent container. If a transaction already exists, the container joins the transaction. For example, if a package includes a sequence container that uses the ‘Required’ option, the sequence container would start its transaction. The sequence container will join the package transaction if the package is configured to use the ‘Required’ Option.
26. What are the differences between SSRS, SSAS, and SSIS?
Ans: SSRS stands for SQL Server Reporting Services. It is a framework with tools like the report builder, report manager, report designer, and report server. It is a web interface that generates interactive reporting solutions in various formats.
SSAS stands for SQL Server Analysis Services. It is a multidimensional tool that supports online analytical processing. It helps to analyse the large amounts of data stored in relational databases.
SSIS stands for SQL Server Integration Services. It comes with ETL capabilities to transform and load data in data warehouses. The critical components of SSIS are the SSIS designer, import and export wizard, and SSIS API programming.
Good! We hope that this section has significantly enhanced your knowledge of SSIS. Now, you are ready to dive deep into the advanced concepts of SSIS packages that are coming up in the following section.
SSIS Interview Questions And Answers for Advanced Learners
I have composed the advanced SSIS interview questions in this section, which will help to boost your SSIS knowledge to greater heights.
27. What is the Difference between Execute TSQL Task and Execute SQL Task?
Ans: In the following, let’s examine the differences between the ‘Execute TSQL task’ and ‘Execute SQL Task’.
Execute the TSQL Task:
- Pros: It takes less memory and offers faster performance
- Cons: It doesn’t support output into variables
Execute SQL Task:
- Pros: It supports output into multiple types of connections, variables, and parameterised queries.
- Cons: It takes more memory and performs slower than the TSQL task.
28. What are Precedence Constraints?
Ans: In SSIS, a task will be executed if the condition set by the precedence constraint is met. The constraints allow tasks to take different paths based on other tasks' success or failure.
- Success: Workflow will proceed when the preceding container executes successfully. It is indicated in the control flow by a solid green line.
- Failure: Workflow will proceed when the preceding container’s execution fails. It is indicated in the control flow by a solid red line.
- Completion: Workflow will proceed when the preceding container’s execution is completed, regardless of success or failure. It is indicated in the control flow by a solid blue line.
- Expression/Constraint with logical AND: The workflow will run when the specified expression is evaluated as ‘True’.
29. What is the use of a config file in SSIS?
Ans: A configuration file in SSIS enables the properties of package objects to be updated dynamically during runtime.
We can store configuration files in multiple ways, as listed below:
XML configuration file: Store the config file as an XML file.
- As an XML file.
- in the registry
- in one of the environment variables.
- as a variable
- in a table in the SQL Server
30. What is the Different between Control Flow and Data Flow?
Ans:
- We use a control flow to design a package flow and a data flow to design ETL processes.
- Data flow is the subset of control flow
- We cannot use a data flow without a control flow
- Process-based tasks are part of a control flow, whereas ETL-related tasks are part of a data flow.
All process base tasks are part of control flow while ETL related tasks are part of Dataflow which is again a subset of control flow.
31. What is a Checkpoint in SSIS?
Ans: In SSIS, a checkpoint is a crucial property to restart a project after it has failed. We create a checkpoint file by setting the property as ‘True’. A Checkpoint file stores the information about the package execution.
33. Can you run SSIS packages with SQL Server Express?
Ans: We use DTExec.exe to run SSIS packages from the command line. We get DTExec.exe and the necessary tools with SQL SERVER 2005 Express Edition. It comes with the Advanced Services and Microsoft SQL Server 2005 Express Edition Toolkit.
34. How can I manually fail a package in Integration Services?
Ans: The execute SQL task runs in the SQL Server. The task checks tables in the SQL Server to see whether they have over 1000 rows. We can fail a package manually if it has less than 1000 rows.
35. How do I force a fail inside of a SQL statement?
Ans: We can use the code below to force a fail inside a SQL statement.
select @count = select count(*) from my_table
if @count < 1000
begin
raiserror(‘Too few rows in my_table’,16,1)
end
else
begin
— Process your table here
end
You should get the results you want.
36. No Process Is on the Other End of the Pipe?
Ans: FYI, I’ve just had the same error.
I switched to Windows authentication, disconnected, then tried to log in again with SQL authentication. This time I was told my password had expired. I changed the password and it all worked again.
Scenario-based SSIS Interview Questions
In this section, I have gathered a set of SSIS scenario-based interview questions and included the perfect answers. It will help you to improve your hands-on skills and make you job-ready.
37. What is the SSIS package and what does it do?
Ans: SSIS (SQL Server Integration Services) is an upgrade of DTS (Data Transformation Services), which is a feature of the previous version of SQL Server. SSIS packages can be created in BIDS (Business Intelligence Development Studio). These can be used to merge data from heterogeneous data sources into SQL Server. They can also be used to populate data warehouses, to clean and standardize data, and to automate administrative tasks.
SQL Server Integration Services (SSIS) is a component of Microsoft SQL Server 2005. It replaces Data Transformation Services, which has been a feature of SQL Server since Version 7.0. Unlike DTS, which was included in all versions, SSIS is only available in the “Standard” and “Enterprise” editions.
Integration Services provides a platform to build data integration and workflow applications. The primary use of SSIS is data warehousing as the product features a fast and flexible tool for data extraction, transformation, and loading (ETL).). The tool may also be used to automate the maintenance of SQL Server databases, update multidimensional cube data, and perform other functions.
38. Running SSIS packages in separate memory allocations or increasing the default buffer size?
Ans: I have an SSIS package that has a child package that is failing. The error message isn’t very helpful.
The attempt to add a row to the Data Flow task buffer failed with error code 0xC0047020
The problem seems to be I am running out of Virtual Memory to complete the job.
I found a forum thread that may help solve the problem.
From the solutions offered I am unsure though how to:
Increase default buffer size
Allocate a child package into its own memory allocation.
I am running the package daily in SQL Server 2005. I was running fine daily up until the 12th. I am assuming the dat file that we are using to import data into the database grew to a size that was too large for the database to handle. It’s only an 8.90MB CSV file though. The import is a straight column to column import.
The problem child package in step 1 and fails and continues and successfully completes the next 8 steps.
39. How much memory is allocated to SQL Server? How much memory is allocated outside of the SQL Server process space?
Ans: The reason I ask is that SSIS memory is allocated from me to leave the area of memory that sits outside of the SQL Server process space.
See HERE for details on configuring the amount of memory available to me to leave a portion of memory.
For generic performance tuning of SSIS consult the following article.
Integration Services: Performance Tuning Techniques
I hope this makes sense but feel free to drop me a line once you have digested the material.
40. How to schedule the SSIS package to run as something other than SQL Agent Service Account?
Ans: If you have access to SQL Server Agent through SQL Server Management Studio, here are the steps to create a job using the Graphical User Interface. The steps show how to create an SQL job to run SSIS using SQL Agent Service Account and also how to create a proxy to run under a different using different credentials.
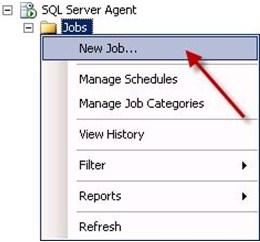
- Go to SQL Server Management Studio. ExpandSQL Server Agent and right-click on Jobs, then select New Job… as shown in screenshot #1.
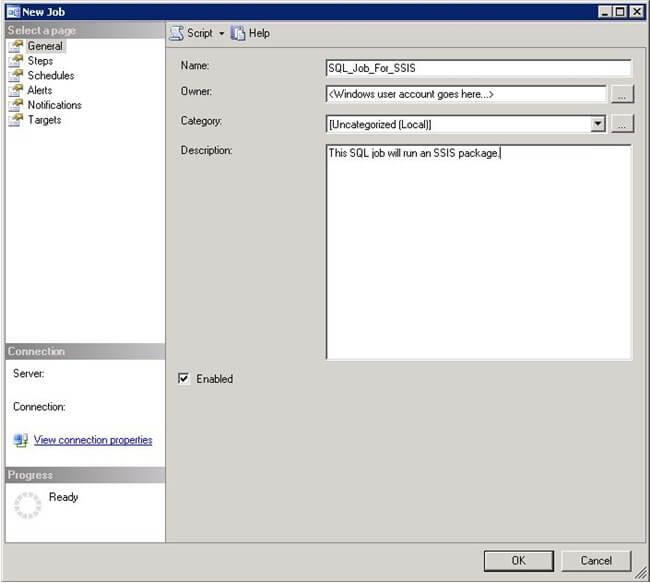
- Provide a name and the Owner by default will be the account that creates the job but you can change it according to your requirements. Assign a Category if you would like to and also provide a description. Refer to screenshot #2.
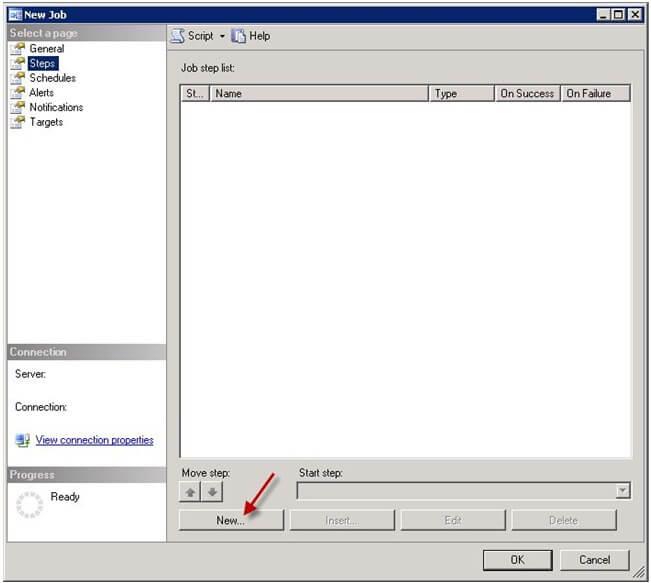
- On the Steps section, click.. as shown in screenshot #3.
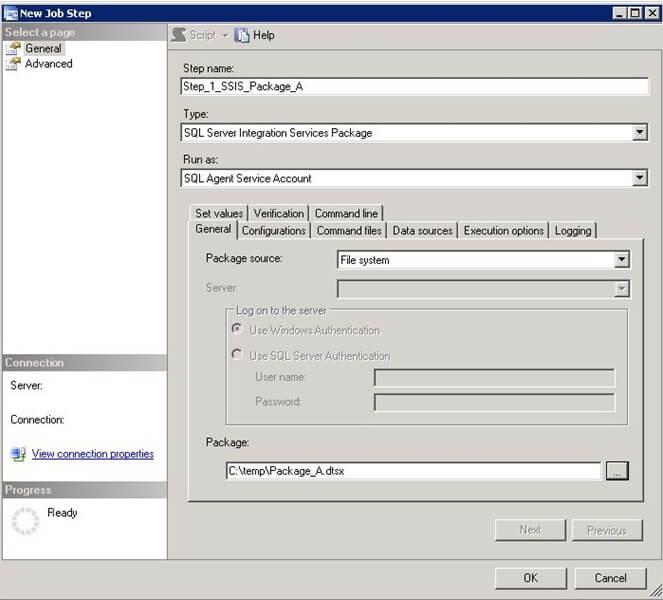
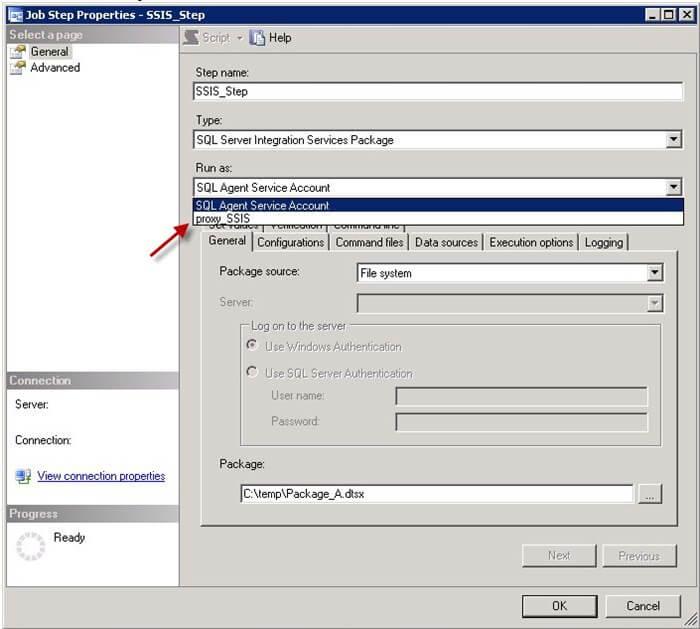
- On the New Job Step dialog, provide a Step name. SelectSQL Server Integration Services Package from Type. This step will run under the SQL Agent Service Account by default. Select thepackage source as a File system and browse to the package path by clicking on ellipsis. This will populate the Package path. Refer to screenshot #4.
- If you don’t want the step to execute under the SQL Agent Service Account, then refer the steps #8 – 9 to know how you can use a different account.
- If you have an SSIS configuration file (.dtsConfig) for the package, click on the configuration tab and add the configuration file as shown in screenshot #5.
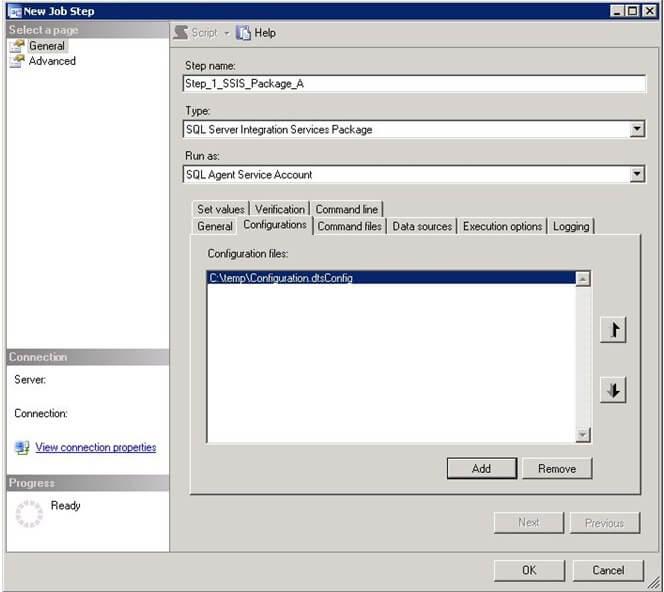
- Click OK and there is the package in step 1 as shown in screenshot #6. Similarly, you can create different steps.
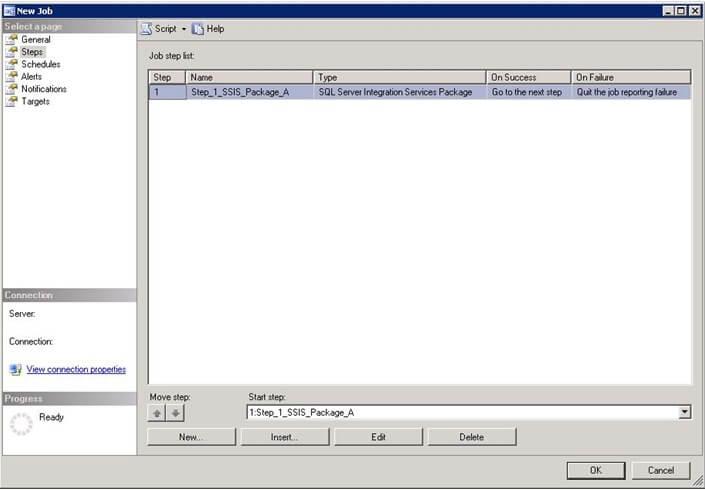
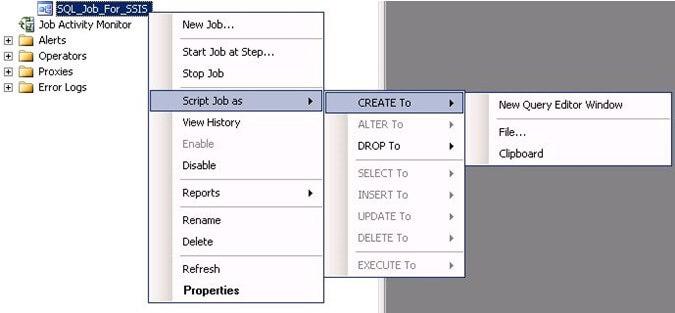
- Once the job has been created, you can right-click on the job and select script Job as –> CREATE To –> New Query Editor Window to generate the script as shown in screenshot #7.
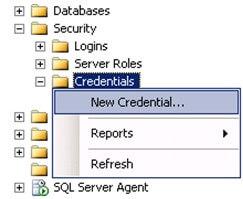
- To run the SSIS step under different accounts, on the Management Studio, navigate to security –> right-click on Credentials –> select New Credential… as shown in screenshot #8.
- On the Credential dialog, provide a Credential name, Windows account, and Password under which you would like to execute SSIS steps in SQL jobs. Refer to screenshot #9.
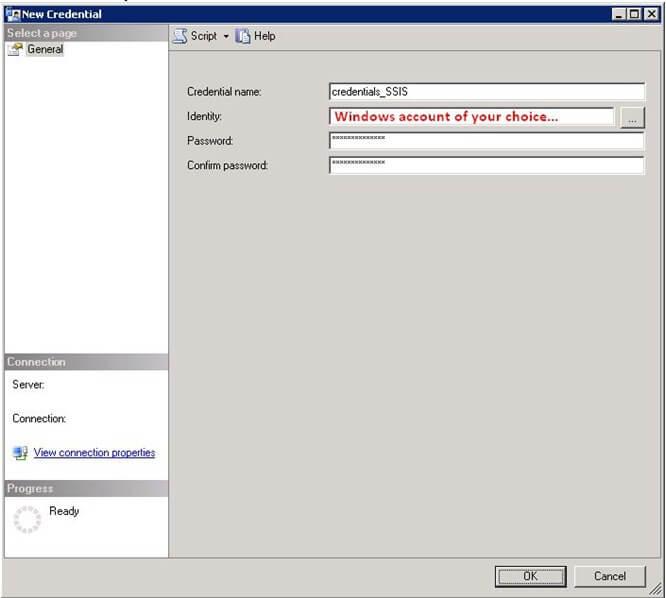
- The credential will be created as shown in screenshot #10.
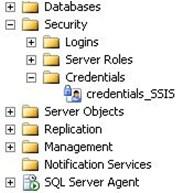
- Next, we need to create a proxy. On the Management Studio, navigate to SQL Server Agent –> Proxies –> right-click on SSIS Package Execution –> select New Proxy… as shown in screenshot #11.
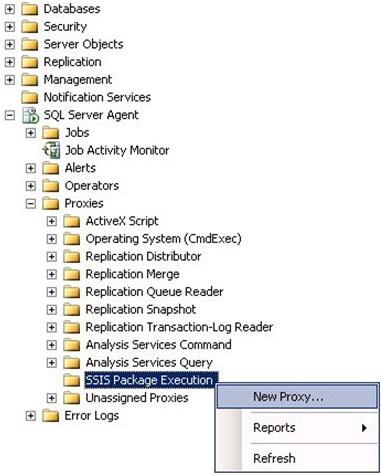
- On the New Proxy Account window, provide a Proxy name, select the newly created Credential, provide a description and select SQL Server Integration Services Package as shown in screenshot #12.
- The proxy account should be created as shown in screenshot #13.
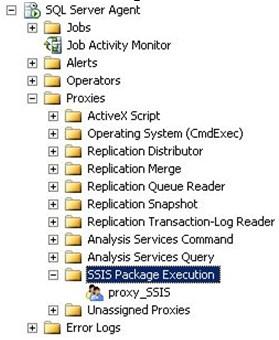
- Now, if you go back to the step in SQL job, you should see the newly created Proxy account in theRun asdrop down. Refer screenshot #14.
41. Overhead of varchar(max) columns with small data?
Ans: VARCHAR(MAX) column values will be stored IN the table row, space permitting. So if you have a single VARCHAR(MAX) field and it’s 200, 300 bytes, chances are it’ll be stored inline with the rest of your data. No problem or additional overhead here.
Only when the entire data of a single row cannot fit on a single SQL Server page (8K) anymore, only then will SQL Server move VARCHAR(MAX) data into overflow pages.
So all in all, I think you get the best of both worlds – inline storage when possible, overflow storage when necessary.
42. SSIS connection manager not storing SQL password, how will you resolve the issue?
Ans: That answer points to this article: SSIS package problem
Here are the proposed solutions – have you evaluated them?
Method 1: First, we must create an SQL Server Agent proxy account. The account will allow the SQL server to run the job using credentials. This account and the account created in the package should be the same. This method can decrypt sensitive information and meet users' critical requirements. This method has some limitations when we move packages from one computer to another.
Method 2: We set the SSIS package ProtectionLevel property to ServerStorage in this method. It allows packages to be stored in the SQL Server database. Also, it allows access control through SQL Server database roles.
Method 3: In this method, we must set the first set of the SSIS package ‘ProtectionLevel’ property. We must set this property as ‘EncryptSensitiveWithPassword’. So, we must use a password for encryption. We must change the ‘SQL Server Agent job step’ command line to use the password.
Method 4: In this method, we use the SSIS package configuration files to store sensitive data. We store the data in a secured folder. If we don’t want to encrypt the package, we must change the ‘ProtectionLevel’ property to ‘Don’tSaveSensitive’ status. The needed information is taken from the configuration file when we run the SSIS package.
Method 5: We must create a package template with a protection level. It must differ from the default settings.
43. Advantages of using SSIS packages over stored procedures?
Ans: If your ETL is mostly E and L, with very little T, and if you can write your SPs so they don’t rely on cursors, then going the SP-only route is probably fine.
For more complex processes, particularly those that involve heavy transforms, slowly changing dimensions, data mining lookups, etc, SSIS has three advantages.
First, it manages memory very efficiently, which can result in big performance improvements compared to T-SQL alone.
Second, the graphical interface lets you build large, complex, and reliable transform much more easily than hand-crafted T-SQL.
And third, SSIS lets you more easily interact with additional external sources, which can be very handy for things like data cleansing.
44. How do you get an SSIS package to only insert new records when copying data between servers?
Ans: You are copying some user data from one SQL Server to another. We can call them Alpha and Beta. The SSIS package runs on Beta and gets the Alpha rows that meet a specific condition. The package then adds the rows to Beta's table.
Now, you want to add new rows to the Beta. You can use the code below.
But this doesn’t work in an SSIS package. How will you resolve this problem?
We are adding only new people and are not looking for changed data in existing records. So, we need to store the last ID in the DB. The below code will help us.
Now, we can use the code below to insert the row's last ID transferred.
When selecting the OLEDB source, set the data access mode to SQL Command and apply the below code.
Hope you are using ID int IDENTITY for your Primary Key. We must have the "last changed" column in every table to monitor for data changes in existing records. Besides, we need to store the time of the last transfer.
35. How would one go about doing this across servers?
Ans: Your example seems simple, it looks like you are adding only new people, not looking for changed data in existing records. In this case, store the last ID in the DB.
CREATE TABLE dbo.LAST (RW int, LastID Int)
go
INSERT INTO dbo.LAST (RW, LastID) VALUES (1,0)
Now you can use this to insert the last ID of the row transferred.
UPDATE dbo.LAST SET LastID = @myLastID WHERE RW = 1
When selecting OLEDB source, set data access mode to SQL Command and use
DECLARE @Last int
SET @Last = (SELECT LastID FROM dbo.LAST WHERE RW = 1)
SELECT * FROM AlphaPeople WHERE ID > @Last;
Note, I do assume that you are using ID int IDENTITY for your PK.
If you have to monitor for data changes of existing records, then have the “last changed” column in every table, and store the time of the last transfer.
A different technique would involve setting up a linked server on Beta to Alpha and running your example without using SSIS. I would expect this to be way slower and more resource-intensive than the SSIS solution.
INSERT INTO dbo.BetaPeople
SELECT * FROM [Alpha].[myDB].[dbo].[AlphaPeople]
WHERE ID NOT IN (SELECT ID FROM dbo.BetaPeople)
46. Does anyone have any good SSIS Best-Practices tips and suggestions?
Ans: There is a 4000-character limit to the DT_WSTR (Unicode string) data type used by SSIS. Since expressions are converted to DT_WSTR, they also cannot exceed 4000 characters.
You’ll get an error if you exceed the limit at design time. However, you will not receive any obvious warnings or errors if you do so at run time. The operation will fail silently, and the expression may be evaluated incorrectly.
Note: this does not mean that strings or SSIS variables cannot exceed 4000 characters. The limitation only applies to expressions and other places that DT_WSTR is used.
Here’s an example that reproduces the issue:
- Create an SSIS string variable named test variable.
- Assign the variable a long value in a script task (5000 characters, for instance). The assignment should succeed.
- Create a second task and connect the two tasks using a precedence constraint. Set the evaluation operation to “Expression” and set the expression to @testVariable != “”.
Even though the variable is not empty, the constraint will incorrectly evaluate to False because the expression exceeds 4000 characters. However, this will not cause any errors and the package will not fail.
If you notice strange behavior in your SSIS logic, take a look at your expressions and ensure that they don’t exceed 4000 characters when evaluated.
47. SSIS SQL Task – “Parameter name is unrecognized”?
Ans: I have a SQL Task that needs to run a simple update to update a single row.
I have set the SQLStatement to:
update agency set AgencyLastBatchSeqNo = ? where agencyID = ?
On the Parameter Mapping page, I gave set Parameter 0 and Parameter 1 to variables that I know contain the right values. I have also set the Parameter Name values correctly.
In the database, the column AgencyLastBatchSeqNo is an int, AgencyID is a big int. Does anyone have a reference to find what the data types map to in SSIS? I have guessed at SHORT for the int and LONG for the big int.
When I run the task I get the following error:
[Execute SQL Task] Error: Executing the query “update agency set AgencyLastBatchSeqNo = ? where AgencyID = ?” failed with the following error: “Parameter name is unrecognized.”. Possible failure reasons: Problems with the query, “ResultSet” property not set correctly, parameters not set correctly, or connection not established correctly.
48. Could anyone please suggest what may be wrong?
Ans: The answer to this is to change the Parameter Name value in the Parameter Mapping screen.
Given the following query
SELECT Id, AnimalName FROM dbo.Farm WHERE Farm_id =?
Assuming my Parameter is an integer Variable named User:: Farm_id
Choose the following values on the Parameter Mapping Screen
Variable Name: User::Farm_id
Direction: Input
Data Type: LONG
Parameter Name: 0
Parameter Size: -1
Originally the Parameter Name will be “NewParameterName”. Simply change this to the ordinal position of your variable marker (“?”)
49. Difference Between Persist Security Info And Integrated Security?
Ans: Persist Security = true means that the Password used for SQL authentication is not removed from the ConnectionString property of the connection.
When Integrated Security = true is used then the Persist Security is completely irrelevant since it only applies to SQL authentication, not to windows/Integrated/SSPI.
50. SSIS Script Component Write to Variable?
Ans: From MS:
In Script component code, you use typed accessor properties to access certain package features such as variables and connection managers.
The PreExecute method can access only read-only variables. The PostExecute method can access both read-only and read/write variables.
For more information about these methods, see Coding and Debugging the Script Component. Comparing the Script Task and the Script Component
It looks like Dts is only available in the Script Task.
Here is what the code looks like:
Skip code block
Imports System
Imports System.Data
Imports System.Math
Imports Microsoft.SqlServer.Dts.Runtime
Imports Microsoft.SqlServer.Dts.Pipeline.Wrapper
Imports Microsoft.SqlServer.Dts.Runtime.Wrapper
Public Class ScriptMain
Inherits UserComponent
Dim updateSQL As String
Public Overrides Sub PostExecute()
Me.ReadWriteVariables(“SQL_ATTR_Update”).Value = “Test”
End Sub
Public Overrides Sub Input0_ProcessInputRow(ByVal Row As Input0Buffer)
‘updateSQL = Row.ITMID + Row.PRCCAT
End Sub
End Class51. SSIS – How to access a RecordSet variable inside a Script Task?
Ans: On the script tab, make sure you put the variable in either the read-only variables or readwritevariables text boxes.
Here is a simple script that I use to format the errors in a data flow (saved in a RecordSet Variable) into the body of an email. Basically, I read the record set variable into a data table and process it row by row with the for loops. After this task completes I examine the value of uvErrorEmailNeeded to determine if there is anything to email using a conditional process flow connector. You will also need to add a reference to system.xml in your vb script. This is in SQL 2005.
Code block
Imports System
Imports System.Data
Imports System.Math
Imports Microsoft.SqlServer.Dts.Runtime
Imports System.Xml
Imports System.Data.OleDb
Public Class ScriptMain
Public Sub Main()
Dim oleDA As New OleDbDataAdapter
Dim dt As New DataTable
Dim col As DataColumn
Dim row As DataRow
Dim sMsg As String
Dim sHeader As String
oleDA.Fill(dt, Dts.Variables(“uvErrorTable”).Value)
If dt.Rows.Count > 0 Then
Dts.Variables(“uvErrorEmailNeeded”).Value = True
For Each col In dt.Columns
sHeader = sHeader & col.ColumnName & vbTab
Next
sHeader = sHeader & vbCrLf
For Each row In dt.Rows
For Each col In dt.Columns
sMsg = sMsg & row(col.Ordinal).ToString & vbTab
Next
sMsg = sMsg & vbCrLf
Next
Dts.Variables(“uvMessageBody”).Value = “Error task. Error list follows:” & vbCrLf & sHeader& sMsg & vbCrLf & vbCrLf
End I
Dts.TaskResult = Dts.Results.Success
End Sub
End Class52. SSIS 2008 Rows per batch and Maximum insert commit size?
Ans: There is no best value, it depends greatly on the design of the database, the number of users, the kind of hardware you are operating one, etc. That is why you need to test for yourself with your system.
53. Where are SSIS Packages Saved?
Ans: If you connect to the Integration Services instance on the server (a different choice in the dropdown from “Database Engine” when you connect in SQL Server Management Studio), they’ll be under the MSDB folder under Stored Packages.
When you start management studio and connect to a database, make sure you have the server type set to Integration Services instead of Database Engine.
54. selectively execute the task in SSIS control flow?
Ans: Between your control flow tasks, click on the arrow and choose Edit. When you do this, you get a dialog that allows you to check the “constraint” (success, completion or failure) of the task, an “expression” (i.e. you can have your execute SQL task return a value, store that value in a variable, and check the value of that variable in an expression to determine whether to continue down the path you are editing), an “expression and a constraint”, and an “expression or a constraint”.
These last two are the same except for the logic. “Expression and constraint” requires a true condition on both the expression and the constraint, “expression or constraint” requires a true condition on only one of the expressions and the constraint.
55. SSIS PrimeOutput Error?
Ans: We have an SSIS job that has been running for over a year with no issue. The job takes a data set from a select statement in an oracle db and transfers the result to a table on a SQL Server 2005 instance.
As of this morning, we receive the following error message:
Error: 2010-05-26 05:06:47.71 Code: 0xC02090F5 Source: [job_name] DataReader Source [793] Description: The component “DataReader Source” (793) was unable to process the data. End Error Error: 2010-05-26 05:06:47.71 Code: 0xC0047038 Source: job_name Description: SSIS Error Code DTS_E_PRIMEOUTPUTFAILED.
The PrimeOutput method on component “DataReader Source” (793) returned error code 0xC02090F5. The component returned a failure code when the pipeline engine called PrimeOutput(). The meaning of the failure code is defined by the component, but the error is fatal and the pipeline stopped executing. There may be error messages posted before this with more information about the failure. End Error Error: 2010-05-26 05:06:47.71 Code: 0xC0047021 Source: P… The package execution fa… The step failed.
56. Does anyone know what a root cause might be?
Ans: There may be error messages posted before this with more information about the failure.
Did you look for other more specific error messages?
Are you logging errors or steps as they run? If so did you look in the logging table? If you aren’t logging in your SSIS package, I’d set that up as part of this fix, it will make it immeasurably easier to find the problem.
Things I would consider: schema changes, permissions changes, any recent software, operating systems updates to the servers involved, data mismatches (the first time perhaps that the Oracle table held data that couldn’t be inserted into the SQL table – check columns that don't directly match first, string data that might get truncated, dates stored as strings that need to convert to DateTime, etc.).
57. Advantage of SSIS package over windows scheduled exe?
Ans: Do you mean what are the pros and cons of using SQL Server Agent Jobs for scheduling running SSIS packages and command shell executions? I don’t really know the pros of windows scheduler, so I’ll stick to listing the pros of SQL Server Agent Jobs.
- If you are already using SQL Server Agent Jobs on your server, then running SSIS packages from the agent consolidates the places that you need to monitor to one location.
- SQL Server Agent Jobs have built-in logging and notification features. I don’t know how Windows Scheduler performs in this area.
- SQL Server Agent Jobs can run more than just SSIS packages. So you may want to run a T-SQL command as step 1, retry if it fails, eventually move to step 2 if step 1 succeeds, or stop the job and send an error if the step 1 condition is never met. This is really useful for ETL processes where you are trying to monitor another server for some condition before running your ETL.
- SQL Server Agent Jobs are easy to report on since their data is stored in the msdb database. We have regularly scheduled subscriptions for SSRS reports that provide us with data about our jobs. This means I can get an email each morning before I come into the office that tells me if everything is going well or if there are any problems that need to be tackled ASAP.
- SQL Server Agent Jobs are used by SSRS subscriptions for scheduling purposes. I commonly need to start SSRS reports by calling their job schedules, so I already have to work with SQL Server Agent Jobs.
- SQL Server Agent Jobs can be chained together. A common scenario for my ETL is to have several jobs run on a schedule in the morning. Once all the jobs succeed, another job is called that triggers several SQL Server Agent Jobs. Some jobs run in parallel and some run serially.
- SQL Server Agent Jobs are easy to script out and load into our source control system. This allows us to roll back to earlier versions of jobs if necessary. We’ve done this on a few occasions, particularly when someone deleted a job by accident.
On one occasion we found a situation where Windows Scheduler was able to do something we couldn’t do with a SQL Server Agent Job. During the early days after a SAN migration, we had some scripts for snapshotting and cloning drives that didn’t work in a SQL Server Agent Job.
So we used a Windows Scheduler task to run the code for a while. After about a month, we figured out what we were missing and were able to move the step back to the SQL Server Agent Job.
Regarding SSIS over exe stored procedure calls.
- If all you are doing is running stored procedures, then SSIS may not add much for you. Both approaches work, so it really comes down to the differences between what you get from a .exe approach and SSIS as well as how many stored procedures are being called.
- I prefer SSIS because we do so much on my team where we have to download data from other servers, import/export files, or do some crazy https posts. If we only had to run one set of processes and they were all stored procedure calls, then SSIS may have been overkill.
- For my environment, SSIS is the best tool for moving data because we move all kinds of types of data to and from the server. If you ever expect to move beyond running stored procedures, then it may make sense to adopt SSIS now.
- If you are just running a few stored procedures, then you could get away with doing this from the SQL Server Agent Job without SSIS. You can even parallelize jobs by making a master job start several jobs via msdb.dbo.sp_start_job ‘Job Name’.
- If you want to parallelize a lot of stored procedure calls, then SSIS will probably beat out chaining SQL Server Agent Job calls. Although chaining is possible in code, there’s no visual surface and it is harder to understand complex chaining scenarios that are easy to implement in SSIS with sequence containers and precedence constraints.
- From a code maintainability perspective, SSIS beats out any exe solution for my team since everyone on my team can understand SSIS and few of us can actually code outside of SSIS. If you are planning to transfer this to someone down the line, then you need to determine what is more maintainable for your environment.
- If you are building in an environment where your future replacement will be a .NET programmer and not a SQL DBA or Business Intelligence specialist, then SSIS may not be the appropriate code-base to pass on to a future programmer.
- SSIS gives you out-of-the-box logging. Although you can certainly implement logging in code, you probably need to wrap everything in try-catch blocks and figure out some strategy for centralizing logging between executables. With SSIS, you can centralize logging to a SQL Server table, log files in some centralized folder, or use another log provider.
- Personally, I always log to the database and I have SSRS reports set up to help make sense of the data. We usually troubleshoot individual job failures based on the SQL Server Agent Job history step details. Logging from SSIS is more about understanding long-term failure patterns or monitoring warnings that don’t result in failures like removing data flow columns that are unused (early indicator for us of changes in the underlying source data structure) or performance metrics (although stored procedures also have a separate form of logging in our systems).
- SSIS gives you a visual design surface. I mentioned this before briefly, but it is a point worth expanding upon on its own. BIDS is a decent design surface for understanding what’s running in what order. You won’t get this from writing do-while loops in code.
- Maybe you have some form of a visualizer that I’ve never used, but my experience with coding stored procedure calls always happened in a text editor, not in a visual design layer. SSIS makes it relatively easy to understand the precedence and order of operations in the control flow which is where you would be working if you are using execute sql tasks.
- The deployment story for SSIS is pretty decent. We use BIDS Helper (a free add-in for BIDS), so deploying changes to packages is a right-click away on the Solution Explorer. We only have to deploy one package at a time. If you are writing a master executable that runs all the ETL, then you probably have to compile the code and deploy it when none of the ETL is running.
- SSIS packages are modular code containers, so if you have 50 packages on your server and you make a change in one package, then you only have to deploy the one changed package. If you set up your executable to run code from configuration files and don’t have to recompile the whole application, then this may not be a major win.
- Testing changes to an individual package is probably generally easier than testing changes in an application. Meaning, if you change one ETL process in one part of your code, you may have to regression test (or unit test) your entire application. If you change one SSIS package, you can generally test it by running it in BIDS and then deploying it when you are comfortable with the changes.
- If you have to deploy all your changes through a release process and there are pre-release testing processes that you must pass, then an executable approach may be easier. I’ve never found an effective way to automatically unit test an SSIS package. I know there are frameworks and test harnesses for doing this, but I don’t have any experience with them so I can’t speak for the efficacy or ease of use. In all of my work with SSIS, I’ve always pushed the changes to our production server within minutes or seconds of writing the changes.
Let me know if you need me to elaborate on any points. Good luck!
58. SSIS, outputting null as a column value within a script task?
Ans: Every column has a boolean property called ColumnName_IsNull (in your case should be Row.ID_IsNull). I think you should set it to true to set the columns value NULL
59. How to create a temporary table in the SSIS control flow task and then use it in the data flow task?
Ans: Set the property RetainSameConnection on the Connection Manager to True so that a temporary table created in one Control Flow task can be retained in another task.
Here is a sample SSIS package is written in SSIS 2008 R2 that illustrates using temporary tables.
Walkthrough:
Create a stored procedure that will create a temporary table named ##tmpStateProvince and populate with few records. The sample SSIS package will first call the stored procedure and then will fetch the temporary table data to populate the records into another database table.
The sample package will use the database named Sora Use the below create stored procedure script.
Skip code block
USE Sora;
GO
CREATE PROCEDURE dbo.PopulateTempTable
AS
BEGIN
SET NOCOUNT ON;
IF OBJECT_ID(‘TempDB..##tmpStateProvince’) IS NOT NULL
DROP TABLE ##tmpStateProvince;
CREATE TABLE ##tmpStateProvince
(
CountryCode nvarchar(3) NOT NULL
, StateCode nvarchar(3) NOT NULL
, Name nvarchar(30) NOT NULL
);
INSERT INTO ##tmpStateProvince
(CountryCode, StateCode, Name)
VALUES
(‘CA’, ‘AB’, ‘Alberta’),
(‘US’, ‘CA’, ‘California’),
(‘DE’, ‘HH’, ‘Hamburg’),
(‘FR’, ’86’, ‘Vienne’),
(‘AU’, ‘SA’, ‘South Australia’),
(‘VI’, ‘VI’, ‘Virgin Islands’);
END
GOCreate a table named dbo.StateProvince that will be used as the destination table to populate the records from the temporary table. Use the below create table script to create the destination table.
Skip code block
USE Sora;
GO
CREATE TABLE dbo.StateProvince
(
StateProvinceID int IDENTITY(1,1) NOT NULL
, CountryCode nvarchar(3) NOT NULL
, StateCode nvarchar(3) NOT NULL
, Name nvarchar(30) NOT NULL
CONSTRAINT [PK_StateProvinceID] PRIMARY KEY CLUSTERED
([StateProvinceID] ASC)
) ON [PRIMARY];
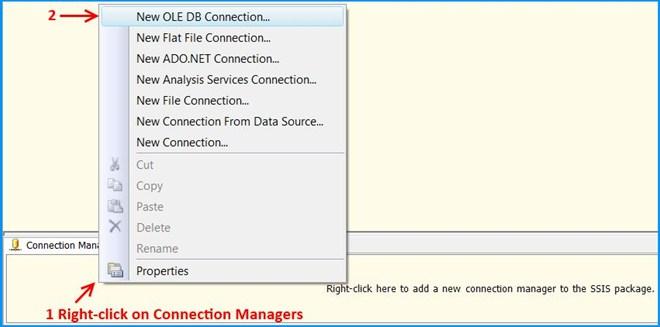
GOCreate an SSIS package using Business Intelligence Development Studio (BIDS). Right-click on the Connection Managers tab at the bottom of the package and click New OLE DB Connection… to create a new connection to access SQL Server 2008 R2 database.
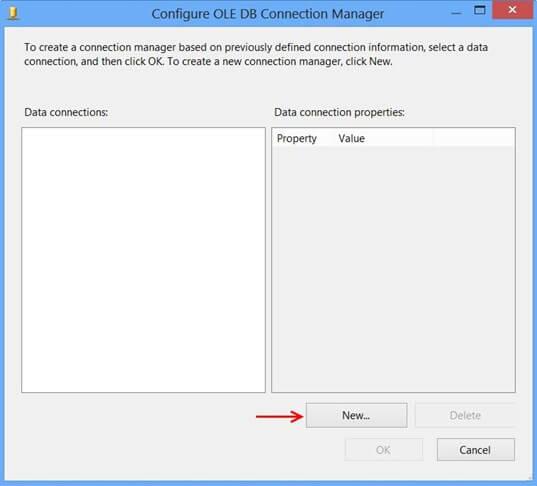
Click New… on Configure OLE DB Connection Manager.
Perform the following actions on the Connection Manager dialog.
-
SelectNative OLE DBSQL Server Native Client 10.0 from Provider since the package will connect to SQL Server 2008 R2 database
-
Enter theServer name, like MACHINENAMEINSTANCE
-
SelectUse Windows Authentication from Log on to the server section or whichever you prefer.
-
Select the database from select or enter a database name, the sample uses the database name Sora.
-
ClickTest Connection
-
ClickOK on the Test connection succeeded
-
ClickOK on Connection Manager
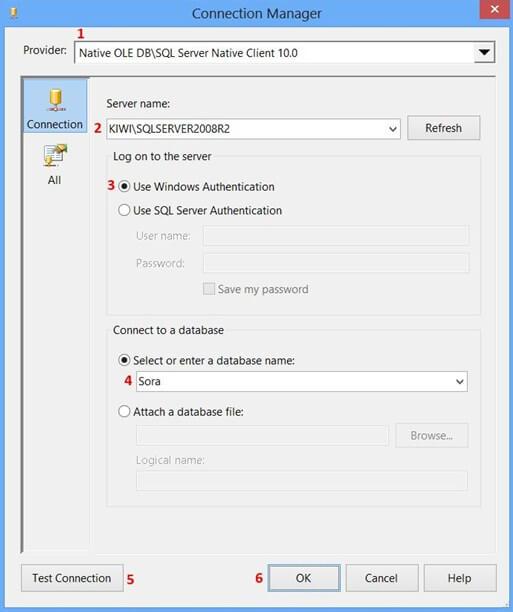
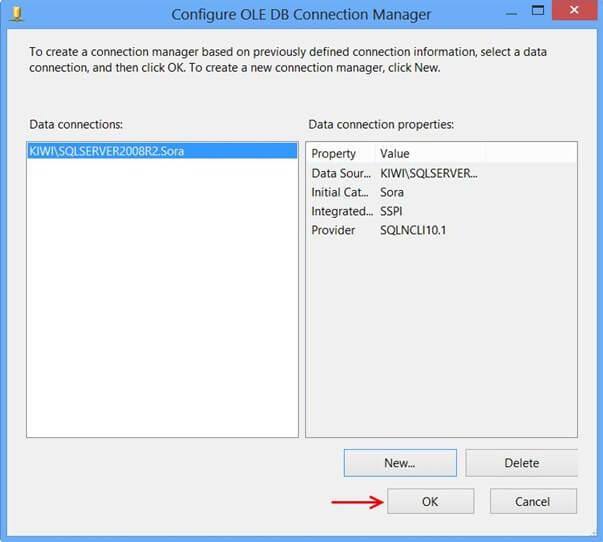
The newly created data connection will appear on Configure OLE DB Connection Manager. ClickOK.
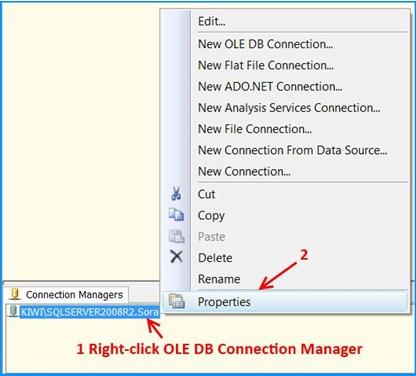
OLE DB connection manager KIWISQLSERVER2008R2.Sora will appear under the Connection Manager tab at the bottom of the package. Right-click the connection manager and click Properties
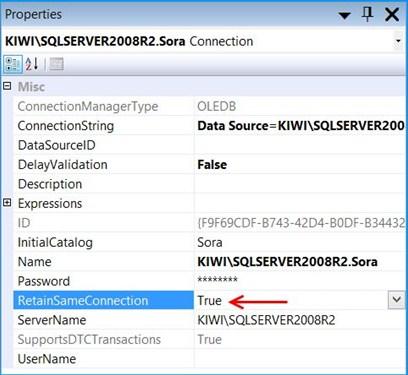
Set the property RetainSameConnection on the connection KIWISQLSERVER2008R2.Sora to the value True.
Right-click anywhere inside the package and then click Variables to view the variables pane. Create the following variables.
A new variable namedPopulateTempTable of data type String in the package scopeSO_5631010 and set the variable with the value EXEC dbo.PopulateTempTable.
A new variable namedFetchTempData of data type String in the package scope SO_5631010and set the variable with the value SELECT CountryCode, StateCode, Name FROM ##tmpStateProvince

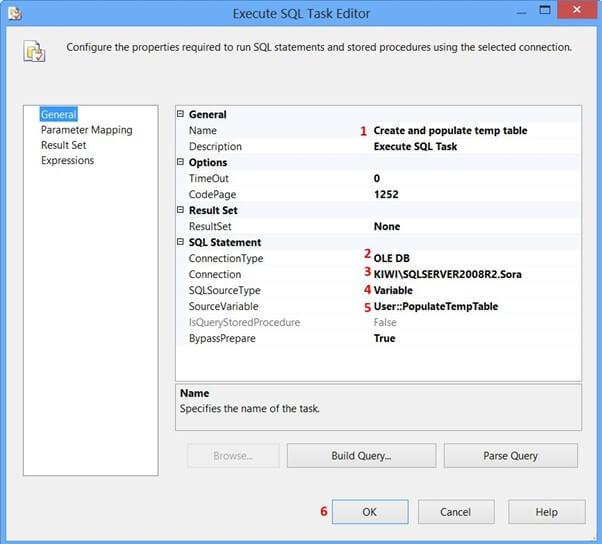
Drag and drop an Execute SQL Task onto the Control Flow tab. Double-click the Execute SQL Task to view the Execute SQL Task Editor.
On the General page of the Execute SQL Task Editor, perform the following actions.
-
Set the name to Create and populate a temp table
-
Set the connection Type to OLE DB
-
Set the connection to KIWISQLSERVER2008R2.Sora
-
SelectVariable from SQLSourceType
-
SelectUser::PopulateTempTable from SourceVariable
ClickOK
Drag and drop a Data Flow Task onto the Control Flow tab. Rename the Data Flow Task as Transfer temp data to a database table. Connect the green arrow from the Execute SQL Task to the Data Flow Task.
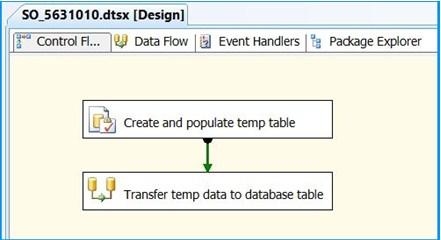
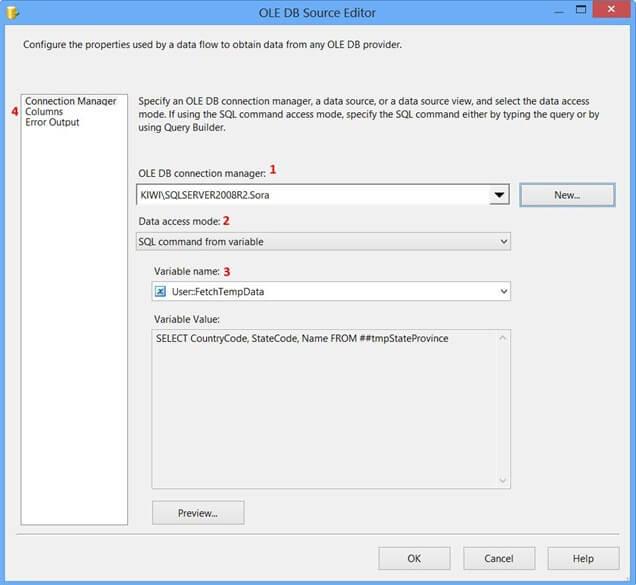
Double-click the Data Flow Task to switch to the Data Flow tab. Drag and drop an OLE DB Source onto the Data Flow tab. Double-click OLE DB Source to view the OLE DB Source Editor.
On the Connection Manager page of the OLE DB Source Editor, perform the following actions.
-
SelectKIWISQLSERVER2008R2.Sora from OLE DB Connection Manager
-
SelectSQL command from variable from Data access mode
-
SelectUser::FetchTempData from Variable name
-
ClickColumns page
Clicking the Columns page on OLE DB Source Editor will display the following error because the table##tmpStateProvince specified in the source command variable does not exist and SSIS is unable to read the column definition.
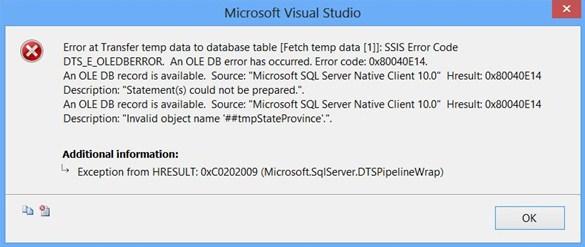
To fix the error, execute the statement EXEC dbo.PopulateTempTable using SQL Server Management Studio (SSMS) on the database Sora so that the stored procedure will create the temporary table. After executing the stored procedure, click the Columns page on OLE DB Source Editor, you will see the column information. Click OK.
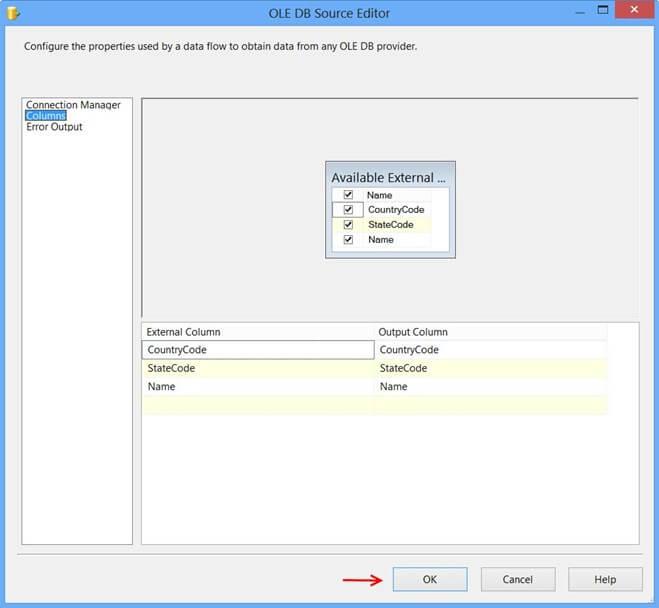
Drag and drop OLE DB Destination onto the Data Flow tab. Connect the green arrow from OLE DB Source to OLE DB Destination. Double-click OLE DB Destination to open OLE DB Destination Editor.
On the Connection Manager page of the OLE DB Destination Editor, perform the following actions.
-
SelectKIWISQLSERVER2008R2.Sora from OLE DB Connection Manager
-
selectable or view – fast load from Data access mode
-
Select[dbo].[StateProvince] from Name of the table or the view
-
ClickMappings page
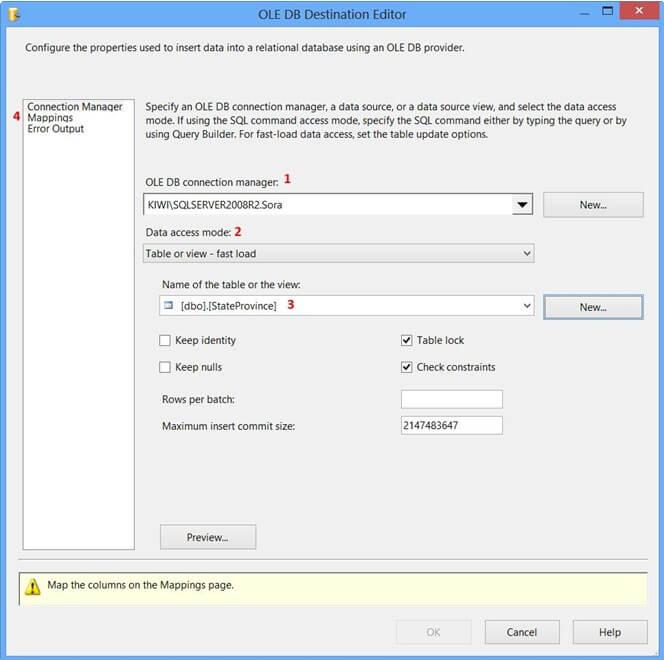
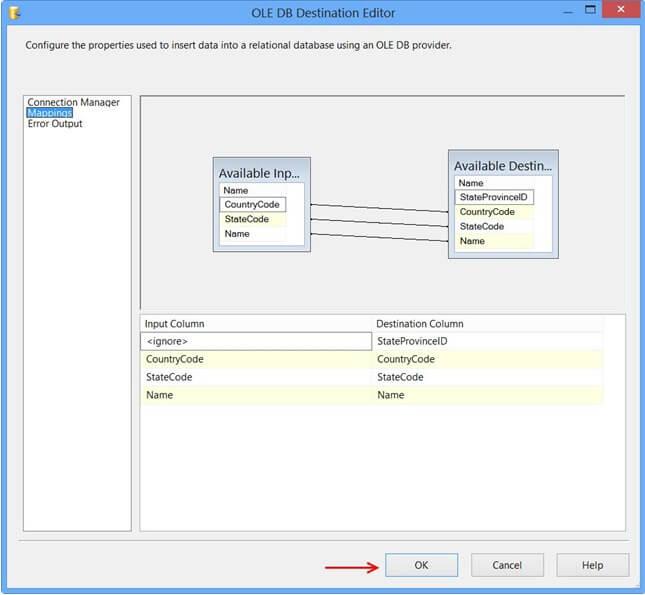
Click Mappings page on the OLE DB Destination Editor would automatically map the columns if the input and output column names are the same. Click OK. Column StateProvinceID does not have a matching input column and it is defined as an IDENTITY column in the database. Hence, no mapping is required.
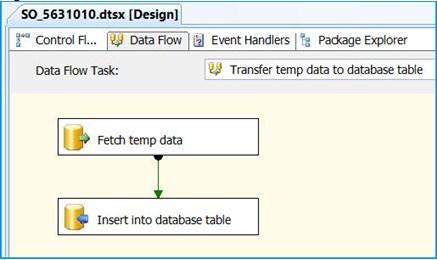
Data Flow tab should look something like this after configuring all the components.
Click the OLE DB Source on the Data Flow tab and press F4 to view Properties. Set the propertyValidateExternalMetadata to False so that SSIS would not try to check for the existence of the temporary table during the validation phase of the package execution.
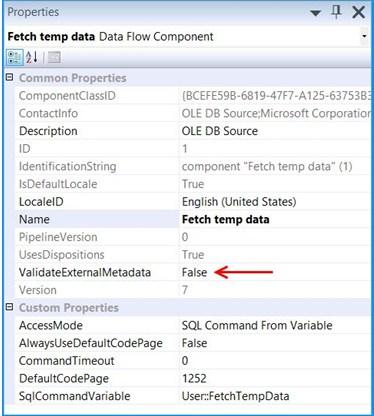
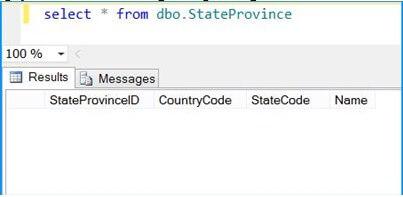
Execute the query select * from dbo.StateProvince in the SQL Server Management Studio (SSMS) to find the number of rows in the table. It should be empty before executing the package.
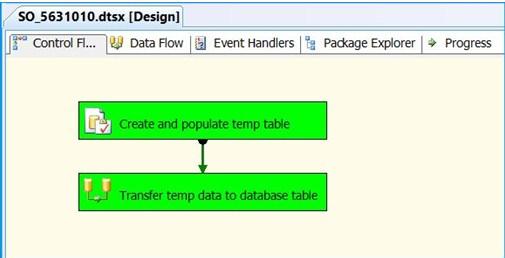
Execute the package. Control Flow shows successful execution.
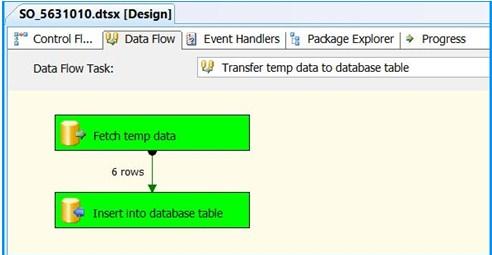
In Data Flow tab, you will notice that the package successfully processed 6 rows. The stored procedure created early in this posted inserted 6 rows into the temporary table.
Execute the query select * from dbo.StateProvince in the SQL Server Management Studio (SSMS) to find the 6 rows successfully inserted into the table. The data should match with rows founds in the stored procedure.
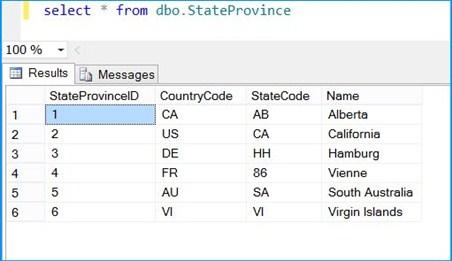
The above example illustrated how to create and use a temporary table within a package.
60. How to check the SSIS package job results after it has completed its execution?
Ans: If you are just interested in knowing the columns being processed and not interested in the info for further use, one possible option is making use of the SSIS logging feature. Here is how it works for data flow tasks.
- Click on the SSIS package.
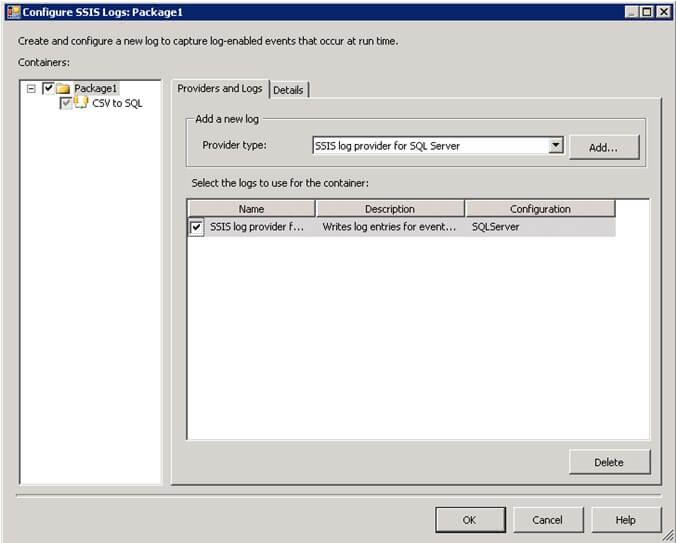
- On the menus, select SSIS –> Logging…
- On the ConfigureSSIS Logs: dialog, select the provider type and click Add. I have chosen SQL Server for this example. Check the Name checkbox and provide the data source under the Configuration column. Here SQLServer is the name of the connection manager. SSIS will create a table named sysssislog and stored procedure dbo.sp_ssis_addlogentry in the database that you selected. Refer to screenshot #1 below.
- If you need the rows processed, select the checkbox OnInformation. Here in the example, the package executed successfully so the log records were found under OnInformation. You may need to fine-tune this event selection according to your requirements. Refer screenshot #2
- Here is a sample package execution within the data flow task. Refer screenshot #3
- Here is a sample output of the log table dbo.sysssislog. I have only displayed the columnsid and message. There are many other columns in the table. In the query, I am filtering the output only for the package named ‘Package1‘ and the event ‘OnInformation‘. You can notice that records with ids 7, 14 and 15 contain the rows processed. Refer screenshot #4
I hope that helps.
Screenshot #1:
Frequently Asked Questions
1. Is SSIS easy to learn?
Yes, learning SSIS is a cakewalk. Anyone can quickly learn to design SSIS packages and make data integration effortlessly. MindMajix offers SSIS training by highly skilled trainers with industry-designed course modules. Once you complete the training, you will become job-ready and stay ahead of the curve.
2. Is SSIS still relevant in 2024?
Yes, learning SSIS is relevant in 2024. First and foremost, learning SSIS is not time-consuming. You can easily integrate ETL processes and data with SSIS. Above all, big data and data analysis are the buzzwords today. SSIS greatly helps to transfer and transform data.
3. Which companies hire SSIS developers?
According to AmbitionBox, Accenture, TCS, Cognizant, Infosys, LTIMindtree, Wipro, Infosys, Deloitte, etc., companies hire SSIS developers for attractive salaries.
4. Is SSIS a good ETL tool?
Yes, SSIS is a good ETL tool. SSIS is the best tool for developers to manage a large volume of complex data. With SSIS, you can create, schedule, and manage data integration efficiently. SSIS employs a virtual design interface that you can use to create packages to define ETL workflows.
5. What are the advantages of SSIS?
Jotted down are the advantages of SSIS.
- SSIS supports various data sources and formats
- It offers a broad range of transformation components
- It enables complex workflow orchestration
- It provides robust error handling and troubleshooting
- It integrates with SQL server databases and services seamlessly.
Conclusion:
It’s time to wrap! We hope this blog’s SSIS interview questions have given you a broad knowledge of SSIS packages, data transformations, ETL design, database design and development, and many more. Now, you are ready to face your SSIS interviews with ultimate confidence.
However, if you go through professional SSIS training, it will help boost your SSIS skills and simplify your efforts to clear SSIS interviews. MindMajix offers top-rated SSIS training, which you can register and gain certification. It will help you elevate your SSIS skills to new heights and make a lot of success stories in your career.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| SSIS Training | Jul 18 to Aug 02 | View Details |
| SSIS Training | Jul 21 to Aug 05 | View Details |
| SSIS Training | Jul 25 to Aug 09 | View Details |
| SSIS Training | Jul 28 to Aug 12 | View Details |

Ravindra Savaram is a Technical Lead at Mindmajix.com. His passion lies in writing articles on the most popular IT platforms including Machine learning, DevOps, Data Science, Artificial Intelligence, RPA, Deep Learning, and so on. You can stay up to date on all these technologies by following him on LinkedIn and Twitter.














