
- SSIS SQL Server Editions
- SSIS Data Flow Destinations
- SSIS Interview Questions
- SSIS Tutorial
- 64-Bit Issues In SSIS
- Guide for Accessing a Heterogeneous Data In SSIS
- Administering SSIS Using The SSIS Catalog
- Advanced Data Cleansing in SSIS
- Fuzzy Lookup and Fuzzy Grouping in SSIS
- SSIS – Analysis Services Processing Task, Execute DDL Task
- BreakPoints In SSIS
- Building the User Interface - SSIS
- Bulk Insert Task in SSIS Package - SSIS
- Learn Cache Connection Manager and Cache Transform in SSIS
- Command-Line Utilities In SSIS
- Creating the Basic Package in SSIS
- Data Extraction In SSIS
- Data Flow Task in SSIS
- Data Loading In SSIS
- Data Preparation Tasks in SSIS
- Data Profiling Task in SSIS with Example
- Introduction to Data Quality Services (DQS) Cleansing Transformation
- Deployment Models In SSIS
- Developing a Custom SSIS Source Component
- Developing a Custom Transformation Component - SSIS
- Dimension Table Loading In SSIS
- Error Outputs in SSIS
- Error Rows in SSIS
- Essential Coding, Debugging, and Troubleshooting Techniques - SSIS
- Event Handling - SSIS
- Excel and Access In SSIS
- SSIS Architecture
- External Management of SSIS
- Fact Table Loading
- Flat Files In SSIS
- Create SSIS Package in SQL Server
- How to Execute Stored Procedure in SSIS Execute SQL Task in SSIS
- How to get Solution Explorer in Visual Studio 2013 - SSIS
- How to Use Derived Column Transformation in SSIS with Example - SSIS
- Importing From Oracle In SSIS
- How to do Incremental Load Data using Control Table Pattern in SSIS
- Software Development Life Cycle in SSIS
- Introduction to SSIS
- Literal SQL - SSIS
- Logging in SSIS
- Lookup Transformation in SSIS
- Overview of Master Data Services SQL Server in SSIS
- Using the Merge Join Transformation in SSIS
- Monitoring Package Executions - SSIS
- Import and Export Wizard in SSIS with SQL Server Data
- Null in SQL Server - SSIS
- What is Open Database Connectivity (ODBC) in SSIS
- Package Configuration Part II - SSIS
- Package Configurations Part I - SSIS
- Package Log Providers - SSIS
- Package Transactions - SSIS
- Performance Counters In SSIS
- Pipeline Performance Monitoring In SSIS
- Restarting Packages In SSIS
- Scaling Out in SSIS
- Scheduling Packages in SSIS
- SSIS Script Task Assign Value to Variable
- Scripting in SSIS
- Security Of SSIS Packages
- SQL Server Boolean Expression In SSIS
- SQL Server Concatenate In SSIS
- SQL Server Data Tools for Visual Studio 2013
- SQL Server Date Time - SSIS
- SQL Server Management Objects Administration Tasks In SSIS
- SQL Server The Data Flow Sources in SSIS 2014
- SQL string functions
- Conditional Expression In SSIS
- SSIS Container
- SSIS Data Flow Design and Tuning
- SSIS Data Flow Examples in SSIS
- SSIS Expressions
- SSIS Script Task
- SSIS Software Development Life Cycle
- SSIS Pipeline Component Methods
- The SSIS Engine
- Typical Mainframe ETL With Data Scrubbing In SSIS
- Understanding Data Types Using Variables, Parameters and Expressions - SSIS
- Understanding The DATA FLOW in SSIS
- Using Precedence Constraints In SSIS
- Using the Script Component in SSIS
- Using T-SQL With SSIS
- Using XML and Web Services In SSIS
- Various Types of Transformations In SSIS - 2014
- Versioning and Source Code Control - SSIS
- Windows Management Instrumentation Tasks In SSIS
- SSIS Workflow Tasks – Integration Services
- Working with SQL Server 2014 Change Data Capture In SSIS
- SSIS Projects and Use Cases
This is another section that applies only to the package deployment model. If you can, you should be changing your SSIS methods to take advantage of the project deployment model.
Unfortunately, SSIS is not a clustered service by default. Microsoft does not recommend that you cluster SSIS, because it can lead to unpredictable results. For example, if you place SSIS in the same cluster group as SQL Server and the SQL Server fails over, it would cause SSIS to fail over as well. Even though it does not cluster in the main SQL Server setup, it can still be clustered manually through a series of relatively easy steps. If you decide you must cluster SSIS, this section walks you through those steps, but it assumes that you already know how to use Windows clustering and understand the basic clustering architecture. Essentially, the steps to setting up SSIS as a clustered service are as follows:
- Install SSIS on the other nodes that can own the service.
- Create a new cluster group (optionally).
- If you created a new group, create a virtual IP, name, and drive as clustered resources.
- Copy over the MsDtsSrvr.ini.xml file to the clustered drive.
- Modify the MsDtsSrvr.ini.xml file to change the location of the packages.
- Change the registry setting to point to the MsDtsSrvr.ini.xml file.
- Cluster the MSDTSServer120 service as a generic service.
You need to make a minor decision prior to clustering. You can choose to cluster the MSDTSServer120 service in the main SQL Server cluster group for a given instance or you can create its own cluster group. You will find that while it’s easier to piggyback the main SQL Server service, it adds complexity to management.
The SSIS service has only a single instance in the entire Windows cluster. If you have a four-instance SQL Server cluster, where would you place the SSIS service then? This is one scenario that demonstrates why it makes the most sense to move the SSIS service into its own group. The main reason, though, is manageability. If you decided that you needed to fail over the SSIS service to another node, you would have to fail over the SQL Server as well if they shared a cluster group, which would cause an outage. Moving the SSIS service into its own cluster group ensures that only the SSIS service fails over and does not cause a wider outage.
Placing the service in its own group comes at a price, though. The service will now need a virtual IP address, its own drive, and a name on the network. Once you meet those requirements, however, you’re ready to go ahead and cluster. If you decided to place SSIS into its own group, you would not need the drive, IP, or name.
The first step to clustering is installing SSIS on all nodes in the Windows cluster. If you installed SSIS as part of your SQL Server install, you’ll see that SSIS installed only on the primary node. You now need to install it manually on the other nodes in the cluster. Make the installation simple by installing SSIS on the same folder on each node.

If you want to have the SSIS service in a different group than the database engine, you first have to create a new group called SSIS in Cluster Administrator for the purpose of this example (although it can be called something else). This group needs to be shared by whichever nodes you would like to participate in the cluster. Then, add to the group a physical drive that is clustered, an IP address, and a network name. The IP address and network names are virtual names and IPs.
From whichever node owns the SSIS group, copy the MsDtsSrvr.ini.xml file to the clustered physical drive that’s in the SSIS cluster group. We generally create a directory called «Clustered Drive Letter»SSISSetup for the file. Make a note of wherever you placed the file for a later configuration step. You’ll also want to create a folder called Packages on the same clustered drive for storing your packages. This directory will store any packages and configuration files that will be stored on the file system instead of the SSIS catalog database.
Next, open the Registry editing tool and changes the key to point to the new location (including the filename) for the MsDtsSrvr.ini.xml file. Make sure you back up the registry before making this change.
Frequently Asked SSIS Interview Questions & Answers
After that, you’re ready to cluster the MSDTSServer120 service. Open Cluster Administrator again and right-click the SSIS cluster group (if you’re creating it in its own group) and select New ⇒ Resource. This will open the Resource Wizard, which clusters nearly any service in Windows. On the first screen, type Integration Services for the name of the clustered resource, and select Generic Service. This name is a logical name that is going to be meaningful only to the administrator and you.
Next, on the Possible Owner screen, add any node that you wish to potentially own the SSIS service. On the Dependencies page, add the group’s Network Name, IP Address, and Drive as dependencies. This ensures that the SSIS service won’t come online before the name and drives are online. Also, if the drive fails, the SSIS service will also fail.
The next screen is Generic Service Parameters, where you should enter MSDTSServer120 for the service to cluster. The last screen in the wizard is the Registry Replication screen, where you want to ensure that the key is replicated.
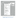
If a change is made to this registry key, it will be replicated to all other nodes. After you finish the wizard, the SSIS service is almost ready to come online and be clustered.
The final step is to move any packages that were stored on the file system over to the clustered drive in the Packages folder. The next time you open Management Studio, you should be able to see all the packages and folders. You also need to edit the MsDtsSrvr.ini.xml file to change the SQL Server to point to SQL Server’s virtual name, not the physical name, which allows failovers of the database engine. In the same file, you need to change the path in the StorePath to point to the folder you created earlier as well. After this, you’re ready to bring the service online in Cluster Administrator.
Now that your SSIS service is clustered, you will no longer connect to the physical machine name to manage the packages in Management Studio. Instead, you will connect to the network name that you created in Cluster Administrator. If you added SSIS as a clustered resource in the same group as SQL Server, you would connect to the SQL Server’s virtual network name.
List of Related Microsoft Certification Courses:
| SSRS | Power BI |
| SSAS | SQL Server |
| SCCM | SQL Server DBA |
| SharePoint | BizTalk Server |
| Team Foundation Server | BizTalk Server Administrator |
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| SSIS Training | Jul 21 to Aug 05 | View Details |
| SSIS Training | Jul 25 to Aug 09 | View Details |
| SSIS Training | Jul 28 to Aug 12 | View Details |
| SSIS Training | Aug 01 to Aug 16 | View Details |

Ravindra Savaram is a Technical Lead at Mindmajix.com. His passion lies in writing articles on the most popular IT platforms including Machine learning, DevOps, Data Science, Artificial Intelligence, RPA, Deep Learning, and so on. You can stay up to date on all these technologies by following him on LinkedIn and Twitter.














