
- SSIS SQL Server Editions
- SSIS Data Flow Destinations
- SSIS Interview Questions
- SSIS Tutorial
- 64-Bit Issues In SSIS
- Guide for Accessing a Heterogeneous Data In SSIS
- Administering SSIS Using The SSIS Catalog
- Advanced Data Cleansing in SSIS
- Fuzzy Lookup and Fuzzy Grouping in SSIS
- SSIS – Analysis Services Processing Task, Execute DDL Task
- BreakPoints In SSIS
- Building the User Interface - SSIS
- Bulk Insert Task in SSIS Package - SSIS
- Learn Cache Connection Manager and Cache Transform in SSIS
- Clustering SSIS
- Command-Line Utilities In SSIS
- Creating the Basic Package in SSIS
- Data Extraction In SSIS
- Data Flow Task in SSIS
- Data Loading In SSIS
- Data Preparation Tasks in SSIS
- Data Profiling Task in SSIS with Example
- Introduction to Data Quality Services (DQS) Cleansing Transformation
- Deployment Models In SSIS
- Developing a Custom SSIS Source Component
- Developing a Custom Transformation Component - SSIS
- Error Outputs in SSIS
- Error Rows in SSIS
- Essential Coding, Debugging, and Troubleshooting Techniques - SSIS
- Event Handling - SSIS
- Excel and Access In SSIS
- SSIS Architecture
- External Management of SSIS
- Fact Table Loading
- Flat Files In SSIS
- Create SSIS Package in SQL Server
- How to Execute Stored Procedure in SSIS Execute SQL Task in SSIS
- How to get Solution Explorer in Visual Studio 2013 - SSIS
- How to Use Derived Column Transformation in SSIS with Example - SSIS
- Importing From Oracle In SSIS
- How to do Incremental Load Data using Control Table Pattern in SSIS
- Software Development Life Cycle in SSIS
- Introduction to SSIS
- Literal SQL - SSIS
- Logging in SSIS
- Lookup Transformation in SSIS
- Overview of Master Data Services SQL Server in SSIS
- Using the Merge Join Transformation in SSIS
- Monitoring Package Executions - SSIS
- Import and Export Wizard in SSIS with SQL Server Data
- Null in SQL Server - SSIS
- What is Open Database Connectivity (ODBC) in SSIS
- Package Configuration Part II - SSIS
- Package Configurations Part I - SSIS
- Package Log Providers - SSIS
- Package Transactions - SSIS
- Performance Counters In SSIS
- Pipeline Performance Monitoring In SSIS
- Restarting Packages In SSIS
- Scaling Out in SSIS
- Scheduling Packages in SSIS
- SSIS Script Task Assign Value to Variable
- Scripting in SSIS
- Security Of SSIS Packages
- SQL Server Boolean Expression In SSIS
- SQL Server Concatenate In SSIS
- SQL Server Data Tools for Visual Studio 2013
- SQL Server Date Time - SSIS
- SQL Server Management Objects Administration Tasks In SSIS
- SQL Server The Data Flow Sources in SSIS 2014
- SQL string functions
- Conditional Expression In SSIS
- SSIS Container
- SSIS Data Flow Design and Tuning
- SSIS Data Flow Examples in SSIS
- SSIS Expressions
- SSIS Script Task
- SSIS Software Development Life Cycle
- SSIS Pipeline Component Methods
- The SSIS Engine
- Typical Mainframe ETL With Data Scrubbing In SSIS
- Understanding Data Types Using Variables, Parameters and Expressions - SSIS
- Understanding The DATA FLOW in SSIS
- Using Precedence Constraints In SSIS
- Using the Script Component in SSIS
- Using T-SQL With SSIS
- Using XML and Web Services In SSIS
- Various Types of Transformations In SSIS - 2014
- Versioning and Source Code Control - SSIS
- Windows Management Instrumentation Tasks In SSIS
- SSIS Workflow Tasks – Integration Services
- Working with SQL Server 2014 Change Data Capture In SSIS
- SSIS Projects and Use Cases
Dimension transformation and loading is about tracking the current and sometimes history of associated attributes in a dimension table. Below Screen shot shows the dimensions related to the Sales Quota Fact table in the AdventureWorksDW database (named FactSalesQuota). The objective of this section is to process data from the source tables into the dimension tables.
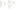
In this example, notice that each dimension (DimEmployee, DimSalesTerritory, and DimDate) has a surrogate key named Dimension Key, as well as a candidate key named Dimension AlternateKey. The surrogate key is the most important concept in data warehousing because it enables the tracking of change history and optimizes the structures for performance. See The Data Warehouse Toolkit, Third Edition, by Ralph Kimball and Margy Ross (Wiley, 2013), for a detailed review of the use and purpose of surrogate keys. Surrogate keys are often auto-incrementing identity columns that are contained in the dimension table.
| Learn how to use SSIS, from beginner basics to advanced techniques, with online video tutorials taught by industry experts. Enroll for a Free SSIS Training Demo! |
Dimension ETL has several objectives, each of which is reviewed in the tutorial steps to load the DimSalesTerritory and DimEmployee tables, including the following:
- Identifying the source keys that uniquely identify a source record and that will map to the alternate key
- Performing any Data Transformations to align the source data to the dimension structures
- Handling the different change types for each source column and adding or updating dimension records
SSIS includes a built-in transformation called the Slowly Changing Dimension (SCD) Transformation to assist in the process. This is not the only transformation that you can use to load a dimension table, but you will use it in these tutorial steps to accomplish dimension loading. The SCD Transformation also has some drawbacks, which are reviewed at the end of this section.
Loading a Simple Dimension Table
Many dimension tables are like the Sales Territory dimension in that they contain only a few columns, and history tracking is not required for any of the attributes. In this example, the DimSalesTerritory table is sourced from the [Sales].[SalesTerritory] table and any source changes to any of the three columns will be updated in the dimension table. These columns are referred to as changing dimension attributes because the values can change.
1. To begin creating the ETL for the DimSalesTerritory table, return to your SSIS project created in the first tutorial and create a new package named ETL_DimSalesTerritory.dtsx.
2. Because you will be extracting data from the AdventureWorks database and loading data into the AdventureWorksDW database, create two OLE DB project connections to these databases named AdventureWorks and AdventureWorksDW, respectively. Refer to the topic SSIS Tools for help defining the project connections.
3. Drag a new Data Flow Task from the SSIS Toolbox onto the Control Flow and navigate to the Data Flow designer.
4. Drag an OLE DB Source component into the Data Flow and double-click the new source to open the editor. Configure the OLE DB Connection Manager dropdown to use the Adventure Works database and leave the data access mode selection as “Table or view.” In the “Name of the table or the view” dropdown, choose [Sales].[SalesTerritory], as shown in the below screenshot.
.png&w=16&q=75)
5. On the Columns property page (see the below screenshot), change the Output Column value for the TerritoryID column to SalesTerritoryAlternateKey, change the Name column to SalesTerritoryRegion, and change the Output Column for the Group column to SalesTerritoryGroup. Also, uncheck all the columns under SalesTerritoryGroup because they are not needed for the DimSalesTerritory table
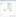
6. Click OK to save your changes and then drag a Lookup Transformation onto the Data Flow and connect the blue data path from the OLE DB Source onto the Lookup.
7. On the General property page, shown in Figure 12-13, edit the Lookup Transformation as follows: leave the Cache mode setting at Full cache, and leave the Connection type setting at OLE DB Connection Manager.

8. On the Connection property page, set the OLE DB Connection Manager dropdown to the AdventureWorks connection. Change the “Use a table or a view” dropdown to [Person].[CountryRegion].
9. On the Columns property page, drag the CountryRegionCode from the Available Input Columns list to the matching column in the Available Lookup Columns list, then select the checkbox next to the Name column in the same column list. Rename the Output Alias of the Name column to SalesTerritoryCountry, as shown in the below screenshot.
10. Select OK in the Lookup Transformation Editor to save your changes.
At this point in the process, you have performed some simple initial steps to align the source data up with the destination dimension table. The next steps are the core of the dimension processing and the use the SCD Transformation.
11. Drag a Slowly Changing Dimension Transformation from the SSIS Toolbox onto the Data Flow and connect the blue data path output from the Lookup to the Slowly Changing Dimension Transformation. When you drop the path onto the SCD Transformation, you will be prompted to select the output of the Lookup. Choose Lookup Match Output from the dropdown and then click OK.
123. To invoke the SCD wizard, double-click the transformation, which will open up a splash screen for the wizard. Proceed to the second screen by clicking Next.
13. The first input of the wizard requires identifying the dimension table to which the source data relates. Therefore, choose AdventureWorksDW as the Connection Manager and then choose [dbo].[DimSalesTerritory] as the table or view, which will automatically display the dimension table’s columns in the list, as shown in the screenshot. For the SalesTerritoryAlternateKey, change the Key Type to the Business key. Two purposes are served here:

=>One, you identify the candidate key (or business key) from the dimension table and which input column it matches. This will be used to identify row matches between the source and the destination.=>Two, columns are matched from the source to attributes in the dimension table, which will be used on the next screen of the wizard to identify the change tracking type. Notice that the columns are automatically matched between the source input and the destination dimension because they have the same name and data type. In other scenarios, you may have to manually perform the match.
. 14 On the next screen of the SCD wizard, you need to identify what type of change each matching column is identified as. It has already been mentioned that all the columns are changing attributes for the DimSalesTerritory dimension; therefore, select all the columns and choose the “Changing attribute” Change Type from the dropdown lists, as shown in Below Screenshot.

Three options exist for the Change Type: Changing attribute, Historical attribute, and Fixed attribute. As mentioned earlier, a Changing attribute is updated if the source value changes. For the Historical attribute, when a change occurs, a new record is generated, and the old record preserves the history of the change. You’ll learn more about this when you walk through the DimEmployee dimension ETL in the next section of this Loading a Data Warehouse Topic. Finally, a Fixed attribute means no changes should happen, and the ETL should either ignore the change or break.
15. The next screen, titled “Fixed and Changing Attribute Options,” prompts you to choose which records you want to update when a source value changes. The “Fixed attributes” option is grayed out because no Fixed attributes were selected on the prior screen. Under the “Changing attributes” option, you can choose to update the changing attribute column for all the records that match the same candidate key, or you can choose to update only the most recent one. It doesn’t matter in this case because there will be only one record per candidate key value, as there are no Historical attributes that would cause a new record. Leave this box unchecked and proceed to the next screen.
16. The “Inferred Dimension Members” screen is about handling placeholder records that were added during the fact table load because a dimension member didn’t exist when the fact load was run. Inferred members are covered in the DimEmployee dimension ETL, later in this Loading a Data Warehouse Topic.
17. Given the simplicity of the Sales Territory dimension, this concludes the wizard, and on the last screen, you merely confirm the settings that you configured. Select Finish to complete the wizard.
The net result of the SCD wizard is that it will automatically generate several downstream transformations, preconfigured to handle the change types based on the candidate keys you selected. Below screenshot shows the completed Data Flow with the SCD Transformation.
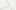
Since this dimension is simple, there are only two outputs. One output is called New Output, which will insert new dimension records if the candidate key identified from the source does not match the dimension. The second output, called Changing Attribute Updates Output, is used when you have a match across the candidate keys and one or more of the changing attributes does not match between the source input and the dimension table. This OLE DB command uses an UPDATE statement to perform the operation

Loading a Complex Dimension Table
Dimension ETL often requires complicated logic that causes the dimension project tasks to take the longest amount of time for design, development, and testing. This is due to change requirements for various attributes within a dimension such as tracking history, updating inferred member records, and so on. Furthermore, with larger or more complicated dimensions, the data preparation tasks often require more logic and transformations before the history is even handled in the dimension table itself.
Preparing the Data
To exemplify a more complicated dimension ETL process, in this section you will create a package for the DimEmployee table. This package will deal with some missing data, as identified earlier in your data profiling research:
1. In the SSIS project, create a new package called ETL_DimEmployee.dtsx. Since you’ve already created project connections for AdventureWorks and AdventureWorksDW, you do not need to add these to the new DimEmployee SSIS package.
2. Create a Data Flow Task and add an OLE DB Source component to the Data Flow.
3. Configure the OLE DB Source component to connect to the AdventureWorks connection and change the data access mode to SQL command. Then enter the following SQL code in the SQL command text window (see the below screenshot):
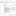
4. Click OK to save the changes to the OLE DB Source component.
5. Drag a Lookup Transformation to the Data Flow and connect the blue data path output from the OLE DB Source to the Lookup. Name the Lookup Sales Territory.
6. Double-click the Lookup Transformation to bring up the Lookup editor. On the General page, change the dropdown named “Specify how to handle rows with no matching entries” to “Redirect rows to no match output.” Leave the Cache mode as Full cache and the Connection type as OLE DB Connection Manager.
7. On the Connection property page, change the OLE DB connection to AdventureWorksDW and then select [dbo].[DimSalesTerritory] in the dropdown below called “Use a table or a view.”
8. On the Columns property page, join the SalesTerritoryCountry, SalesTerritoryGroup, and SalesTerritoryRegion columns between the input columns and lookup columns, as shown in below screenshot. In addition, select the checkbox next to SalesTerritoryKey in the lookup columns to return this column to the Data Flow.

At this point, recall from your data profiling that some of the sales territory columns in the source have NULL values. Also, recall that TerritoryGroup and TerritoryName have a one-to-many functional relationship. In fact, assume that you have conferred with the business users, and they confirmed that you can look at the StateProvinceName and CountryRegionName, and if another salesperson has the same combination of values, you can use their SalesTerritory information.
To handle the missing SalesTerritories with the preceding requirements, add a second Lookup Transformation to the Data Flow, and name it Get Missing Territories. Then connect the blue path output of the Sales Territory Lookup to this new Lookup. You will be prompted to choose the Output; select Lookup No Match Output from the dropdown list, as shown in below screenshot.

10. Edit the new Lookup and configure the OLE DB Source component to connect to the AdventureWorks connection. Then change the data access mode to SQL command. Enter the following SQL code in the SQL command text window:
SELECT DISTINCT
CountryRegionName as SalesTerritoryCountry
, TerritoryGroup as SalesTerritoryGroup
, TerritoryName as SalesTerritoryRegion
, StateProvinceName
FROM [Sales].[vSalesPerson]
WHERE TerritoryName IS NOT NULL
11. On the Columns property page, join the SalesTerritoryCountry and StateProvinceName between the input and lookup columns list and then enable the checkboxes next to SalesTerritoryGroup and SalesTerritoryRegion on the lookup list. Append the word “New” to the OutputAlias, as shown in below screenshot.

Next, you will recreate the SalesTerritory Lookup from the prior steps to get the Sales TerritoryKey for the records that originally had missing data.
12. Add a new Lookup to the Data Flow named Reacquire SalesTerritory and connect the output of the Get Missing Territories Lookup (use the Lookup Match Output when prompted). On the General tab, edit the Lookup as follows: leave the Cache mode as Full cache and the Connection type as OLE DB Connection Manager.
13. On the Connections page, specify the AdventureWorksDW Connection Manager and change the “Use a table or a view” option to [dbo]. [DimSalesTerritory].
14. On the Columns property page (shown in below screenshot), match the columns between the input and lookup table, ensuring that you use the “New” Region and Group column. Match across SalesTerritoryCountry, SalesTerritoryGroupNew, and SalesTerritoryRegionNew. Also return the SalesTerritory Key and name its Output Alias SalesTerritoryKeyNew.

15. Click OK to save your Lookup changes and then drag a Union All
Transformation onto the Data Flow. Connect two inputs into the Union
All Transformation:=>The Lookup Match Output from the original Sales Territory Lookup
=>The Lookup Match Output from the Reacquire SalesTerritory Lookup
16. Edit the Union All Transformation as follows: locate the SalesTerritoryKey column and change the value in the dropdown for the input coming from second lookup to use the SalesTerritoryKeyNew column. This is shown in below screenshot.

17. Click OK to save your changes to the Union All. At this point, your Data Flow should look similar to the one pictured in below screen shot.
.png&w=16&q=75)
These steps described how to handle one data preparation task. When you begin to prepare data for your dimension, chances are good you will need to perform several steps to get it ready for the dimension data changes.
You can use many of the other SSIS transformations for this purpose, described in the rest of the Topic. A couple of examples include using the Derived Column to convert NULLs to Unknowns and the Fuzzy Lookup and Fuzzy Grouping to cleanse dirty data. You can also use the Data Quality Services of SQL Server 2014 to help clean data. A brief overview of DQS is included in Advanced Data Cleansing Topic.
Frequently Asked SSIS Interview Questions & Answers
Handling Complicated Dimension Changes with the SCD Transformation
Now you are ready to use the SCD Wizard again, but for the DimEmployee table, you need to handle different change types and inferred members:
1. Continue development by adding a Slowly Changing Dimension Transformation to the Data Flow and connecting the data path output of the Union All to the SCD Transformation. Then double-click the SCD Transformation to launch the SCD Wizard.
2. On the Select a Dimension Table and Keys page, choose the AdventureWorksDW Connection Manager and the [dbo].[DimEmployee] table.
a. In this example, not all the columns have been extracted from the
source and other destination columns are related to the dimension
change management, which are identified in Step 3. Therefore, not all
the columns will automatically be matched between the input columns
and the dimension columns.
b. Find the EmployeeNationalIDAlternateKey and change the Key Type to
Business Key.
c. Select Next.
3. On the Slowly Changing Dimension Columns page, make the following Change Type designations, as shown in Figure 12-25:
a. Fixed Attributes: BirthDate, HireDate
b. Changing Attributes: CurrentFlag, EmailAddress, FirstName, Gender, LastName, LoginID, MaritalStatus, MiddleName, Phone, SickLeaveHours, Title, VacationHours
c. Historical Attributes: ParentEmployeeNationalIDAlternateKey, SalariedFlag, SalesTerritoryKey
4. On the Fixed and Changing Attribute Options page, uncheck the checkbox under the Fixed attributes label. The result of this is that when a value changes for a column identified as a fixed attribute, the change will be ignored, and the old value in the dimension will not be updated. If you had checked this box, the package would fail.
5. On the same page, check the box for Changing attributes. As described earlier, this ensures that all the records (current and historical) will be updated when a change happens to a changing attribute.
6. You will now be prompted to configure the Historical Attribute Options, as shown in below screenshot. The SCD Transformation needs to know how to identify the current record when a single business key has multiple values (recall that when a historical attribute changes, a new copy of the record is created). Two options are available. One, a single column is used to identify the record. The better option is to use a start and end date. The DimEmployee table has a StartDate and EndDate column; therefore, use the second configuration option button and set the “Start date column” to StartDate, and the “End date column” to EndDate. Finally, set the “Variable to set date values” dropdown to System::StartTime.

7. Assume for this example that you may have missing dimension records when processing the fact table. In this case, a new inferred member is added to the dimension. Therefore, on the Inferred Dimension Members page, leave the “Enable inferred member support” option checked. The SCD Transformation needs to know when a dimension member is an inferred member. The best option is to have a column that identifies the record as inferred; however, the DimEmployee table does not have a column for this purpose. Therefore, leave the “All columns with a change type are null” option selected.
8. This concludes the wizard settings. Click Finish so that the SCD Transformation can build the downstream transformations needed based on the configurations. Your Data Flow will now look similar to the one shown in below screenshot.
As you have seen, when dealing with historical attribute changes and inferred members, the output of the SCD Transformation is more complicated with updates, unions, and derived calculations. One of the benefits of the SCD Wizard is rapid development of dimension ETL. Handling changing attributes, new members, historical attributes, inferred members, and fixed attributes is a complicated process that usually takes hours to code, but with the SCD Wizard, you can accomplish this in minutes. Before looking at some drawbacks and alternatives to the SCD Transformation, consider the outputs (refer to above screenshot) and how they work:
- Changing Attribute Updates Output: The changing attribute output records are records for which at least one of the attributes that were identified as a changing attribute goes through a change. This update statement is handled by an OLE DB Command Transformation with the code shown here:
The question marks (?) in the code are mapped to input columns sent down from the SCD Transformation. Note that the last question mark is mapped to the business key, which ensures that all the records are updated. If you had unchecked the changing attribute checkbox in Step 4 of the preceding list, then the current identifier would have been included and only the latest record would have changed.
- New Output: New output records are simply new members that are added to the dimension. If the business key doesn’t exist in the dimension table, then the SCD Transformation will send the row out of this output. Eventually, these rows are inserted with the Insert Destination (refer to the above screenshot), which is an OLE DB Destination. The Derived Column 1 Transformation shown in the below screenshot is to add the new StartDate of the record, which is required for metadata management.

This dimension is unique, because it has both a StartDate column and a Status column (most dimension tables that track history have either a Status column that indicates whether the record is current or datetime columns that indicate the start and end of the record’s current status, but usually not both). The values for the Status column are Current and , so you should add a second Derived Column to this transformation called Status and force a “Current” value in it. You also need to include it in the destination mapping.
- Historical Attribute Inserts Output: The historical output is for any attributes that you marked as historical and underwent a change. Therefore, you need to add a new row to the dimension table. Handling historical changes requires two general steps:Update the old record with the EndDate (and NULL Status). This is done through a Derived Column Transformation that defines the EndDate as the System::StartTime variable and an OLE DB command that runs an update statement with the following code:
UPDATE [dbo].[DimEmployee]
SET [EndDate] = ?
, [Status] = NULL
WHERE [EmployeeNationalIDAlternateKey] = ?
AND [EndDate] IS NULLThis update statement was altered to also set the Status column to NULL because of the requirement mentioned in the new output. Also, note that [EndDate] IS NULL is included in the WHERE clause because this identifies that the record is the latest record. Insert the new version of the dimension record. This is handled by a Union All Transformation to the new outputs. Because both require inserts, this can be handled in one destination. Also note that the Derived Column shown earlier in above screenshot is applicable to the historical output.
- Inferred Member Updates Output: Handling inferred members is done through two parts of the ETL. First, during the fact load when the dimension member is missing, an inferred member is inserted. Second, during the dimension load, if one of the missing inferred members shows up in the dimension source, then the attributes need to be updated in the dimension table. The following update statement is used in the OLE DB Command 1 Transformation:
What is the difference between this update statement and the update statement used for the changing attribute output? This one includes updates of the changing attributes, the historical attributes, and the fixed attributes. In other words, because you are updating this as an inferred member, all the attributes are updated, not just the changing attributes.
- Fixed Attribute Output (not used by default): Although this is not used by default by the SCD Wizard, it is an additional output that can be used in your Data Flow. For example, you may want to audit records whose fixed attribute has changed. To use it, you can simply take the blue output path from the SCD Transformation and drag it to a Destination component where your fixed attribute records are stored for review. You need to choose the Fixed Attribute Output when prompted by adding the new path.
- Unchanged Output (not used by default): This is another output not used by the SCD Transformation by default. As your dimensions are being processed, chances are good that most of your dimension records will not undergo any changes. Therefore, the records do not need to be sent out for any of the prior outputs. However, you may wish to audit the number of records that are unchanged. You can do this by adding a Row Count Transformation and then dragging a new blue data path from the SCD Transformation onto the Row Count Transformation and choosing the Unchanged Output when prompted by adding the new path. With SSIS in SQL Server 2014, you can also report on the Data Flow performance and statistics when a package is deployed to the SSIS server. Understanding and Tuning the Data Flow Engine Topic and Administering SSIS Topic review the Data Flow reporting status column (most dimension tables that track history have either a Status column that indicates whether the record is current or datetime columns that indicate the start and end of the record’s current status, but usually not both). The values for the Status column are Current and , so you should add a second Derived Column to this transformation called Status and force a “Current” value in it. You also need to include it in the destination mapping.
Considerations and Alternatives to the SCD Transformation
As you have seen, the SCD Transformation boasts powerful, rapid development, and it is a great tool to understand SCD and ETL concepts. It also helps to simplify and standardize your dimension ETL processing. However, the SCD Transformation is not always the right choice for handling your dimension ETL.
Some of the drawbacks include the following:
- For each row in the input, a new lookup is sent to the relational engine to determine whether changes have occurred. In other words, the dimension table is not cached in memory. That is expensive! If you have tens of thousands of dimension source records or more, the performance of this approach can be a limiting feature of the SCD Transformation.
- For each row in the source that needs to be updated, a new update statement is sent to the dimension table (and updates are used by the changing output, historical output, and inferred member output). If a lot of updates are happening every time your dimension package runs, this will also cause your package to run slowly.
- The Insert Destination is not set to fast load. This is because deadlocks can occur between the updates and the inserts. When the insert runs, each row is added one at a time, which can be very expensive.
- The SCD Transformation works well for historical, changing, and fixed dimension attributes, and, as you saw, changes can be made to the downstream transformations. However, if you open the SCD Wizard again and make a change to any part of it, you will automatically lose your customizations.
- Consider some of these approaches to optimize your package that contains the output from the SCD wizard:
- Create an index on your dimension table for the business key, followed by the current row identifier (such as the EndDate). If a clustered index does not already exist, create this index as a clustered index, which will prevent a query plan lookup from getting the underlying row. This will help the lookup that happens in the SCD Transformation, as well as all of the updates.
- The row-by-row updates can be changed to set-based updates. To do this, you need to remove the OLE DB Command Transformation and add a Destination component in its place to stage the records to a temporary table. Then, in the Control Flow, add an Execute SQL Task to perform the set-based update after the Data Flow is completed.
- If you remove all the OLE DB Command Transformations, then you can also change the Insert Destination to use fast load and essentially bulk insert the data, rather than perform per-row inserts.
- Overall, these alterations may provide you with enough performance improvements that you can continue to use the SCD Transformation effectively for higher data volumes. However, if you still need an alternate approach, try building the same SCD process through the use of other built-in SSIS transformations such as these:
- The Lookup Transformation and the Merge Join Transformation can be used to cache the dimension table data. This will greatly improve performance because only a single select statement will run against the dimension table, rather than potentially thousands.
- The Derived Column Transformation and the Script component can be used to evaluate which columns have changed, and then the rows can be sent out to multiple outputs. Essentially, this would mimic the change evaluation engine inside of the SCD Transformation.
- After the data is cached and evaluated, you can use the same SCD output structure to handle the changes and inserts, and then you can use set based updates for better performance.
List of Related Microsoft Certification Courses:
| SSRS | Power BI |
| SSAS | SQL Server |
| SCCM | SQL Server DBA |
| SharePoint | BizTalk Server |
| Team Foundation Server | BizTalk Server Administrator |
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| SSIS Training | Aug 01 to Aug 16 | View Details |
| SSIS Training | Aug 04 to Aug 19 | View Details |
| SSIS Training | Aug 08 to Aug 23 | View Details |
| SSIS Training | Aug 11 to Aug 26 | View Details |

Ravindra Savaram is a Technical Lead at Mindmajix.com. His passion lies in writing articles on the most popular IT platforms including Machine learning, DevOps, Data Science, Artificial Intelligence, RPA, Deep Learning, and so on. You can stay up to date on all these technologies by following him on LinkedIn and Twitter.














