
- SSIS SQL Server Editions
- SSIS Data Flow Destinations
- SSIS Interview Questions
- SSIS Tutorial
- 64-Bit Issues In SSIS
- Guide for Accessing a Heterogeneous Data In SSIS
- Administering SSIS Using The SSIS Catalog
- Advanced Data Cleansing in SSIS
- Fuzzy Lookup and Fuzzy Grouping in SSIS
- SSIS – Analysis Services Processing Task, Execute DDL Task
- BreakPoints In SSIS
- Building the User Interface - SSIS
- Bulk Insert Task in SSIS Package - SSIS
- Learn Cache Connection Manager and Cache Transform in SSIS
- Clustering SSIS
- Command-Line Utilities In SSIS
- Creating the Basic Package in SSIS
- Data Extraction In SSIS
- Data Flow Task in SSIS
- Data Loading In SSIS
- Data Preparation Tasks in SSIS
- Introduction to Data Quality Services (DQS) Cleansing Transformation
- Deployment Models In SSIS
- Developing a Custom SSIS Source Component
- Developing a Custom Transformation Component - SSIS
- Dimension Table Loading In SSIS
- Error Outputs in SSIS
- Error Rows in SSIS
- Essential Coding, Debugging, and Troubleshooting Techniques - SSIS
- Event Handling - SSIS
- Excel and Access In SSIS
- SSIS Architecture
- External Management of SSIS
- Fact Table Loading
- Flat Files In SSIS
- Create SSIS Package in SQL Server
- How to Execute Stored Procedure in SSIS Execute SQL Task in SSIS
- How to get Solution Explorer in Visual Studio 2013 - SSIS
- How to Use Derived Column Transformation in SSIS with Example - SSIS
- Importing From Oracle In SSIS
- How to do Incremental Load Data using Control Table Pattern in SSIS
- Software Development Life Cycle in SSIS
- Introduction to SSIS
- Literal SQL - SSIS
- Logging in SSIS
- Lookup Transformation in SSIS
- Overview of Master Data Services SQL Server in SSIS
- Using the Merge Join Transformation in SSIS
- Monitoring Package Executions - SSIS
- Import and Export Wizard in SSIS with SQL Server Data
- Null in SQL Server - SSIS
- What is Open Database Connectivity (ODBC) in SSIS
- Package Configuration Part II - SSIS
- Package Configurations Part I - SSIS
- Package Log Providers - SSIS
- Package Transactions - SSIS
- Performance Counters In SSIS
- Pipeline Performance Monitoring In SSIS
- Restarting Packages In SSIS
- Scaling Out in SSIS
- Scheduling Packages in SSIS
- SSIS Script Task Assign Value to Variable
- Scripting in SSIS
- Security Of SSIS Packages
- SQL Server Boolean Expression In SSIS
- SQL Server Concatenate In SSIS
- SQL Server Data Tools for Visual Studio 2013
- SQL Server Date Time - SSIS
- SQL Server Management Objects Administration Tasks In SSIS
- SQL Server The Data Flow Sources in SSIS 2014
- SQL string functions
- Conditional Expression In SSIS
- SSIS Container
- SSIS Data Flow Design and Tuning
- SSIS Data Flow Examples in SSIS
- SSIS Expressions
- SSIS Script Task
- SSIS Software Development Life Cycle
- SSIS Pipeline Component Methods
- The SSIS Engine
- Typical Mainframe ETL With Data Scrubbing In SSIS
- Understanding Data Types Using Variables, Parameters and Expressions - SSIS
- Understanding The DATA FLOW in SSIS
- Using Precedence Constraints In SSIS
- Using the Script Component in SSIS
- Using T-SQL With SSIS
- Using XML and Web Services In SSIS
- Various Types of Transformations In SSIS - 2014
- Versioning and Source Code Control - SSIS
- Windows Management Instrumentation Tasks In SSIS
- SSIS Workflow Tasks – Integration Services
- Working with SQL Server 2014 Change Data Capture In SSIS
- SSIS Projects and Use Cases
Among the various applications of SQL Server Integration Services (SSIS), one of the more common is loading a data warehouse or data mart. SSIS provides the extract, transform, and load (ETL) features and functionality to efficiently handle many of the tasks required when dealing with transactional source data that will be extracted and loaded into a data mart, a centralized data warehouse, or even a master data management repository, including the capabilities to process data from the relational data warehouse into SQL Server Analysis Services (SSAS) cubes.
SSIS provides all the essential elements of data processing — from your source, to staging, to your data mart, and onto your cubes (and beyond!). A few common architectures are prevalent in data warehouse solutions. Figure below highlights one common architecture of a data warehouse with an accompanying business intelligence (BI) solution.
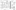
The presentation layer on the right side of above screen shot shows the main purpose of the BI solution, which is to provide business users (from the top to the bottom of an organization) with meaningful data from which they can take actionable steps. Underlying the presentation data are the back-end structures and processes that make it possible for users to access the data and use it in a meaningful way.
Another common data warehouse architecture employs a central data warehouse with subject-oriented data marts loaded from the data warehouse. Below screenshot demonstrates this data warehouse architecture
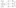
ETL is an important part of a data warehouse and data mart back-end process because it is responsible for moving and restructuring the data between the data tiers of the overall BI solution. This involves many steps, as you will see — including data profiling, data extraction, dimension table loading, fact table processing, and SSAS processing.
This Topic will set you on course to architecting and designing an ETL process for data warehouse and business intelligence ETL. In fact, SSIS contains several out-of-the-box tasks and transformations to get you well on your way to a stable and straightforward ETL process. Some of these components include the Data Profiling Task, the Slowly Changing Dimension Transformation, and the Analysis Services Execute DDL Task. The tutorials in this Loading a Data Warehouse Topic, like other Topic, use the sample databases for SQL Server, called AdventureWorks and AdventureWorksDW. In addition to the databases, a sample SSAS cube database solution is also used. These databases represent a transactional database schema and a data warehouse schema. The tutorials in this Loading a Data Warehouse Topic use the sample databases and demonstrate a coordinated process for the Sales Quota Fact table and the associated SSAS measure group, which includes the ETL required for the Employee dimension. You can go to WWW.WROX.COM/GO/PROSSIS2014 and download the code and package samples found in this Topic, including the version of the SSAS AdventureWorks database used.
Ultimately, data warehousing and BI is about reporting and analytics, and the first step to reach that objective is understanding the source data, because that has immeasurable impact on how you design the structures and build the ETL.
Data profiling is the process of analyzing the source data to better understand its condition in terms of cleanliness, patterns, number of nulls, and so on. In fact, you probably have profiled data before with scripts and spreadsheets without even realizing that it was called data profiling.
A helpful way to data profile in SSIS, the Data Profiling Task, is reviewed in SSIS Task Topic, but let’s drill into some more details about how to leverage it for data warehouse ETL.

Initial Execution of the Data Profiling Task
The Data Profiling Task is unlike the other tasks in SSIS because it is not intended to be run repeatedly through a scheduled operation. Consider SSIS as the wrapper for this tool. You use SSIS to configure and run the Data Profiling Task, which outputs an XML file with information about the data you select. You then observe the results through the Data Profile Viewer, which is a standalone application. The output of the Data Profiling Task will be used to help you in your development and design of the ETL and dimensional structures in your solution. Periodically, you may want to rerun the Data Profiling task to see how the data has changed, but the task will not run in the recurring ETL process.
1. Open Visual Studio and create a new SSIS project called ProSSIS_Ch12.
You will use this project throughout this Loading a Data Warehouse Topic.
2.In the Solution Explorer, rename Package.dtsx to Profile_EmployeeData.dtsx.
3. The Data Profiling Task requires an ADO.NET connection to the source database (as opposed to an OLE DB connection). Therefore, create a new ADO.NET connection in the Connection Manager window by right-clicking and choosing “New ADO.NET Connection” and then click the New button. After you create a connection to the AdventureWorks database, return to the Solution Explorer window.
4. In the Solution Explorer, create a new project connection to your local machine or where the AdventureWorks sample database is installed, as shown in below screen shot.
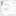
5. Click OK to save the connection information and return to the SSIS package designer. (In the Solution Explorer, rename the project connection to ADONETAdventureWorks.conmgr so that you will be able to distinguish this ADO.NET connection from other connections.)
6. Drag a Data Profiling Task from the SSIS Toolbox onto the Control Flow and double-click the new task to open the Data Profiling Task Editor.
7. The Data Profiling Task includes a wizard that will create your profiling scenario quickly; click the Quick Profile Button on the General tab to launch the wizard.
8. In the Single Table Quick Profile Form dialog, choose the ADONETAdventureWorks connection; and in the Table or View dropdown, select the [Sales].[vSalesPerson] view from the list. Enable all the checkboxes in the Compute list and change the Functional Dependency Profile to use 2 columns as determinant columns, as shown in below screen shot. The next section reviews the results and describes the output of the data profiling steps.
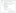
9. Click OK to save the changes, which will populate the Requests list in the Data Profiling Task Editor, as shown in below screen shoot. describes each of these different request types, and you will see the purpose and output of a few of these when we run the viewer.

10. Return to the General tab of the editor. In the Destination property box, choose New File Connection. This is where you will select the location of the XML file where the Data Profiling Task stores its profile output when it is run.
11. In the File Connection Manager Editor, change the Usage type dropdown to “Create file” and enter C:ProSSISDataEmployee_Profile.xml in the File text box. Click OK to save your changes to the connection, and click OK again to save your changes in the Data Profiling Task Editor.
12. Now it is time to execute this simple package. Run the package in Visual Studio, which will initiate several queries against the source table or view (in this case, a view). Because this view returns only a few rows, the Data Profiling task will execute rather quickly, but with large tables it may take several minutes (or longer if your table has millions of rows and you are performing several profiling tests at once).
The results of the profile are stored in the Employee_Profile.xml file, which you will next review with the Data Profile Viewer tool.
Reviewing the Results of the Data Profiling Task
Despite common user expectations, data cannot be magically generated, no matter how creative you are with data cleansing. For example, suppose you are building a sales target analysis that uses employee data, and you are asked to build into the analysis a sales territory group, but the source column has only 50 percent of the data populated. In this case, the business user needs to rethink the value of the data or fix the source. This is a simple example for the purpose of the tutorials in this Loading a Data Warehouse Topic, but consider a more complicated example or a larger table.
The point is that your source data is likely to be of varying quality. Some data is simply missing, other data has typos, sometimes a column has so many different discrete values that it is hard to analyze, and so on. The purpose of doing data profiling is to understand the source, for two reasons. First, it enables you to review the data with the business user, which can effect changes; second, it provides the insight you need when developing your ETL operations. In fact, even though we’re bringing together business data that the project stakeholders use every day, we’re going to be using that data in ways that it has never been used before. Because of this, we’re going to learn things about it that no one knows — not even the people who are the domain experts. Data profiling is one of the up-front tasks that helps the project team avoid unpleasant (and costly) surprises later on.
Now that you have run the Data Profiling Task, your next objective is to evaluate the results:
1. Observing the output requires using the Data Profile Viewer. This utility is found in the Integration Services subdirectory for Microsoft SQL Server 2014 (Start Button ⇒ All Programs ⇒ Microsoft SQL Server 2014 ⇒ Integration Services) or in Windows 8, simply type Data Profile Viewer at the start screen.
2. Open the Employee_Profile.xml file created earlier by clicking the Open button and navigating to the (or the location where the file was saved), highlighting the file, and clicking Open again.
3. In the Profiles navigation tree, first click the table icon on the top left to put the tree viewer into Column View. Then drill down into the details by expanding Data Sources, server (local), Databases, AdventureWorks, and the [Sales].[vSalesPerson] table, as shown in below screen shot.

4. The first profiling output to observe is the Candidate Key Profiles, so click this item under the Columns list, which will open the results in the viewer on the right. Note that the Data Profiling Task has identified seven columns that are unique across the entire table (with 100 percent uniqueness), as shown in below screen shot.

Given the small size of this table, all these columns are unique, but with larger tables, you will see fewer columns and less than 100 percent uniqueness, and any exceptions or key violations. The question is, which column looks to be the right candidate key for this table? In the next section you will see how this answer affects your ETL.
5. Click the Functional Dependency Profile object on the left and observe the results. This shows the relationship between values in multiple columns. Two columns are shown: Determinant Column(s) and Dependant Column. The question is, for every unique value (or combination) in the Determinant Column, is there only one unique value in the Dependant Column? Observe the output. What is the relationship between these combinations of columns: TerritoryGroup and TerritoryName, StateProvinceName, and CountryRegionName. Again, in the next section you will see how these results affect your ETL.
6. In the profile tree, click the “View Single Column by Profile” icon at the top right of the profile tree. Next, expand the TerritoryName column and highlight the Column Length Distribution. Then, in the distribution profile on the right, double-click the length distribution of 6, as shown in below screen shot.

The column length distribution shows the number of rows by length. What are the maximum and minimum lengths of values for the column?
7. Under TerritoryName in the profile browser, select the Column Null Ratio
Profile and then double-click the row in the profile viewer on the right to
view the detail rows.
The Column Null Ratio shows what percentage of rows in the entire table have NULL values. This is valuable for ETL considerations because it spells out when NULL handling is required for the ETL process, which is one of the most common transformation processes.
Frequently Asked SSIS Interview Questions & Answers
8. Select the Column Value Distribution Profile on the left under the TerritoryName and observe the output in the results viewer. How many unique values are there in the entire table? How many values are used only one time in the table?
9. In the left navigation pane, expand the PhoneNumber column and then click the Column Pattern Profile. Double-click the first pattern, number 1, in the list on the right, as shown in Figure 12-9. As you can see, the bottom right of the window shows the actual data values for the phone numbers matching the selected pattern. This data browser is helpful in seeing the actual values so that you can analyze the effectiveness of the Data Profile Task.
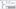
The Column Pattern Profile uses regular expression syntax to display what pattern or range of patterns the data in the column contains. Notice that for the PhoneNumber column, two patterns emerge. The first is for phone numbers that are in the syntax ###-555-####, which is translated to ddd-555-dddd in regular expression syntax. The other pattern begins with 1 (11) 500 555- and ends with four variable numbers.
The final data profiling type to review is the Column Statistics Profile. This is applicable only to data types related to numbers (integer, float, decimal, numeric) and dates (dates allow only minimum and maximum calculations). In the Profiles tree view on the left of the Data Profile Viewer, expand the SalesYTD column and then click the Column Statistics Profile. Four results are calculated across the spread of values in the numeric column:
Minimum: The lowest number value in the set of column values
Maximum: The highest number value in the set of column values
Mean: The average of values in the set of column values
Standard Deviation: The average variance between the values and the mean
The Column Statistics Profile is very valuable for fact table source evaluation, as the measures in a fact table are almost always numeric based, with a few exceptions.
Overall, the output of the Data Profiling Task has helped to identify the quality and range of values in the source. This naturally leads to using the output results to formulate the ETL design.
Turning Data Profile Results into Actionable ETL Steps
The typical first step in evaluating source data is to check the existence of source key columns and referential completeness between source tables or files. Two of the data profiling outputs can help in this effort:
- The Candidate Key Profile will provide the columns (or combination of columns) with the highest uniqueness. It is crucial to identify a candidate key (or composite key) that is 100 percent unique, because when you load your dimension and fact tables, you need to know how to identify a new or existing source record. In the preceding example, shown in Below screen shot, several columns meet the criteria. The natural selection from this list is the BusinessEntityID column.
- The Column NULL Ratio is another important output of the Data Profiling Task. This can be used to verify that foreign keys in the source table have completeness, especially if the primary key to foreign key relationships will be used to relate a dimension table to a fact, or a dimension table to another dimension table. Of course, this doesn’t verify that the primaryto- foreign key values line up, but it will give you an initial understanding of referential data completeness.
As just mentioned, the Column NULL Ratio can be used for an initial review of foreign keys in source tables or files that have been loaded into SQL Server for data profiling review. The Column NULL Ratio is an excellent output, because it can be used for almost every destination column type, such as dimension attributes, keys, and measures. Anytime you have a column that has NULLs, you will most likely have to replace them with unknowns or perform some data cleansing to handle them.
In Step 7 of the previous section, the Territory Name has approximately a 17 percent NULL ratio. In your dimension model destination this is a problem, because the Employee dimension has a foreign surrogate key to the Sales Territory dimension. Because there isn’t completeness in the SalesTerritory, you don’t have a reference to the dimension. This is an actionable item that you will need to address in the dimension ETL section later.
Other useful output of the Data Profiling Task includes the column length and statistics presented. Data type optimization is important to define; when you have a large inefficient source column where most of the space is not used (such as a char(1000)), you will want to scale back the data type to a reasonable length. To do so, use the Column Length Distribution .
The column statistics can be helpful in defining the data type of your measures. Optimization of data types in fact tables is more important than dimensions, so consider the source column’s max and min values to determine what data type to use for your measure. The wider a fact table, the slower it will perform, because fewer rows will fit in the server’s memory for query execution, and the more disk space it will occupy on the server.
Once you have evaluated your source data, the next step is to develop your data extraction, the “E” of ETL.
DATA EXTRACTION AND CLEANSING
Data extraction and cleansing applies to many types of ETL, beyond just data warehouse and BI data processing. In fact, several Topic in this Tutorial deal with data extraction for various needs, such as incremental extraction, change data capture, and dealing with various sources. Refer to the following Topic to plan your SSIS data extraction components:
- The DataFlow Topic takes an initial look at the Source components in the Data Flow that will be used for your extraction.
- Advanced Data Cleansing Topic considers data cleansing, which is a common task for any data warehouse solution.
- Using the Relational Engine Topic deals with using the SQL Server relational engine to perform change data capture.
- Accessing Heterogeneous Data Topic is a look at heterogeneous, or non-SQL Server, sources for data extraction.
The balance of this Topic deals with the core of data warehouse ETL, which is dimension and fact table loading, SSAS object processing, and ETL coordination.
List of Related Microsoft Certification Courses:
| SSRS | Power BI |
| SSAS | SQL Server |
| SCCM | SQL Server DBA |
| SharePoint | BizTalk Server |
| Team Foundation Server | BizTalk Server Administrator |
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| SSIS Training | Jul 25 to Aug 09 | View Details |
| SSIS Training | Jul 28 to Aug 12 | View Details |
| SSIS Training | Aug 01 to Aug 16 | View Details |
| SSIS Training | Aug 04 to Aug 19 | View Details |

Ravindra Savaram is a Technical Lead at Mindmajix.com. His passion lies in writing articles on the most popular IT platforms including Machine learning, DevOps, Data Science, Artificial Intelligence, RPA, Deep Learning, and so on. You can stay up to date on all these technologies by following him on LinkedIn and Twitter.














