
- SSIS SQL Server Editions
- SSIS Data Flow Destinations
- SSIS Interview Questions
- SSIS Tutorial
- 64-Bit Issues In SSIS
- Guide for Accessing a Heterogeneous Data In SSIS
- Administering SSIS Using The SSIS Catalog
- Advanced Data Cleansing in SSIS
- Fuzzy Lookup and Fuzzy Grouping in SSIS
- SSIS – Analysis Services Processing Task, Execute DDL Task
- BreakPoints In SSIS
- Building the User Interface - SSIS
- Bulk Insert Task in SSIS Package - SSIS
- Learn Cache Connection Manager and Cache Transform in SSIS
- Clustering SSIS
- Command-Line Utilities In SSIS
- Creating the Basic Package in SSIS
- Data Flow Task in SSIS
- Data Loading In SSIS
- Data Preparation Tasks in SSIS
- Data Profiling Task in SSIS with Example
- Introduction to Data Quality Services (DQS) Cleansing Transformation
- Deployment Models In SSIS
- Developing a Custom SSIS Source Component
- Developing a Custom Transformation Component - SSIS
- Dimension Table Loading In SSIS
- Error Outputs in SSIS
- Error Rows in SSIS
- Essential Coding, Debugging, and Troubleshooting Techniques - SSIS
- Event Handling - SSIS
- Excel and Access In SSIS
- SSIS Architecture
- External Management of SSIS
- Fact Table Loading
- Flat Files In SSIS
- Create SSIS Package in SQL Server
- How to Execute Stored Procedure in SSIS Execute SQL Task in SSIS
- How to get Solution Explorer in Visual Studio 2013 - SSIS
- How to Use Derived Column Transformation in SSIS with Example - SSIS
- Importing From Oracle In SSIS
- How to do Incremental Load Data using Control Table Pattern in SSIS
- Software Development Life Cycle in SSIS
- Introduction to SSIS
- Literal SQL - SSIS
- Logging in SSIS
- Lookup Transformation in SSIS
- Overview of Master Data Services SQL Server in SSIS
- Using the Merge Join Transformation in SSIS
- Monitoring Package Executions - SSIS
- Import and Export Wizard in SSIS with SQL Server Data
- Null in SQL Server - SSIS
- What is Open Database Connectivity (ODBC) in SSIS
- Package Configuration Part II - SSIS
- Package Configurations Part I - SSIS
- Package Log Providers - SSIS
- Package Transactions - SSIS
- Performance Counters In SSIS
- Pipeline Performance Monitoring In SSIS
- Restarting Packages In SSIS
- Scaling Out in SSIS
- Scheduling Packages in SSIS
- SSIS Script Task Assign Value to Variable
- Scripting in SSIS
- Security Of SSIS Packages
- SQL Server Boolean Expression In SSIS
- SQL Server Concatenate In SSIS
- SQL Server Data Tools for Visual Studio 2013
- SQL Server Date Time - SSIS
- SQL Server Management Objects Administration Tasks In SSIS
- SQL Server The Data Flow Sources in SSIS 2014
- SQL string functions
- Conditional Expression In SSIS
- SSIS Container
- SSIS Data Flow Design and Tuning
- SSIS Data Flow Examples in SSIS
- SSIS Expressions
- SSIS Script Task
- SSIS Software Development Life Cycle
- SSIS Pipeline Component Methods
- The SSIS Engine
- Typical Mainframe ETL With Data Scrubbing In SSIS
- Understanding Data Types Using Variables, Parameters and Expressions - SSIS
- Understanding The DATA FLOW in SSIS
- Using Precedence Constraints In SSIS
- Using the Script Component in SSIS
- Using T-SQL With SSIS
- Using XML and Web Services In SSIS
- Various Types of Transformations In SSIS - 2014
- Versioning and Source Code Control - SSIS
- Windows Management Instrumentation Tasks In SSIS
- SSIS Workflow Tasks – Integration Services
- Working with SQL Server 2014 Change Data Capture In SSIS
- SSIS Projects and Use Cases
Even if a data warehouse solution starts off simple — using one or two sources — it can rapidly become more complex when the users begin to realize the value of the solution and request that data from additional business applications be included in the process. More data increases the complexity of the solution, but it also increases the execution time of the ETL. Storage is certainly cheap today, but the size and amount of data are growing exponentially. If you have a fixed batch window of time in which you can load the data, it is essential to minimize the expense of all the operations. This section looks at ways of lowering the cost of extraction and how you can use those methods within SSIS.
SSIS Data Flow
In an SSIS Data Flow, the OLE DB Source and ADO.NET Source Components allow you to select a table name that you want to load, which makes for a simple development experience but terrible runtime performance. At runtime the component issues a SELECT * FROM «table» command to SQL Server, which obediently returns every single column and row from the table.
This is a problem for several reasons:
- CPU and I/O cost: You typically need only a subset of the columns from the source table, so every extra column you ask for incurs processing overhead in all the subsystems it has to travel through in order to get to the destination. If the database is on a different server, then the layers include NTFS (the file system), the SQL Server storage engine, the query processor, TDS (tabular data stream, SQL Server’s data protocol), TCP/IP, OLE DB, the SSIS Source component, and finally the SSIS pipeline (and probably a few other layers). Therefore, even if you are extracting only one redundant integer column of data from the source, once you multiply that cost by the number of rows and processing overhead, it quickly adds up. Saving just 5 percent on processing time can still help you reach your batch window target.
- Robustness: If the source table has ten columns today and your package requests all the data in a
- SELECT * manner, then if tomorrow the DBA adds another column to the source table, your package could break. Suddenly the package has an extra column that it doesn’t know what to do with, things could go awry, and your Data Flows will need to be rebuilt.
- Intentional design: For maintenance, security, and self-documentation reasons, the required columns should be explicitly specified.
- DBA 101: If you are still not convinced, find any seasoned DBA, and he or she is likely to launch into a tirade of why SELECT * is the root of all evil.
As per below screen shot shows, the Source components also give you the option of using checkboxes to select or deselect the columns that you require, but the problem with this approach is that the filtering occurs on the client-side. In other words, all the columns are brought across (incurring all that I/O overhead), and then the deselected columns are deleted once they get to SSIS.

So what is the preferred way to extract data using these components? The simple answer is to forget that the table option exists and instead use only the query option. In addition, forget that the column checkboxes exist. For rapid development and prototyping these options may be useful, but for deployed solutions you should type in a query to only return the necessary columns. SSIS makes it simple to do this by providing a query builder in both the OLE DB and ADO.NET Source Components, which enables you to construct a query in a visual manner, as shown in below screen shot.
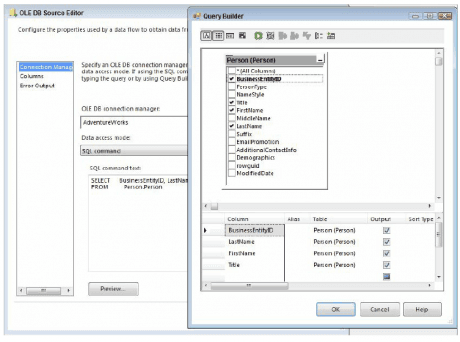
If you forget to use the query option or you use a SELECT * while using the query option and do not need the extraneous columns, SSIS will gently remind you during the execution of the package. The Data Flow Task’s pipeline recognizes the unused columns and throws warning events when the package runs. These messages provide an easy way to verify your column listing and performance tune your package. When running the package in debug mode, you can see the messages on the Progress tab, as shown in Figure 13-3. An example full message states: “[SSIS.Pipeline] Warning: The output column “PersonType” (31) on output “OLE DB Source Output” (29) and component “Table Option Source – Bad Practice” (18) is not subsequently used in the Data Flow task. Removing this unused output column can increase Data Flow task performance.” This reminds you to remove the column PersonType from the source query to prevent the warning from reoccurring and affecting your future package executions.

NOTE When using other SSIS sources, such as the Flat File Source, you do not have the option of selecting specific columns or rows with a query. Therefore, you will need to use the method of unchecking the columns to filter these sources.
As an ancillary to the previous tenet, the WHERE clause (also called the query predicate) is one of the most useful tools you can use to increase performance. Again, the table option in the Source components does not allow you to narrow down the set of columns, nor does it allow you to limit the number of rows. If all you really need are the rows from the source system that are tagged with yesterday’s date, then why stream every single other row over the wire just to throw them away once they get to SSIS? Instead, use a query with a WHERE clause to limit the number of rows being returned. As before, the less data you request, the less processing and I/O is required, and thus the faster your solution will be.
–BAD programming practice (returns 11 columns, 121,317 rows)
SELECT * FROM Sales.SalesOrderDetail;
–BETTER programming practice (returns 6 columns, 121,317 rows)
SELECT SalesOrderID, SalesOrderDetailID, OrderQty,
ProductID, UnitPrice, UnitPriceDiscount
FROM Sales.SalesOrderDetail;
–BEST programming practice (returns 6 columns, 79 rows)
SELECT SalesOrderID, SalesOrderDetailID, OrderQty,
ProductID, UnitPrice, UnitPriceDiscount
FROM Sales.SalesOrderDetail
WHERE ModifiedDate = ‘2008-07-01’;
In case it is not clear, Below screen shot shows how you would use this SELECT statement (and the other queries discussed next) in the context of SSIS. Drop an OLE DB or ADO.NET Source Component onto the Data Flow design surface, point it at the source database (which is AdventureWorks in this case), select the SQL command option, and plug in the preceding query.
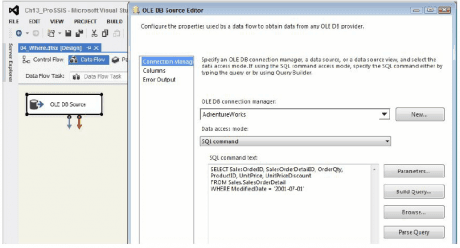
Transform during Extract
The basic message here is to do some of your transformations while you are extracting. This is not a viable approach for every single transformation you intend to do — especially if your ETL solution is used for compliance reasons, and you want to specifically log any errors in the data — but it does make sense for primitive operations, such as trimming whitespace, converting magic numbers to NULLs, sharpening data types, and even something as simple as providing a friendlier column name.
NOTE A magic number is a value used to represent the “unknown” or NULL value in some systems. This is generally considered bad database design practice; however, it is necessary in some systems that don’t have the concept of a NULL state. For instance, you may be using a source database for which the data steward could not assign the value “Unknown” or NULL to, for example, a date column, so instead the operators plugged in 1999/12/31, not expecting that one day the “magic number” would suddenly gain meaning!
The practice of converting data values to the smallest type that can adequately represent them is called data sharpening. In one of the following examples, you convert a DECIMAL(37,0) value to BIT because the column only ever contains the values 0 or 1, as it is more efficient to store and process the data in its smallest (sharpest) representation.

Many data issues can be cleaned up as you’re extracting the data, before it even gets to SSIS. This does not mean you physically fix the data in the source system (though that would be an ideal solution).
NOTE The best way to stop bad data from reaching your source system is to restrict the entry of the data in operational applications by adding validation checks, but that is a topic beyond the scope of this Tutorial.
To fix the extraction data means you will need to write a query smart enough to fix some basic problems and send the clean data to the end user or the intended location, such as a data warehouse. If you know you are immediately going to fix dirty data in SSIS, fix it with the SQL query so SSIS receives it clean from the source.
By following this advice you can offload the simple cleanup work to the SQL Server database engine, and because it is very efficient at doing this type of set-based work, this can improve your ETL performance, as well as lower the package’s complexity. A drawback of this approach is that data quality issues in your source systems are further hidden from the business, and hidden problems tend to not be fixed!
To demonstrate this concept, imagine you are pulling data from the following source schema. The problems demonstrated in this example are not merely illustrative; they reflect some real-world issues that the authors have seen.
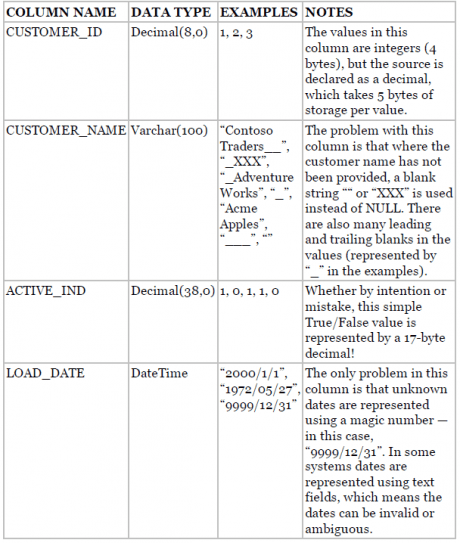
If you retrieve the native data into SSIS from the source just described, it will obediently generate the corresponding pipeline structures to represent this data, including the multi-byte decimal ACTIVE_IND column that will only ever contain the values 1 or 0. Depending on the number of rows in the source, allowing this default behavior incurs a large amount of processing and storage overhead. All the data issues described previously will be brought through to SSIS, and you will have to fix them there. Of course, that may be your intention, but you could make your life easier by dealing with them as early as possible.
Here is the default query that you might design:
–Old Query
SELECT [BusinessEntityID]
,[FirstName]
,[EmailPromotion]
FROM [AdventureWorks].[Person].[Person]
You can improve the robustness, performance, and intention of the preceding query. In the spirit of the “right tool for the right job,” you clean the data right inside the query so that SSIS receives it in a cleaner state. Again, you can use this query in a Source component, rather than use the table method or plug in a default SELECT * query:
–New Query
SELECT
–Cast the ID to an Int and use a friendly name
cast([BusinessEntityID] as int) as BusinessID
–Trim whitespaces, convert empty strings to Null
,NULLIF(LTRIM(RTRIM(FirstName)), ”) AS FirstName
–Cast the Email Promotion to a bit
,cast((Case EmailPromotion When 0 Then 0 Else 1 End) as bit) as
EmailPromoFlag
FROM [AdventureWorks].[Person].[Person]
–Only load the dates you need
Where [ModifiedDate] > ‘2008-12-31’
Let’s look at what you have done here:
- First, you have cast the BusinessEntityID column to a 4-byte integer. You didn’t do this conversion in the source database itself; you just converted its external projection. You also gave the column a friendlier name that your ETL developers many find easier to read and remember.
- Next, you trimmed all the leading and trailing whitespace from the FirstName column. If the column value were originally an empty string (or if after trimming it ended up being an empty string), then you convert it to NULL.
- You sharpened the EmailPromotion column to a Boolean (BIT) column and gave it a name that is simpler to understand.
- Finally, you added a WHERE clause in order to limit the number of rows.
What benefit did you gain? Well, because you did this conversion in the source extraction query, SSIS receives the data in a cleaner state than it was originally. Of course, there are bound to be other data quality issues that SSIS will need to deal with, but at least you can get the trivial ones out of the way while also improving basic performance. As far as SSIS is concerned, when it sets up the pipeline column structure, it will use the names and types represented by the query. For instance, it will believe the IsActive column is (and always has been) a BIT — it doesn’t waste any time or space treating it as a 17-byte DECIMAL. When you execute the package, the data is transformed inside the SQL engine, and SSIS consumes it in the normal manner (albeit more efficiently because it is cleaner and sharper).
You also gave the columns friendlier names that your ETL developers may find more intuitive. This doesn’t add to the performance, but it costs little and makes your packages easier to understand and maintain. If you are planning to use the data in a data warehouse and eventually in an Analysis Services cube, these friendly names will make your life much easier in your cube development.
The results of these queries running in a Data Flow in SSIS are very telling. The old query returns over 19,000 rows, and it took about 0.3 seconds on the test machine. The new query returned only a few dozen rows and took less than half the time of the old query. Imagine this was millions of rows or even billions of rows; the time savings would be quite significant. So query tuning should always be performed when developing SSIS Data Flows.
Many And Make Light Work
OK, that is a bad pun, but it’s also relevant. What this tenet means is that you should let the SQL engine combine different data sets for you where it makes sense. In technical terms, this means do any relevant JOINs, UNIONs, subqueries, and so on directly in the extraction query.
That does not mean you should use relational semantics to join rows from the source system to the destination system or across heterogeneous systems (even though that might be possible) because that will lead to tightly coupled and fragile ETL design. Instead, this means that if you have two or more tables in the same source database that you are intending to join using SSIS, then JOIN or UNION those tables together as part of the SELECT statement.
For example, you may want to extract data from two tables — SalesQ1 and SalesQ2 — in the same database. You could use two separate SSIS Source components, extract each table separately, then combine the two data streams in SSIS using a Union All Component, but a simpler way would be to use a single Source component that uses a relational UNION ALL operator to combine the two tables directly:
–Extraction query using UNION ALL
SELECT –Get data from Sales Q1
SalesOrderID,
SubTotal
FROM Sales.SalesQ1
UNION ALL –Combine Sales Q1 and Sales Q2
SELECT –Get data from Sales Q2
SalesOrderID,
SubTotal
FROM Sales.SalesQ2
Here is another example. In this case, you need information from both the Product and the Subcategory table. Instead of retrieving both tables separately into SSIS and joining them there, you issue a single query to SQL and ask it to JOIN the two tables for you (see Joining Data Topic for more information):
–Extraction query using a JOIN
SELECT
p.ProductID,
p.[Name] AS ProductName,
p.Color AS ProductColor,
sc.ProductSubcategoryID,
sc.[Name] AS SubcategoryName
FROM Production.Product AS p
INNER JOIN –Join two tables together
Production.ProductSubcategory AS sc
ON p.ProductSubcategoryID = sc.ProductSubcategoryID;
SORT in the Database
SQL Server has intimate knowledge of the data stored in its tables, and as such it is highly efficient at operations such as sorting — especially when it has indexes to help it do the job. While SSIS allows you to sort data in the pipeline, you will find that for large data sets SQL Server is more proficient. As an example, you may need to retrieve data from a table, then immediately sort it so that a Merge Join Transformation can use it (the Merge Join Transformation requires pre-sorted inputs). You could sort the data in SSIS by using the Sort Transformation, but if your data source is a relational database, you should try to sort the data directly during extraction in the SELECT clause. Here is an example:
–Extraction query using a JOIN and an ORDER BY
SELECT
p.ProductID,
p.[Name] AS ProductName,
p.Color AS ProductColor,
sc.ProductSubcategoryID,
sc.[Name] AS SubcategoryName
FROM
Production.Product AS p
INNER JOIN –Join two tables together
Production.ProductSubcategory AS sc
ON p.ProductSubcategoryID = sc.ProductSubcategoryID
ORDER BY –Sorting clause
p.ProductID,
sc.ProductSubcategoryID;
In this case, you are asking SQL Server to pre-sort the data so that it arrives in SSIS already sorted. Because SQL Server is more efficient at sorting large data sets than SSIS, this may give you a good performance boost. The Sort Transformation in SSIS must load all of the data in memory; therefore, it is a fully blocking asynchronous transform that should be avoided whenever possible. See Joining Data Topic for more information on this.
Note that the OLE DB and ADO.NET Source Components submit queries to SQL Server in a pass-through manner — meaning they do not parse the query in any useful way themselves. The ramification is that the Source components will not know that the data is coming back sorted. To work around this problem, you need to tell the Source components that the data is ordered, by following these steps:
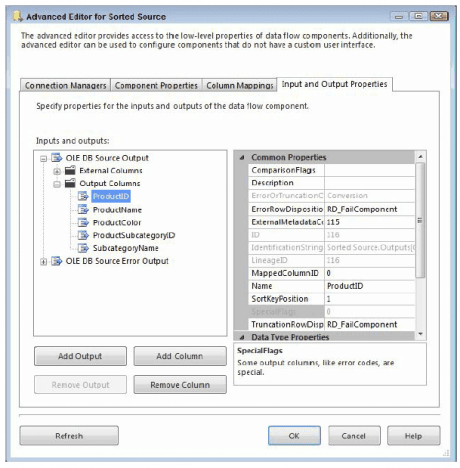
- Right-click the Source component and choose Show Advanced Editor.
- Select the Input and Output Properties tab and click the root node for the default output (not the error output). In the property grid on the right is a property called IsSorted. Change this to True. Setting the IsSorted property to true just tells the component that the data is pre-sorted, but it does not tell it in what order.
- Next, select the columns that are being sorted on, and assign them values as follows: If the column is not sorted, the value should be zero. If the column is sorted in ascending order, the value should be positive. If the column is sorted in descending order, the value should be negative. The absolute value of the number should correspond to the column’s position in the order list. For instance, if the query was sorted with ColumnA ascending, ColumnB descending, then you would assign the value 1 to ColumnA and the value -2 to ColumnB, with all other columns set to 0.
- In Below screen shot, the data is sorted by the ProductID column. Expand the Output Columns node under the default output node, and then select the ProductID column. In the property grid, set the SortKeyPosition value to 1. Now the Source component is aware that the query is returning a sorted data set; furthermore, it knows exactly which columns are used for the sorting. This sorting information will be passed downstream to the next tasks. The passing down of information allows you to use components like the Merge Join Transformation, which requires sorted inputs, without using an SSIS Sort Transformation in the Data Flow.
Be very careful when specifying the sort order — you are by contract telling the system to trust that you know what you are talking about, and that the data is in fact sorted. If the data is not sorted, or it is sorted in a manner other than you specified, then your package can act unpredictably, which could lead to data and integrity loss.
Modularize
If you find you have common queries that you keep using, then try to encapsulate those queries in the source system. This statement is based on ideal situations; in the real world you may not be allowed to touch the source system, but if you can, then there is a benefit. Encapsulating the queries in the source system entails creating views, procedures, and functions that read the data — you are not writing any data changes into the source. Once the (perhaps complex) queries are encapsulated in the source, your queries can be used in multiple packages by multiple ETL developers. Here is an example:
USE SourceSystemDatabase;
GO
CREATE PROCEDURE dbo.up_DimCustomerExtract(@date DATETIME)
— Test harness (also the query statement you’d use in the SSIS
source component):
— Sample execution: EXEC dbo.up_DimCustomerExtract ‘2004-12-20’;
AS BEGIN
SET NOCOUNT ON;
SELECT
–Convert to INT and alias using a friendlier name
Cast(CUSTOMER_ID as int) AS CustomerID
–Trim whitespace, convert empty strings to NULL and alias
,NULLIF(LTRIM(RTRIM(CUSTOMER_NAME)), ”) AS CustomerName
–Convert to BIT and use friendly alias
,Cast(ACTIVE_IND as bit) AS IsActive
,CASE
–Convert magic dates to NULL
WHEN LOAD_DATE = ‘9999-12-31’ THEN NULL
–Convert date to smart surrogate number of form YYYYMMDD
ELSE CONVERT(INT, (CONVERT(NVARCHAR(8), LOAD_DATE, 112)))
–Alias using friendly name
END AS LoadDateID
FROM dbo.Customers
–Filter rows using input parameter
WHERE LOAD_DATE = @date;
SET NOCOUNT OFF;
END;
GO
To use this stored procedure from SSIS, you would simply call it from within an OLE DB or ADO .NET Source Component. The example shows a static value for the date parameter, but in your solution you would use a variable or expression instead, so that you could call the procedure using different date values (see Using Variables, Parameters, and Expressions Topic for more details):
EXEC dbo.up_DimCustomerExtract ‘2013-12-20’;
Here are some notes on the benefits you have gained here:
- In this case you have encapsulated the query in a stored procedure, though you could have encased it in a user-defined function or view just as easily. A side benefit is that this complex query definition is not hidden away in the depths of the SSIS package — you can easily access it using SQL Server.
- The benefit of a function or procedure is that you can simply pass a parameter to the module (in this case @date) in order to filter the data (study the WHERE clause in the preceding code). Note, however, that SSIS Source components have difficulty parsing parameters in functions, so you may need to use a procedure instead (which SSIS has no problems with), or you can build a dynamic query in SSIS to call the function (see Using Variables, Parameters, and Expressions Topic for more information).
- If the logic of this query changes — perhaps because you need to filter in a different way, or you need to point the query at an alternative set of tables — then you can simply change the definition in one place, and all the callers of the function will get the benefit. However, there is a risk here too: If you change the query by, for example, removing a column, then the packages consuming the function might break, because they are suddenly missing a column they previously expected. Make sure any such query updates go through a formal change management process in order to mitigate this risk.
SQL Server Does Text Files Too
It is a common pattern for source systems to export nightly batches of data into text files and for the ETL solution to pick up those batches and process them. This is typically done using a Flat File Source Component in SSIS, and in general you will find SSIS is the best tool for the job. However, in some cases you may want to treat the text file as a relational source and sort it, join it, or perform calculations on it in the manner described previously. Because the text file lives on disk, and it is a file not a database, this is not possible — or is it?
Actually, it is possible! SQL Server includes a table-valued function called OPENROWSET that is an ad hoc method of connecting and accessing remote data using OLE DB from within the SQL engine. In this context, you can use it to access text data, using the OPENROWSET(BULK …) variation of the function.
NOTE Using the OPENROWSET and OPENQUERY statements has security ramifications, so they should be used with care in a controlled environment. If you want to test this functionality, you may need to enable the functions in the SQL Server Surface Area Configuration Tool. Alternatively, use the T-SQL configuration function as shown in the following code. Remember to turn this functionality off again after testing it (unless you have adequately mitigated any security risks). See our Tutorial Online for more information.
sp_configure ‘show advanced options’, 1; –Show advanced
configuration options
GO
RECONFIGURE;
GO
sp_configure ‘Ad Hoc Distributed Queries’, 1; –Switch on OPENROWSET
functionality
GO
RECONFIGURE;
GO
sp_configure ‘show advanced options’, 0; –Remember to hide advanced
options
GO
RECONFIGURE;
GO
The SQL Server documentation has loads of information about how to use these two functions, but the following basic example demonstrates the concepts. First create a text file with the following data in it. Use a comma to separate each column value. Save the text file using the name BulkImport.txt in a folder of your choice.
1,AdventureWorks
2,Acme Apples Inc
3,Contoso Traders
Next create a format file that will help SQL Server understand how your custom flat file is laid out. You can create the format file manually or you can have SQL Server generate it for you: Create a table in the database where you want to use the format file (you can delete the table later; it is just a shortcut to build the format file). Execute the following statement in SQL Server Management Studio — for this example, you are using the AdventureWorks database to create the table, but you can use any database because you will delete the table afterward. The table schema should match the layout of the file.
–Create temporary table to define the flat file schema
USE AdventureWorks
GO
CREATE TABLE BulkImport(ID INT, CustomerName NVARCHAR(50));
Now open a command prompt, navigate to the folder where you saved the BulkImport.txt file, and type the following command, replacing “AdventureWorks” with the database where you created the BulkImport table:
Frequently Asked SSIS Interview Questions & Answers
bcp AdventureWorks..BulkImport format nul -c -t , -x -f
BulkImport.fmt -T
If you look in the folder where you created the data file, you should now have another file called BulkImport.fmt. This is an XML file that describes the column schema of your flat file — well, actually it describes the column schema of the table you created, but hopefully you created the table schema to match the file. Here is what the format file should look like:
.PNG&w=16&q=75)
Remember to delete the table (BulkImport) you created, because you don’t need it anymore. If you have done everything right, you should now be able to use the text file in the context of a relational query. Type the following query into SQL Server Management Studio, replacing the file paths with the exact folder path and names of the two files you created:
.PNG&w=16&q=75)
After executing this command, you should get back rows in the same format they would be if they had come from a relational table. To prove that SQL Server is treating this result set in the same manner it would treat any relational data, try using the results in the context of more complex operations such as sorting:.PNG&w=16&q=75)
You can declare if and how the text file is pre-sorted. If the system that produced the text file did so in a sorted manner, then you can inform SQL Server of that fact. Note that this is a contract from you, the developer, to SQL Server. SQL Server uses something called a streaming assertion when reading the text file to double-check your claims, but in some cases this can greatly improve performance. Later you will see how this ordering contract helps with the MERGE operator, but here’s a simple example to demonstrate the savings.
Run the following query. Note how you are asking for the data to be sorted by OrgID this time. Also note that you have asked SQL Server to show you the query plan that it uses to run the query:
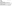
Have a look at the following query plan that SQL Server generates. The query plan shows the internal operations SQL Server has to perform to generate the results. In particular, note the second operation, which is a SORT:
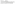
This is obvious and expected; you asked SQL Server to sort the data, and it does so as requested. Here’s the trick: In this case, the text file happened to be pre-sorted by OrgID anyway, so the sort you requested was actually redundant. (Note the text data file; the ID values increase monotonically from 1 to 3.)
To prove this, type the same query into SQL again, but this time use the OPENROWSET(… ORDER) clause:
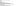
Once again you have asked for the data to be sorted, but you have also contractually declared that the source file is already pre-sorted. Have a look at the new query plan. Here’s the interesting result: Even though you asked SQL Server to sort the result in the final ORDER BY clause, it didn’t bother doing so because you indicated (and it confirmed) that the file was already ordered as such: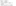
As you can see, there is no SORT operation in the plan. There are other operators, but they are just inexpensive assertions that confirm the contract you specified is true. For instance, if a row arrived that was not ordered in the fashion you declared, the statement would fail. The streaming assertion check is cheaper than a redundant sort operation, and it is good logic to have in place in case you got the ordering wrong, or the source system one day starts outputting data in a different order than you expected.
So after all that, why is this useful to SSIS? Here are a few examples:
- You may intend to load a text file in SSIS and then immediately join it to a relational table. Now you could do all that within one SELECT statement, using a single OLE DB or ADO .NET Source Component.
- Some of the SSIS components expect sorted inputs (the Merge Join Component, for example). Assuming the source is a text file, rather than sort the data in SSIS you can sort it in SQL Server. If the text file happens to be pre-sorted, you can declare it as such and save even more time and expense.
- The Lookup Transformation can populate data from almost anywhere (see Joining Data Topic). This may still prove a useful technique in some scenarios.
WARNING Using OPENROWSET to select from a text file should be used only as a temporary solution, as it has many downfalls. First, there are no indexes on the file, so performance is going to be degraded severely. Second, if the sourcetype=“warning” data file changes in structure (for instance, a column is dropped), and you don’t keep the format file in sync, then the query will fail. Third, if the format file is deleted or corrupted, the query will also fail. This technique can be used when SSIS is not available or does not meet your needs. In most cases, loading the file into a table with SSIS and then querying that table will be your best option.
Using Set-Based Logic
Cursors are infamous for being very slow. They usually perform row-by-row operations that are time-consuming. The SQL Server relational database engine, along with SSIS, performs much faster in set-based logic. The premise here is simple: Avoid any use of cursors like the plague. Cursors are nearly always avoidable, and they should be used only as a final resort. Try out the following features and see if they can help you build efficient T-SQL operations:
- Common table expressions (CTEs) enable you to modularize subsections of your queries, and they also support recursive constructs, so you can, for instance, retrieve a self-linked (parent-child) organizational hierarchy using a single SQL statement.
- Table-valued parameters enable you to pass arrays into stored procedures as variables. This means that you can program your stored procedure logic using the equivalent of dynamic arrays.
- UNION is now joined by its close cousins, INTERSECT and EXCEPT, which completes the primitive set of operations you need to perform set arithmetic. UNION joins two rowsets together, INTERSECT finds their common members, and EXCEPT finds the members that are present in one rowset but not the other.
The following example brings all these ideas together. In this example scenario, suppose you have two tables of data, both representing customers. The challenge is to group the data into three subsets: one set containing the customers who exist in the first table only, the second set containing customers who exist in the second table only, and the third set containing the customers who exist in both tables. The specific example illustrates the power and elegance of common table expressions (CTEs) and set-arithmetic statements. If you remember Venn diagrams from school, what you are trying to achieve is the relational equivalent of the diagram shown in below screen shot.

Following is a single statement that will partition the data as required. This statement is not meant to convey good programming practice, because it is not the most optimal or concise query you could write to derive these results. It is simply meant to demonstrate the manner in which these constructs can be used. By studying the verbose form, you can appreciate the elegance, composability, and self-documenting nature of the syntax.
For convenience you will use related tables from AdventureWorks and AdventureWorksDW. Note the use of multiple CTE structures to generate intermediate results (though the query optimizer is smart enough to not execute the statements separately). Also notice the use of UNION, EXCEPT, and INTERSECT to derive specific results:
WITH SourceRows AS ( –CTE containing all source rows
SELECT TOP 1000 AccountNumber
FROM AdventureWorks.Sales.Customer
ORDER BY AccountNumber
),
DestinationRows(AccountNumber) AS ( –CTE containing all destination
rows
SELECT CustomerAlternateKey
FROM AdventureWorksDW.dbo.DimCustomer
),
RowsInSourceOnly AS ( –CTE: rows where AccountNumber is in source
only
SELECT AccountNumber FROM SourceRows –select from previous CTE
EXCEPT –EXCEPT means ‘subtract’
SELECT AccountNumber FROM DestinationRows –select from previous CTE
),
RowsInSourceAndDestination AS( –CTE: AccountNumber in both source &
destination
SELECT AccountNumber FROM SourceRows
INTERSECT –INTERSECT means ‘find the overlap’
SELECT AccountNumber FROM DestinationRows
),
RowsInDestinationOnly AS ( –CTE: AccountNumber in destination only
SELECT AccountNumber FROM DestinationRows
EXCEPT –Simply doing the EXCEPT the other way around
SELECT AccountNumber FROM SourceRows
),
RowLocation(AccountNumber, Location) AS ( –Final CTE
SELECT AccountNumber, ‘Source Only’ FROM RowsInSourceOnly
UNION ALL –UNION means ‘add’
SELECT AccountNumber, ‘Both’ FROM RowsInSourceAndDestination
UNION ALL
SELECT AccountNumber, ‘Destination Only’ FROM RowsInDestinationOnly
)S
ELECT * FROM RowLocation –Generate final result
ORDER BY AccountNumber;
Here is a sample of the results:
AccountNumber Location
———– ———–
AW00000700 Source Only
AW00000701 Source Only
AW00011000 Both
. . .
AW00011298 Both
AW00011299 Destination Only
AW00011300 Destination Only
SQL Server provides many powerful tools for use in your data extraction arsenal. Learn about them and then start using the SQL Server relational database engine and SSIS in concert to deliver optimal extraction routines. The list presented previously is not exhaustive; you can use many other similar techniques to improve the value of the solutions you deliver.
List of Related Microsoft Certification Courses:
| SSRS | Power BI |
| SSAS | SQL Server |
| SCCM | SQL Server DBA |
| SharePoint | BizTalk Server |
| Team Foundation Server | BizTalk Server Administrator |
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| SSIS Training | Aug 04 to Aug 19 | View Details |
| SSIS Training | Aug 08 to Aug 23 | View Details |
| SSIS Training | Aug 11 to Aug 26 | View Details |
| SSIS Training | Aug 15 to Aug 30 | View Details |

I am Ruchitha, working as a content writer for MindMajix technologies. My writings focus on the latest technical software, tutorials, and innovations. I am also into research about AI and Neuromarketing. I am a media post-graduate from BCU – Birmingham, UK. Before, my writings focused on business articles on digital marketing and social media. You can connect with me on LinkedIn.














