- Home
- Blog
- SQL Server
- RDBMS Interview Questions

- SQL Server Cluster
- SQL Server Constraints with Example
- Error Handling in SQL Server
- SQL Server Joins
- R Data Tables Tutorial with Examples
- SQL Server 2019: New Features
- SQL Server DBA Interview Questions
- SQL Server Interview Questions
- SQL Server Interview Questions for 2-5 Years Experienced
- Top 10 SQL Server Interview Questions for 5 years Experienced
- SQL Server Tutorial
- Creating a PowerPivot Data Model in Excel 2013
- How to Implement In-Memory OLTP SQL Server
- Creating a Power View Report in Excel
- What is PolyBase in SQL Server
- SQL Server In-Memory OLTP Architecture Overview
- In-Memory OLTP integration and application migration In SQL Server
- SQL Server In-Memory OLTP Investments
- Introducing Power BI for Office 365 – SQL Server
- Creating a Power Map Reporting Content from SQL Server
- Platform For Hybrid Cloud
- Database Testing Interview Questions
- Magento Interview Questions
- What is Magento - A Complete Tutorial Guide
- SQL Joins Interview Questions
- T-SQL Tutorial
- DBMS Interview Questions
- SQL Server Architecture - Detailed Explanation
- BigQuery Interview Questions
- DB2 Interview Questions
- Testing Connection to SQL Server
- How to Install Microsoft SQL Server?
An RDBMS (Relational Database Management System) provides a foundation for numerous applications and services. Top companies widely use relational databases to manage their data. Hence, being well-versed in this technology allows you to remain relevant in the industry.
The following RDBMS Interview Questions are categorized based on their difficulty level: basic, intermediate, and advanced. They address various RDBMS-related topics from all angles and tough questions for experienced RDBMS applicants.
Top 10 RDBMS Frequently Asked Questions
- What Structures exist in a Relational Database?
- What are the Types of relationships in RDBMS?
- Explain DBMS vs RDBMS
- Name a few RDBMS Operators.
- Why is ACID property important in RDBMS?
- Name a few sub-systems of an RDBMS.
- How many components are there in RDBMS?
- What is Normalization in RDBMS?
- Name a few types of Keys in an RDBMS.
- How is Denormalization different from Normalization?
Basic RDBMS Interview Questions
1. What is DBMS?
A database management system is a computerized data-keeping system for storing, retrieving, and managing data. A DBMS makes it easy for users to create, read, protect, delete, and update the data in a database.
It serves as an interface between the users and databases, ensuring consistent data access.
The most popular DBMS in enterprise database systems is RDBMS. The complete form is Relational Database Management System.
| If you want to enrich your career and become a professional in RDBMS, then enroll in "SQL Server Training" - This course will help you to achieve excellence in this domain. |
2. Explain RDBMS with an Example.
Relational database management is a set of programs and capabilities used to create, update, administer, and interact with a relational database among IT teams. A relational database stores and provides access to data points related to one another.
In RDBMS, data storage is in the form of tables, and each row within the table is a record with a unique ID called a key. The table's columns hold the data attributes, and the record usually contains the value of each attribute, to establish the relationship among data points quickly.
Let's take an example of a digital storefront, and understand more clearly how we can structure data in RDBMS.

In the database, we store customer information in tables, with columns representing the names and addresses and rows holding individual customer data.
We can even link or relate the tables using keys. Each row is defined in a table using a unique "Primary Key." The primary key added to another table is referred to as a "Foreign Key." The relationships among the primary/foreign keys form the basis of how relational databases work.
3. What Structures exist in a Relational Database?
The following structures exist in relational databases
-
Database
A database is a logical grouping of data. It contains the data associated with one application or with a group of related applications. It includes a collection of related table spaces and index spaces.
-
Table
A table is a logical structure made of columns and rows. Rows have no specific order, but columns follow a fixed order to retrieve the data.
-
Indexes
An index is nothing more than an ordered set of pointers to rows of a table. Unlike the rows of the table, the rows in the indexes maintain a specific order to retrieve data.
-
Keys
A key is one or more columns specified as keys when a table, index, or referential integrity is defined. The various types of keys in RDBMS include primary key, unique key, and foreign key.

4. What are the Types of relationships in RDBMS?
There are three main types of relationships between the tables to ensure the absolute flexibility of the relational database model.
-
One-to-One Relationship
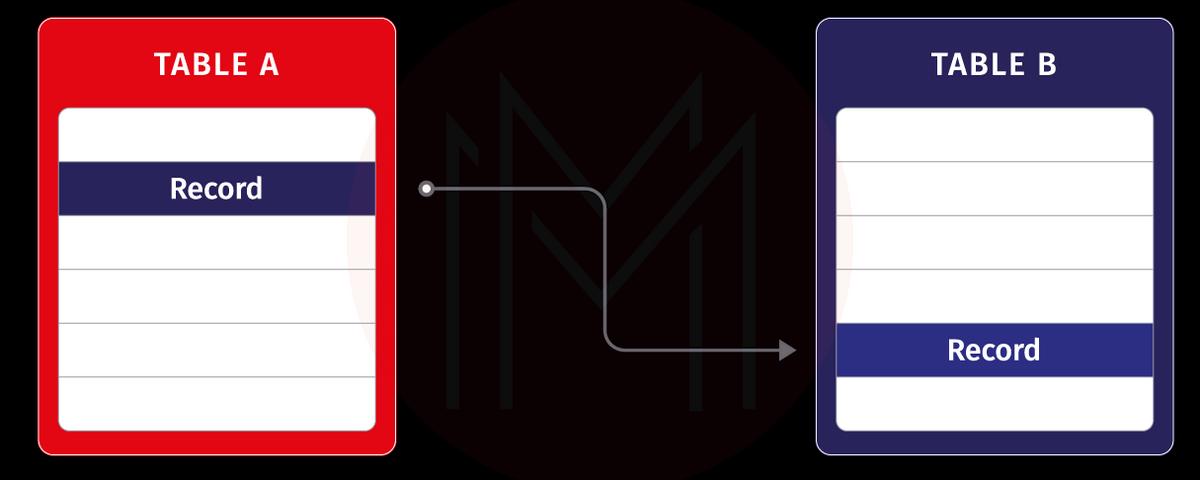
Suppose a single record of table A is related to a single record of table B. In that case, it is a one-to-one relationship.
-
One-to-Many Relationship
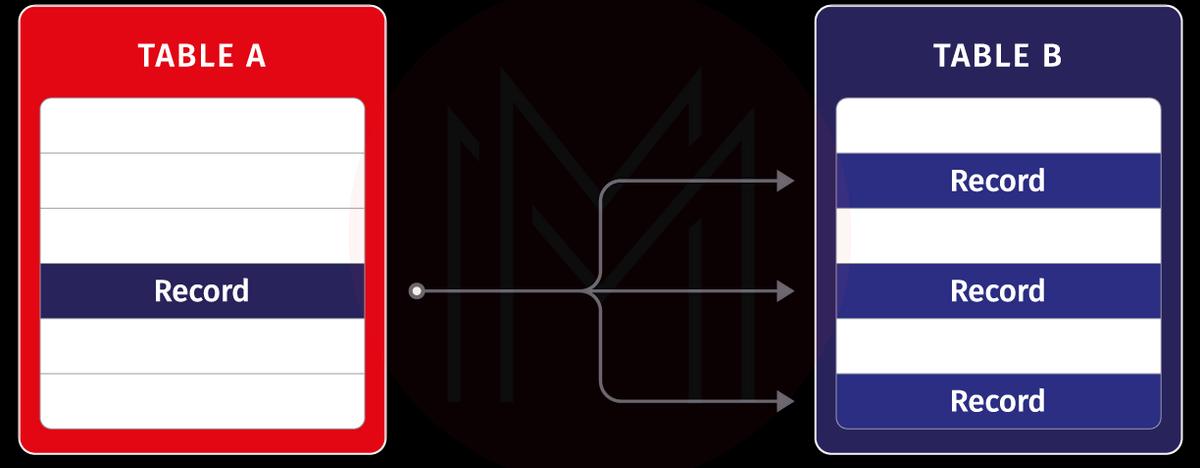
Suppose a single record of table A is related to multiple records of table B. In that case, it is a one-to-many relationship.
-
Many-to-Many Relationship
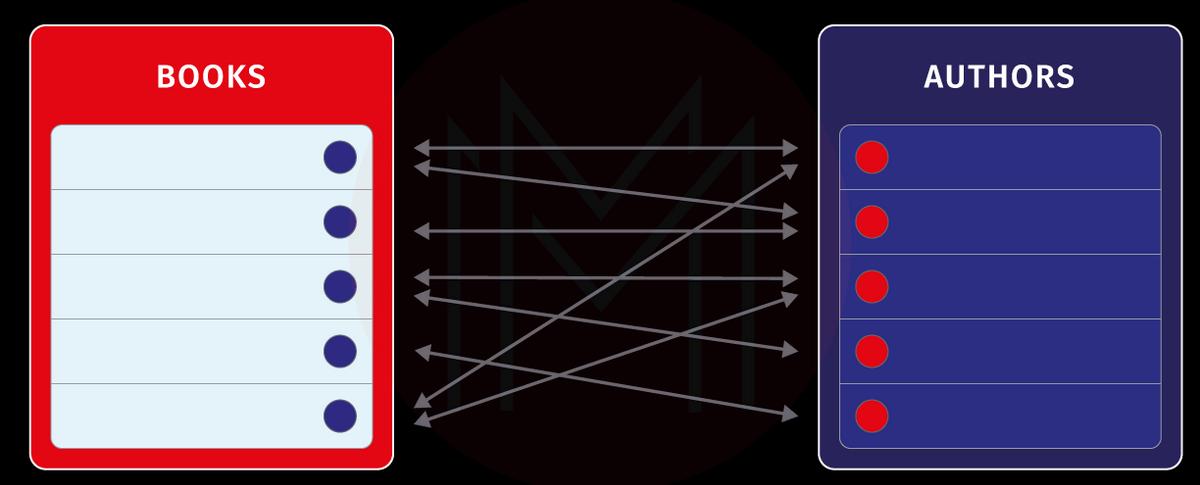
Suppose multiple records of table A are related to multiple records of table B. In that case, it is a many-to-many relationship.
5. What are the essential Features of RDBMS?
The following are the features of RDBMS
-
Structured and Interrelated Data
Relational databases store data in an easily understandable table format.
-
Multi-user access
Allows multi-user access along with the benefits that let administrators have complete control over databases and provide different levels of access to other users.
-
ACID Support
Relational databases provide complete ACID support. The term "ACID" means Atomicity, Consistency, Isolation, and Durability, a well-known database property guaranteeing data validity despite errors, failures, and other possible mishaps.
6. What are the advantages and disadvantages of RDBMS?
Pros
- Flexible data management
- Reliable data storage, backup, and recovery.
- Sensitive data integrity and security.
- Compliance with data protection standards and regulations.
- Fast integration with commercial software and a streamlined development process
Cons
- Regular RDBMS updates may require higher maintenance.
- RDBMS requires the skilled expertise of database administrators and developers.
- Higher software and hardware costs.
- Scalability can be expensive.
7. Explain DBMS vs RDBMS
A database management system supports the development and administration of database platforms. An RDBMS is an advanced version of a DBMS that saves data in a row-based table structure. The file storage used in RDBMS is different than DBMS.
Check out the table below to learn more about RDBMS vs DBMS
| Parameters | DBMS | RDBMS |
| Users allowed | Allows one user at a time | Multiple users at a time |
| Amount of Data | Handles a small amount of data. | Takes any amount of data |
| ACID Implementation | Doesn't Support | Supports |
| Database Normalization | DBMS cannot be normalized | RDBMS can be normalized |
| Data redundancy | Common in this model | Doesn't allow |
| Requirements | Less software and hardware | High software and hardware |
| Storage | File storage | Tabular structure |
| Distributed database | DBMS will not support | RDBMS provides complete support |
| Database structure | The hierarchical arrangement of data | Stores data in the form of rows and columns within tables. |
| Security | Lack of security | Good data security due to several log files. |
8. Name a few RDBMS Operators.
The RDBMS supports a variety of relational operations, such as
- Union operator
- Intersection operator
- Difference operator
- Join operator
9. Are object-oriented database management systems and RDBMS the same?
No. OODBMS stands for Object Oriented DataBase Management System. RDBMS is a relational database management system that stores the data as entities.
10. Why is ACID property important in RDBMS?
Specific properties are followed before and after each transaction to maintain database consistency. These are called ACID properties.
ACID properties in RDBMS
- Atomicity - The entire transaction occurs at once or doesn't happen.
- Consistency - The database must be consistent before and after each transaction.
- Isolation - Multiple transactions take place individually without interference.
- Durability - The chances of a successful transaction occurring even if the system fails.
11. What are the Types of Tables in RDBMS?
A table is a set of data elements organized into rows and columns. A single entry into a table is like a row or a record. There are several records in a table, and they can break down into smaller entities known as fields.
In RDBMS, there are two types of tables - master, and transactions. Identifying them during database development helps you understand how the system interacts with the database.
The below table helps us to decide whether the table is a master or transaction.
| Parameters | Master | Transaction |
| Changes | Data is likely to stay the same. | Data that often changes. |
| Timestamps | It may not require a timestamp with each entry. | Every transaction is usually associated with a timestamp. |
| Records | Less compared to the transaction table. | Records are more. |
| Partitions | Vertical partitioning for normalization. | Horizontal partitioning for easier querying. |
| Use | It stores system information. | It captures system events. |
| Indexed | Mostly no | Yes |
12. What are the most popular Relational Databases?
RDBMS is the optimal choice for data management in every business domain. Examples of popular relational database management systems include MySQL, Oracle, SQLite, SQL Server, PostgreSQL, and Microsoft SQL Server.
| Related Article: SQL Server Interview Questions |
13. Is SQL and RDBMS the Same?
RDBMS is a database management system. Whereas SQL is the language used to communicate with data in an RDBMS.
14. Name a few sub-systems of an RDBMS.
- I/O
- Language Processing
- Security
- Storage Management
- Process Control
- Logging and Recovery
- Transaction Control
- Lock Management
- Distribution Control
- Memory Management
15. What are Codd's 12 rules for Relational Databases?
- Information Rule
- Systematic Treatment of NULL Values
- Guaranteed Access Rule
- Comprehensive Data Sublanguage Rule
- Integrity Independence
- High-Level Insert, Update, and Delete Rule
- Non-Subversion Rule
- Active Online Catalog
- View Updating Rule
- Physical Data Independence
- Logical Data Independence
- Distribution Independence
Intermediate RDBMS Interview Questions
16. What's a SQL Query?
SQL stands for Structured Query Language. SQL lets you access the data stored within relational databases. Using SQL statements, you can store, update, remove, search, and retrieve data from the database. You can even use it to optimize and maintain the performance of the databases.
17. How many Components are there in RDBMS?
Here are the major components of the RDBMS

-
Table
A table is a collection of tuples or records comprising the values related to the attributes or columns in a table.
-
Tuple (A record)
In the database, data storage is in the form of various tuples, known as rows, under the attributes. The tuple, record, and row items are stored interchangeably here.
-
Column (Attribute)
Columns are commonly known as attributes. You can effectively map data using columns.
-
Domain
The domain of a database is the permitted value that a database can store.
-
Schema
A table's structure is known as its schema. The database schema comprises the columns and types of data they hold.
-
Constraints
These rules will apply to our data as it is added to and kept up in our database. We maintain our data's accuracy and integrity by using constraints. Depending on the use case, we may have limitations at the column or table level.
18. Describe a NULL Value.
Knowing the difference between a NULL value and other values, such as zero or fields with spaces, is crucial. In a table, a NULL value is in a field with no value. During the construction of a record, a field with a NULL value indicates that it was left empty.
19. What are the SQL Constraints?
The rules enforced on data columns in a table are known as SQL constraints. These limit the kind of information entered in the tables. As a result, the database's data is reliable and accurate.
Both column-level and table-level constraints are possible. Table-level constraints are applied to the entire table, whereas column-level constraints are to just one column.
Some of the most popular SQL constraints are listed below.
| Constraint | Description |
| NOT NULL | Stop the column from taking NULL values. |
| DEFAULT | Provides a default value for the column when none is specified. |
| UNIQUE | Ensure that all the values are different in the column. |
| PRIMARY KEY | Uniquely identifies each record in a database table. |
| FOREIGN KEY | Uniquely identifies each record in another database table. |
| CHECK | Ensure that all the values in a column satisfy specific conditions. |
| INDEX | Helps to create and retrieve records fast. |
20. Explain Data Integrity in RDBMS.
Data integrity refers to the complete consistency, completeness, and accuracy of data across its entire lifecycle. When data has integrity, mechanisms have been established to ensure that an unauthorized person or software cannot alter data-in-use, data-in-transit, and data-at-rest.
The major types of Data Integrity in an RDBMS are as follows
| Integrity Type | Description |
| Entity Integrity | This one states that a table cannot include any duplicate tuples. |
| Domain Integrity | This one directs us to save data in any specified column in the proper format, type, and range. |
| Referential Integrity | This one states that we cannot delete necessary records for accessing other records. |
| User-Defined Integrity | This one states that the rules given by the user when creating the database are consistently applied and verified before entering data into the database. |
21. What is Normalization in RDBMS?
Database Normalization is a process used to filter and organize data in a database. Normalization helps you to do the following:
Eliminates redundant data, thus permitting practical usage of available memory.
Ensures the data dependencies' logical consistency.
There are four primary normal forms that we need to understand
-
1NF or First Normal Form
We ensure that no multi-value records exist in a database when it is in the First normal form. For every attribute, there is only one value present in each record.
-
2NF or Second Normal Form
When a database is in the Second Normal Form state, it must adhere to all the requirements of 1NF. It is not permissible for any columns to depend partially on the primary key.
-
3NF of Third Normal Form
A database must be in 3NF normal form for it to be in BCNF form. You must also evaluate transitive dependency in addition to this. If the database uses BCNF, there shouldn't be any transitive dependencies.
-
BCNF or Boyce Codd Normal Form
The following requirements must be satisfied for a database to be in the third normal form
- The database must be in the second normal form.
- The primary key should be a requirement for each non-primary attribute.
22. What is the ER Model in RDBMS?
ER Model is an Entity-Relationship Model or high-level data model in RDBMS that represents the entity sets relationship. ER Models are used to outline the database design. By defining entities, attributes, and relationships, ER diagram describes the logical structure of databases.
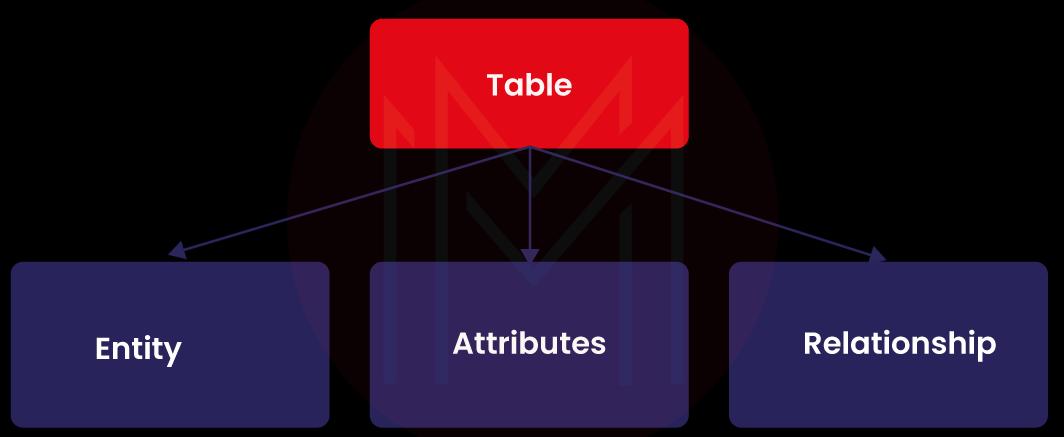
1. Entity
Any object physically and logically created in the real world is called an entity. Entities are of two types
- Strong Entity – Entity types with a key attribute are considered strong entities. The primary key uniquely identifies each entity. Because it cannot take null values, it cannot serve as a unique key.
- Weak Entity – Weak entities lack a crucial attribute. Its distinct identity is dependent upon some other powerful entity.
2. Attribute
An attribute is a characteristic or property of an entity. An entity can have numerous attributes.
There are five such attributes
- Simple attribute
- Composite attribute
- Single-valued attribute
- Multi-valued attribute
- Derived attribute.
3. Relationship
In a DBMS, a relationship primarily refers to the connection between two or more data sets. The datasets can communicate and store data in different tables because of relationships. They also assist in connecting various types of data.
Types of relationships
- One to One
- One to Many
- Many to Many
Advanced RDBMS Interview Questions
23. How is data abstraction achieved in RDBMS?
Data abstraction is the process of hiding unimportant user information. The developers conceal internal, irrelevant customer information to simplify database interaction for customers.
Three levels of abstraction exist
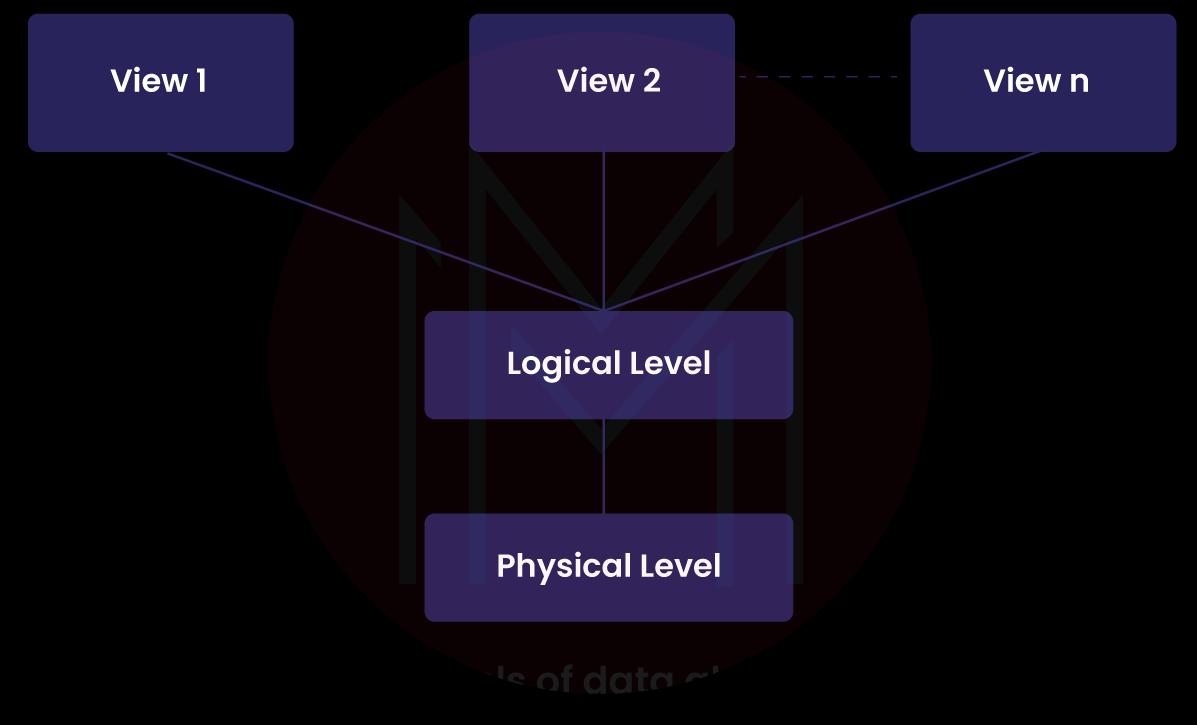
1) Physical: This is the most basic level of abstraction. It explains the storage of memory in records.
2) Logical: The database's current data comprises tables at this level—the relationship between the data items stored in comparatively simple structures.
3) View: The third level of abstraction is a view. The actual database is only partially visible to users.
24. What are the Types of Indexes in DBMS?
Indexes are unique RDBMS objects that let users quickly retrieve records from the database.
There are primarily two indexing methods
- Clustered Indexing
Cluster indexing is the term used to describe storing more than two records in a single file.
- Non-clustered or Secondary Indexing
It provides a list of virtual pointers or references to the location where the data is stored, i.e., it does not attempt to cluster the data. Data doesn't follow index order. Instead, leaf nodes include the data.
| Related Article: DBMS Interview Questions |
25. What is a Buffer Manager in RDBMS?
In RDBMS, the buffer manager allows relational operators, heap files, and access methods to read, write, allocate, and de-allocate pages. These operations are carried out on disc pages by the underlying DB class object, which the buffer manager invokes.
26. What are the different types of locks in RDBMS?
A database lock is a method that prevents two or more database users from updating a shared piece of data simultaneously. No other database user or session can edit the data once a single database user or session has obtained a lock. This limitation remains in place until the lock is released. There are two different types of locks, namely:
- Shared lock
Also known as a Read-only lock. The transaction in the share lock pattern can only read the data item.
- Exclusive lock
The transaction can read and write the data item in the exclusive lock.
27. What's the difference between Relational Algebra and Relational Calculus?
| Basis of Comparison | Relational Algebra | Relational Calculus |
| Language | Procedural language | Declarative language |
| Procedure | It means how to obtain the results. | It means what results have to obtain. |
| Order | The order is specified to perform the operations. | Order not specified. |
| Domain | Domain-Independent | Domain dependent |
| Programming language | Nearer to programming languages. | Nearer to natural language |
| Inclusion in SQL | Only a few relational algebraic features are present in SQL. | The tuple relational calculus forms the basis of SQL to a greater extent. |
| Query Evaluation | Query evaluation relies on the specification of the order in which you must perform operations. | The order of operations doesn’t matter for the evaluation of queries. |
28. Name a few types of Keys in an RDBMS.
- A super key is a collection of one or more keys that identify the database's rows.
- A primary key is a column or a set of columns that uniquely identifies each row in the table.
- A candidate key is a group of characteristics used to identify tuples in a table.
- An alternate key is a column or collection of columns uniquely identifies each row in the table.
- A compound key enables you to distinguish a specific record because it combines two or more characteristics. None of the columns in the database may be unique on their own.
- A composite key combines two or more columns to identify each row in a table in a unique way.
- A surrogate key is a made-up key that seeks to identify each record in a certain way.
29. What is the difference between DELETE and TRUNCATE?
The below table illustrates the differences between DELETE and TRUNCATE commands
| DELETE | TRUNCATE |
| Specific rows get deleted using the DELETE command (one or more). | While using this command, all the rows in a table get deleted. |
| It is a DML command (Data Manipulation Language). | It’s a DDL (Data Definition Language) command. |
| The DELETE command could include a "WHERE clause" for records filtering. | While the TRUNCATE command does not include a "WHERE clause." |
| A tuple gets locked before being deleted when using the DELETE command. | The data page is locked while this command runs before the table data gets deleted. |
| The DELETE command eliminates rows one at a time while adding a transaction log entry for each deleted row. | By reallocating the data pages used to store the table data, TRUNCATE Database removes the data from the table. It simply logs the page deallocations in the transaction log. |
| Compared to TRUNCATE, DELETE is the slower command. | The TRUNCATE command, however, is quicker than the DELETE command. |
| You require the table's DELETE permission to utilize Delete. | We require at least the ALTER permission on the table before using Truncate. |
| Using the DELETE Statement on the table leaves the identification of the fewer columns intact. | Identity If an identity column is present in the table, you can reset it to its seed value. |
| This command also has an active trigger option. | This command does not have an active trigger option. |
| Compared to Truncate, the DELETE statement uses more transaction spaces. | Truncate statements take up fewer transaction spaces than DELETE statements. |
30. What is the difference between Extension and Intention?
- Extension
The term "extension" refers to the total number of tuples in a table at any time and entirely relies on the time.
- Intension
Intention does not depend on time and describes the table's name, configuration, and restrictions.
31. Explain data Independence in RDBMS.
Data independence describes how freely any program can access the information it stores. It is for storage configuration and enables data modification presented in the database. There are two kinds of data independence:
- Physical Data Independence.
It allows the modification to be made in the physical point and won't affect the logical point.
- Logical Data Independence
It makes it possible to finish the modification at the logical level and affects the view level.
32. How is Denormalization different from Normalization?
- The normalization of datasets for analytical processing is low.
- It is used to extract data accumulated over a lengthy period and is old. Denormalization takes place for this reason, resulting in intelligent business applications.
- Dimensional tables in the star schema provide a compelling illustration of denormalized data.
- During extraction, transformation, loading, and processing, you must keep the denormalized form under control.
- The restriction that a user cannot view the state until it is consistent should be in place.
- On many systems without an RDBMS platform, it is utilized to boost performance.
Most Commonly Asked RDBMS FAQs
1. What is the difference between DBMS and RDBMS?
Database Management System is known as DBMS, and Relational Database Management System is known as RDBMS. Unlike RDBMS, which stores data in tables, DBMS stores data as a file.
2. What is SQL in RDBMS?
To create, update, and retrieve data in RDBMS, one must utilize the standard database language known as structured query language (SQL).
3. What are the Types of DBMS?
There are four types of DBMS
- Hierarchical Database
The data is stored using parent-child relationships in this DBMS. There are several different hierarchical database management systems.
To make data accessible and usable, they organize it in a way that resembles a tree. Similar to this, the tree's nodes contain the DBMS configuration.
- Network DBMS
Many-to-many relationships are supported by network DBMS, creating intricate database architectures. RDM Server best exemplifies the network DBMS.
- Relational DBMS
Relational DBMS uses tables, also known as relations or tuples, to store data based on database relationships. They offer many-to-many relationships but only predefined data types.
- Object-Oriented Relational DBMS
You can store various data types with this DBMS. It stores data in objects.
4. What are the Main Components of RDBMS?
A relational database management system comprises several components. Tables, records, attributes, instances, schemas, and keys form a relational database.
5. What is a Function in the RDBMS?
RDBMS provides four primary functions as follows −
- Security
It is one of the essential RDBMS functions. Rules are established by security management that permit access to the database. Additionally, this function limits the specific data that any user may see or write.
- Accuracy
Primary and foreign key concepts are used in relational database management systems to connect several tables. There is no data repetition. As a result, it eliminates the possibility of data duplication. RDBMS accuracy is, therefore, good.
- Integrity
Data integrity enforces the three constraints. Entity integrity means the use of a table's primary key.
- Consistency
The relational model in RDBMS offers the best data consistency for keeping data between application and database copies.
6. What are RDBMS examples?
Some examples of RDBMS include Oracle, Microsoft SQLServer, MySQL, and PostgreSQL.
7. Why do we use Triggers in RDBMS?
You can create a set of SQL statements that numerous applications can use by creating a trigger since it is stored in the database and is accessible to everyone with the necessary privileges. When multiple programs must carry out the same database operation, you can avoid redundant code by using triggers.
8. What are the uses of DBMS?
- Authentication and authorization configuration.
- It is simple to set up user accounts, specify access policies, and alter limitations and access scopes.
- Provide data backups.
- Performance tuning.
- Data recovery.
Here are a few Tips For Candidates To Clear RDBMS Interviews
Keeping in mind these tips improve your chances of clearing an RDBMS interview successfully
- Research is the first step in preparing for and passing the RDBMS interview. Learn about the organization, typical RDBMS interview questions, the degree of complexity, and the job role and responsibilities that go along with it.
- Make sure you prepare for both the technical and behavioral parts of the interview. By interacting with an RDBMS employee, you can learn essential details regarding the discussion that can help you focus your preparations.
- Explaining concepts with actual examples demonstrates your in-depth understanding of various concepts. Recruiters pay close attention to this.
- Any response you provide to the recruiter should be conveyed in a confident, straightforward, and understandable manner. The probability of making a favorable impression on recruiters is increased by the knowledge that is demonstrated confidently.
- Last but not least, be aware that the interview process includes several stages, each taking a lengthy time. The best way to prepare for an interview is to put in the necessary time, effort, and consistency.
Conclusion
This brings us to the end of our post on RDBMS interview questions, and there is a high probability that your interviewer will ask these questions. Be thorough with your responses. For more preparation, you can check out our RDBMS Training Courses.
Also, if you have attended an RDBMS interview recently, we urge you to post any new or tough questions you faced. So that our experts will come up with the best possible solution.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| SQL Server Training | Aug 01 to Aug 16 | View Details |
| SQL Server Training | Aug 04 to Aug 19 | View Details |
| SQL Server Training | Aug 08 to Aug 23 | View Details |
| SQL Server Training | Aug 11 to Aug 26 | View Details |

Madhuri is a Senior Content Creator at MindMajix. She has written about a range of different topics on various technologies, which include, Splunk, Tensorflow, Selenium, and CEH. She spends most of her time researching on technology, and startups. Connect with her via LinkedIn and Twitter .



