- Home
- Blog
- SQL Server
- BigQuery Interview Questions

- SQL Server Cluster
- SQL Server Constraints with Example
- Error Handling in SQL Server
- SQL Server Joins
- R Data Tables Tutorial with Examples
- SQL Server 2019: New Features
- SQL Server DBA Interview Questions
- SQL Server Interview Questions
- SQL Server Interview Questions for 2-5 Years Experienced
- Top 10 SQL Server Interview Questions for 5 years Experienced
- SQL Server Tutorial
- Creating a PowerPivot Data Model in Excel 2013
- How to Implement In-Memory OLTP SQL Server
- Creating a Power View Report in Excel
- What is PolyBase in SQL Server
- SQL Server In-Memory OLTP Architecture Overview
- In-Memory OLTP integration and application migration In SQL Server
- SQL Server In-Memory OLTP Investments
- Introducing Power BI for Office 365 – SQL Server
- Creating a Power Map Reporting Content from SQL Server
- Platform For Hybrid Cloud
- Database Testing Interview Questions
- Magento Interview Questions
- What is Magento - A Complete Tutorial Guide
- SQL Joins Interview Questions
- T-SQL Tutorial
- DBMS Interview Questions
- SQL Server Architecture - Detailed Explanation
- RDBMS Interview Questions
- DB2 Interview Questions
- Testing Connection to SQL Server
- How to Install Microsoft SQL Server?
BigQuery is a google-managed enterprise data warehouse with built-in features like business intelligence, geospatial analysis, and machine learning capabilities that allow you to manage and analyze the data.
MindMajix experts have compiled the most frequently asked BigQuery interview questions and answers to help you in the interview preparation process. These interview questions are classified into three levels: technical, experienced, and scenario-based. They cover many BigQuery-related topics and challenging questions for interview-preparing candidates.
Top 10 Frequently Asked BigQuery Interview Questions
- What are the benefits of GCP BigQuery?
- What are some Google BigQuery Components?
- What is BigQuery Storage?
- How can views be made with Google BigQuery?
- What is the difference between BigQuery and SQL?
- What is GCP App Engine?
- How can I get into the BigQuery Cloud Data Warehouse?
- What are some ways that Bigquery window functions can be used?
- Why is BigQuery faster than SQL?
- What type of database is BigQuery?
Big Query Technical Interview Questions
1) What is Google BigQuery?
Google BigQuery is a big data analytics web service that runs in the cloud and is designed to process very massive read-only data collections.
BigQuery is a fully managed, serverless data warehouse that enables petabyte-scale data processing. BigQuery's serverless architecture allows you to perform SQL queries to resolve your business's most pressing issues. Using BigQuery's distributed analytical engine, you may query terabytes in seconds and petabytes in minutes.
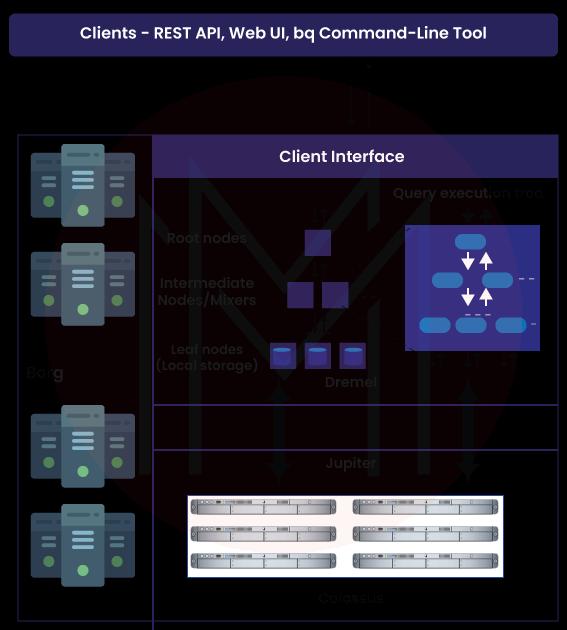
2) Describe the architecture of Google BigQuery.
Google BigQuery architecture consists of the majority of 4 parts. They are
- Dremel- It makes creating execution trees from SQL queries much easier.
- Colossus- It enables columnar storage and comes equipped with a compression mechanism, both of which are beneficial for data storage.
- Jupiter- It is helpful because it improves the CPUs and storage connection.
- Borg- It contributes to the regulation of error tolerance for the processing power of Dremel jobs.
| If you want to enrich your career and become a professional in SQL, then visit Mindmajix - a global online training platform: "SQL Server Training" This course will help you to achieve excellence in this domain. |
3) What are the benefits of GCP BigQuery?
Some of the GCP BigQuery benefits include
- BigQuery's Storage API makes it possible to read Spark and Beam workloads, which is a big assist for integration.
- BigQuery reduces the need to rewrite the code by supporting the standard SQL Dialect.
- Data can be replicated using BigQuery, and a seven-day history of changes can be kept to aid restoration and comparison.
4) What is Bigquery Query Cache?
Bigquery Query Cache is what makes the platform's data retrieval so swift.
BigQuery uses a temporary cached results table to save query results during the first execution. We call this "Query Cache" for short.
5) What are some Google BigQuery Components?
The following are the 12 components that make up Google BigQuery:
- Opinionated Storage Engine.
- Serverless Service Model.
- IAM, Authentication & Audit Logs.
- Batch Ingest.
- UX, CLI, SDK, ODBC/JDBC, API.
- Streaming Ingest.
- The Free Pricing Tier.
- Federated Query Engine.
- Pay-Per-Query & Flat Rate Pricing.
- Enterprise-grade Data Sharing.
- Public, Commercial, and Marketing Datasets
- Dremel Execution Engine & Standard SQL.
6) How should data be loaded into BigQuery?
The application known as BigQuery Data Transfer Service is the tool that should be utilized for the most successful loading of data into BigQuery. With the assistance of this tool, you will be able to swiftly and efficiently import data into BigQuery from various sources, including other services offered by the Google Cloud Platform.
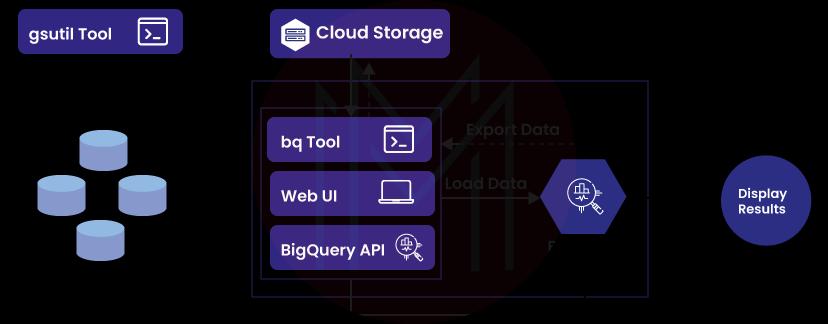
7) What is BigQuery Storage?
Data can be represented in BigQuery Storage using rows, columns, and tables, and the columnar Storage format, which is optimized for analytical queries, can be used to store the data.
BigQuery Storage also assists with storing the data. It supplies comprehensive assistance for database transaction semantics (ACID). It is possible to replicate it across many sites to provide high availability.
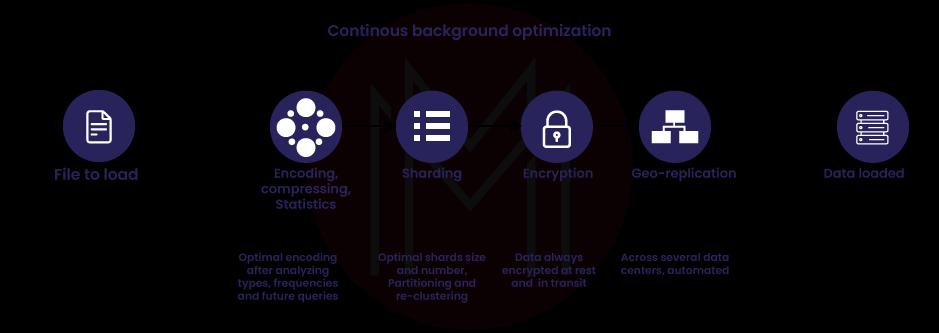
8) What do you know about sharding when it comes to BigQuery?
Sharding is the process of breaking data into smaller pieces so that it can be handled and managed more quickly and easily. When working with BigQuery, sharding, which is the process of dividing the data across multiple processors, can be used to speed things up overall.
9) What are some strategies for improving query computation in Big Query?
The following is a list of various approaches to optimize the computation of queries in Big Query:
- Utilize native UDFs whenever possible rather than user-defined functions written in JavaScript.
- Make advantage of the aggregate analytic process to retrieve the most recent record.
- It is recommended that optimization be performed on the table joining pattern.
10) What does it mean for BigQuery tables to be partitioned?
The performance of queries can be helped in BigQuery by partitioning tables. This enables the query engine to cut down the amount of data it needs to scan, improving query performance.
For instance, if you have a table with data for many different years, you may divide the database into partitions based on the years. Then, if you run a query that needs data from a particular year, the query engine can skip over the other partitions, saving you both time and resources.
| Related Article: Snowflake vs BigQuery |
Big Query Experienced Interview Questions
11) How does BigQuery convert a stringified array to an array?
Using the following command, we may convert a stringified array to an array from a BigQuery Table:
COMMAND:
#standardSQL
WITH k AS (
SELECT 1 AS id, '["a", "b", "c"]' AS x UNION ALL
SELECT 2, '["x", "y"]'
)
SELECT
id,
ARRAY(SELECT * FROM UNNEST(SPLIT(SUBSTR(x, 2 , LENGTH(x) - 2)))) AS x
FROM k12) How do I determine the BigQuery storage size for a single table?
Using the following command, we may determine the BigQuery storage size for a single table:
COMMAND:
select
sum(size_bytes)/pow(10,9) as size
from
<your_dataset>.__TABLES__
where
table_id = '<your_table>'13) How do you handle Google API Errors with Python?
Using the following command, we may handle Google API Errors with Python from a BigQuery Table:
COMMAND:
from googleapiclient.errors import HttpError
try:
...
except HttpError as err:
# If the error is a rate limit or connection error,
# wait and try again.
if err.resp.status in [403, 500, 503]:
time.sleep(5)
else: raise14) What Query would you use in GCP BigQuery to fetch each user between two dates?
Using the following command, we may fetch each user between two dates from a BigQuery Table:
COMMAND:
SELECT
timestamp_trunc(timestamp, DAY) as Day,
user_id,
count(1) as Number
FROM `table`
WHERE timestamp >= '2023-12-28 00:00:00 UTC'
AND timestamp <= '2023-12-27 23:59:59 UTC'
GROUP BY 1, 2
ORDER BY Day15) How can we delete the duplicate rows in the BigQuery Table?
Using the following command, we may delete duplicate rows from a BigQuery Table:
COMMAND:
SELECT *
FROM (
SELECT
*,
ROW_NUMBER()
OVER (partition by Fixed Accident Index)
row_number
FROM Accidents.Cleaned FilledCombined
)
WHERE row_number = 516) In Google BigQuery, how can we create a temporary table?
Using the following command, we may create a temporary table from a BigQuery:
COMMAND:
SELECT * INTO <TEMP TABLE>
FROM <name>17) Why is it necessary to use Google Cloud Storage as a secondary storage layer when loading data into BigQuery?
Google Cloud Storage is utilized as an intermediary storage layer to import data into BigQuery because of the reasonable pricing of the cloud data storage that it provides. You can significantly reduce the high expenses associated with cloud storage if you use Google Cloud Storage rather than one of the many other cloud storage providers.
18) What are the various ways to access BigQuery once configured?
Once BigQuery has been configured, it can be accessed in several ways.
- First, most users access BigQuery via the Google Cloud Console, a web-based administration and data analysis interface.
- A second option is to use the BigQuery command-line tool, which lets you communicate with BigQuery via the command line and issue queries.
- Last but not least, BigQuery may be integrated with various third-party tools that offer additional features and capabilities.
19) What is the best way to make sure that data stored in BigQuery is in line with GDPR rules?
Encrypting data before it is stored in BigQuery is the most effective technique to ensure that a company complies with the standards set forth by the GDPR.
Since BigQuery offers a variety of encryption strategies, you are free to choose and choose the one that works best for your organization. Consider implementing a data access control system to ensure that only individuals with a legitimate need for the information can access it.

20) How can views be made with Google BigQuery?
You are given the ability to develop views with Google BigQuery. You can use the command line interface (CLI), the BigQuery online UI, or the API to accomplish this. Before developing a view, you will need first to make a dataset. You can generate a view after that dataset has been created.
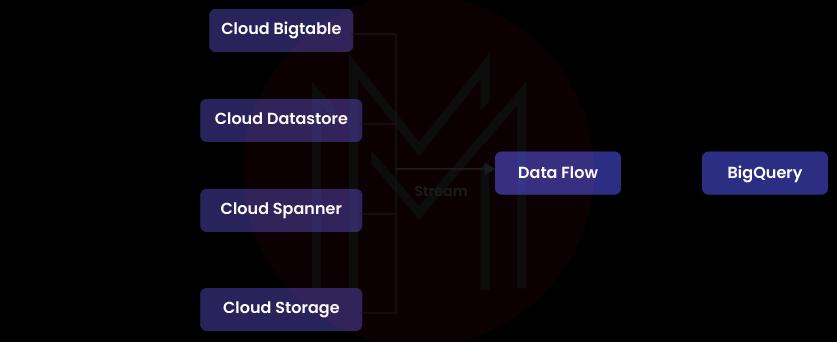
21) How does data loading work in Google BigQuery?
Google BigQuery supports multiple input formats when receiving data.
BigQuery's web-based user interface is another option for transferring data files. In addition to importing data from a local file or a Google Cloud Storage bucket, the BigQuery command-line tool can do the same for a Google Cloud Datastore bucket. BigQuery's application programming interface (API) then lets you import records from numerous sources.
22) What are the two kinds of jobs that BigQuery can do?
- Interactive query jobs: BigQuery's default settings have it set to execute interactive (on-demand) query tasks as quickly as possible.
- Batch query jobs: BigQuery will queue each batch query on your behalf when you use these jobs. It will begin processing the Query as soon as idle resources become available, often within a few minutes.
23) What is the difference between BigQuery and SQL?
Google BigQuery is a cloud-based architecture that offers remarkable performance due to its ability to auto-scale up and down depending on the amount of data load and rapidly perform data analysis.
On the other hand, SQL Server employs a client-server architecture and, unless the user scales it manually, maintains a constant level of performance throughout the system.
24) Can you explain what a BigQuery columnar database is and how it works?
A database that organizes its data into columns instead of to rws is known as a columnar database. BigQuery is a columnar database that contains data in columns rather than rows, like traditional relational databases (RDMS) do. Because of this, it is an excellent choice for storing massive volumes of data and conducting queries on that data.
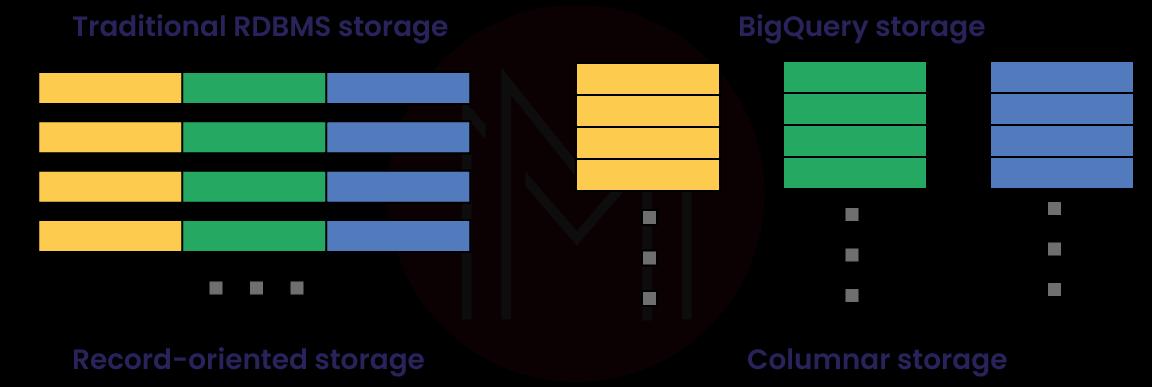
25) What features does Google BigQuery have?
Below are some of the Google BigQuery features, including
- BigQuery Omni: It's a multi-cloud analytics solution that's fully managed, so we can use it to perform analyses across AWS and Azure, for example.
- BigQuery ML: It makes it possible for all data analysts to construct and operationalize machine learning models on structured or semi-structured data at planet size directly inside BigQuery, using simple SQL and doing so in a fraction of the time previously required.
- BigQuery GIS: It is utilized to connect the serverless architecture of BigQuery with the native support for geospatial analysis, which enables you to enhance your analytics processes with location intelligence.
- BigQuery BI Engine: It is used in the analyzing service created in BigQuery, enabling users to interactively examine huge and complicated datasets with a query response time of less than one second and high concurrency.
Big Query Advanced Interview Questions
26) How do you fix the most common SQL errors in BigQuery?
Check that your Query follows the proper syntax using the Query Validator. If you try to run a query that already has errors, the attempt will fail, and the error will be logged in the Job details. The query validator will show a tick in the green box whenever there are no problems with the Query. Click the Run button to execute the Query and see the results after the checkmark appears in the green box.
27) Can you explain what makes legacy SQL different from standard SQL?
Using standard SQL to query data in BigQuery is the most up-to-date and recommended way. The SQL:2011 standard, on which it is based, provides numerous enhancements over older versions of the language. Performance enhancements, more assistance for SQL standard features, and enhanced compatibility with other SQL-based systems are only some of how this has been enhanced.
Legacy SQL is a way of querying data in BigQuery that predates the SQL:2003 standard. While traditional SQL is still supported for compatibility reasons, it is strongly recommended that you use more modern forms of the language whenever possible.
28) What kinds of reports can be generated using BigQuery data?
The following reports are examples of those that can be generated from the data contained in BigQuery:
- Inventory reports
- Marketing reports
- Sales reports
- Product reports
- Customer reports
- Financial reports
29) What is GCP App Engine?
Google Cloud Platform App Engine provides and ensures our application's capacity and availability. It is done by supplying the capability.
It is responsible for offering built-in services and APIs, managing the servers and infrastructures on our behalf, and controlling the traffic to our websites.
When it comes to the construction of our application, GCP App Engine offers interaction with a variety of development tools, like GIT, Eclipse, Jenkins, and Maven, among others, so that our workflow is not disrupted.
30) What are BigQuery's Window Functions?
Functions that aggregate to a single value for a set of rows are called "window functions," They're helpful for computing values over a set of rows and returning just that result.
It has three different kinds of functions, such as:
- Navigation function: The navigation function returns a value based on a specific location.
- Numbering function: Numbering functions are used to give each row a number that is based on where it is in the window.
- Analytic function: Analytic functions are used to do the math on a set of values.
31) How can I get into the BigQuery Cloud Data Warehouse?
The following are methods for connecting to the BigQuery Cloud Data Warehouse:
- ODBC Drivers
- Web User Interface
- JDBC Drivers
- Python Libraries
- BQ Command-line Client
32) What is a Big Query time decorator?
Using time decorators in Big Query enables access to historical data. For instance, if you accidentally deleted a table an hour ago, you may still retrieve the data from the table using a time decorator.
33) How much information can BigQuery deal with?
BigQuery was explicitly developed to manage massive data collections. It can store up to 10 petabytes of data and can analyze up to 100 terabytes of data every single day.
34) What does it take to set up BigQuery?
The procedure of installing and configuring BigQuery is simple enough. After establishing a project in the Google Cloud Console, you can activate the BigQuery API. Creating a project is the first step. After enabling the API, you can begin creating datasets and running queries.
35) What are some ways that Bigquery window functions can be used?
Here are some ways that Big Query can be used with window functions:
- To figure out the total amount.
- To figure out the moving average.
- To put rows in order based on specific criteria.
36) How to convert from one type of data to another in Big Query?
Big Query's conversion methods allow for the explicit transformation of data types. The following syntax can be used to convert an expression to a string:
CAST (expr AS STRING)37) What is the maximum size of a table that BigQuery can create?
In BigQuery, the size of a table you build is not limited by a maximum value.
38) Does Google BigQuery permit sharing data and queries with the public? If so, explain how?
The answer is yes; you can publicize your searches and data on Google BigQuery. You can implement this by launching a project, discussing it with specific people, or making it available to the general public.
39) Is BigQuery PaaS or SAAS?
Google's BigQuery is a fully managed serverless data warehouse that supports scalable analysis of data sets up to several petabytes in size. A cloud computing environment that supports ANSI SQL queries.
BigQuery FAQ'S
1) Is BigQuery an OLAP or OLTP?
BigQuery is a solution for OLAP, which stands for online analytical processing.
BigQuery is best suited for large workloads, such as regular OLAP reporting and archiving activities. It is because query latency is significant in BigQuery. BigQuery's architecture discourages OLTP-style queries.
2) Is BigQuery an ETL tool?
Yes, BigQuery and Snowflake are two of the best ETL software solutions for businesses that want to manage their data from various sources and get the most out of their data insights. These businesses aim to gain as much as they can from their data.
3) Why is BigQuery faster than SQL?
The query engine can process petabyte-scale data using standard SQL queries in seconds, and terabyte-scale data takes only minutes. BigQuery delivers tremendous efficiency with no requirement for index creation, infrastructure maintenance, or rebuilding. Because of its speed and scalability, BigQuery is well-suited for processing massive datasets.
4) Why does BigQuery use SQL?
Both the Google Standact and legacy Sdialectsect are available for use with BigQuery.
BigQuery supports the Google Standard SQL dialect. If you are unfamiliar with BigQuery, you should start with Google Standard SQL because it has the most comprehensive features. For instance, features such as DDL and DML statements are only supported when using Google Standard SQL.
5) Does BigQuery need a schema?
When creating an empty table or loading data into an existing one, BigQuery allows you to choose the table's schema. On the other hand, you can utilize schema auto-detection to find out what file formats can be used to store your data.
6) What type of storage is BigQuery?
BigQuery's data storage is a fully managed service. No need to set aside storage space or reserve a certain amount of storage capacity. When you upload data to BigQuery, the service immediately begins allocating storage space. Only the space you actually use will be charged to you.
7) Is BigQuery structured or unstructured?
BigQuery is intended for typical SQL queries on structured and semi-structured data. It is extremely cost-effective and highly optimized for query performance. BigQuery is a fully managed cloud service; therefore, there is no operational overhead.
8) Is BigQuery a data lake?
Yes, A data lake, notably the popular and convenient Google BigQuery, is the greatest solution to store data. The data lake on Google Cloud drives any study on any sort of data.
9) What type of database is BigQuery?
BigQuery is an entirely managed enterprise data warehouse that offers built-in technologies like geospatial analysis, machine learning, and business intelligence to assist you in analyzing and managing your data.
10) How many slots does BigQuery have?
Depending on the size and complexity of each query, BigQuery determines how many slots are needed. At each level of the query, separate units of work are carried out by BigQuery slots. For a certain step of a query, BigQuery can ask for an unlimited number of slots.
For example, If BigQuery finds that the best parallelization factor for a stage is 10, it asks 10 slots to process that stage.
Tips to Prepare for BigQuery Interview
- Prepare questions in advance- There is nothing wrong with having a brief list of questions and thoughts; it demonstrates that you have done your research and are interested in learning more about the company and the position.
- Review the job specifications- Check the role's responsibilities. Include at least one example from your past that shows how you met the standards. You will be ready with an example when the interviewer asks about the criterion.
- Focus- Don't make excuses for your lack of experience; instead, put the focus where it belongs: on your traits, your transferrable talents, and your willingness to learn.
- Use the right words- You should speak professionally during the interview. Be careful about using bad slang or talking about age, race, religion, politics, or sexual orientation. These things could get you kicked out of a place very quickly.
- Close on a positive note- Convey your appreciation for the interviewer's time and emphasize your want to work for the company. Leave quickly and courteously with a handshake and a smile.
Conclusion
We've covered all the Google BigQuery interview questions and answers that will likely ask during the interview. If you are thinking of preparing for a BigQuery interview, check out all these important questions to ace the interview well. To learn more, have a look at our Google SQL Server Training.
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| SQL Server Training | Jul 28 to Aug 12 | View Details |
| SQL Server Training | Aug 01 to Aug 16 | View Details |
| SQL Server Training | Aug 04 to Aug 19 | View Details |
| SQL Server Training | Aug 08 to Aug 23 | View Details |

Hari Kiran is an accomplished Database Engineer with an extensive 17-year career spanning various IT domains, including healthcare, banking, project & portfolio management, and CRM. He brings a fervent dedication to PostgreSQL and has provided invaluable support to clients worldwide, offering expertise in database administration, enterprise deployments, security enhancements, backup and recovery strategies, and performance optimization. Hari has held positions at renowned organizations such as GE, EDB, Oracle, Optum, and 2ndQuadrant. Currently, Hari is leading Customer Success at pgEdge and continuing his Entrepreneurial journey with OpenSource DB. Additionally, he is a sought-after speaker at PostgreSQL conferences like FOSSASIA Summit, PGConf India/ASIA, and PGConf Down Under in Australia.



