- Home
- Blog
- SQL Server
- SQL Server 2019: New Features

- SQL Server Cluster
- SQL Server Constraints with Example
- Error Handling in SQL Server
- SQL Server Joins
- R Data Tables Tutorial with Examples
- SQL Server DBA Interview Questions
- SQL Server Interview Questions
- SQL Server Interview Questions for 2-5 Years Experienced
- Top 10 SQL Server Interview Questions for 5 years Experienced
- SQL Server Tutorial
- Creating a PowerPivot Data Model in Excel 2013
- How to Implement In-Memory OLTP SQL Server
- Creating a Power View Report in Excel
- What is PolyBase in SQL Server
- SQL Server In-Memory OLTP Architecture Overview
- In-Memory OLTP integration and application migration In SQL Server
- SQL Server In-Memory OLTP Investments
- Introducing Power BI for Office 365 – SQL Server
- Creating a Power Map Reporting Content from SQL Server
- Platform For Hybrid Cloud
- Database Testing Interview Questions
- Magento Interview Questions
- What is Magento - A Complete Tutorial Guide
- SQL Joins Interview Questions
- T-SQL Tutorial
- DBMS Interview Questions
- SQL Server Architecture - Detailed Explanation
- RDBMS Interview Questions
- BigQuery Interview Questions
- DB2 Interview Questions
- Testing Connection to SQL Server
- How to Install Microsoft SQL Server?
Introduction to SQL Server 2021
Microsoft, owing to the new demands and other technological advancements in the software industry, has released the upgraded version of SQL Server 2021, which is SQL server 2021. This was announced and introduced in the Ignite 2018 event, on September 24th. However, this was just a preview edition. A more technically advanced and detailed picture of SQL Server 2021, was submitted only in the PASS Summit, which happened later in November, in the same year.
The newer version of the SQL server has come up with higher-end integration of modules such as Azure SQL Database, Apache Kafka Support on Azure Event Hubs, Azure SQL Data Warehouse and Hadoop Distributed File System (HDFS), all packed together to provide a single, integrated solution
Microsoft SQL Server 2021 is built with an aim to take the Artificial Intelligence (AI), a step forward, by integrating Big Data with the Database services.
If you want to build your career with an SQL Server certified professional, then register here SQL Server Training Course. This course will help you to achieve excellence in this domain.
Table of Contents
Top 8 SQL Server 2021 Features
There are many advancements made to SQL server 2021 to release the new version, which is SQL Server 2021 making it more efficient and stable. These new features are discussed below in detail.
1. Big Data Clusters
Big data clusters are new additions to the SQL server 2019 release. This feature allows you to deploy multiple, scalable clusters of SQL Server, Spark, and HDFS containers running on Kubernetes, at once. The Big data Cluster, as an infrastructure, allows these clusters to run parallelly, where you can read, write, and process Big Data from Transact-SQL to Spark. It enables us to easily combine and analyze the high-value relational data with high-volume big data.
Features:
- Data Virtualization: SQL Server PolyBase has eased the task of querying the external data sources for the SQL Server big data clusters, by reducing the effort of moving or copying the data for making a query. SQL Server 2019 preview has introduced new connectors to data sources.
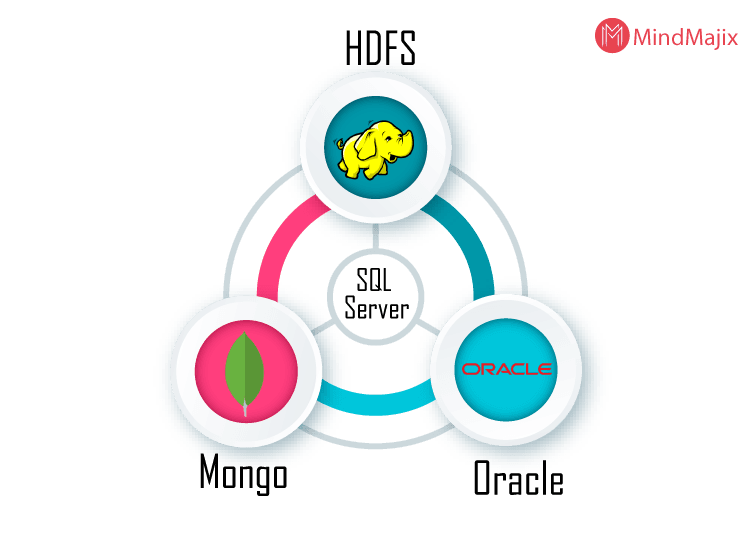
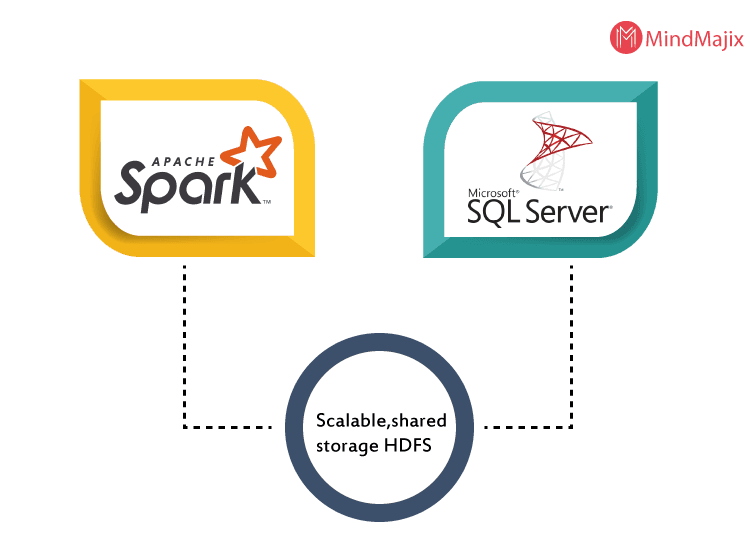
- Data Lake: The big data cluster allows for a scalable HDFS storage pool. This potentially increases the efficiency of big data storage from external sources.
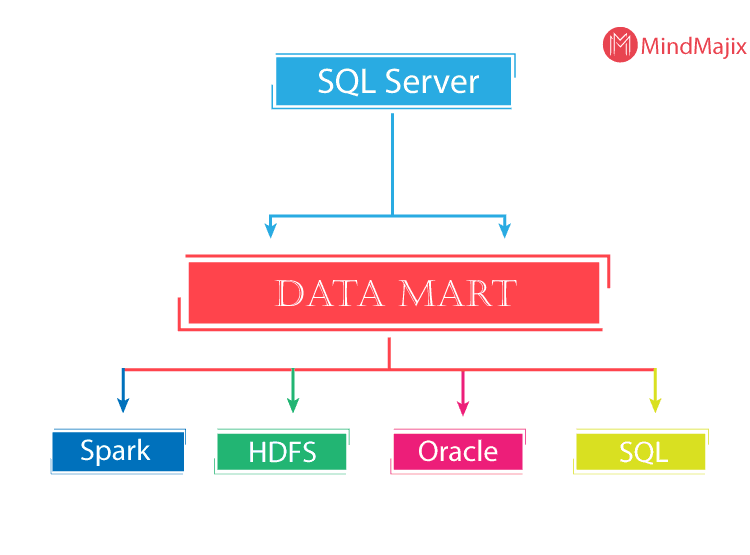
- Scale-out data mart: Big data cluster provides scale-out compute and storage to improve the data analysis. The data can be ingested and stored across multiple data pool nodes as cache, for further analysis.
- Integrated AI and Machine Learning: The big data cluster allows for AI and ML on the data stored across multiple HDFS storage pools and data pools. SQL server provides many built-in AI tools like R, Python, Scala or Java.
- Management and Monitoring: The cluster administrator portal is the website that provides the status and health of the pods in the cluster. It also provides links for other dashboards for log analytics and monitoring.
- Management and monitoring will be done using the combination of the command line tools, APIs, administrator portal and dynamic management views.
[Related Page: New SQL Server Cluster]
Advantages of Big Data Cluster:
- Has built-in snippets for regular management tasks.
- Allows browsing HDFS, to create directories, to preview files and upload files.
- Allows creating, opening and running Jupyter-compatible notebooks.
- The creation of external data sources has been simplified by the Data Virtualization Wizard.
- Big data cluster with K8 infrastructure increases the speed of setting up the whole group infrastructure.
- The security concerns arising with the integration of the relational environment with the Big Data are handled completely by the big data clusters.
- The data virtualization allows for easy data integration without having to perform ETL (extract, transform, and load).
2. UTF-8 Support
The new SQL Server 2019 supports the very popular UTF-8 data encoding system. The UTF-8 character encoding is employed in data export, import, database-level, and column -level data collation. It is enabled when creating or changing the object collation type to object collation with UTF-8. It is supported for char and varchar data types.
The reason why data has to be encoded while storing and retrieving is mainly because of 2 reasons.
- For reducing the memory occupancy or storage space.
- To provide data security for sensitive data.
Note: As of Microsoft SQL Server 2016, UTF-8 is supported by BCP, BULK_INSERT, and OPENROWSET.
The earlier versions of SQL Server had encoding done in different formats like UCS-2 and they did not support the UTF-8 format. However, the introduction of Unicode encoding was done only from SQL Server 7.0.
[Related Page: Exception Handling In SQL Server]
Advantages of UTF Encoding:
This feature helps in storage saving, by using the right character set. For example, changing the existing data type of column with Latin strings from NCHAR(10) to CHAR(10) using a UTF-8 enabled collation, leads to 50% reduction in storage requirements. This saving happens because NCHAR(10) requires 20 bytes for storage, whereas CHAR(10) requires 10 bytes for the same Unicode string.
CTP 2.1 allows selecting UTF-8 collation as default during SQL Server 2019 preview setup.
CTP 2.2 allows selecting to use UTF-8 character encoding with SQL Server Replication.
3. Resumable Online Index Create (CTP 2.0)
This is the feature that allows an index to create operation to pause and resume later, right from the point where the operation failed or paused, instead of starting the process all over again.
The index is one of the powerful tools for database management. With more operations on databases like insert, update and delete, the index becomes more fragmented and hence less efficient. In order to combat this, index rebuild operations are increasingly adopted by the DBAs.
Resumable Online Index Rebuilding (ROIR) was adopted from SQL Server 2017 as an important feature to enhance database performance.
However, in the SQL Server 2019 version, a newer version of the feature is incorporated, which is "Resumable Online Index Create"
Features of the Resumable Online Index Create
- You can resume the index create operation after an index creates failure in case of overuse of disk space or during database loss.
- Pausing the ongoing index create operation in case of blockages will result in freeing up the resources temporarily, to resume the blocked tasks.
- The heavy log generation due to the cumbersome index creation operation can be handled by pausing the index create operation, truncating or taking the backup of the log and then resuming the same.
In the older versions, when this feature was not introduced, upon the new index creates operation failure, the whole process had to start from the beginning.
The SQL Server 2019 also allows setting this as a default feature for a specific database.
[Related Page: SQL Server Constraints With Example]
4. Intelligent Query Processing (CTP 2.0)
The feature of Intelligent Query Processing (IQP) is a method adopted to obtain an optimal query execution plan with lower compiler time. This feature is expanded to include many other sub-features in the SQL Server 2019, CTP 2.2.
There are many factors considered while executing IQP, mainly to generate a good enough execution plan. These factors are Structures to be used, Joins to be made in a query (Hash Join, Nested Loop, Merge Adaptive, etc.), Outer Input, execution mode (Batch or Row execution mode), etc.
SQL Server 2017 had the feature of Intelligent Query Processing with the following sub-features:
- Adaptive joins in Batch Mode to dynamically select a join type during the runtime or execution time, based on the input rows.
- Interleaved Execution under the Compatibility Level 140, which uses the cardinality of a multi-statement table according to the values encountered on the first compilation, rather than a fixed guess.
- Memory Grant Feedback (Batch mode) to handle the memory allocation. If a batch mode query has operations that demand extra disk space, more memory will be allocated for it, in the consecutive executions. While, if the query uses less than 50% of the allocated memory, the memory grant will be reduced from the consecutive executions.
There are, however, many improvements made in the IQP for the SQL Server 2019 CTP 2.0 preview version. These features are:
- Starting from SQL Server 2019 CTP 2.0, the server provides an approximate Count Distinct for the big data scenarios. Count Distinct returns the approximate number of unique non-null values in a group. This feature reduces the memory footprint, hence increasing performance efficiency.
- Batch mode on Row store is allowed in the 2019 version, under compatibility level 150, which provide the batch mode on for the CPU bound relational DW workloads. This feature does not require having column store indexes.
- Memory Grant Feedback (Row Mode) to handle the memory allocation in Row Mode. If a row mode query has operations that demand extra disk space, more memory will be allocated for it, in the consecutive executions. While, if the query uses less than 50% of the allocated memory, the memory grant will be reduced from the following executions.
- Scalar UDF Inlining is adopted to bring larger performance gains. This mainly deals with transforming the scalar UDFs into equivalent relational expressions, which are "inlined" into calling the query.
- Table Variable Deferred Compilation which slightly differs from the interleaved execution. This feature uses the actual cardinality of the table variable encountered on the first compilation instead of a fixed guess.
[Related Page: R Data Tables Tutorial With Examples ]
5. Always On Availability Groups
Always On availability groups is a disaster-recovery and a high-availability (HA) solution that aims at providing an enterprise-level alternative to database mirroring. This feature was initially introduced for SQL Server 2012, to increase the availability of a set of user databases for an enterprise.
An availability group is designed to support the replicate environment for a set of user databases called availability databases. An availability group can be either created for High Availability (HA) or for read-scale.
The failure of an availability group happens at the level of an availability replica. Availability database incurs, failover all together.
Features of Always On availability groups in SQL Server 2017
SQL Server 2017 introduces two sets of availability groups, differentiated on the basis of their architecture.
Always On availability groups
This provides high availability, disaster recovery, and read-scale balance. The availability groups here use the cluster manager in case of a cluster failover. In Linux, Pacemaker is used for the same while, Windows uses a cluster manager.
Read-scale availability group
This architecture provides replicas only for the read-only workloads. They don't provide the High Availability. There is no Cluster manager used in a Read-scale availability.
Every set of an availability database is hosted by an availability replica. The 2017 SQL Server version provides only 2 types of the replica. They are the primary replica and the secondary replica. An availability replica supports with redundancy only at the database level.
[Related Page: Different Types Of Joins In SQL Server]
New Added Features of SQL Server 2019
Apart from the existing features of the SQL Server 2017, there are new improvements and additions made to the SQL Server 2019.
- Unlike the older version, SQL Server 2019 increases the maximum number of replicas from 2 to 5. Out of 5 replicas, 1 is the primary replica, while the other 4 are the secondary replicas. You can configure these 5 replicas to handle the group failover.
- Secondary-to-primary replica connection redirection:
- This allows the client connections to be redirected to the primary replica, regardless of the target specifications in the connection string. This connection provides the connection redirection without a listener.
- Use secondary-to-primary replica connection redirection in the following cases:
- The listener capability is absent in the cluster technology.
- When the redirection becomes complex in a multi-subnet configuration.
- Scenarios of the read-scale out or disaster recovery, where the cluster type is NONE.
- SQL Server 2019 provides for an ability to configure Always on Availability Groups using Kubernetes as an orchestration layer in place of the Windows cluster failure.

Advantages of the new features of Always On availability groups in SQL Server 2019
- Increased number of availability replicas improve the availability during the disaster recovery phase. For each availability database, a set of 4 secondary replicas and one primary replica are available for recovery.
- The secondary to primary replica redirection improves the efficiency of database management.
- Always On availability groups ensures that resource management is made efficiently and the database availability is improved.
6. Machine Learning on Linux
Microsoft has always been keen on mixing up the data and the code. Microsoft SQL Server has seen a transition of this trend from T-SQL, to Azure-focused U-SQL, which then extended T-SQL with C# elements. SQL Server then added an embedded R support in 2016. In 2017, this focus was extended to the addition of Python to the SQL Server. This has insanely attracted the Machine Learning enthusiasts who are not even introduced to SQL Server!
Microsoft has always looked up to introduce new features that would make the SQL Servers on Linux get in parity with the SQL Server on Windows. Some of the improvements in Machine Learning, made in SQL Server 2019 on Linux, are discussed below.
Features of Machine Learning on Linux in SQL Server 2017
There are many advantages of having Python and R embedded in the SQL Server. Some of them are listed below:
- Having Python embedded on SQL Server lets you take advantage of the Microsoft scaling and performance features, by gaining direct access to the in-memory database features and speeding up the OLAP requests.
- The code executed will be in the form of stored procedures. This enables the SQL developers to just get the procedure and execute without having to worry about the code, while the data-scientists can take care of the written scripts. This ensures data security.
- The dual support to the R and python in SQL server has been a logical move to Microsoft. Since it runs both on the platform and on the cloud, SQL servers can work with the traditional big data sources with all the data.
New Added Features of the Machine Learning in SQL Server 2019
- Besides R and Python, the new Java language extension is added to the SQL Server.
- AppContainers have replaced the local user accounts under SQL Restricted User Group (SQLRUserGroup).
- The membership availability of SQLRUserGroup has changed. Instead of the multiple local user accounts as in the previous version, SQL Server is just having a Launchpad service account. All the processes of R, Python, and Java, now execute under the Launchpad Service identity, isolated from the AppContainers. [
[Related Page: R Data Tables Tutorial With Examples ]
7. SQL Server on Linux
- One of the biggest improvements of the SQL Server 2019 is the addition of the big data clusters. Enhanced big data integration is one of the major areas of focus for Microsoft SQL Server 2019.
- The big data clusters are supported on a number of technologies including SQL Server on Linux in Docker containers, Apache Spark, Hadoop, and Kubernetes. The big data clusters developed, allows the user to deploy the scalable cluster containers on Kubernetes, which can read, write, and process the big data using the T-SQL.
- The big data cluster is made of the SQL Server and Spark Linux containers. Linux containers use the Kubernetes for container management and orchestration. Multiple Docker containers on a scalable group of nodes comprise the compute tier, on which the queries run parallelly. Advanced analytics and Machine Learning is well supported by Spark. Here, the big data clusters are managed by the master instance of the SQL Server.
- Some of the other direct improvements for SQL Server on Linux in 2019 are the extended support for transactional replication and distributed transactions.
- SQL Server 2019 on Linux instances can participate in the snapshot, merge, and transactional replication topologies as a subscriber, publisher or distributor.
- The support for Microsoft Distributed Transaction Coordinator (MSDTC) allows for distributed transactions on Linux instances of SQL Server. This was made possible through the new Linux version of MSDTC that runs within the SQL Server process.
- SQL Server 2019 on Linux has better integration with Active Directory, which provides functionalities like user authentication, replication, distributed queries, and AGs. Furthermore, it also has OpenLDAP support for third-party AD providers. It also provides for in-database machine learning.
- SQL Server 2019 on Linux has come up with a new Red Hat Enterprise Linux (RHEL)-certified Docker container image: docker pull mcr.microsoft.com/mssql/rhel/server:2019-CTP2.1
- Microsoft also has come up with a new master container registry. This registry is meant to support existing catalogs like Docker Hub, Red Hat Container Catalog, and Azure Marketplace.
8. Enhanced Security
Since SQL Server is directly dealing with the database management and procuring, the security of the transactions and the data involved forms one of the most important requirement.
Security for accessing the SQL servers is managed by certificates. The new security feature of SQL Server 2019 includes Certificate management in SQL Server Configuration Manager (CTP 2.0). This certificate authenticates the secure access to SQL Server instances. The certificate management is now dedicated to SQL Server Configuration Manager, hence easing other tasks such as:
- Viewing and validating the certificates installed in the instance of SQL Server.
- Managing certificates that are nearing the expiration.
- Managing the certification deployment across machines, which are participating in Always On Availability Groups.
- Managing the certificates deployment across machines, participating in failover cluster instance.
Always Encrypted was used as the Microsoft solution for data security. However, there are certain limitations to this method, where simple functions like mathematical operations cannot be performed on the encrypted data.
To overcome this, a new technology called "Secure Enclaves" is adopted which allows simple functions like the aggregate functions and LIKE queries to be executed on the Always Encrypted data.
Microsoft SQL Server 2017 vs 2019
Below are a few distinctive features that differentiate the SQL Server 2017 version from SQL Server 2019.
| Topics | SQL Server 2017 | SQL Server 2019 |
| Big Data clusters | Was not included | A new feature of big data cluster incorporated to handle the big data problems |
| Security | Always Encrypted” feature encodes data. Encoded data cannot handle any mathematical or relational operations on them. | “Secure Enclaves” improvises over the previously encoded data by allowing the basic mathematical or relational operations on encoded data. |
| Intelligent Query Processing | Adaptive Joins in batch mode and memory feedback in batch mode supported. | Along with previous version features, includes memory feedback in row store mode and Scalar UDF Inlining. |
| Indexes | Resumable Online Index Rebuilding | Resumable Online Index Create |
| Always On availability groups | 2 replicas |
5 replicas Secondary to primary index replica redirection |
| Linux | Doesn’t support the OpenLDAP | Supports OpenLDAP |
[Related Page: Hybrid Cloud With SQL Server ]
Standard SQL Server 2019: Standard Edition Vs. Enterprise Versions
This section deals with the introduction to the Standard and Enterprise Editions of SQL Server 2019 and the differences between them.
Standard: Standard provides the basic functionalities of databases like reporting, analysis, basic availability features, disaster-recovery, etc.
Enterprise: Enterprise version has all the Standard edition features along with some additional, advanced features. This version is suitable for companies that are looking for high scalability and performance.
Below are a few differences between the standard and the Enterprise edition
| Topics of difference | Standard Edition | Enterprise Edition |
| Performance and Scalability | Basic support for scalability and limited performance compared to Enterprise Edition. | Provides better scalability and performance |
| Support | Supports for 128 GB | Supports up to 524 petabytes |
| Security | Provides basic auditing, contained databases, encryption and backups, and user-defined roles | Provides fine-grained auditing, transparent database encryption, and extensible key management apart from the basic Standard Security features |
| Replication | Provides the fundamental SQL Server change tracking, merge replication, and snapshot replication. | Provides the high-end Oracle publishing and peer-to-peer transactional replication, besides the basic Standard edition replication capabilities |
Only 3 of the 11 features of the Enterprise edition are there in Standard edition when it comes to scalability and performance. Hence, the users should be wise enough to choose the enterprise edition, in case of any foreseen scalability.
Frequently Asked SQL Server Interview Questions
Why You Should Upgrade from SQL Server 2017 to 2019 Version?
Microsoft has been very strategical in bringing the enhancements and features to every SQL Server Version. A new version is brought, always with an ode to the limitations of the previous version and with a new target in mind. Below are some reasons as to why one should upgrade to SQL Server 2019.
1. Big Data Capabilities
The SQL Server 2019 is brought with a focus to enhance the big data capabilities and improvised Machine Learning experience and Linux SQL Server performance.
As most of the companies are adapting to the big data, it is important to incorporate the features that support big data, in SQL Server. The SQL Server 2019 has developed big data clusters, which handles all the tasks related to big data. However, this feature was not implemented in the SQL Server 2017.
2. SQL Server performance on Linux
Microsoft has always aimed at enhancing the SQL Server to adapt to multiple platforms like Windows, Linux, and Mac OS. There are continuous efforts made to match the performance in the other two platforms with that of the Windows SQL Server. The SQL Server 2019 has better-integrated support for Linux with Kubernetes. The performance of the SQL Server 2019 on Linux instances have become better with parallel processing of the tasks on the Containers.
3. Availability
There are multiple improvements made on the Always On Availability Group. New features of connection redirection and enhanced database health checks are ensured.
Resumable Online Index creation has eased the whole process of heavy Index creation, manageable. Otherwise, in older editions, with any pause to the Index creation process, either due to memory constraints or otherwise, the process had to be re-started, making it cumbersome.
Conclusion
SQL Server 2019 is definitely an improvised version of the previous SQL Server editions. There are many good reasons why companies need to adapt to the new version. Since most of the features are an extension to the existing features of the older SQL server versions, no new installation or environment setup needs to be done. Many feedbacks to the new installation and update include the ease of set up and easy usage of the tool. Overall, it's a reliable and stable product.
List of Related Microsoft Certification Courses:
| SSIS | Power BI |
| SSRS | SQL Server |
| SSAS | SQL Server DBA |
| SCCM | BizTalk Server |
| Team Foundation Server | BizTalk Server Administrator |
 On-Job Support Service
On-Job Support Service
Online Work Support for your on-job roles.

Our work-support plans provide precise options as per your project tasks. Whether you are a newbie or an experienced professional seeking assistance in completing project tasks, we are here with the following plans to meet your custom needs:
- Pay Per Hour
- Pay Per Week
- Monthly
| Name | Dates | |
|---|---|---|
| SQL Server Training | Jul 25 to Aug 09 | View Details |
| SQL Server Training | Jul 28 to Aug 12 | View Details |
| SQL Server Training | Aug 01 to Aug 16 | View Details |
| SQL Server Training | Aug 04 to Aug 19 | View Details |

Arogyalokesh is a Technical Content Writer and manages content creation on various IT platforms at Mindmajix. He is dedicated to creating useful and engaging content on Salesforce, Blockchain, Docker, SQL Server, Tangle, Jira, and few other technologies. Get in touch with him on LinkedIn and Twitter.



